
Если коротко, Роскомнадзор не «нажимает одну кнопку и выключает сайт». Ограничение доступа почти всегда начинается с правового основания, потом запись попадает в контур блокировки, после чего хостинг, владелец ресурса и оператор связи получают свои роли. Уже на последнем шаге в ход идут сетевые методы: DNS, IP, фильтрация по домену, DPI, ТСПУ, сбросы соединений или замедление трафика.
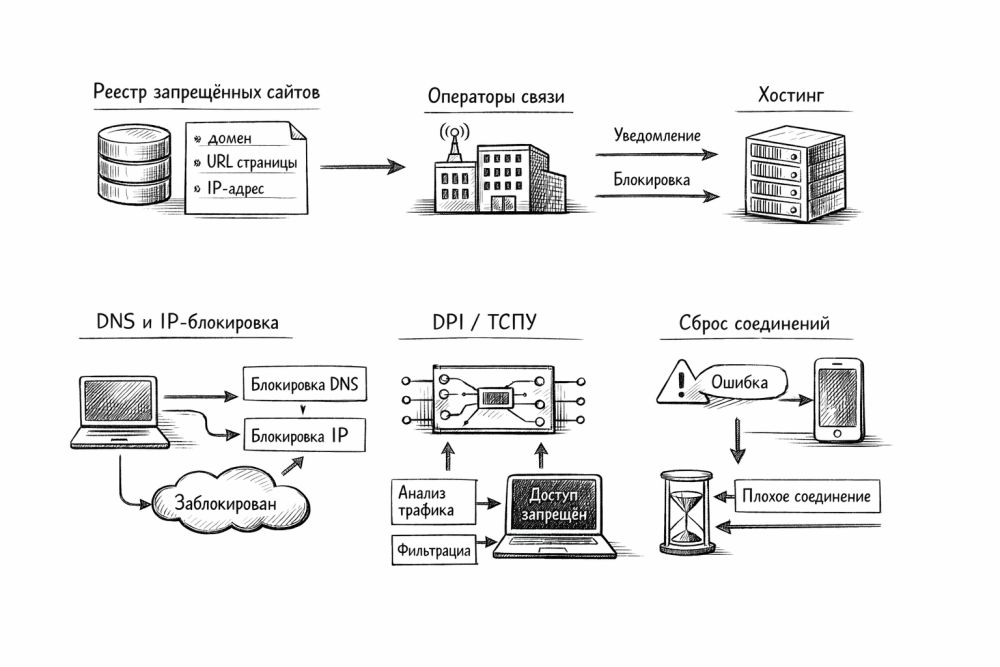
Поэтому вопрос «как блокируют» лучше делить на три слоя. Первый слой отвечает на вопрос, кто и по какому основанию решил ограничить доступ. Второй показывает, как решение доезжает до хостинга и операторов. Третий объясняет, почему у пользователя сайт либо не открывается совсем, либо грузится через раз, либо внезапно работает по одному провайдеру и ломается по другому. Без такого деления разговор быстро скатывается в мифы.
Текст носит обзорный характер, не является инструкцией по обходу ограничений и не заменяет юридическую консультацию. При работе с любыми ресурсами и публикациями нужно соблюдать законы РФ. Распространять запрещенный контент, помогать обходить блокировки или строить на этом «лайфхаки» нельзя.
Правовая основа блокировок Роскомнадзора и роль единого реестра
Базовая схема до сих пор опирается на статью 15.1 закона «Об информации». В ней прямо сказано, что для ограничения доступа создается единый реестр, куда могут вносить доменные имена, указатели страниц и сетевые адреса. Уже по этой формулировке видно главное: российская модель изначально строилась не только вокруг «сайта целиком», а вокруг трех разных объектов блокировки - домена, конкретной страницы и IP-адреса.
Дальше работает не магия, а вполне приземленный конвейер. Владелец ресурса или хостинг-провайдер получает уведомление, материал предлагают удалить, и только если контент не убрали, в дело вступает более жесткая стадия с ограничением доступа у операторов. Официальный реестр как раз и нужен для такой передачи данных между регулятором, хостингом и операторами.
Здесь уже видна первая неочевидная вещь. Роскомнадзор технически блокирует не только «площадки», но и отдельные точки внутри инфраструктуры. На бумаге можно целиться в страницу. На практике точность зависит не от красивой формулировки в документе, а от того, что сеть реально способна увидеть и отрезать.
