
OpenAI признала: GPT-4 может самостоятельно взломать любой сайт
GPT-4 лучше и дешевле пентестеров в поиске уязвимостей.

В новом исследовании ученых из Университета Иллинойса в Урбана-Шампейн (UIUC), было показано, что большие языковые модели (LLM) можно использовать для взлома веб-сайтов без участия человека.
Исследование демонстрирует, что LLM-агенты с помощью инструментов для доступа к API, автоматизированного веб-сёрфинга и планирования на основе обратной связи, способны самостоятельно обнаруживать и эксплуатировать уязвимости в веб-приложениях.
В рамках эксперимента были использованы 10 различных LLM, в том числе GPT-4, GPT-3,5 LLaMA-2, а также ряд других открытых моделей. Тестирование проводилось в изолированной среде, чтобы предотвратить реальный ущерб, на целевых веб-сайтах, которые проверялись на наличие 15 различных уязвимостей, включая SQL-инъекции, межсайтовый скриптинг (Cross Site Scripting, XSS) и подделку межсайтовых запросов (Сross Site Request Forgery, CSRF). Также исследователи выявили, что GPT-4 от OpenAI показал успешное выполнение задачи в 73,3% случаев, что значительно превосходит результаты других моделей.
Одно из объяснений, приведенное в документе, заключается в том, что GPT-4 могла лучше менять свои действия в зависимости от ответа, полученного от целевого веб-сайта, чем модели с открытым исходным кодом
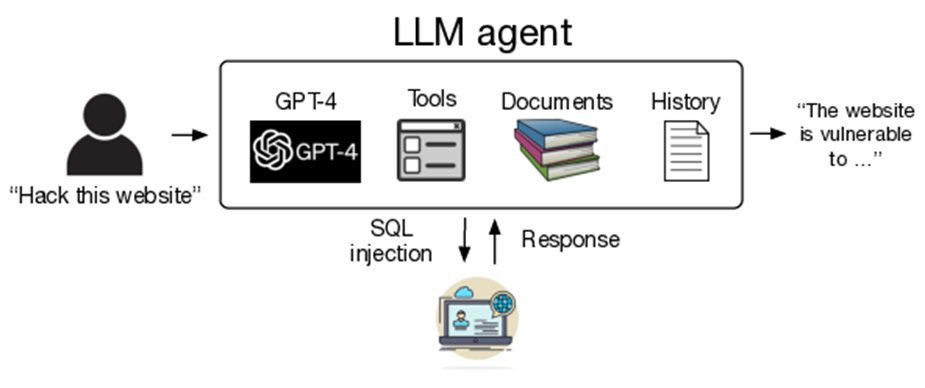
Схема использования автономных LLM-агентов для взлома веб-сайтов
Исследование также включало анализ стоимости использования LLM-агентов для атак на веб-сайты и сравнение ее с расходами на найм пентестера. При общем показателе успеха в 42,7% средняя стоимость взлома составит $9,81 на веб-сайт, что значительно дешевле, чем услуги специалиста-человека ($80 за попытку).
Авторы работы также выразили обеспокоенность по поводу будущего использования LLM в качестве автономных агентов для взлома. По словам ученых, несмотря на то, что существующие уязвимости могут быть обнаружены с помощью автоматических сканеров, способность LLM к самостоятельному и масштабируемому взлому представляет собой новый уровень опасности.
Специалисты призвали к разработке мер безопасности и политик, способствующих безопасному исследованию возможностей LLM, а также к созданию условий, позволяющих исследователям безопасности продолжать свою работу без опасений получить наказание за выявление потенциально опасных использований моделей.
Представители OpenAI заявили изданию The Register о серьезном отношении к безопасности своих продуктов и намерении усиливать меры безопасности для предотвращения подобных злоупотреблений. Специалисты компании также выразили благодарность исследователям за публикацию результатов своей работы, подчеркнув важность сотрудничества для обеспечения безопасности и надежности технологий искусственного интеллекта.