
А мы продолжаем про дашборды в SOCах :-) Мне тут в одном чатике по SOCам задали ожидаемый вопрос, почему я расписываю дашборды про мало кому интересный аспект деятельности центра мониторинга, то есть людей, их квалификацию, компетенции (я, кстати, про дашборд о компетенциях еще не писал, но видать уже и не буду) и желание работать в компании, вместо того, чтобы показать примеры визуализации самого интересного - мониторинга и реагирования на инциденты. Попробую исправиться...
Но только попробую. Потому что тема визуализации этой темы достаточно объемна и, самое главное, зависит от целей этого самого мониторинга и реагирования. Можно ограничиться только визуализацией числа инцидентов ИБ, которые обрабатывает SOC (можно даже с динамикой изменения этого числа). Например, вот так:
А можно копнуть глубже и посмотреть соотношение открытых и закрытых инцидентов (можно добавить еще большую детализацию, если указать тип инцидента или его приоритет или увязать инциденты с аналитиками). Показанный ниже пример интересен тем, что в нем используется не гистограмма (которая для визуализации соотношения вообще не подходит) и даже не диаграмма, которая просто показывает соотношение числа открытых и закрытых инцидентов, а "бегунок", который лучше визуализирует не только соотношение, но и стремление к цели (то есть сокращение числа незакрытых инцидентов). И тут важно помнить, что мы говорим о стремлении свести к нулю не число инцидентов (это невозможно), а число именно незакрытых инцидентов.

Смотря на рекламные материалы некоторых аутсорсинговых SOCов, удивляешься, когда SOC пишет, что они за 15 минут реагируют на инцидент. Тут либо манипуляция терминами и под словом "реагирование" они понимают "принимают в обработку" (но тогда чем тут хвалиться)? Либо речь идет о непонимании реальной работы SOC, в котором время принятия инцидента в обработку может составлять минуты (пока прилетит сигнал тревоги в SIEM, пока он скоррелируется, пока он приоритезируется). Поэтому одной из важных метрик в SOC будет время принятия инцидента в обработку первой линией. Виджет, который это будет показывать, может выглядеть так:

В нем не только отображено среднее время взятия инцидента в работу (можно еще детализировать для разных типов инцидентов и аналитиков; для приоритета бессмысленно), но и указана цель этого показателя. В реальном дашборде значение времени будет отображаться зеленым, если показатель находится в заданных пределах, и красным, если он вышел за границы (можно добавить еще желтый, если считать приближение к граничному значению). Обратите внимание, что помимо среднего арифметического я также добавил медиану, так как именно она лучше отражает типичное значение времени взятия инцидента в работу.
Но этот виджет показывает нам текущее значение (за указанный интервал времени), не говоря ни слова о том, какое число инцидентов из общего их числа было взято вовремя. Для этого может подойти вот такой виджет: Опять же, зеленая/красная направленная стрелка показывает нам улучшение или ухудшение (а не рост или падение) этого показателя, а зеленый или красный цвет числа покажет, вышли ли мы за установленные целевые значения или нет. Если накапливать этот показатель в течение времени, то можно будет еще строить динамику его изменения.



Еще одним интересным виджетом может стать "занятость аналитика". Обычно мы считаем, что человек работает весь рабочий день, с 9-ти до 6-ти или с 9-ти до 9-ти или в каком-то ином режиме, в зависимости от длительности смен. На самом же деле, может оказаться так, что аналитик отлынивает от работы, много времени отдыхает, перекуривает и т.п. Поэтому занятость аналитика, которая оценивается как отношение суммарного времени, затраченного на работу с инцидентами (легко оценивается в IRP/SOAR-платформе), к общей длительности смены, является очень хорошим показателем. На виджете ниже вы видите, как его можно визуализировать. Мы видим не только текущее значение для всех аналитиков или какого-то конкретного из них, но и целевое значение. В рабочей версии виджета мы можем использовать фотографии аналитиков и цифровую дифференциацию в зависимости от попадания или нет в целевые значения.