Как выглядит блокировка по шагам
В упрощенном виде цепочка такая. Сначала появляется основание: решение суда, решение уполномоченного органа или иная процедура по профильной норме. Потом сведения попадают в реестр или в смежный механизм ограничения. После этого либо сам ресурс удаляет материал, либо доступ режут на стороне хостинга, либо оператор ограничивает трафик у абонентов.
Исторически долго работала логика «оператор получил выгрузку - оператор режет доступ своими средствами». Такая схема никуда не исчезла, но в последние годы поверх нее вырос второй этаж: централизованное управление через ТСПУ. Поэтому современная блокировка в России - уже не просто список IP и доменов, а смесь реестров, фильтрации трафика и централизованных политик на сети операторов.
Какие технические методы блокировки применяют на практике
| Метод | Что режут | Когда помогает | Главный минус |
|---|---|---|---|
| DNS-блокировка | Разрешение доменного имени | Когда пользователь опирается на DNS провайдера | Сам по себе метод уже редко достаточен |
| IP-блокировка | Сетевой адрес или подсеть | Когда ресурс сидит на выделенном IP или регулятор готов к грубому отсечению | Часто задевает чужие сайты и сервисы на той же инфраструктуре |
| HTTP/URL-блокировка | Конкретный путь страницы | Когда трафик виден без шифрования или есть содействие площадки | С HTTPS путь после домена обычно скрыт |
| DPI и ТСПУ | Домен, SNI, сигнатуры протоколов, тип трафика, часть метаданных | Когда нужен более точный контроль, чем у DNS и IP | Дорого, сложно, иногда дает побочные сбои |
| Замедление и сброс соединений | Отдельный сервис, приложение или класс трафика | Когда полная блокировка слишком груба или неудобна | Пользователь видит не явный запрет, а странную деградацию |
DNS-блокировка: самый старый и самый понятный слой
DNS - телефонная книга интернета. Пользователь вводит домен, система спрашивает, какому IP соответствует имя, и только потом строит соединение. Если на этом шаге вернуть неправильный ответ, пустой ответ или ошибку, сайт для обычного пользователя как будто исчезает.
Плюс DNS-блокировки в дешевизне. Оператору не нужно глубоко разбирать трафик, достаточно контролировать резолверы и ответы. Минус тоже очевиден: DNS решает только вопрос «как узнать адрес», но не решает вопрос «что делать с пакетом, когда адрес уже известен». Поэтому в эпоху внешних DNS-сервисов, DoH, DoT и других зашифрованных схем один DNS давно перестал быть универсальным оружием.
Именно поэтому разговор о блокировках на уровне DNS быстро упирается в более широкий контроль над протоколами разрешения имен. Публичные примеры таких экспериментов уже были, о чем писали в разборе про блокировку DNS-сервисов Google и Cloudflare. Логика тут простая: если имя сайта нельзя увидеть на шаге DNS, точечная фильтрация осложняется и регулятору приходится уходить глубже в сеть.
IP-блокировка: грубо, быстро, с большими побочками
IP-блокировка режет доступ к сетевому адресу или диапазону адресов. На маршрутизаторах и межсетевых экранах такой механизм выглядит почти банально: пакет до нужного адреса либо не пропускают, либо уводят в «черную дыру». Для регулятора и оператора такая схема удобна, когда нужен быстрый и массовый результат.
Проблема в том, что интернет давно живет на общих облаках, reverse proxy и CDN. Один IP может обслуживать сотни и тысячи сайтов. Поэтому удар по адресу часто задевает не только цель, но и чужие ресурсы. Чем активнее сайты прячутся за общей инфраструктурой, тем выше цена такой грубой фильтрации.
Отсюда один из самых частых пользовательских эффектов: «не открывается не только один сайт, но и кусок интернета рядом с ним». Никакой мистики здесь нет. Сработала не точная адресная блокировка, а отсечение общего сетевого сегмента.
Блокировка по URL и по домену: почему с HTTPS все стало сложнее
Когда трафик шел по обычному HTTP, оператор мог увидеть полный адрес страницы, включая путь после домена, и отрезать ровно нужный URL. Такая точность всем нравилась. Регулятору не нужно было рубить весь сайт, оператору не нужно было ловить побочку, владельцу ресурса было проще понять претензию.
