
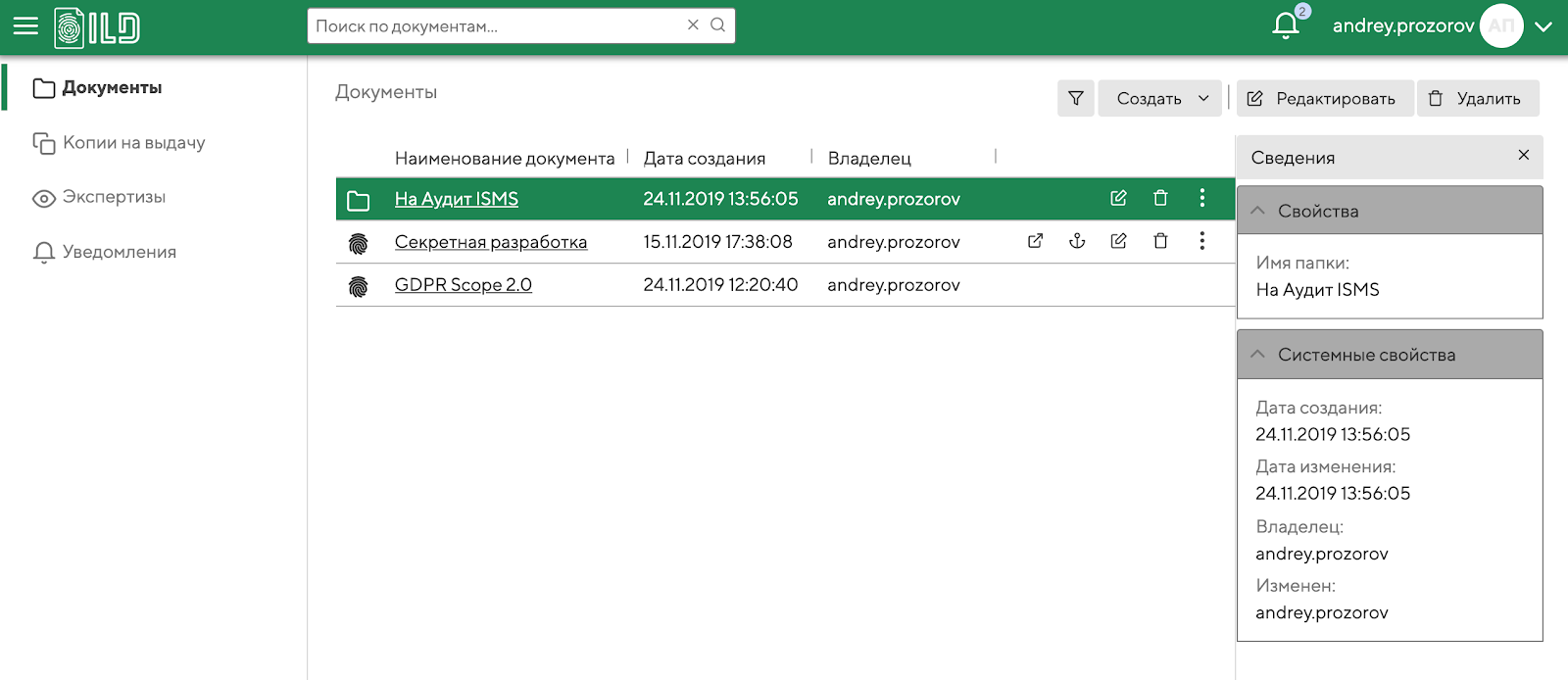
Взял потестировать продукт EveryTag VDR ("Виртуальная комната для безопасного обмена файлами и обнаружения нарушителя в случае утечки"), который из себя представляет что-то типа корпоративного Dropbox для обмена действительно конфиденциальными документами, когда каждый получатель каждый раз получает свою уникальную копию документа. При этом копии помечаются не какими-то невидимыми и/или цифровыми метками, суть в другом: система выделяет и чуть сдвигает отдельные слова/объекты в тексте и по их взаимному расположению распознает конкретные экземпляры документа.
