
Тестируют все, побеждают одни: Chatbot Arena заподозрили в подыгрывании элите
Новая коррупция — ИИ-бенчмарки.

Платформа Chatbot Arena, которая давно считается эталоном в сравнении языковых моделей, оказалась в центре скандала. Новое исследование, подготовленное сотрудниками Cohere, Stanford, MIT и AI2, обвиняет её создателей - организацию LM Arena - в систематической помощи крупнейшим ИИ-компаниям в обходе правил честного тестирования. Речь идёт о скрытом доступе к приватным испытаниям и умолчании о слабых результатах отдельных моделей.
По словам вице-президента Cohere по исследованиям ИИ Сары Хукер, лишь ограниченное число компаний, включая Meta*, OpenAI, Google и Amazon, получали возможность тестировать десятки вариантов своих моделей до их публичного запуска. При этом худшие версии просто не публиковались, а лучшие оказывались в топе рейтингов - при полном неведении конкурентов о подобных возможностях.
Созданная в 2023 году как академический проект, Chatbot Arena быстро стала популярной площадкой для тестов моделей на основе голосования пользователей, выбирающих лучший из двух анонимных ответов. Но, как утверждают авторы исследования, принципы прозрачности оказались нарушены. Meta, например, протестировала 27 вариантов Llama 4 на платформе в первом квартале 2025 года, но в публичном пространстве фигурировала только одна - и именно она взлетела в рейтинге.
В LM Arena обвинения называют «неверными» и указывают на «сомнительные методы анализа». По заявлению сооснователя платформы Айона Стоики, никакого предпочтения одним компаниям не было - просто некоторые отправляли больше моделей на тестирование, чем другие. Но это объяснение не устраивает авторов исследования, которые утверждают, что подобный «приватный доступ» вообще не был доступен большинству участников.
Для анализа команда исследователей изучила более 2,8 миллиона «дуэлей» моделей за пять месяцев. Они пришли к выводу, что у компаний, таких как Meta и OpenAI, модели гораздо чаще появлялись в поединках, что дало им больше статистики и данных. Это, в свою очередь, могло увеличить точность их моделей в сопутствующем бенчмарке Arena Hard до 112%.
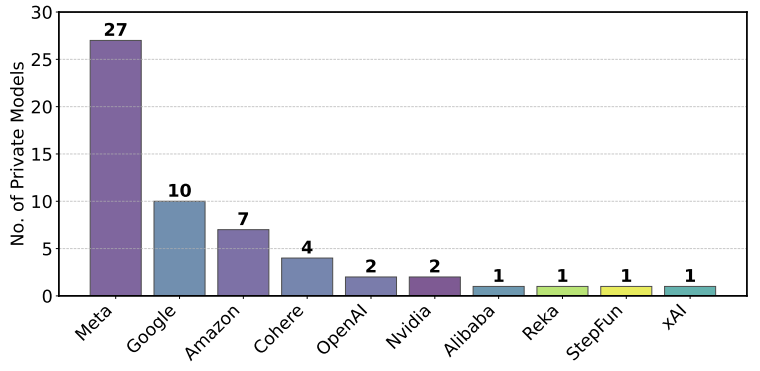
Количество моделей, протестированных в частном порядке (январь–март 2025 г.). Наибольшее количество частных заявок приходится на Meta, Google и Amazon, причем только Meta протестировала 27 анонимных моделей только в марте (arxiv.org)
LM Arena, в свою очередь, заявила, что Arena Hard и Chatbot Arena не связаны напрямую, а различия в частоте тестов - результат выбора самих участников. Однако критика усиливается на фоне того, что вскоре после запуска Llama 4 стало известно, что Meta оптимизировала одну из версий модели исключительно под требования Chatbot Arena - а затем вовсе не выпустила эту версию в публичный доступ. Результат: высокие позиции в рейтинге за счёт модели-приманки.
Исследователи призывают LM Arena ограничить число приватных тестов, публиковать все полученные результаты и уравнять частоту появления моделей в поединках. Представители LM Arena отреагировали частично: они заявили, что готовы обновить алгоритм подбора моделей, но по-прежнему отказываются публиковать оценки нереализованных моделей.
Дополнительное внимание вызывает и то, что LM Arena недавно сообщила о планах стать коммерческой компанией и привлечь инвестиции. В этом контексте требования к прозрачности становятся особенно важными: любая приватность в оценке ИИ-моделей может повлиять на рынок, технологии и доверие сообщества.
* Компания Meta и её продукты (включая Instagram, Facebook, Threads) признаны экстремистскими, их деятельность запрещена на территории РФ.