
Конец Geoguessr или инструмент шпиона? Новая модель GeoVista найдет вас, даже если вы не ставили геотег

Ваши публичные фото больше не анонимны — новый ИИ GeoVista сопоставляет их с данными из сети и почти безошибочно находит точку съёмки.

Китайские исследователи представили GeoVista — открытую ИИ-модель для определения локации по фотографии, которая по точности уже подбирается к уровню коммерческих систем вроде Gemini 2.5 Flash. В отличие от многих конкурентов, GeoVista не ограничивается анализом изображения: модель сама выходит в интернет, увеличивает нужные фрагменты кадра и сверяется с публичными источниками, чтобы максимально точно определить место съёмки.
GeoVista разработана Tencent совместно с несколькими китайскими университетами. В основе системы — два ключевых инструмента. Первый позволяет «зумить» отдельные участки изображения, чтобы разглядеть вывески, дорожные знаки, архитектурные детали и другие важные мелочи. Второй запускает веб-поиск и подтягивает до десяти релевантных источников с площадок вроде Tripadvisor, Instagram*, Facebook*, Pinterest и Wikipedia. Модель сама решает, когда увеличить картинку, а когда обратиться к сети.

GeoVista последовательно увеличивает участки изображения и запрашивает данные из онлайн-источников, пока не определит точное местоположение (Wang et al)
Авторы работы называют интеграцию с веб-поиском главным преимуществом GeoVista по сравнению с другими подходами. Пока модели вроде Mini-o3 или DeepEyes от ByteDance в основном сосредоточены на анализе и трансформации самих изображений, GeoVista активно добывает внешние данные. При этом в статье не уточняется, какой именно поисковый провайдер используется «под капотом».
Фактически GeoVista действует как агент: модель по шагам увеличивает отдельные фрагменты кадра, формулирует запросы, сверяется с онлайн-источниками и обновляет гипотезы о возможной локации, пока не сойдётся на наиболее вероятном месте. В качестве базовой архитектуры исследователи взяли Qwen2.5-VL-7B-Instruct и обучали систему в два этапа.
На первом этапе, в режиме контролируемого обучения, модели показали около 2000 тщательно отобранных примеров с разбором рассуждений и использованием инструментов. Коммерческие ИИ-модели генерировали образцы вызова инструментов и объяснения, а авторы собрали их в многоуровневые цепочки рассуждений, чтобы научить GeoVista базовой логике и правильному применению зума и поиска.
Затем последовал этап обучения с подкреплением на 12 000 примеров. Здесь исследователи ввели собственную систему вознаграждений, которая поощряет максимальную географическую точность: правильный ответ на уровне города ценится выше, чем попадание в провинцию или страну. Это стимулирует модель не просто угадывать регион, а добиваться максимального приближения к конкретной точке.
На созданном командой бенчмарке GeoBench GeoVista показала 92,64 % точности на уровне страны, 79,60 % — на уровне провинции и 72,68 % — на уровне города. Лучше всего модель чувствует себя на панорамных снимках (79,49 % точности по городам) и обычных фотографиях (72,27 %), а вот спутниковые изображения остаются для неё самым сложным режимом — 44,92 % попаданий по городам.
