
Скоростная отказоустойчивая компрессия
Данная статья уже вторая в теме о скоростной компрессии данных.
Данная статья уже вторая в теме о скоростной компрессии данных. В первой статье был описан компрессор работающий со скоростью 10 Гбайт/сек. на одно процессорное ядро (минимальное сжатие, RTT-Min).
Этот компрессор используется в криминалистических дубликаторах, обеспечивая скоростное сжатие дампов носителей информации и усиление стойкости криптографии. Также он может применяться для сжатия образов виртуальных машин и своп файлов оперативной памяти при сохранении их на быстродействующих SSD накопителях.
Тема скоростной компрессии на этом не закончилась, она перетекла в разработку более сложного алгоритма компрессии для сжатия образов дисковых накопителей с существенно улучшенными параметрами компрессии (среднее сжатие, RTT-Mid). К настоящему времени этот компрессор полностью готов и данная статья именно о нем.
Фактор скорости
Скорость упаковки/распаковки данных является критическим параметром определяющим область применения технологий компрессии. Если нужно архивировать 1-10 МегаБайт данных, то для этого используются архиваторы со скоростью работы в 15-20 МегаБай/сек.. Такие архиваторы обеспечивают максимальную степень сжатия, но при этом очень медлительны.
Если нужно архивировать данные большого обьема, то вряд ли кому придет в голову сжимать эти данные с скоростью 10-15 МегаБайт в секунду, ведь на сжатие 1ТераБайт данных придется затратить почти двадцать часов при полной загрузке процессора…
С другой стороны тот же терабайт можно скопировать на скоростях порядка 2-3ГигаБайт в секунду минут за десять. Поэтому сжатие информации большого обьема актуально если его производить со скоростью не ниже скорости ввода/вывода. Для современных систем это не менее 100 МегаБайт в секунду.
Если компрессор имеет такие скорости обработки данных, то его уже можно применять в системах резервного копирования и хранения больших объемов данных класса Big Data.
Причем при обработке Больших Данных важна не столько скорость упаковки данных (это одноразовая операция), а скорость распаковки, поскольку эта операция выполняется многократно.
Скорость 100 МегаБайт/сек. и выше современные алгоритмы компрессии могут выдавать только в режиме «fast». Вот в этом режиме и будем проводить сравнение алгоритма RTT-Mid с традиционными алгоритмами Rar и Zip.
Также проведем сравнение с алгоритмом LZ4. Являясь наиболее скоростным из семейства алгоритмов словарного метода, LZ4 отстает от них в степени сжатия. В режимах Fast и Norm алгоритм LZ4 слишком слаб в сжатии и может конкурировать только с алгоритмом RTT-Min, это не та «весовая категория» для текущего сравнения. Поэтому будем использовать алгоритм LZ4 в режиме Ultra, обеспечивающем максимальное сжатие.
Сравнительное тестирование нового алгоритма компрессии
Поскольку используемые в сравнительном тесте компрессоры построены на разных принципах и различные типы данных сжимают по разному, то для объективности теста использовался метод замера «средней температуры по больнице».
Был создан файл посекторного дампа логического диска с операционной системой Windows -10, это наиболее естественная смесь различных структур данных реально имеющаяся на каждом компьютере. Сжатие этого файла позволит провести сравнение по скорости и степени компрессии нового алгоритма с самыми продвинутыми компрессорами используемыми в современных архиваторах.
Вот этот файл дампа:
Файл дампа сжимался компрессорами РТТ-Mid, 7-zip, WinRar и кастомизированной версией 7-zip в которой использовался алгоритм сжатия LZ4. Компрессоры WinRar и 7-zip были выставлены на максимальную скорость работы, компрессор LZ4 был выставлен в режим Ultra.
Компрессор RTT-Mid работал в составе тестовой (отладочной) программы. В реальном «рабочем» приложении он работает значительно быстрее, там грамотно используется многопоточность и применяется «нормальный» компилятор, а не СИ#.
