
Автор: R T Т
1. Области применения компрессоров
Первоначально, сжатие информации использовалась для экономии информационного пространства на долговременных носителях информации. Постепенно эта задача утрачивает актуальность, сейчас проблем с емкостью носителей для хранения данных уже практически нет.
В настоящее время сжатие информации актуально для «уплотнения» каналов передачи данных, чтобы прокачать за единицу времени как можно больше информации.
Имеющиеся алгоритмы компрессии, реализованные программно, работают на скоростях до 70-100МегаБайт/сек. и могут удовлетворить потребности относительно низкоскоростных каналов связи.
Более скоростные каналы передачи данных, включая связь дисковых подсистем и оперативной памяти (скорость до 3ГигаБайт/сек) обслуживаться существующими программными компрессорами не могут.
2. Новый алгоритм компрессии
Чтобы операция сжатия информации перестала быть «бутылочным горлышком» в прохождении данных между системами хранения на современных HDD и SSD дисков и Оперативной памятью требуется создать алгоритм компрессии с темпом реальной работы не менее 3 ГигаБайт/сек. и не загружающего при этом процессор.
Для решения этой задачи был создан новый алгоритм компрессии максимально быстро реализуемый в аппаратуре и системе команд современных процессоров х86/64.
Алгоритм имеет следующие особенности:
- Используется символьное представление данных с грануляцией кратной 8бит
- Используется один проход по сжимаемым данным
- Цикл создания сжатого образа совмещен с циклом поиска совпадений
- Индексация совпадений выполнена на базе относительных смещений
- Индексируются частично совпадающие блоки
- Если размер индекса больше индексируемой экономии то он отбрасывается
- Выявление совпадающих блоков производится методом сдвигов кратных символу
- Применяются только последовательные операции чтения/записи данных
- Все операции сжатия/распаковки выполняются на регистрах процессора
- Промежуточные данные хранятся на регистрах процессора
- Буфер исходного и сжатого текста совмещены (в цикле упаковки)
- Служебный буфер имеет размер ¼ исходного буфера (в цикле упаковки)
- В цикле распаковки служебные буфера не используются.
Новый алгоритм использует для поиска совпадений символьных строк Кеш первого уровня процессорного ядра (окно поиска совпадений 16 кБайт).
Алгоритм использует индивидуальный Кеш первого уровня процессорного ядра, поэтому процедура компрессии может масштабироваться на все физические ядра без потери быстродействия.
Поиск совпадений выполняется на регистрах YMM длиной в 32байта, в окне просмотра 16кБайт, из-за этих ограничений новый алгоритм уступает по степени сжатия известным методам, но существенно превосходит их в скорости выполнения операций компрессии и декомпрессии.
На стенде получена скорость упаковки/распаковки 10ГигаБайт/сек. для одного процессорного ядра работающего на частоте 4ГигаГерца.
3. Пример реализации
Новый алгоритм сжатия информации уже реализован в серийном изделии.

На снимке криминалистический дубликатор. Это устройство позволяет параллельно считывать информацию с восьми дисков/флешек/карт памяти на внутренний SSD накопитель.
Сжатие информации в этом устройстве применяется для увеличения скорости операций копирования на внутренний накопитель. Устройство может обеспечивать суммарную пропускную способность до 800мегабайт/сек. по 8 каналам чтения, это ограничение аппаратурное, больше не могут пропустить используемые USB хабы.
Скорость работы внутреннего накопителя не более 500мегабайт/сек., для того чтобы записать 800мегабайт за секунду на накопитель работающий со скоростью 500мегабайт/сек. требуется сжать данные перед записью.
Эту задачу решает компрессор на новом скоростном алгоритме сжатия, кроме того, дополнительным бонусом будет экономия дискового пространства на устройстве хранения дампов.
На примере этого устройства оценим скорость работы алгоритма и его эффективность в типичных условиях работы.
Для сравнения нового алгоритма компрессии с используемыми в настоящее время компрессорами возьмем коммерческую систему создания резервных копий фирмы «АКРОНИС», она тоже делает посекторные дампы дисков с использованием сжатия информации.
