
Нестандартная форензика от JSOC CERT: самые интересные случаи 2019 года
На прошедшем PHDays 9 ИБ-сообщество активно обсуждало актуальные киберугрозы и свежие кейсы из жизни форензеров. Эксперты из JSOC CERT делятся методами расследования наиболее сложных инцидентов 2019 года.

Автор: Виктор Сергеев, старший инженер технического расследования JSOC CERT «Ростелеком-Солар»
Как обнаружить следы вредоноса, если он самоудалился, а сисадмин уже затер неразмеченное пространство диска? Каким образом выявить того, кто стер важные бизнес-документы с файлового сервера, на котором толком не настроено логирование? Наконец, как может злоумышленник без проникновения в сеть получить пароли от десятков не связанных между собой доменных учеток? Да, нам в JSOC CERT скучать некогда.
Будни JSOC CERT
Часто нам приходится оценивать фактическую компрометацию сети клиентов, для этого мы проводим ретроспективный анализ жестких дисков и образов памяти, реверс-инжиниринг вредоносного ПО, а при необходимости — экстренно разворачивать мониторинг и сканировать хосты на наличие индикаторов компрометации и следов хакинга. В свободное время мы пишем детальные конспекты, методики и playbooks — по сути инструкции, помогающие масштабировать даже комплексные расследования, т.к. по ним можно действовать полуавтоматически.
Во время расследования часто приходятся разбирать образы дисков и памяти, чтобы найти там активное вредоносное ПО. Чтобы процесс был предсказуемым и объективным, мы формализовали и автоматизировали несколько методик по ретроспективному анализу дисков, а за основу взяли уже ставшую классической методику SANS — в оригинальной версии она достаточно высокоуровневая, но при правильном применении позволяет с очень высокой точностью обнаруживать активное заражение.
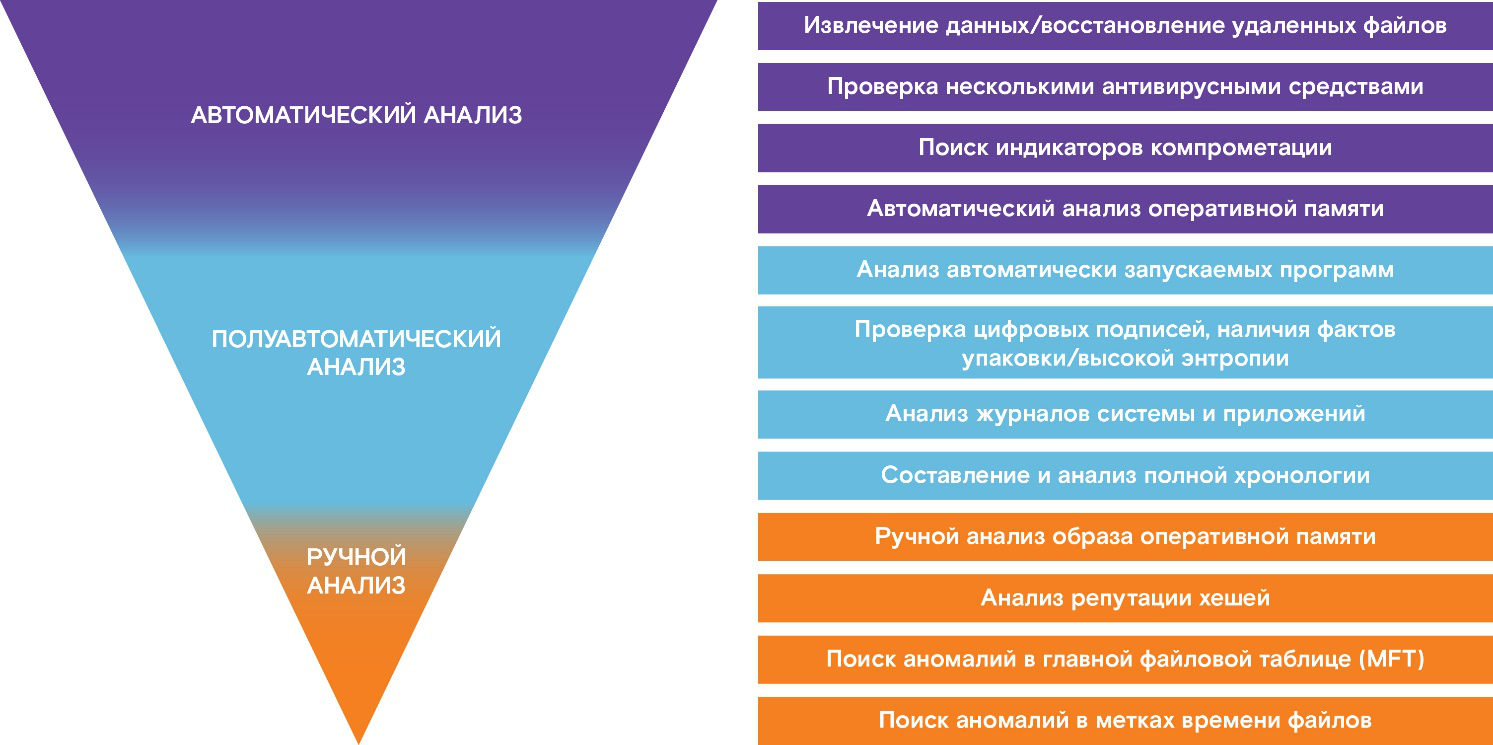
Понятно, что для выполнения всех проверок требуются время и глубокие экспертные знания об особенностях работы различных компонентов операционных систем (да и софта специализированного нужно немало).