Работает компрессор Zip:
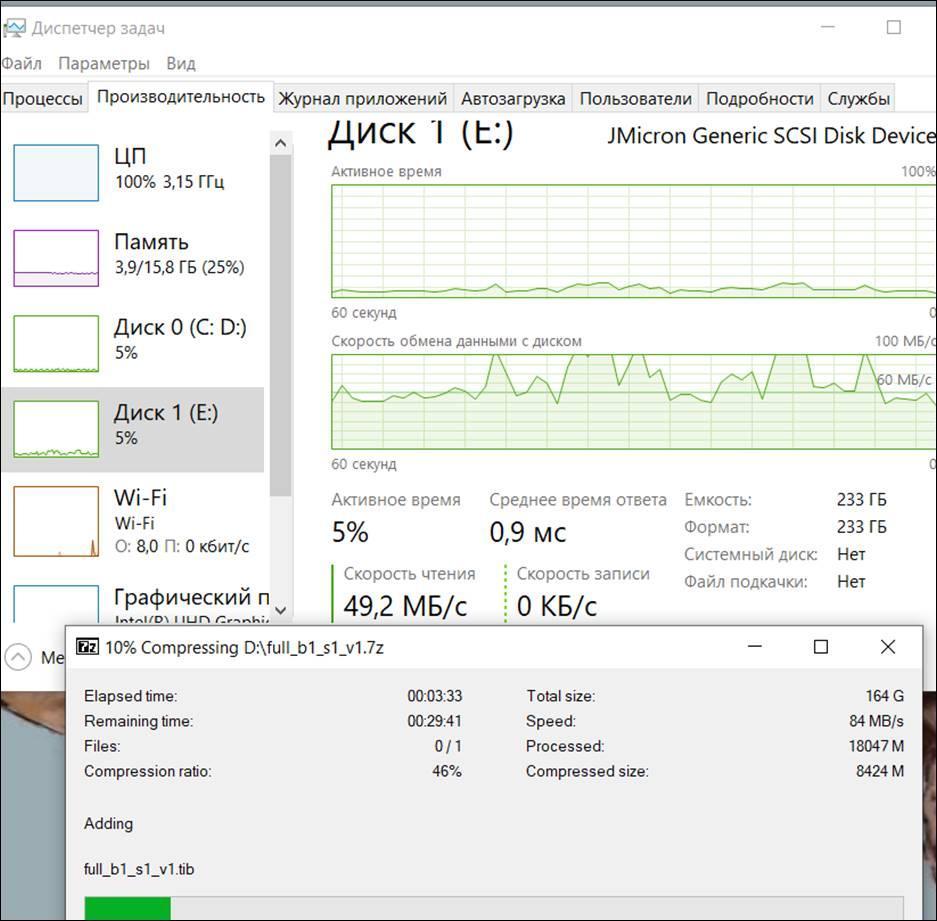
Он грузит процессор на 100%, при этом средняя скорость чтения исходного дампа (Диск 1) около 80МегаБайт/сек.
Работает компрессор Rar:
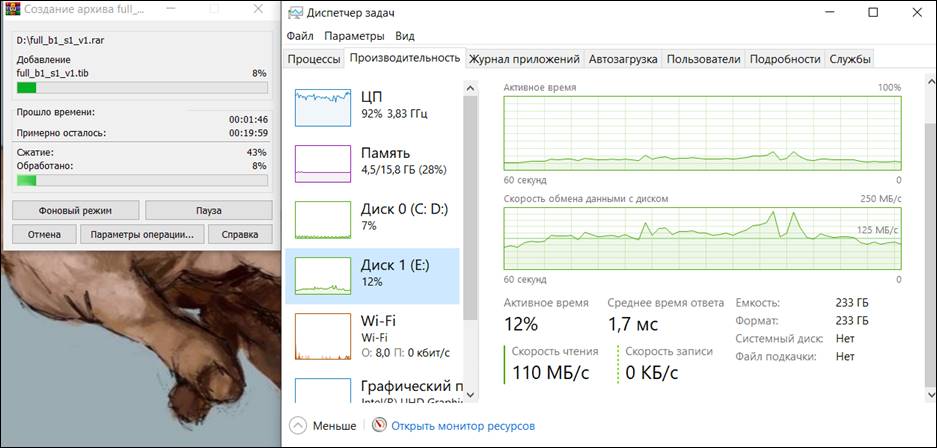
Ситуация аналогичная, загрузка процессора практически 100%, средняя скорость чтения дампа (Диск 1) около 125 МегаБайт/сек.