С HTTPS путь страницы шифруется. Для сети часто остается видимым только IP, порт, часть служебных признаков и, в ряде случаев, доменное имя из рукопожатия TLS. Поэтому современная точечная блокировка одной страницы внутри HTTPS-сайта стала намного труднее. На практике из-за этого точность часто уступает место грубым мерам: блокируют весь домен, конкретный IP или сервис по косвенным признакам.
Здесь и рождается популярный миф, будто HTTPS «делает блокировку невозможной». Не делает. HTTPS хорошо скрывает содержимое и URL, но не скрывает весь сетевой контекст. Регулятор все еще может работать по IP, домену, SNI, сигнатурам протокола и поведенческим признакам трафика.
DPI и ТСПУ: современный центр тяжести блокировок
Если DNS и IP - скорее лобовые инструменты, то DPI работает умнее. Deep Packet Inspection анализирует пакеты глубже, чем обычный маршрутизатор. В российской модели такую роль играют ТСПУ - технические средства противодействия угрозам, которые после поправок 2019 года стали обязательным элементом сети крупных операторов и механизмом централизованной фильтрации.
Смысл сдвига простой. Раньше государству приходилось в большей степени рассчитывать на то, что каждый оператор сам корректно применит выгрузку и сам выстроит нужную фильтрацию. Теперь значительная часть логики уехала в централизованный слой. Для пользователя разница огромная. Блокировка все чаще зависит не от локальной аккуратности конкретного провайдера, а от того, как политика задана и обновлена в общем контуре.
Важно не путать ТСПУ с СОРМ. СОРМ - про доступ уполномоченных органов к данным связи и оперативно-разыскной контур. ТСПУ - про управление трафиком, устойчивость сети и ограничение доступа к запрещенной информации. В публичных спорах эти системы часто смешивают, но с технической и юридической точки зрения речь идет о разных задачах.
Публичным примером возможностей ТСПУ стало замедление Twitter в 2021 году. Тогда регулятор официально объявил не о «выключении сайта», а именно о замедлении доставки части контента. Позже сам механизм и роль ТСПУ разбирали, в том числе на примере этой истории.
Что реально видит DPI, а что не видит
DPI - не волшебный рентген интернета. Без расшифровки TLS такое оборудование не «читает весь сайт глазами оператора». Обычно речь идет о другом наборе данных:
- IP-адрес назначения и порт
- доменное имя, если его не скрыли на этапе TLS-рукопожатия
- HTTP Host и URL у незашифрованного HTTP
- тип протокола, ALPN, сигнатуры клиента и сервера
- длину пакетов, последовательность обмена, тайминги, характер сессии
Этого уже хватает, чтобы довольно уверенно отличать обычный веб-трафик от отдельных приложений, туннелей, некоторых прокси-схем и целых классов сервисов. Но как только сайт и протоколы начинают лучше скрывать имя ресурса и метаданные, точность падает, а риск побочных сбоев растет.
Что бывает кроме DNS, IP и «чистого» DPI
Реальная сеть любит гибриды. Поэтому между бинарными вариантами «открывается» и «заблокировано» есть целый промежуточный этаж.
Первый вариант - сброс соединения. Сессия вроде бы стартует, а потом внезапно рвется. Для пользователя картина выглядит как случайный сетевой сбой, хотя на деле это может быть вполне целенаправленное вмешательство.
Второй вариант - принудительное ухудшение работы конкретного протокола или класса данных. Так делают, когда хотят сделать сервис почти непригодным без явной таблички «доступ ограничен». Пользователь видит вечную загрузку видео, обрыв медиа, нормальную загрузку текста и странную деградацию приложения. Для сетевого инженера такой рисунок выглядит как selective drop, traffic shaping или протокольный прессинг.
Третий вариант - блокировка не самого сайта, а вспомогательного слоя: DNS-резолверов, протоколов разрешения имен, отдельных транспортов, иногда даже характерных сетевых отпечатков. Такой подход особенно удобен, когда конкретный сервис постоянно меняет домены и IP, а прямой удар не дает стабильного эффекта.
Почему у одного провайдера блок есть, а у другого будто нет
Потому что блокировка - не один рубильник на всю страну, а набор политик, которые внедряют на разных сетях с разной топологией, разными обновлениями, разной зависимостью от ТСПУ и разным запасом ручной настройки. Один оператор сильнее опирается на собственные ACL и DNS, другой - на централизованный контур, третий комбинирует оба подхода.
