
Спрашиваете ИИ про политику? Ваш провайдер это видит. Даже через HTTPS.
Microsoft раскрыла атаку "Whisper Leak".

Microsoft рассказала о новой атаке побочного канала на удаленные языковые модели. Она позволяет пассивному злоумышленнику, который видит зашифрованный сетевой трафик, определить тему разговора пользователя с ИИ даже при использовании HTTPS. Технику назвали Whisper Leak.
В компании пояснили, что утечка касается диалогов со стриминговыми LLM, то есть с моделями, которые отправляют ответ частями по мере генерации. Такой режим удобен для пользователя, потому что не нужно ждать, пока модель полностью посчитает длинный ответ. Но именно по этим частям можно восстановить контекст разговора. Microsoft отмечает, что это создает риск для конфиденциальности переписки людей и корпоративных пользователей.
Исследователи Джонатан Бар Ор и Джефф Макдональд из Microsoft Defender Security Research Team объяснили, что атака становится возможной в ситуации, когда к трафику есть доступ у сильного противника. Это может быть структура на уровне провайдера, кто-то в той же локальной сети или даже человек, подключенный к тому же Wi-Fi. Такой противник не сможет прочитать содержимое сообщения, потому что TLS шифрует данные. Но он увидит размеры пакетов и интервалы между ними. Этого достаточно, чтобы обученной модели определить, относится ли запрос к одной из заранее заданных тем.
По сути атака использует последовательность размеров и времени прихода зашифрованных пакетов, которые возникают при ответе стриминговой языковой модели. Microsoft проверила гипотезу на практике. Исследователи обучили бинарный классификатор, который отличает запрос на конкретную тему от всего остального шума. В качестве доказательства работоспособности они использовали три разных подхода машинного обучения LightGBM, Bi-LSTM и BERT. Оказалось, что для целого ряда моделей Mistral, xAI, DeepSeek и OpenAI точность превысила 98 процентов. Это значит, что злоумышленник, который просто наблюдает трафик к популярным чатботам, может довольно надежно помечать диалоги, где спрашивают про чувствительные вещи.
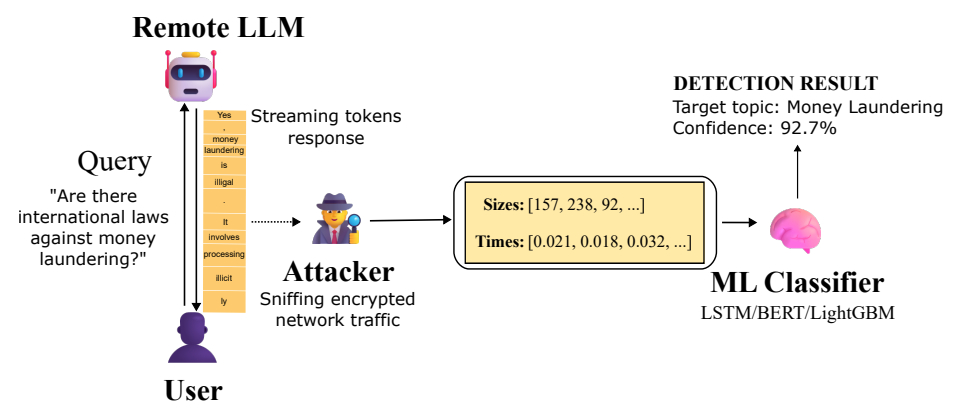
Microsoft отдельно подчеркнула, что при массовом мониторинге трафика, например на стороне провайдера или госструктуры, таким способом можно выявлять пользователей, которые задают вопросы про отмывание денег, политическое инакомыслие или другие контролируемые темы, даже если весь обмен зашифрован.
Авторы работы отмечают неприятную деталь. Чем дольше злоумышленник будет собирать обучающие выборки и чем больше у него будет примеров диалогов, тем точнее станет классификация. Это превращает Whisper Leak из теоретической атаки в практическую. После ответственного раскрытия информации OpenAI, Mistral, Microsoft и xAI внедрили защитные меры.
Одним из эффективных приемов защиты стало добавление к ответу случайной последовательности текста переменной длины. Это размывает зависимость между длиной токенов и размерами пакетов, из-за чего побочный канал теряет информативность. Microsoft также советует пользователям, которые переживают за конфиденциальность, не обсуждать чувствительные темы в недоверенных сетях, при возможности использовать VPN, выбирать нестриминговые варианты LLM и работать с провайдерами, которые уже внедрили смягчающие меры.
На этом фоне Cisco опубликовала отдельную оценку безопасности восьми открытых по весам LLM от Alibaba, DeepSeek, Google, Meta, Microsoft, Mistral, OpenAI и Zhipu AI. Исследователи показали, что такие модели плохо держатся в сценариях с несколькими ходами диалога и их проще обмануть именно в длинных сессиях. По их словам, у моделей, где приоритетом была мощность, а не безопасность, выше уязвимость при многошаговых атаках. Это дополняет вывод Microsoft о том, что организации, которые берут открытые модели и встраивают их в свои процессы, должны сами добавлять защитные контуры, регулярно проводить red teaming и жестко задавать системные промты.
В совокупности эти исследования показывают, что безопасность LLM пока остается незавершенной задачей. Шифрование трафика защищает содержание, но не всегда скрывает поведение модели. Поэтому разработчикам и заказчикам ИИ-систем придется учитывать и такие побочные каналы, особенно при работе с чувствительными темами и в сетях, где трафик может наблюдаться третьими лицами.