Как и в предыдущем случае, скорость работы архиватора ограничена возможностями процессора.
Работает алгоритм LZ4 с максимальной степенью сжатия:
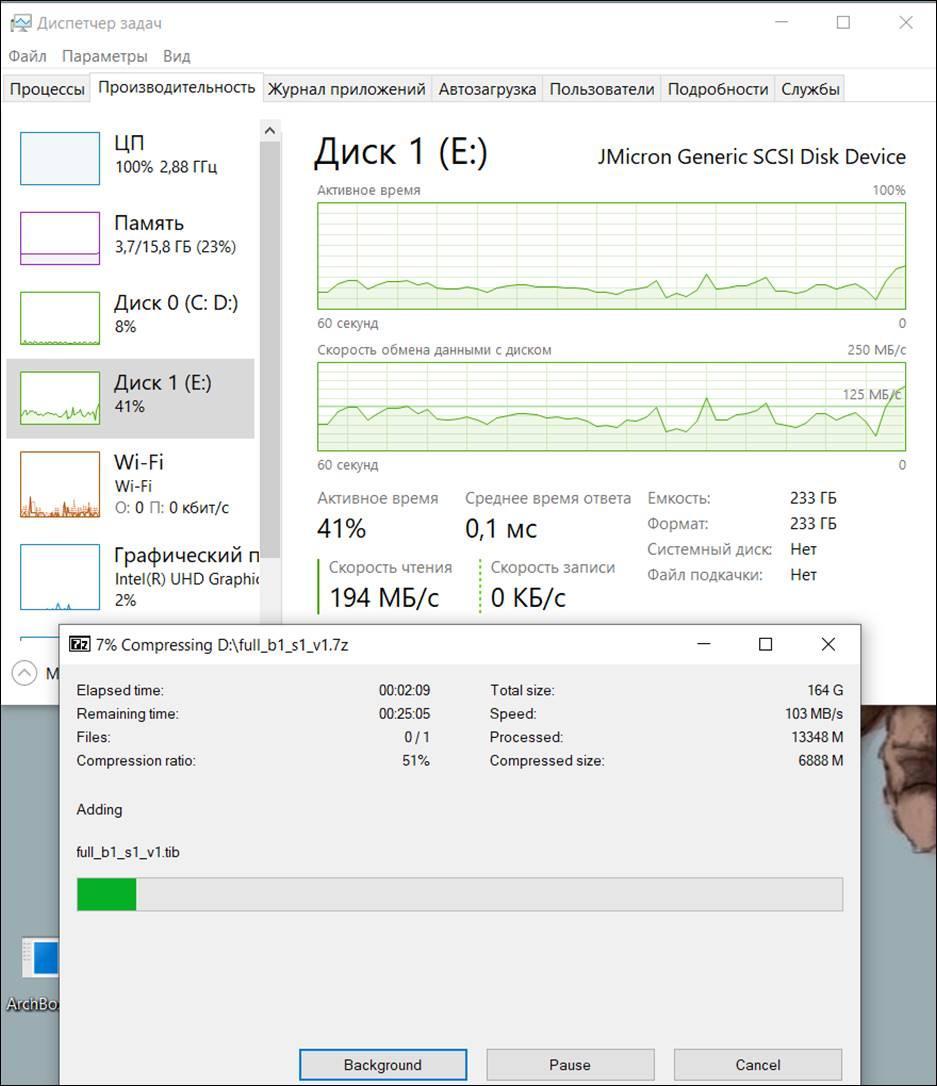
Получаем скорость чтения дампа (Диск 1) около 100МегаБайт/сек., и опять упираемся в ограничение скорости работы вызванное полной загрузкой процессора.