Как упростить проверку диска на наличие активного заражения? Делимся лайфхаком — его можно проверить динамически (как в песочнице), для этого:
1) побитово скопируйте жесткий диск подозрительного хоста;
2) сконвертируйте полученный dd-образ в формат VMDK с помощью этой утилиты;
3) запустите VMDK-образ в Virtual Box/ VMware;
4) и проведите анализ как на живой системе, уделяя внимание трафику.
Но всегда будут инциденты, для которых детальные инструкции не написаны и методики не автоматизированы.
Кейс 1. Как мы нашли удаленный вредонос и спасли бухгалтера
Клиент попросил нас проверить компьютер бухгалтера на наличие вредоносного ПО: кто-то провел несколько платежных поручений на неизвестный адрес. Бухгалтер утверждал, что он тут ни при чем и что компьютер до этого вел себя странно: мышка иногда буквально сама двигалась по экрану. Собственно, эти показания нас и попросили проверить. Загвоздка была в том, что нацеленный на 1C троянец сделал свои грязные делишки и самоудалился, а после заражения прошел почти месяц — за это время старательный эникейщик установил довольно много софта, перетерев неразмеченное пространство диска и тем самым сведя к минимуму вероятность успеха в расследовании.
В подобных случаях может помочь только опытный, придирчивый к деталям аналитик и обширная, автоматически пополняемая база Threat Intelligence. Так, в ходе проверки папки автозагрузки внимание привлек подозрительный ярлычок, указывающий на якобы утилиту по обновлению антивируса:

Само тело троянца с диска восстановить, к сожалению, не удалось, зато в кэше Superfetch были обнаружены факты запуска утилиты удаленного администрирования из той же папки:

Сопоставив их с временем инцидента, мы доказали, что в краже денег виновен вовсе не бухгалтер, а внешний злоумышленник.
Кейс 2. Кто удалил файлы?
Большая часть наших расследований и реагирований на инциденты так или иначе связана с выявлением вредоносного ПО, целевыми атаками с применением многомодульных утилит и тому подобными историями, где есть внешний злоумышленник. Однако иногда бывают куда более приземленные, но не менее интересные расследования.
У клиента стоял самый обычный старенький файловый сервер, общие папки которого были доступны нескольким департаментам. На сервере лежало множество весьма важных бизнес-документов, которые кто-то взял и удалил. Спохватились поздно — после того как бэкап перезаписался. Стали искать виноватых.
Если вы когда-нибудь пытались гуглить, как определить, кто из пользователей удалил файл, то наверняка натыкались на советы, которые сводятся к тому, что все есть в логах Windows, если их правильно настроить заранее:
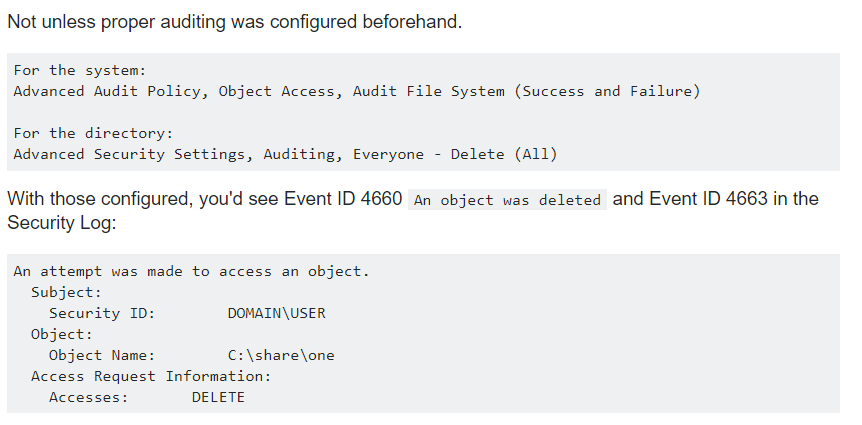
Источник: https://serverfault.com/questions/881344/how-to-find-out-who-deleted-files-windows-server-2012-r2
Но в реальности аудит файловой системы мало кто проводит, банально потому что файловых операций много и журналы будут быстро перетираться, к тому же для хранения логов нужен отдельный сервер.