Для чего нужен такой сервис/продукт? Для создания и контроля персонифицированных копий документов, и если эти документы скомпрометированы (например, о готовящейся сделке написали СМИ, или документы по конкурсу утекли конкуренту, или подрядчик-аудитор потерял флешку с файлами), то можно выявить источник утечки даже по небольшому фрагменту документа (или его копии, фотографии, клочку бумаги). У меня получалось установить автора по 25% текста на странице, но разработчики обещают высокую точность и при меньших объемах "уцелевшего" текста.
Ну, а для себя я рассматриваю это решение, в первую очередь, для обмена внутренними документами с поставщиками (при внешних аудитах и при при выборе и оценке новых поставщиков). Также оно может заинтересовать мой топ-менеджмент возможностью создания уникальных копий протоколов важных и особо конфиденциальных совещаний...
Вернемся к продукту, интерфейс его прост и удобен, опций и кнопок по минимуму. Можно загружать документы, создавать и оправлять их копии, проводить экспертизы (расследования) по фактам инцидентов.
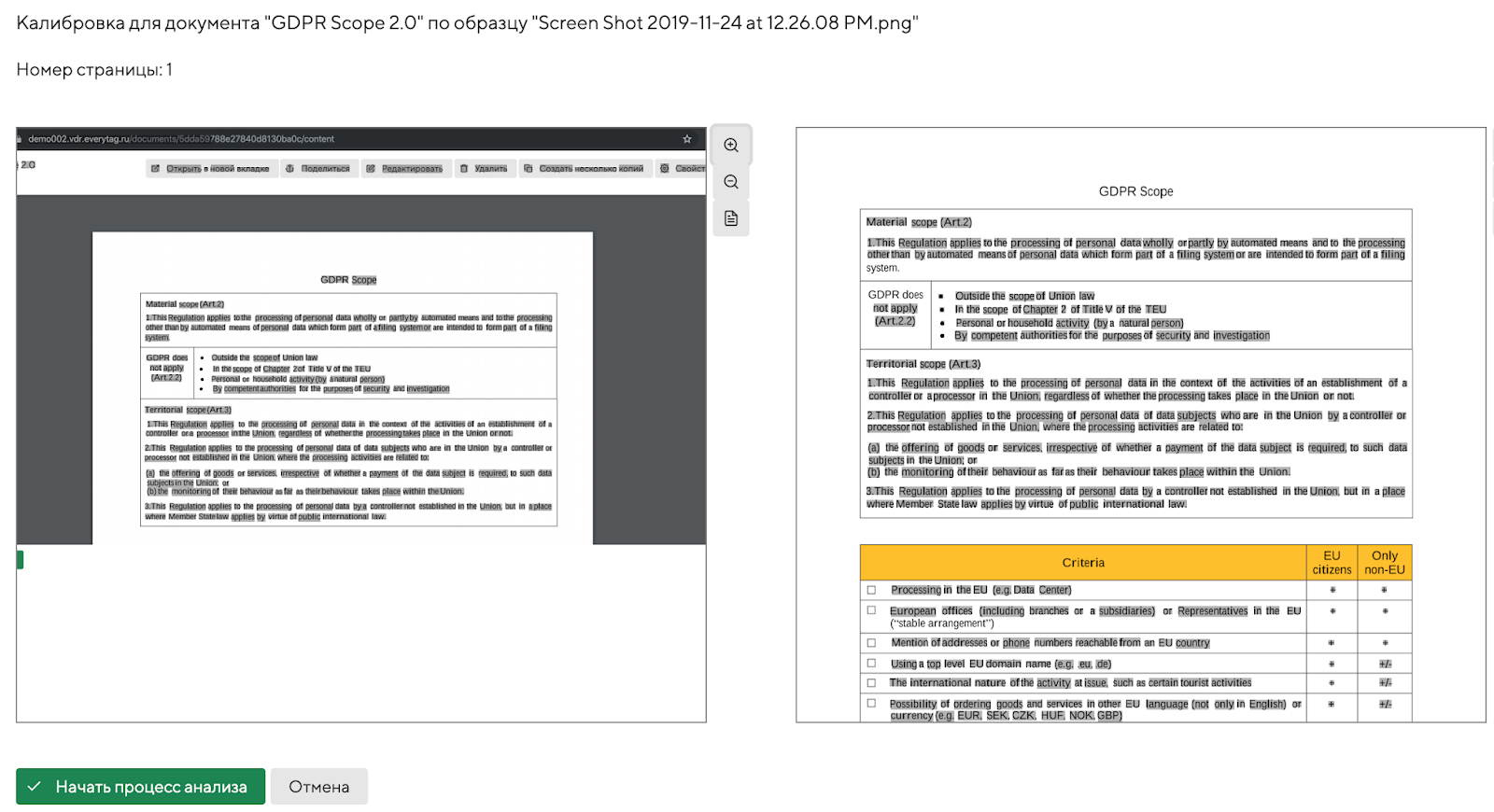
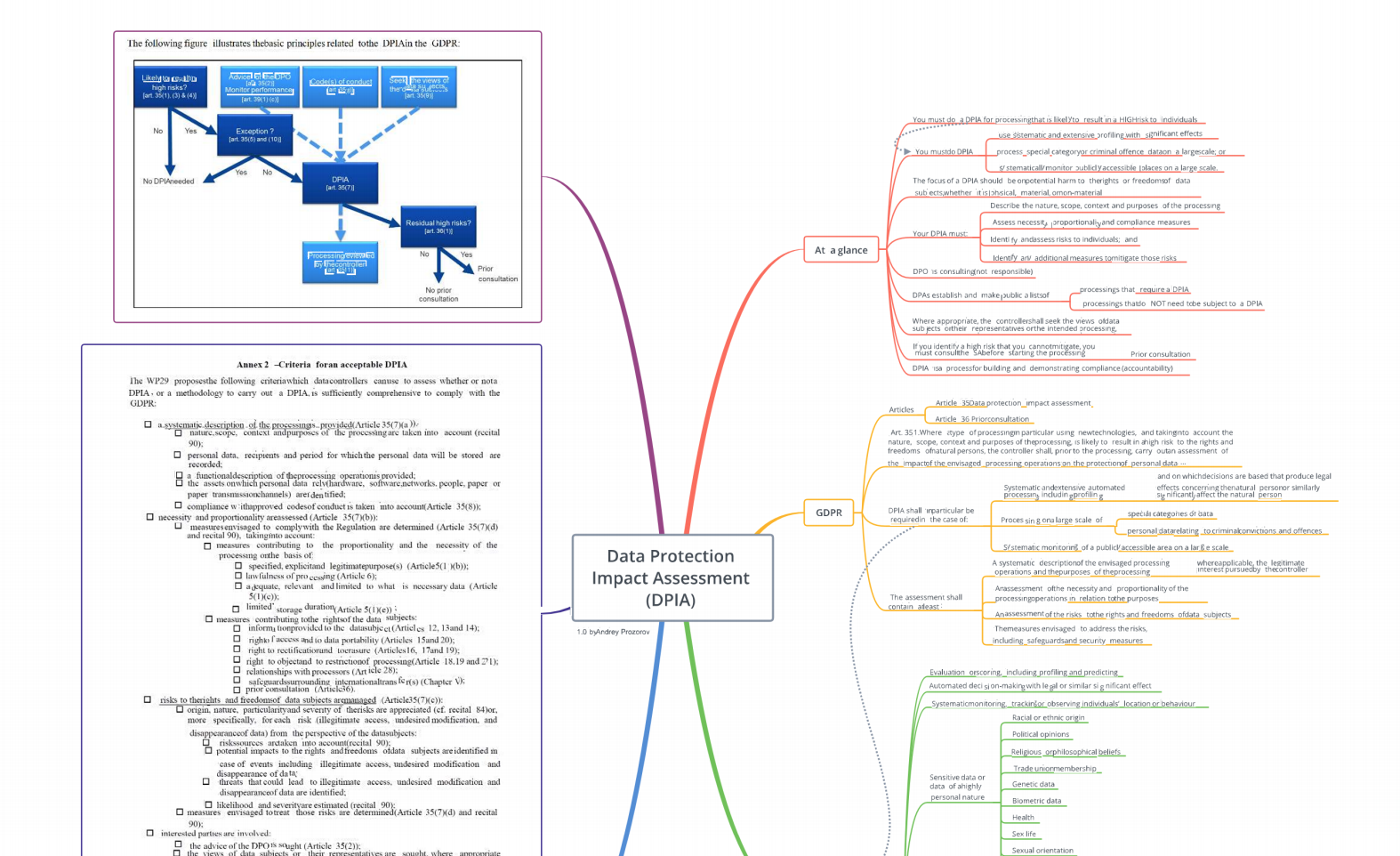
Ниже пару скринов простого сценария. Я загрузил документ "GDPR Scope 2.0", затем создал и отправил несколько его копий разным адресатам. Потом я открыл одну из них, сделал скриншот и загрузил его в систему для определения источника утечки. Система безошибочно его указала.
Обратите внимание, что я проверял именно картинку (скриншот), а не какой-то специальный электронный файл с электронными метками, аналогично я мог натравить систему на фото документа или скан печатной копии... Также в моем примере я не захотел уменьшать масштаб и на скриншот попала лишь часть документа (порядка 45%), но этого оказалось более чем достаточно.
При загрузке фрагмента документа на анализ система, определив исходный (эталонный) документ, предложит сделать калибровку копии документа и исходного текста, это необходимо сделать для повышения скорости и точности разбора. Достаточно выделить несколько пар объектов и можно начинать анализ...
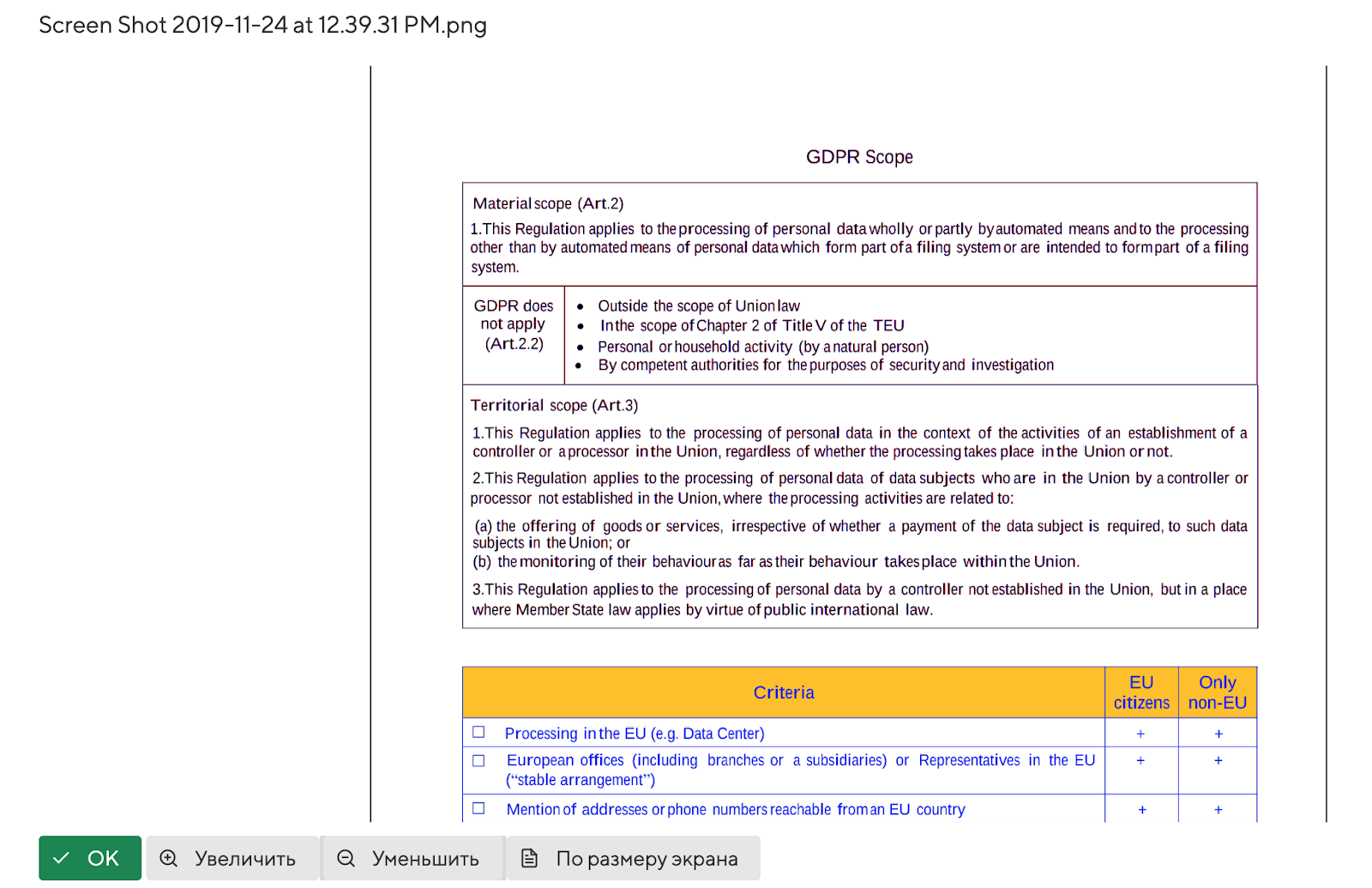