Теперь работает тестовая программа компрессора RTT-Mid:
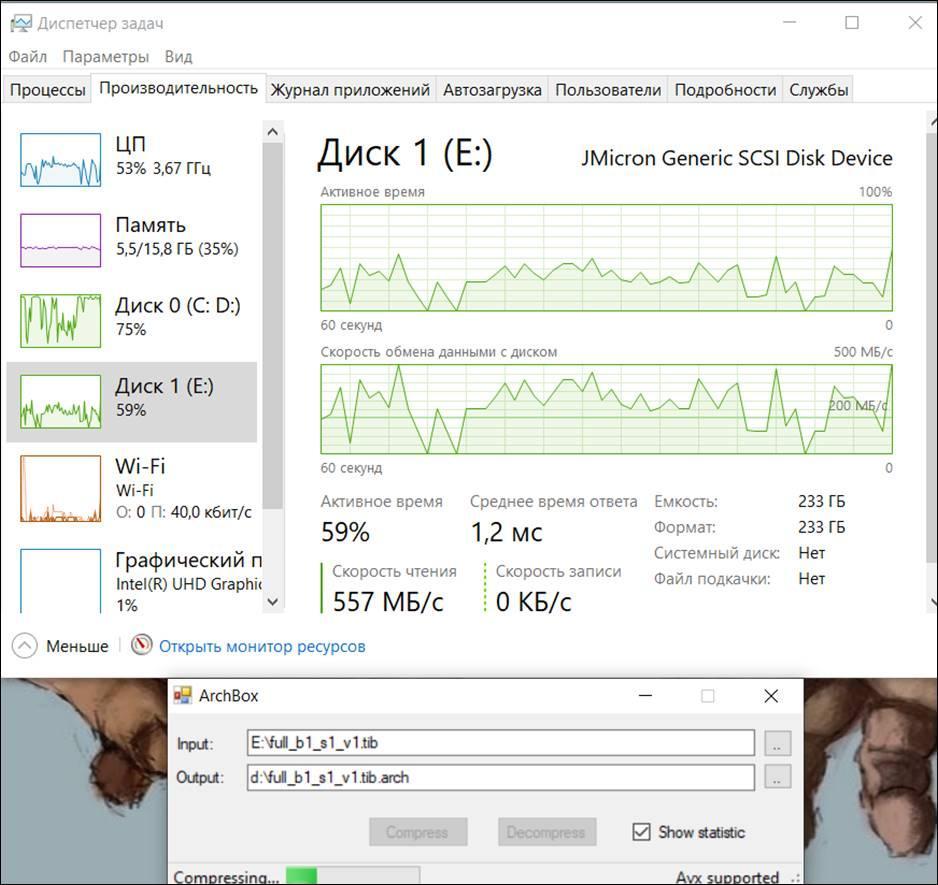
Скриншот показывает, что процессор загружен на 50% и простаивает остальное время, потому как некуда выгружать сжатые данные. Диск выгрузки данных (Диск 0) загружен практически полностью. Скорость чтения данных (Диск 1) сильно скачет, но в среднем более 200МегаБайт/сек.
Скорость работы компрессора ограничивается в данном случае возможностью записи сжатых данных на Диск 0, а не возможности процессора.
Теперь степень сжатия получившихся архивов.
7-Zip:

WinRar

LZ-4(Ultra)

RTT-Mid

Видно что компрессор RTT-Mid лучше всех справился с компрессией, архив созданный им на 1.3 ГигаБайта меньше архива Rar, на 2.1 ГигаБайта меньше архива Zip и на 7.8 ГигаБайта меньше архива LZ4 в режиме Ultra.
Время затраченное на создание архива:
7-zip – 26минут 10 секунд
WinRar – 17минут 40 секунд
LZ4 (Ultra) – 14минут 15 секунд
RTT-Mid – 7 минут 30 секунд
Таким образом, даже тестовая, не оптимизированная программа используя алгоритм RTT-Mid смогла более чем в два раза быстрее создать архив не нагружая процессор на «полную катушку», при этом архив оказался существенно меньшим нежели у конкурентов…
Желающие провести самостоятельное тестирование могут скачать реализующую алгоритм RTT-Mid программу, доступную по ссылке. Тестовая программа работает на процессорах с поддержкой AVX-2, и не тестируйте алгоритм на старых процессорах AMD, они медленные в части выполнения AVX команд….
