
Идея звучит почти идеально. Один endpoint, один формат запроса, один клиент в коде, а дальше уже можно переключать модели без переписывания приложения. На словах все просто. На практике проблема упирается в три вещи: у OpenAI, Anthropic и Google разные ключи, разные endpoint’ы и разные особенности API.
Нормальная рабочая схема давно существует. Между приложением и провайдерами ставят прослойку. Прослойка принимает запросы в одном формате, а дальше уже сама решает, куда отправить трафик: в OpenAI, Claude или Gemini. Для быстрого старта обычно хватает внешнего роутера вроде OpenRouter. Для продакшна с аудитом, бюджетами и своими ключами чаще поднимают собственный gateway, например на базе LiteLLM.
Что вообще значит «один API» для трех разных моделей
В бытовом смысле «один API» означает вот что: приложение отправляет одинаковый JSON, получает похожий JSON и не знает, кто именно обработал запрос. Внутри такой схемы можно настроить маршрутизацию по цене, скорости, типу задачи или запасному сценарию. Сегодня код пишет Claude, завтра длинные аналитические ответы отдает GPT, а массовую классификацию закрывает Gemini.
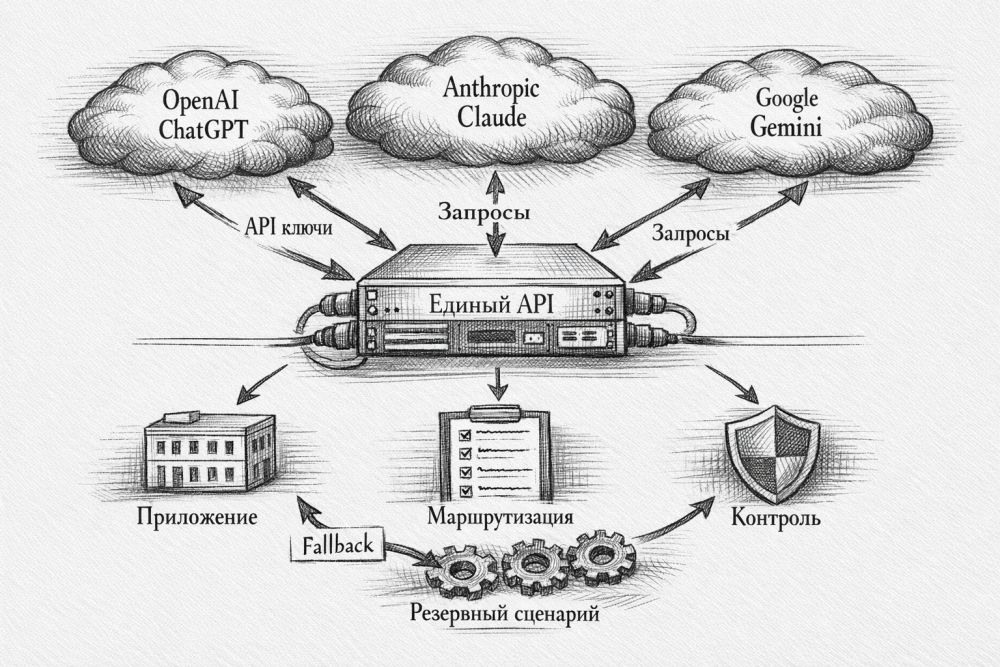
Но тут есть важная оговорка. Единый API не делает модели одинаковыми. Единый API убирает жесткую привязку к одному поставщику. Разница кажется небольшой только на словах. Архитектурно это две совершенно разные цели.
Какой путь выбрать: внешний роутер или свой gateway
| Подход | Когда подходит | Плюсы | Слабые места |
|---|---|---|---|
| Внешний роутер | MVP, прототип, быстрый тест нескольких моделей | Один ключ, один endpoint, быстрый старт, fallback между моделями | Появляется внешний посредник, часть возможностей нормализуется не идеально |
| Свой gateway | Продакшн, внутренняя платформа, сервис с чувствительными данными | Контроль над ключами, логами, лимитами, алиасами и правилами доступа | Нужно поднимать, обновлять и сопровождать сервис |
| Режим совместимости | Миграция или быстрый эксперимент | Можно оставить OpenAI SDK и поменять base URL | Совместимость неполная, на краях быстро всплывают различия |
Режим совместимости часто переоценивают. У части провайдеров уже есть совместимость с OpenAI SDK, а Gemini тоже умеет работать через OpenAI-compatible слой. Для быстрого теста такой путь удобен. Для серьезной мультивендорной схемы лучше думать не про «полную взаимозаменяемость», а про «единый вход и контролируемую маршрутизацию».