Ну а дальше мы можем визуализировать инциденты/тикеты по различным срезам и с привязкой к разным их атрибутам.
Вообще тема визуализации метрик ИБ в виде отчетов и дашбордов сегодня очень мало кем прорабатывается. Она гораздо сложнее, чем даже просто тема измерения эффективности SOC. Ну считаете вы классические TTD/TTC/TTR. Может быть вы добавляете к ним MTTI, MTTQ, MTTV или MTTM. А может быть вы все-таки оцениваете еще и другие параметры (число переданных на L2 инцидентов, число открытых инцидентов критического уровня, точность эскалации инцидентов или число пострадавших активов/устройств). Допускаю. Но вот правильно их сочетать и визуализировать - это совершенно иное умение, которое и помогает быстро принимать правильные решения, направленные на улучшение деятельности центра мониторинга.
ЗЫ. Прикинул тут на досуге - уже накопилось материала на отдельный курс по дашбордам в ИБ. Думаю, еще покумекаю над ним, добавлю про варианты реализации дашбордов, и запущу на какой-нибудь платформе для онлайн-обучения.
Но только попробую. Потому что тема визуализации этой темы достаточно объемна и, самое главное, зависит от целей этого самого мониторинга и реагирования. Можно ограничиться только визуализацией числа инцидентов ИБ, которые обрабатывает SOC (можно даже с динамикой изменения этого числа). Например, вот так:

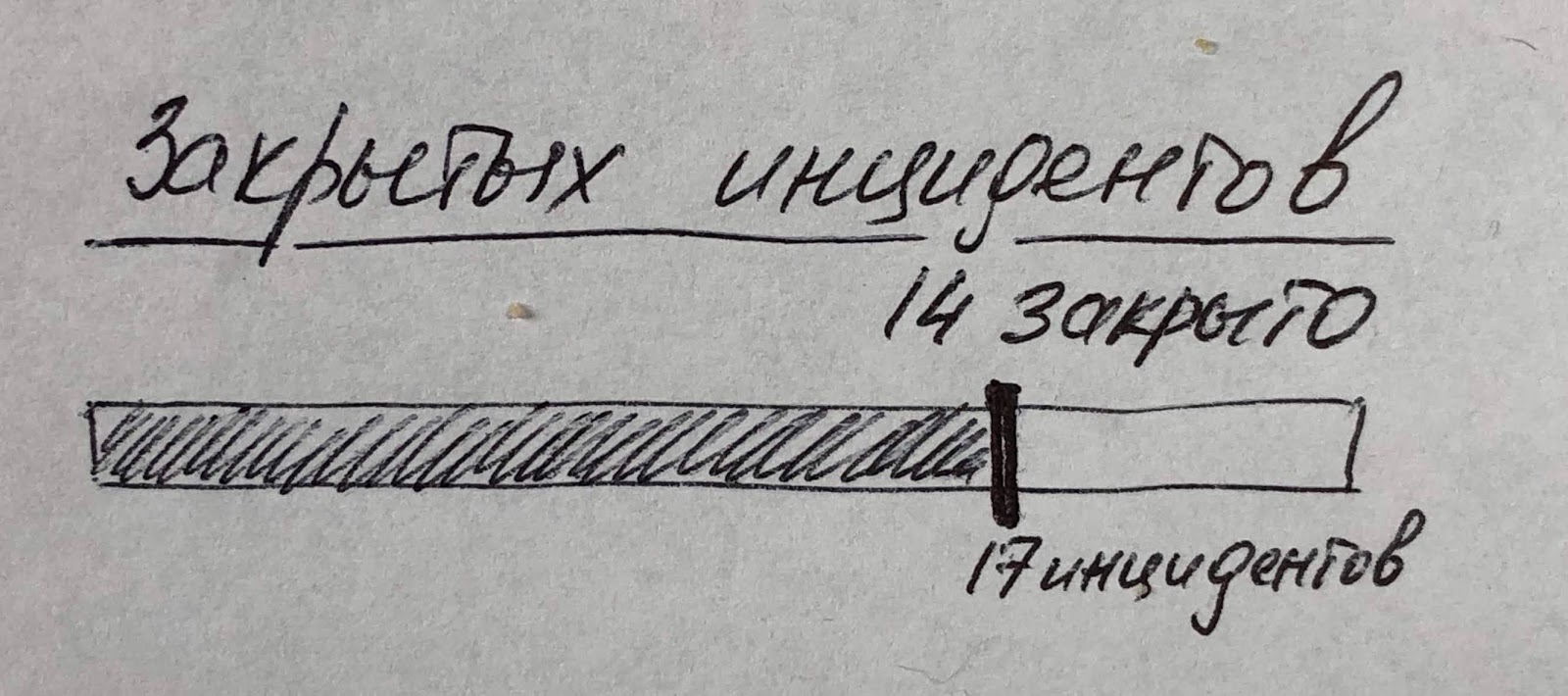
А можно копнуть глубже и посмотреть соотношение открытых и закрытых инцидентов (можно добавить еще большую детализацию, если указать тип инцидента или его приоритет или увязать инциденты с аналитиками). Показанный ниже пример интересен тем, что в нем используется не гистограмма (которая для визуализации соотношения вообще не подходит) и даже не диаграмма, которая просто показывает соотношение числа открытых и закрытых инцидентов, а "бегунок", который лучше визуализирует не только соотношение, но и стремление к цели (то есть сокращение числа незакрытых инцидентов). И тут важно помнить, что мы говорим о стремлении свести к нулю не число инцидентов (это невозможно), а число именно незакрытых инцидентов.
Смотря на рекламные материалы некоторых аутсорсинговых SOCов, удивляешься, когда SOC пишет, что они за 15 минут реагируют на инцидент. Тут либо манипуляция терминами и под словом "реагирование" они понимают "принимают в обработку" (но тогда чем тут хвалиться)? Либо речь идет о непонимании реальной работы SOC, в котором время принятия инцидента в обработку может составлять минуты (пока прилетит сигнал тревоги в SIEM, пока он скоррелируется, пока он приоритезируется). Поэтому одной из важных метрик в SOC будет время принятия инцидента в обработку первой линией. Виджет, который это будет показывать, может выглядеть так:
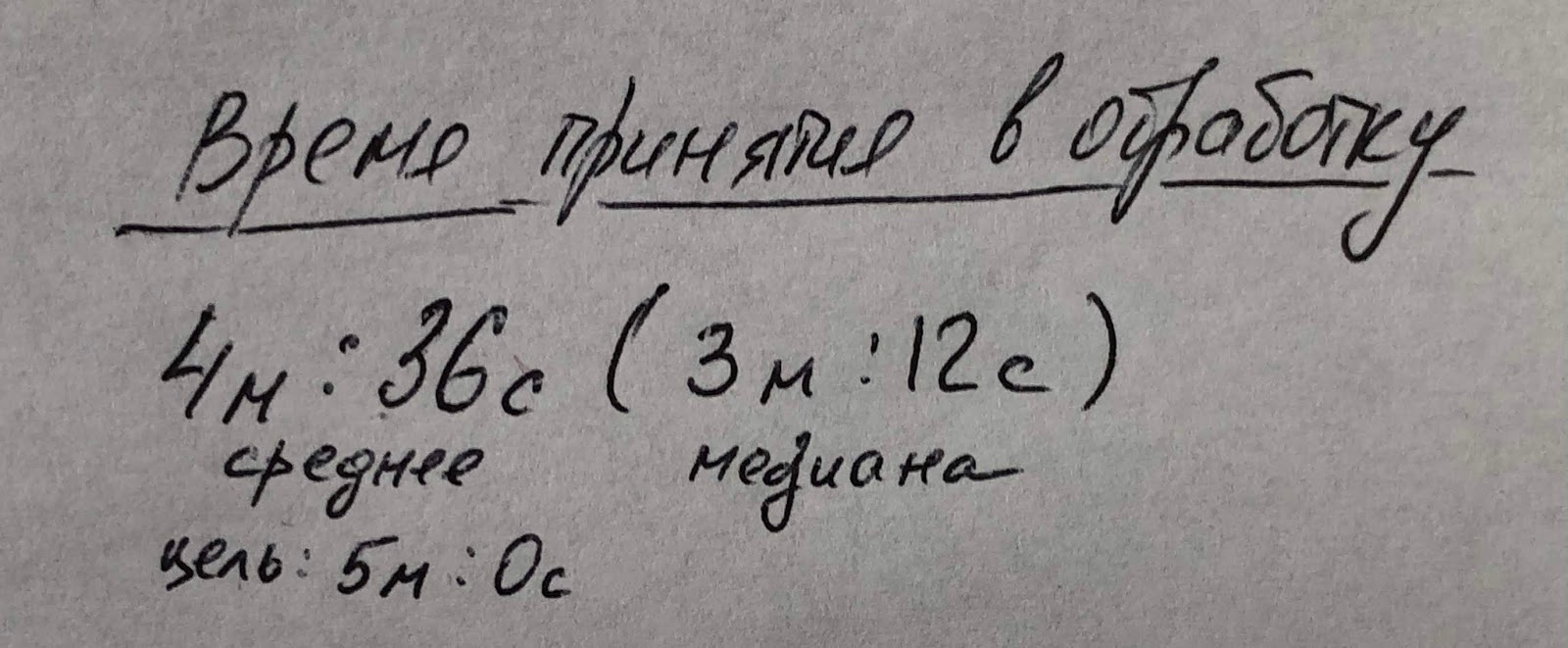
В нем не только отображено среднее время взятия инцидента в работу (можно еще детализировать для разных типов инцидентов и аналитиков; для приоритета бессмысленно), но и указана цель этого показателя. В реальном дашборде значение времени будет отображаться зеленым, если показатель находится в заданных пределах, и красным, если он вышел за границы (можно добавить еще желтый, если считать приближение к граничному значению). Обратите внимание, что помимо среднего арифметического я также добавил медиану, так как именно она лучше отражает типичное значение времени взятия инцидента в работу.
Но этот виджет показывает нам текущее значение (за указанный интервал времени), не говоря ни слова о том, какое число инцидентов из общего их числа было взято вовремя. Для этого может подойти вот такой виджет: Опять же, зеленая/красная направленная стрелка показывает нам улучшение или ухудшение (а не рост или падение) этого показателя, а зеленый или красный цвет числа покажет, вышли ли мы за установленные целевые значения или нет. Если накапливать этот показатель в течение времени, то можно будет еще строить динамику его изменения.