Используемый метод компрессии
В алгоритме RTT-Mid используется метод индексирования повторяющихся фрагментов текста в байтовой грануляции (дедупликатор). Такой метод сжатия известен давно, но не использовался, поскольку операция поиска совпадений была очень затратна по необходимым ресурсам и требовала гораздо более времени нежели построение словаря. Так что алгоритм RTT-Mid является классическим примером движения «назад, в будущее», ничего нового в используемом методе нет, это оптимизация, не более того.
В компрессоре РТТ используется скоростной сканер поиска совпадений, именно он позволил ускорить процесс компрессии. Сканер поиска совпадений выполнен по двухуровневой вероятностной схеме, сначала сканируется наличие «признака» совпадения, и только после выявления «признака» в этом месте запускается процедура обнаружения реального совпадения.
Окно поиска совпадений имеет непредсказуемый размер, зависящий от степени энтропии в обрабатываемом блоке данных. Для полностью случайных (несжимемых) данных оно имеет размер мегабайт, для данных имеющих повторы всегда имеет размер больше мегабайта.
Но многие современные форматы данных несжимаемы и «гонять» по ним ресурсоемкий сканер бесполезно и расточительно, поэтому в сканере используется два режима работы. Сначала ищутся участки исходного текста с возможными повторами, эта операция проводится тоже вероятностным методом и выполняется очень быстро (на скорости 4-6ГигаБайт/сек). Затем участки с возможными совпадениями обрабатываются основным сканером.
Индексное сжатие не очень эффективно, приходится заменять повторяющиеся фрагменты индексами, и индексный массив существенно снижает коэффициент сжатия.
Для увеличения степени сжатия индексируются не только полные совпадения байтовых строк, но и частичные, когда в строке имеются совпавшие и не совпавшие байты. Для этого в формат индекса включено поле маски совпадений, которая указывает на совпавшие байты двух блоков. Для еще большей компрессии используется индексирование с наложением нескольких частично совпадающих блоков, на текущий блок.
Все это позволило получить в компрессоре РТТ-Mid степень сжатия, сопоставимую с компрессорами выполненными по словарному методу, но работающий гораздо быстрее.
Скорость работы нового алгоритма компрессии
Если компрессор работает с монопольным использованием кешпамяти (на один поток требуется 4МегаБайта), то скорость работы колеблется в диапазоне 700-2000 мегабайт/сек. на одно процессорное ядро в зависимости от типа сжимаемых данных и мало зависит от рабочей частоты процессора.
При многопоточной реализации компрессора эффективная масштабируемость определяется обьемом кешпамяти третьего уровня. К примеру, имея «на борту» 9МегаБайт кешпамяти запускать более двух потоков компрессии нет смысла, скорость расти от этого не будет. Но при кеше в 20МегаБайт можно уже запускать пять потоков компрессии.
Также существенным параметром определяющим скорость работы компрессора становится латентность оперативной памяти. Алгоритм использует рандомные обращения к ОП, часть из которых не попадает в кешпамять (около 10%) и ему приходится простаивать ожидая данные из ОП, что снижает скорость работы.
Существенно влияет на скорость компрессора и работа системы ввода/вывода данных. Запросы к ОП от ввода/вывода блокируют обращения за данными со стороны ЦП, что также снижает скорость компрессии. Эта проблема существенна для ноутбуков и десктопов, для серверов она менее существенна благодаря более продвинутому блоку управления доступом к системной шине и многоканальной оперативной памяти.
Скорость декомпрессии сжатых данных по алгоритму РТТ-Mid ограничивается только скоростью ввода/вывода. Одно физическое ядро в одном потоке спокойно обеспечивает скорости распаковки на уровне 5 Гигабайт/сек.
Это связано с отсутствием в процессе распаковки операции поиска совпадений, которая «сжирает» основные ресурсы процессора и кешпамяти при компрессии. Отсутствие вычислительной нагрузки при распаковке данных приводит к парадоксальному явлению, доступ к данным в упакованном формате выполняется быстрее чем доступ к неупакованным данным…
К примеру, имеем 1ГигаБайт данных, и он сжимается в два раза.
При распаковке для доступа к нему требуется прочитать из накопителя всего 500МегаБайт данных и потратить совсем немного процессорного времени на распаковку данных в оперативной памяти.