По результатам выдается вердикт - рейтинг о совпадении экземпляра с уникальной копией. В моем кейсе свою копию скомпрометировал Максим.

На картинке видно, что первая часть текста (именно она попала в тестовый фрагмент) полностью совпадает с копией виртуального Максима.
Я протестировал продукт на нескольких сценариях и разных документах и, в целом, его работой я доволен.
Что понравилось:
- Продукт не требует какой-то дополнительной настройки (ну, кроме прав доступа) и способен к работе и пользе прямо с момента его запуска. Платформа для управления копиями документов проста и удобна даже для далеких от ИТ специалистов.
- Систему можно развернуть у себя, а можно использовать облачный сервис.
- Используется графический механизм создания копий, это позволяет работать с фотографиями и сканами бумажных документов. При этом форматирование текста хотя и происходит, но оно довольно легкое и, что удивительно, даже не всегда (но часто) заметное. Странно, что даже сложные таблицы в моих тестах визуально не изменились, и даже майндкарты выглядят нормально.
- Продукт создает уникальную копию при каждом открытии документа. Разработчики утверждают: "VDR способен создавать более 205 триллионов уникальный копий для одной страницы."
- Есть интеграция по ICAP с другими системами. Было бы интересно их задружить с СЭД и DLP...
Но есть и несколько моментов, которые мне не понравились:
- Я 2 раза поломал алгоритм обучения для новых пользователей системы - интерактивную пошаговую инструкцию. Видимо мой сценарий использования продукта чуть отличается от ожиданий разработчика.
- При использовании некачественных экземпляров на анализ, а именно при "перекошенных" сканах или фотографиях, сделанных под углом, их первоначально придется выровнять в стороннем графическом редакторе. Система пока не умеет их выравнивать самостоятельно.
- При использовании цветных строк таблиц или при наличии выделения строк цветом иногда (но не всегда) в копиях не аккуратно смещается текст
В общем, коллеги разработали интересный продукт, который может хорошо дополнить комплексный подход по защите от внутренних угроз. Рекомендую к ним присмотреться - https://everytag.ru