Используем обе системы по их прямому назначению,- создадим дамп диска. Для этого возьмем SSD диск с системным разделом:
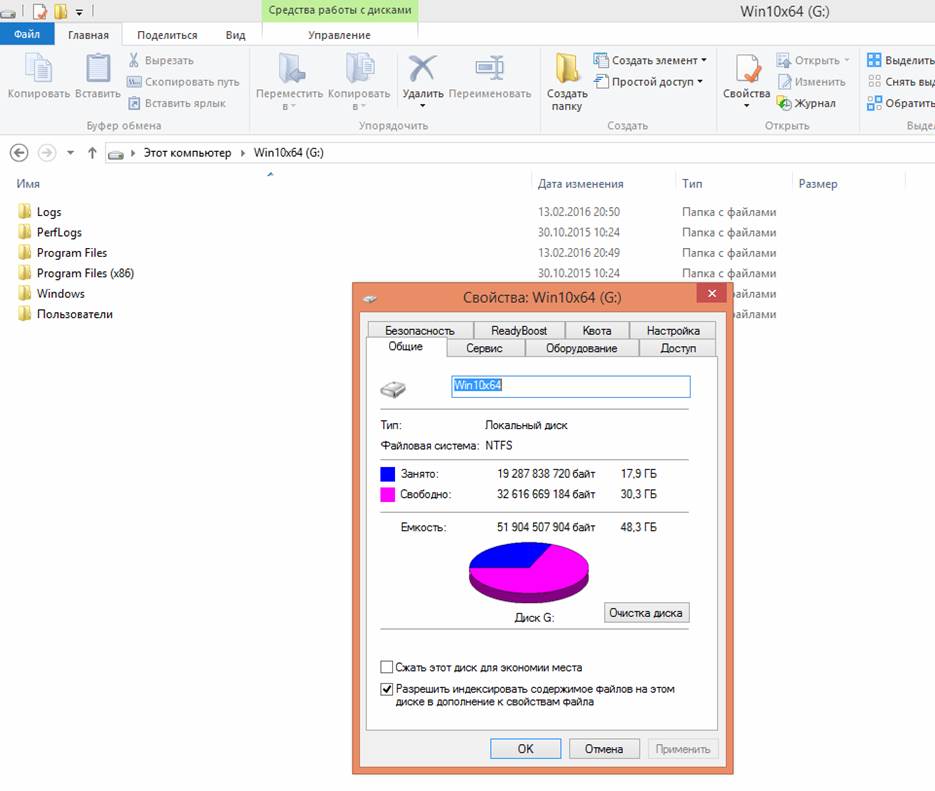
В системном разделе занято 17,9ГБ из общего объема 48,3ГБ.
Системный диск в качестве материала для тестирования выбран для объективности оценки, поскольку он есть на любом компьютере, то может выступать в качестве эталонной смеси из разных форматов данных для проверки эффективности сжатия.
Создаем дамп этого диска «Акронисом» с максимальной степенью компрессии, и видим следующую картину:
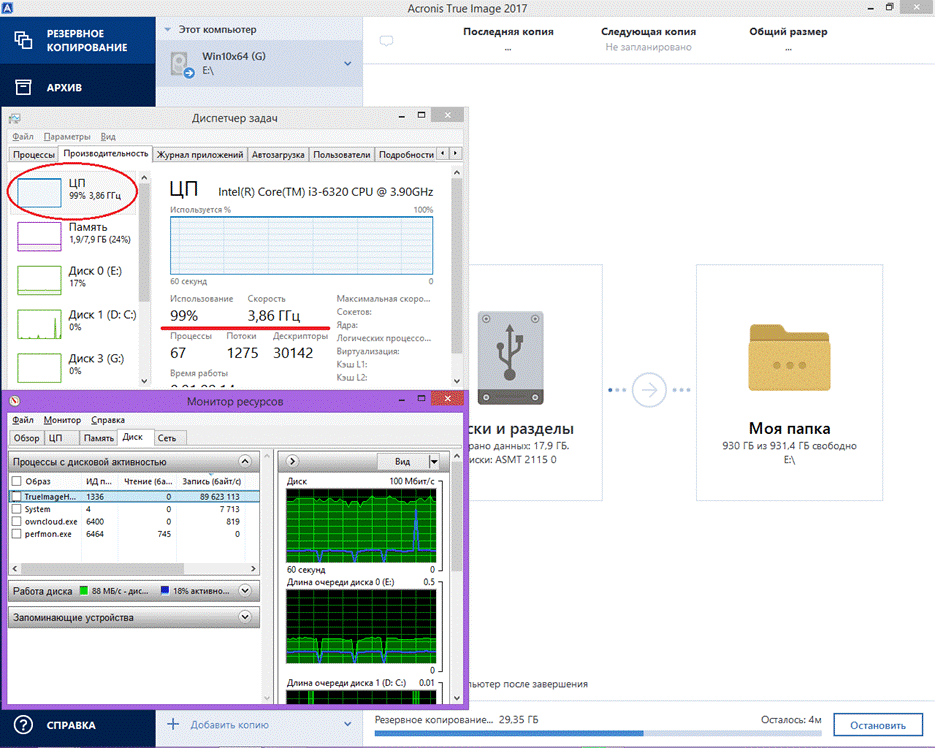
Процессор загружен компрессией на 99%, система практически неработоспособна, даже мышь начинает тормозить.