Если бы данные были не упакованы, то пришлось бы читать из накопителя 1ГигаБайт данных.
Другими словами, потратить на операцию ввода данных с накопителя в два раза больше времени.
Надежность хранения сжатых данных
Как следует из названия всего класса программных средств использующих компрессию данных (архиваторы), они предназначены для длительного хранения информации, не годами, а столетиями и тысячелетиями…
Ни один из ответственных производителей современных цифровых систем хранения данных и цифровых носителей к ним не дает гарантий полной сохранности данных более чем на 75 лет.
Системы хранения цифровых данных теряют данные и раньше, ошибки могут появиться в любое время, даже во время их записи. Системы коррекции могут восстановить утраченную информацию далеко не всегда, а если и восстанавливают, то нет гарантий, что операция восстановления прошла корректно.
И это большая проблема для хранения данных в сжатом виде, когда нет гарантий полной сохранности данных на носителе информации.
Объясню почему это так.
За время хранения любые носители информации теряют часть данных, вот пример:

Этому «аналоговому» носителю информации тысяча лет, современные цифровые носители информации так надежно хранить данные не умеют, но не это главная проблема…
Ошибки хранения на этом носителе не фатальны, они локализованы и не мешают чтению неповрежденных данных. Если бы на этом носителе были записаны цифровые сжатые данные то после первого утерянного фрагмента весь остальной текст стал бы абсолютно не читаем.
Низкая отказоустойчивость современных словарных алгоритмов обусловлена форматом хранения сжатых данных. Информация в таком архиве не содержат исходный текст, там хранятся номера записей в словаре, сам же словарь динамически модифицируется текущим сжимаемым текстом. При утере или искажении фрагмента архива, все последующие записи архива невозможно идентифицировать, поскольку непонятно чему соответствует текущий номер словарной записи.
Для таких архивов утеря фрагмента информации будет фатальным событием, все данные после ошибочного фрагмента информации становятся нечитаемыми. Существует даже устоявшийся термин для такой ситуации,- «битый архив»…
Восстановить информацию из такого «битого» архива невозможно уже после появления самой первой ошибки от начала информационного блока.
Алгоритм РТТ-Mid построен на основе более надежного индексного метода хранения сжатых данных. Такой подход к компрессии позволяет локализовать последствия искажения информации на носителе.
Это связано с тем, что архивный файл в случае индексного сжатия содержит два поля:
- поле исходного текста с удаленными из него участками повтора
- поле индексов.
Критически важное для восстановления информации поле индексов, не велико по размеру и его можно дублировать для надежности хранения данных. Поэтому даже если будет утерян фрагмент исходного текста или индексного массива, то вся остальная информация будет восстанавливаться без проблем, как на картинке с «аналоговым» носителем информации.
Степень сжатия
Достоинств не бывает без недостатков. Индексный метод компрессии не сжимает повторяющиеся последовательности малой длины. Это связано с ограничениями индексного метода. Индексы имеют размер не менее 3 байт и могут быть размером до 12байт. Если встречается повтор с меньшим размером чем описывающий его индекс, то он не учитывается, как бы часто такие повторы не выявлялись в сжимаемом файле.
Традиционный, словарный метод компрессии, эффективно сжимает множественные повторы малой длины и поэтому достигает большего коэффициента сжатия нежели индексная компрессия. Правда это достигается за счет высокой загруженности центрального процессора, чтобы словарный метод начал сжимать данные эффективнее индексного метода ему приходится снижать скорость обработки данных до 10-20 МегаБайт в секунду на реальных вычислительных установках при полной загрузке ЦП.
Такие низкие скорости неприемлемы для современных систем хранения данных и представляют больше «академический» интерес, нежели практический.
В любом случае, даже с этим недостатком, можно констатировать, что для скоростных компрессоров (100 МегаБайт/сек. и более) метод индексного сжатия стал более эффективным нежели словарный метод, как по скорости, так и по степени сжатия.
Для компрессии со скоростями менее 100 МегаБайт/сек. сохраняется лидерство за словарным методом, но эта ситуация не фатальна, у индексного метода есть еще резервы…
Степень сжатия информации будет существенно повышена в следующей модификации алгоритма, он уже в разработке.