Поставленную задачу мы решили разбить на две: во-первых, определить, КОГДА были удалены файлы; во-вторых, — КТО именно подключался к серверу в момент удаления. Если вы имеете представление об особенностях работы NTFS, то знаете, что в большинстве реализаций этой файловой системы при удалении файла место, которое он занимал, помечается как свободное, а его метки времени не меняются. Поэтому, на первый взгляд, время удаления установить нельзя.
Однако в файловой системе есть не только файлы, но и папки. При этом у каждой из папок имеется специальный атрибут $INDEX_ROOT, описывающий в виде B-дерева ее содержимое. Естественно, удаление файла изменяет атрибут $INDEX_ROOT папки и тем самым изменяет ее временнЫе метки, в частности, в структуре $STD_INFO. Таким образом можно определить примерное время удаления большого количества файлов и папок, по аномалии в MFT (главной файловой таблице):
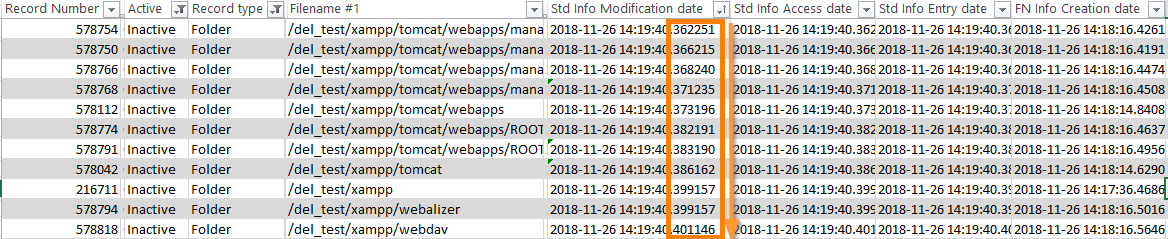
Выяснив, когда примерно были удалены файлы, можно попытаться узнать, кто в этот момент работал на севере, чтобы сузить круг подозреваемых. На ум приходят следующие способы:
1) по журналам самого сервера — по событиям с EventID 4624/4625 видно, когда пользователь подключился и отключился;
2) по журналам контроллера домена — EventID 4768 позволяет определить, что конкретный пользователь запрашивал доступ к серверу;
3) по трафику — netflow/журналам внутренних маршрутизаторов — можно прикинуть, кто активно общался по сети с данным сервером по smb.
В нашем случае этих данных уже не было: прошло слишком много времени, логи ротировались. На этот случай есть еще один не очень надежный, но все же метод, а точнее ключ реестра — Shellbags. В нем сохраняется информация, в частности, о том, какой вид был у папки, когда пользователь ее посещал последний раз: таблица, список, крупные значки, мелкие значки, содержимое и т.д. И этот же ключ содержит метки времени, которые можно с высокой долей уверенности интерпретировать как время последнего посещения папки.
Метод нашелся, дело осталось за малым — собрать реестры с нужных хостов и проанализировать их. Для этого нужно:
1) определить по доменной группе, кто имел доступ к папке (в нашем случае оказалось около 300 пользователей);
2) собирать реестры со всех хостов, на которых работали эти пользователи (просто так этого не сделаешь, нужна специальная утилита для работы с диском напрямую, например, https://github.com/jschicht/RawCopy);
3) загрузить все реестры в Autopsy и воспользоваться Shellbags plugin;
4) Profit!

Конкретно в данном инциденте время удаления файлов совпало со временем посещения корня удаленной папки одним из пользователей, что позволило нам сузить круг подозреваемых с 300 человек до 1.
Что произошло дальше с этим сотрудником — история умалчивает. Знаем только, что девушка созналась, что сделала это случайно, и продолжает работу в компании.
Кейс 3. Угнать пароль за пару секунд (и даже быстрее)
В сеть клиента, попросившего нас помочь, злоумышленник проник через VPN и сразу же был обнаружен. Что не удивительно, ведь сразу после входа он начал сканировать подсеть сканером уязвимостей — Honeypot замигал, как новогодняя ёлка.