Эта картина нагрузки и скорости работы (около 70мБ/сек) характерна для работы любого современного компрессора и на месте «Акрониса» могла быть любая другая система, результат был бы аналогичным.
Теперь посмотрим как работает компрессор на новом алгоритме используемый в криминалистическом дубликаторе:
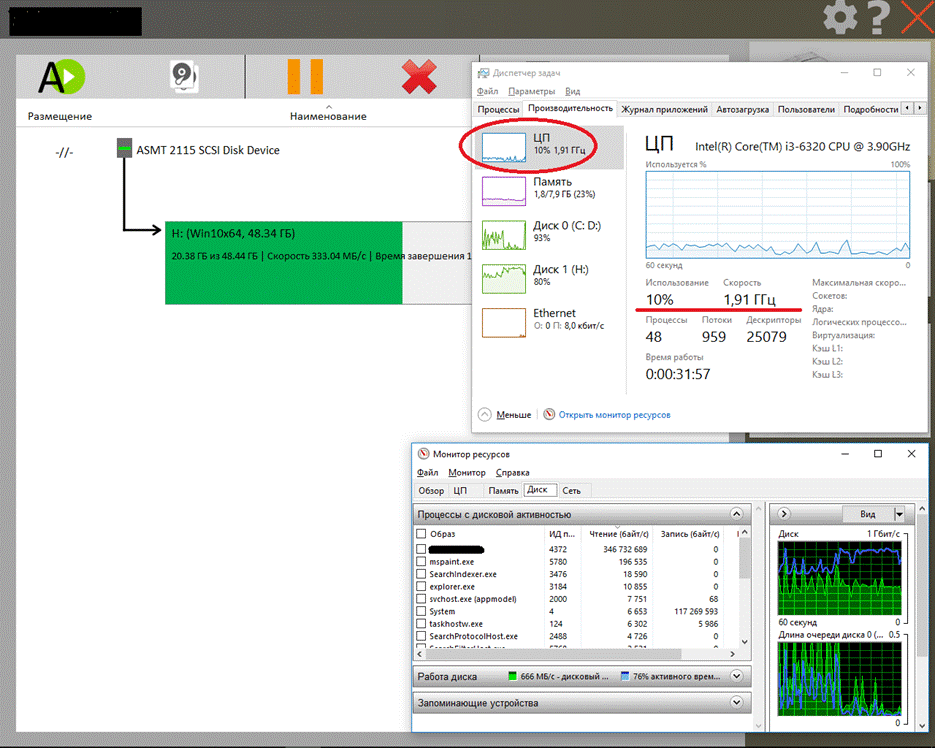
Работа системы дампирования и сжатия в криминалистическом дубликаторе проходит практически в фоновом режиме. Загрузка процессора не превышает 10% причем на сниженной практически в два раза частоте, из-за отсутствия нагрузки.
Теперь оценим качество сжатия, для этого посмотрим размеры получившихся дампов:
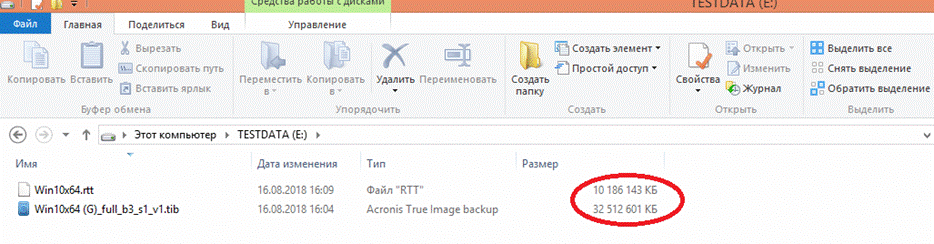
Компрессор РТТ сжал дамп в три раза лучше чем это смог сделать компрессор установленный в «Акронис».