Добавьте сюда CDN, Anycast, кэширование DNS, мобильные и фиксированные сети, различия между IPv4 и IPv6, резервные маршруты и особенности приложений - получите знакомую картину, когда один и тот же ресурс утром не открывается у всех, днем работает у части операторов, а вечером снова ломается. Со стороны пользователя такая картина кажется хаотичной, но у хаоса обычно есть вполне инженерное объяснение.
Главные мифы о блокировках Роскомнадзора
Первый миф - «Роскомнадзор блокирует только по IP». Нет, российская модель изначально шире: в реестре фигурируют и домены, и страницы, и сетевые адреса. IP - лишь один из инструментов.
Второй миф - «DPI читает весь зашифрованный трафик». Тоже нет. DPI видит много, но не все. На HTTPS без расшифровки содержание страницы и путь URL обычно скрыты. Поэтому фильтрация идет по метаданным, доменному имени, сигнатурам и косвенным признакам.
Третий миф - «если сайт на HTTPS, заблокировать его нельзя». Можно. Просто блокировка становится менее изящной и чаще бьет по домену, IP или по характеру трафика, а не по одной конкретной странице.
Четвертый миф - «вся ответственность лежит на операторе». Уже не совсем так. Оператор по-прежнему отвечает за исполнение, но современная модель все сильнее завязана на централизованные механизмы, ТСПУ и регуляторную инфраструктуру.
Что вся эта схема значит для сайтов, сервисов и обычных пользователей
Для владельца сайта главный вывод простой: надеяться на «авось не заметят» давно бессмысленно. Если запись попала в реестр или под иной контур ограничения, вопрос быстро упирается не только в жалобу, но и в сетевое исполнение на стороне хостинга и операторов.
Для сервисов на общей инфраструктуре плохая новость в другом. Чем сильнее площадка зависит от общих CDN, общих адресных пулов и скрытия имен хостов, тем выше риск, что в спорной ситуации по ней ударят не скальпелем, а кувалдой.
Для обычного пользователя главный practical point такой: видимый симптом не всегда подсказывает реальный метод блокировки. Ошибка DNS, обрыв TLS, бесконечная загрузка медиа, «сайт недоступен», случайный reset или деградация только на мобильной сети могут быть разными лицами одной и той же политики ограничения доступа.
Вывод: как на самом деле устроены блокировки в Рунете
Роскомнадзор блокирует доступ к запрещенному контенту не одним методом, а многослойной связкой. Юридическое основание дает команду. Реестр и смежные механизмы передают объект блокировки. Хостинг, площадка и оператор получают свои обязанности. Сеть исполняет решение через DNS, IP, домен, URL, DPI, ТСПУ, сбросы соединений или замедление.
Главный сдвиг последних лет в том, что старая модель «выгрузка плюс ручная фильтрация у оператора» никуда не исчезла, но перестала быть единственной. Современная российская практика намного сильнее опирается на ТСПУ и централизованное управление трафиком. Поэтому спор о блокировках сегодня - уже не только спор о черных списках сайтов, а разговор о том, насколько глубоко государство встроилось в сетевой слой Рунета.
FAQ
Можно ли заблокировать только одну страницу, а не весь сайт?
Да, юридически такая модель предусмотрена. Но технически она лучше работает на незашифрованном HTTP. На HTTPS точность резко падает.
Почему после блокировки иногда страдают чужие сайты?
Потому что несколько ресурсов могут жить на одном IP, в одной подсети или за одной CDN. Грубая IP-фильтрация почти всегда несет риск побочного ущерба.
Почему сервис может открываться через домашний интернет и не работать через мобильный?
У мобильного и фиксированного оператора разная топология, разная степень зависимости от централизованной фильтрации, разные DNS и разные маршруты. Отсюда разный результат.
DPI видит содержимое переписки?
Не автоматически. Без расшифровки HTTPS и защищенных протоколов DPI обычно работает по метаданным, доменному имени, сетевым признакам и сигнатурам трафика.
DNS-блокировка до сих пор актуальна?
Да, но сама по себе уже редко решает задачу полностью. Поэтому ее все чаще комбинируют с IP-фильтрацией, DPI и протокольными ограничениями.