Быстрый старт: подключаем все через один внешний роутер
Если задача звучит как «хочу за час завести один endpoint и сравнить несколько моделей», внешний роутер обычно выигрывает. Клиентский код остается почти таким же, как при обычной работе с OpenAI-совместимым API.
Шаг 1. Ставим клиент
pip install openaiШаг 2. Добавляем ключ в переменную окружения
export OPENROUTER_API_KEY="ваш_ключ"Шаг 3. Создаем единый клиент
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["OPENROUTER_API_KEY"],
base_url="https://openrouter.ai/api/v1",
)Шаг 4. Описываем модели в конфиге
Здесь лучше не хардкодить реальные model slug’и по всему проекту. Названия моделей меняются, старые версии уезжают в архив, новые появляются внезапно. В боевом коде храните slug’и в конфиге, а в приложении используйте понятные алиасы.
MODELS = {
"smart": "anthropic/claude-... или openai/... или google/...",
"fast": "google/gemini-... или openai/...",
"code": "openai/... или anthropic/..."
}Такой подход выглядит скучнее, чем красивая витрина с названиями моделей, зато переживает обновления куда лучше.
Шаг 5. Пишем одну функцию для вызова любой модели
def ask(model_alias: str, prompt: str) -> str:
response = client.chat.completions.create(
model=MODELS[model_alias],
messages=[
{"role": "system", "content": "Отвечай кратко и по делу."},
{"role": "user", "content": prompt},
],
temperature=0.2,
)
return response.choices[0].message.contentПосле такого шага приложение уже не зависит от конкретного бренда модели. Зависимость переносится в конфиг. Для архитектуры это намного полезнее, чем кажется на старте.
Шаг 6. Добавляем fallback
Вот участок, где единый API начинает приносить реальную пользу. Если первая модель недоступна, отвечает слишком долго или упирается в лимит, запрос можно увести на следующую без падения всего сервиса.
payload = {
"models": [
"anthropic/claude-...",
"openai/...",
"google/gemini-..."
],
"messages": [
{"role": "user", "content": "Собери JSON со списком рисков миграции на единый API"}
],
"provider": {
"allowFallbacks": True
}
}В результате приложение перестает быть заложником одного вендора. Это и есть главная цель всей конструкции.
Продакшн-схема: поднимаем собственный gateway
Когда появляется команда, бюджеты, аудит, несколько окружений и чувствительные данные, внешний роутер уже не всегда выглядит хорошей идеей. Тогда обычно поднимают свой gateway. Схема простая: приложение ходит в ваш внутренний endpoint, а gateway уже сам вызывает OpenAI, Anthropic и Gemini по разным ключам.
Шаг 1. Устанавливаем proxy
pip install 'litellm[proxy]'Шаг 2. Готовим ключи
export OPENAI_API_KEY="sk-..."
export ANTHROPIC_API_KEY="sk-ant-..."
export GEMINI_API_KEY="..."Шаг 3. Пишем конфиг с алиасами
model_list:
- model_name: chat-smart
litellm_params:
model: anthropic/claude-...
api_key: os.environ/ANTHROPIC_API_KEY
- model_name: chat-fast
litellm_params:
model: gemini/...
api_key: os.environ/GEMINI_API_KEY
- model_name: code-main
litellm_params:
model: openai/...
api_key: os.environ/OPENAI_API_KEYЗдесь есть мелкий, но важный нюанс. Для Gemini в LiteLLM лучше явно указывать префикс gemini/, чтобы не плодить двусмысленность в конфиге.
Шаг 4. Запускаем gateway
litellm --config config.yamlШаг 5. Подключаем приложение к своему endpoint
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:4000",
api_key="локальный_служебный_ключ"
)
response = client.chat.completions.create(
model="chat-smart",
messages=[
{"role": "user", "content": "Собери план миграции backend на единый LLM gateway"}
],
)
print(response.choices[0].message.content)Преимущество такой схемы в том, что клиентский код знает только про алиасы вроде chat-fast или code-main. Какая именно модель стоит за алиасом, решаете уже вы. Перевести часть трафика на новую модель можно без переписывания приложения.
Почему единый API не делает ChatGPT, Claude и Gemini одинаковыми
Вот участок, на котором ломаются почти все презентации про «полную унификацию». Базовый chat completion действительно можно свести к одному формату. Но как только вы выходите за пределы простого чата, различия быстро возвращаются.
Первый слой различий связан с tool calling. Формально инструменты есть почти у всех, но качество следования схеме, поведение на сложных цепочках и обработка ошибок различаются. Один провайдер аккуратно держит JSON, второй начинает творить вольности, третий меняет структуру ответа на краю сценария.
Второй слой связан с системными инструкциями и служебными полями. Даже когда провайдер обещает совместимость с OpenAI SDK, совместимость обычно касается базового контура, а не всей поверхности API без остатка.