После блокировки учетной записи сотрудники службы безопасности клиента стали разбирать журналы VPN и увидели, что для проникновения злоумышленник использовал больше 20 разных доменных учёток (с большинством он успешно логинился, а для некоторых аутентификация завершилась неуспешно). И встал логичный вопрос: а откуда он узнал пароли от этих учетных записей? Для поиска ответа и были приглашены эксперты JSOC CERT.
Расследование мы начали с формирования гипотез, которые далее проверяли в порядке уменьшения их вероятности. В первую очередь выписали типовые векторы кражи доменных учетных записей:
· Bruteforce
· Mimikatz или аналогичные техники
· Keylogger
· Phishing
· NTLM-hash harvesting (например, https://github.com/CylanceSPEAR/SMBTrap) или аналогичные сетевые атаки.
Проверили множество версий, но нигде не было даже намека на атаку. Внутренний голос и здравый смысл подсказывали: что-то тут не так — нужно сделать шаг назад и посмотреть на картину шире.
Действительно, на первый взгляд, все эти учётки никак не связаны между собой. Их владельцы из разных, территориально разделённых департаментов. Обычно пользуются не пересекающимся множеством сервисов компании. Даже уровень ИТ-грамотности разный. Да, одного шага назад оказалось недостаточно — нужен был еще один.
К этому времени мы успели собрать огромное количество логов из разных систем предприятия и выделить следы, оставленные злоумышленником. Стали анализировать, где он засветился (напомню: он активно сканировал внутреннюю сеть компании). Заметили, что на фоне равномерно распределённого сетевого шума от эксплойтов есть аномально большое количество запросов к сервису по восстановлению паролей. Сервису, доступному из Интернета.
Если вы занимаетесь мониторингом событий безопасности, то наверняка знаете, что анализ попыток атак на доступный извне сервер часто не имеет смысла из-за интернет-шума: отличить действительно серьезные атаки от многочисленных попыток script-kiddie в общем случае непросто. Но не всегда.


Проведя некоторое время над журналами web-сервиса, мы смогли выделить следующие атаки на сервис:
1) сканирование с помощью Acunetix,
2) сканирование с помощью SQLmap,
3) большое количество запросов к одной странице.
Третья атака, с первого взгляда, похожа на брут логинов пользователей. Но это не так, потому что сервис от этого защищен, как минимум, тем, что пароли хранятся в хешированном с солью виде — или нет? Нужно было быстро это проверить.
На картинке ниже представлена типовая схема работы сервиса по сбросу паролей:
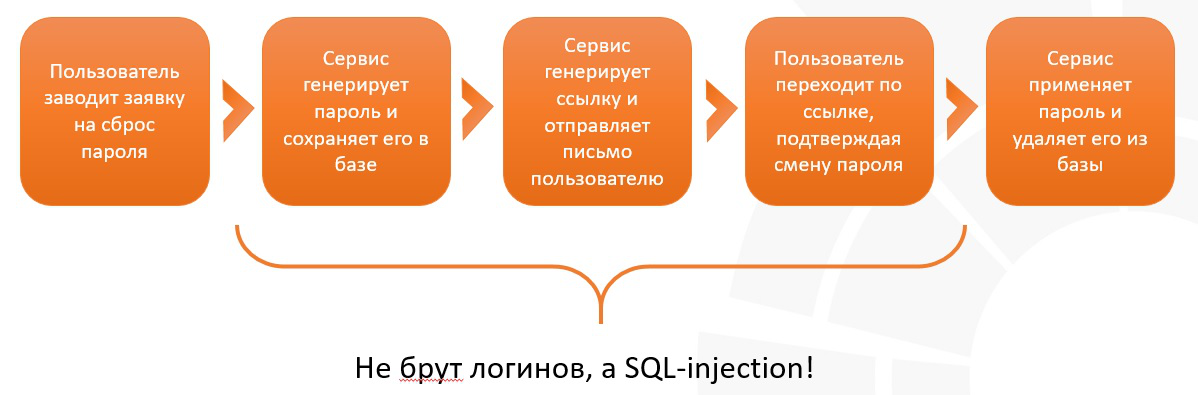
Пароли не всегда хранятся в защищенном виде — есть момент времени, когда они находятся в открытом доступе — сразу после заведения заявки и до ее исполнения! Большое количество запросов к одной странице оказалось не брутфорсом и не сканированием, а высокочастотными запросами с SQL-инъекцией, целью которых было выуживание паролей в момент их смены.
Вот так, проведя моделирование атаки на сервис, сопоставив информацию из логов web-сервера, журналов смены паролей и нескольких сетевых устройств, мы отыскали точку проникновения злоумышленника на предприятие.
В заключение хочу дать совет коллегам: проверяйте raw data — там много интересного.
мы в MAX