По тем же тестам коммерческий Gemini 2.5 Pro на уровне города набрал 78,98 %, GPT-5 — 67,11 %, а Gemini 2.5 Flash — 73,29 %. Открытые модели заметно отстают: Mini-o3-7B смогла набрать лишь 11,3 %. Авторы отмечают, что недавно анонсированный Gemini 3 может изменить расстановку сил в будущих сравнениях, но текущие результаты уже показывают: открытый GeoVista-7B вплотную приблизился к лучшим закрытым системам искусственного интеллекта по точности геолокации.
Если смотреть не на административные единицы, а на расстояние до реальной точки съёмки, то в 52,83 % случаев предсказания GeoVista оказываются ближе чем в 3 км от настоящего места, с медианным отклонением 2,35 км. Для сравнения: Gemini 2.5 Pro попадает в радиус 3 км в 64,45 % случаев с медианой около 800 метров, а GPT-5 — в 55,12 % случаев при медианном расстоянии 1,86 км. То есть коммерческие модели пока точнее, но отрыв уже не выглядит недосягаемым.
Эксперименты по «выключению» частей обучения подтвердили, что обе фазы критически важны. Без первого этапа с контролируемыми примерами модель начинала давать слишком короткие ответы и почти не использовала инструменты, что резко снижало точность. Пропуск обучения с подкреплением приводил к схожему провалу. При этом многоуровневая система вознаграждений оказалась ключевой для эффективного использования географических данных на разных уровнях. Интересная деталь: доля некорректного использования инструментов снизилась на этапе RL, хотя специально под это метрику не оптимизировали. А увеличение объёма данных — с 1500 до 3000, 6000 и 12 000 примеров — давало устойчивый рост качества.
Вместе с моделью команда представила и сам GeoBench — датасет из 1142 изображений высокого разрешения из 66 стран и 108 городов. В него входят 512 обычных фотографий, 512 панорам и 108 спутниковых снимков, причём каждое изображение имеет разрешение не менее одного мегапикселя. Система оценки по шагам проверяет корректность указанных страны, провинции и города, а затем автоматически геокодирует адрес и сравнивает полученные координаты с эталонными.
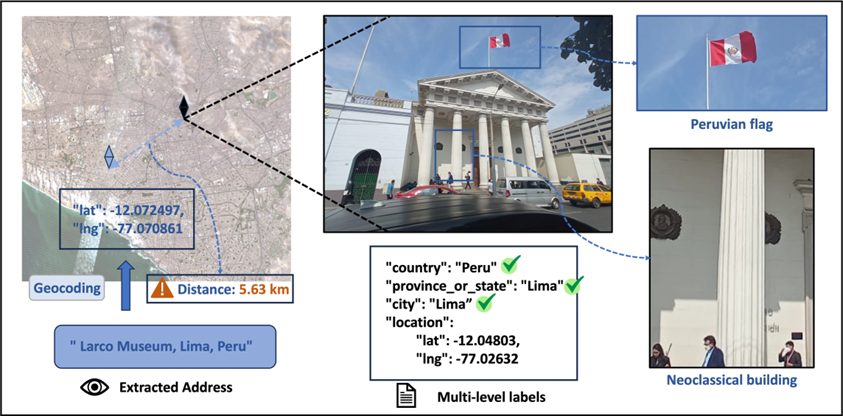
GeoBench проверяет названия стран, провинций и городов, а затем автоматически геокодирует данные для сравнения с контрольными координатами (Wang et al)
Главное отличие GeoBench от существующих наборов вроде OpenStreetView-5M или GeoComp — строгая фильтрация. Исследователи убрали «нелокализуемые» изображения (вроде крупных планов еды или абстрактных пейзажей), а также слишком узнаваемые достопримечательности. По их мнению, в реальном интернете сложность геолокации с помощью нейросетей сильно варьируется, и бенчмарк должен отражать именно сложные случаи, а не коллекцию очевидных ответов.
GeoBench оценивает модели двумя способами: пошаговой точностью на уровнях страна–провинция–город и метриками по расстоянию, когда текстовые ответы переводятся в координаты, а затем вычисляется отклонение от эталонной точки. Вес модели, исходный код и сам бенчмарк уже доступны на странице проекта.
Авторы работы напрямую не обсуждают риски злоупотреблений, но вывод напрашивается сам собой: любой, кто публикует свои фотографии в открытом доступе, должен исходить из того, что ИИ-модели всё лучше умеют определять место съёмки с высокой точностью. Это делает вопросы приватности и анонимности в сети ещё более чувствительными.
* Компания Meta и её продукты (включая Instagram, Facebook, Threads) признаны экстремистскими, их деятельность запрещена на территории РФ.