Третий слой связан с мультимодальностью, файлами, кэшированием, reasoning-параметрами и бета-функциями. Здесь различия между провайдерами уже не косметические, а архитектурные. Поэтому единый API нужно оценивать не по лозунгу «один формат на всех», а по вопросу «насколько легко поменять backend без переписывания бизнес-логики».
Что меняется для безопасности и почему аудитории SecurityLab стоит смотреть сюда внимательно
У этой схемы есть оборотная сторона. Любой внешний роутер технически видит ваши запросы, иначе роутер просто не сможет их переслать дальше. Значит, если в промптах есть внутренние документы, исходники, секреты, данные клиентов или расследовательские материалы, такой трафик уже проходит через дополнительную внешнюю точку. Для безопасников это не мелочь, а главный вопрос всей конструкции.
Отсюда следует простое правило. Для тестов, демо и не слишком чувствительных сценариев внешний роутер часто оправдан. Для боевого сервиса с закрытыми данными лучше поднимать свой gateway, убирать сырой лог запросов, разносить ключи по окружениям и проектам, а для особенно чувствительных контуров держать inference в приватной сети там, где платформа и тариф это позволяют.
Еще один неприятный риск связан не с самой моделью, а с привычками команды. Разработчики часто включают подробный debug, пишут полные промпты в логи, копируют ключи между staging и production и отправляют фронтенд напрямую в API. Потом начинается разбор полетов, где виноват вроде бы «LLM-провайдер», хотя настоящая причина намного прозаичнее.
Минимальный чеклист перед публикацией такого решения в прод
- Не отправляйте фронтенд напрямую в LLM API.
- Храните ключи в secret manager или хотя бы в переменных окружения.
- Разводите ключи по окружениям, командам и проектам.
- Используйте алиасы задач, а не реальные названия моделей в приложении.
- Логируйте стоимость, задержку, тип ошибки и маршрут вызова.
- Не храните чувствительные промпты в сыром виде дольше, чем нужно.
- Проверяйте tools, JSON mode, стриминг и файлы отдельно на каждом маршруте.
- Заранее решите, какая модель идет первой, а какая страхует отказ.
Типичные ошибки
Самая частая ошибка звучит так: «Раз API OpenAI-совместимый, значит все будет работать одинаково». Не будет. Совместимый формат запроса не гарантирует одинакового поведения модели.
Вторая ошибка проще и опаснее. В коде жестко прописывают конкретные model slug’и. Через месяц каталог обновляется, через два месяца часть маршрутов начинает вести себя иначе, а через три месяца выясняется, что половину проекта нужно править руками.
Третья ошибка уже чисто операционная. Команда берет внешний роутер как временное решение, а потом временное решение незаметно становится постоянным. В итоге сервис растет, данных становится больше, а архитектура безопасности остается на уровне первого прототипа.
Правильная цель не в том, чтобы сделать ChatGPT, Claude и Gemini одинаковыми. Правильная цель в том, чтобы сделать backend заменяемым, а приложение устойчивым к смене модели, цен, лимитов и сбоев.
Практический вывод
Если нужен быстрый результат, берите внешний роутер и один OpenAI-совместимый клиент. Такой путь хорошо подходит для MVP, пилота и сравнительных тестов. Если нужен продакшн с нормальным контролем, журналированием и безопасной работой с чувствительными данными, поднимайте собственный gateway и сразу стройте систему вокруг алиасов, маршрутов, лимитов и fallback.
Главная мысль простая. Один API полезен не потому, что стирает различия между провайдерами. Один API полезен потому, что убирает жесткую зависимость от одного вендора и дает вам свободу менять backend без капитального ремонта всего приложения.
FAQ
Можно ли использовать один OpenAI SDK для всех трех провайдеров?
Да, можно. Именно на этом и строятся внешние роутеры, compatibility-слои и многие собственные gateway.
Нужен ли отдельный ключ на каждого провайдера?
Для внешнего роутера обычно хватает одного ключа к самому роутеру. Для своего gateway чаще нужны отдельные ключи OpenAI, Anthropic и Gemini.
Одинаково ли будут работать tools, JSON и мультимодальность?
Нет. Базовый чат унифицируется относительно хорошо, а сложные сценарии лучше проверять отдельно на каждом маршруте.
Когда внешний роутер уже не подходит?
Когда появляются чувствительные данные, требования к аудиту, внутренняя политика безопасности, сложная маршрутизация и необходимость жестко контролировать ключи и логи.
Нужно ли писать реальные названия моделей в статье и коде?
Для долгоживущего гайда лучше показывать схему с алиасами и отдельно пояснять, что конкретные model slug’и нужно сверять перед запуском. Так текст стареет медленнее.