В результате время создания дампа с компрессией РТТ составило 2.26 минут при загрузке процессора около 10% и сниженной вдвое от номинала частоте.
«Акронис» работал 9.35 минут при 100% загрузке процессора на максимальной частоте и создал дамп в три раза большего размера по сравнению с дампом РТТ.
4. Многопоточная нагрузка
Применяемые до настоящего времени алгоритмы сжатия не могут эффективно работать в многопоточных приложениях из-за исчерпания пропускной способности подсистемы памяти уже одним процессом компрессии.
Условно говоря, если процессор может обеспечить в одном потоке компрессии скорость 100мБ/сек., то два потока компрессии будут работать со скоростью 50мБ/сек. каждый. И это идеальный случай, на практике скорости будут гораздо ниже из-за коллизий в Кеше.
Новый алгоритм компрессии не создает нагрузки на ОП, он работает только с индивидуальным кешем первого уровня процессорного ядра. Поэтому можно запускать без снижения производительности столько потоков компрессии, сколько имеется физических процессорных ядер.
Вот пример подтверждающий это:
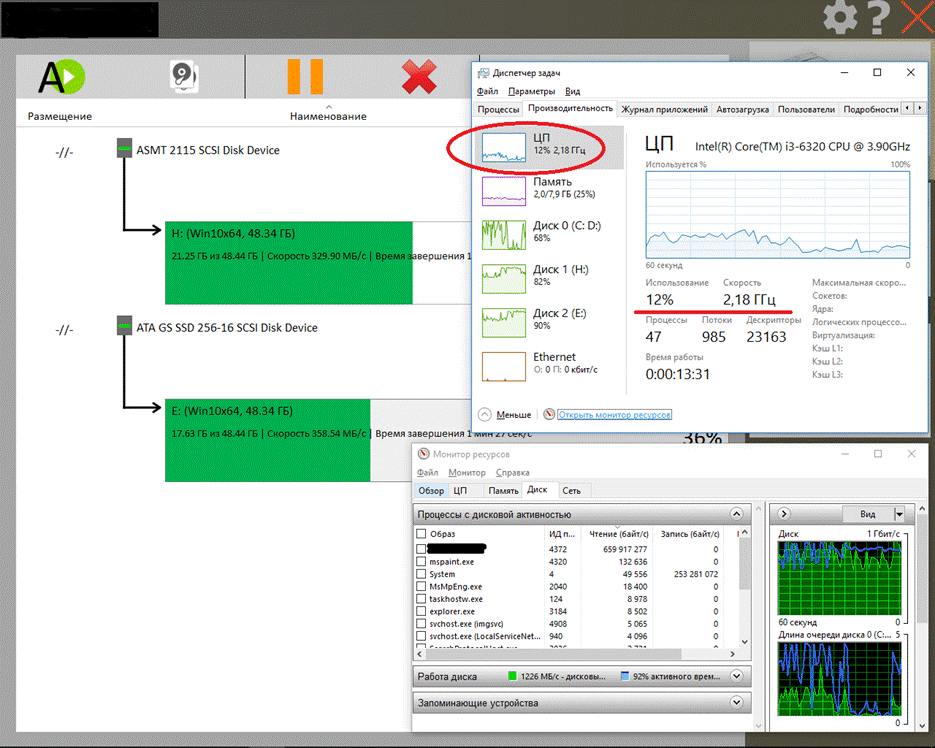
Одновременно копируется и сжимается два идентичных диска на скорости 320-350мБ/сек. каждый, но при этом загрузка процессора и его частота работы практически не изменилась, по сравнению с копированием одиночного диска.
5. Выводы
1. Реализованный алгоритм компрессии позволяет создавать системы сжатия информации работающие на скорости до 10ГигаБайт/сек для одного процессорного ядра и применять их в многопоточных системах создания резервных копий.
2. Степень компрессии может значительно превосходить существующие системы сжатия информации, для разнородных данных типа «системный диск» степень компрессии находиться на уровне пятикратного сжатия полного объема диска и двукратного сжатия реальных данных на этом диске.
3. Скоростные параметры нового алгоритма компрессии позволяют эффективно сжимать дампы дисковых систем в фоновом режиме, не загружая процессор.
4. За счет уплотнения канала передачи данных повышается скорость работы таких конечных систем как:
- Операционных систем за счет ускорения своп систем (файлов подкачки ОС)
- Исполняемых файлов за счет ускорения загрузки
- Гипервизоров в части загрузки/выгрузки образов виртуальных машин.