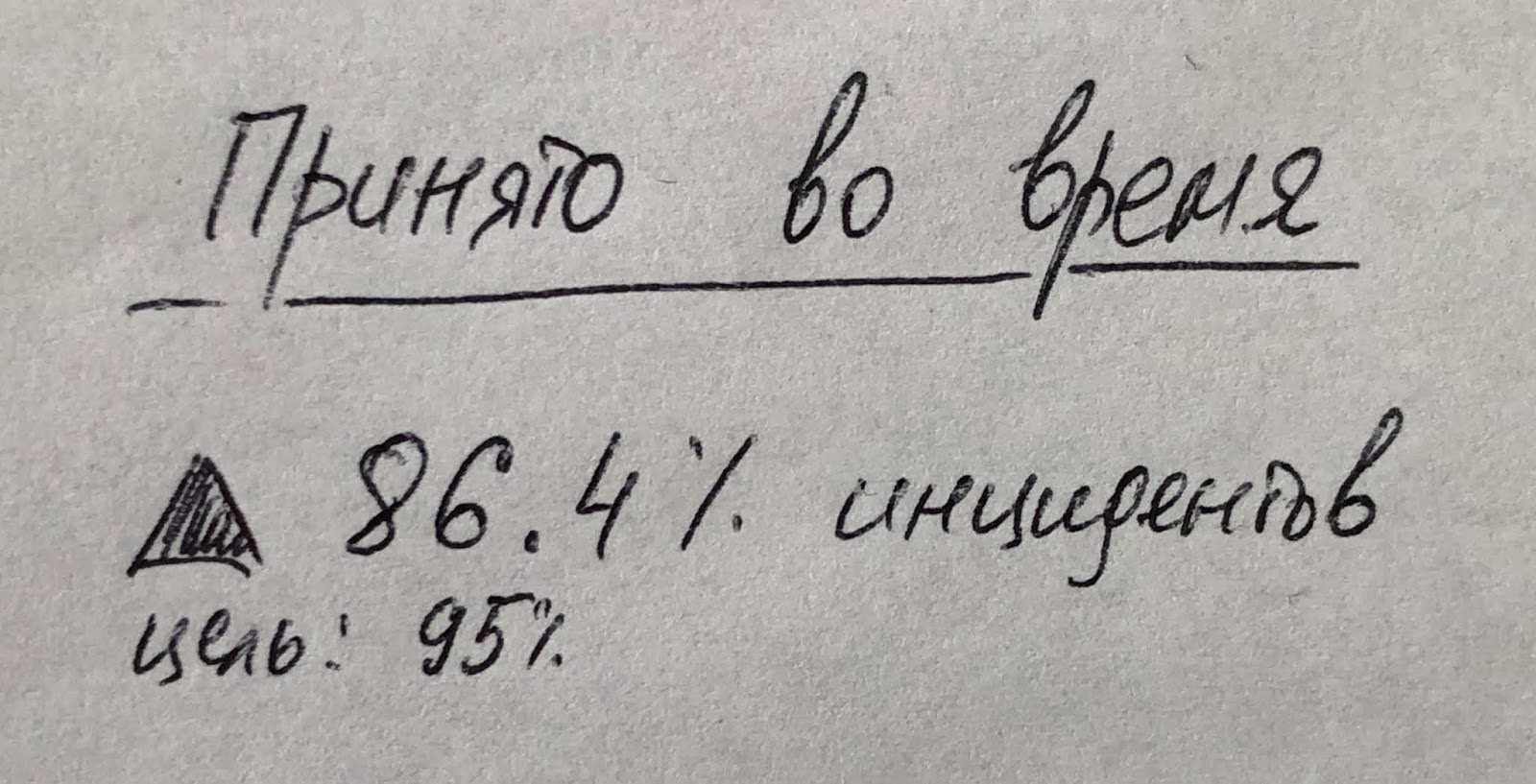
Данный виджет может быть интересен не только в его абсолютном значении. Мы можем захотеть понять, от чего зависит несвоевременность принятия инцидентов в обработку. Например, может оказаться так, что аналитики перегружены инцидентами и не успевают их отрабатывать, что приводит к переполнению очереди и нарушению установленного SLA. А может быть несвоевременность связана с усталостью аналитика? Тогда надо анализировать предыдущий показатель в привязке к времени суток. Выглядеть это может так:

Если инцидент не был разрулен на первой линии SOC, то он передается на вторую линию (не эскалируется, как ошибочно считают многие). Посколько аналитиков второй линии в SOC обычно меньше (бывают исключения) и они дороже обходятся компании, то их избыточная нагрузка может негативно сказаться на показателях работы SOC. Аналитики L1 могут по ошибке, незнанию или умышленно передавать даже простые инциденты на вторую линию, чтобы соблюсти свои показатели деятельности (своевременно закрыт инцидент). Поэтому нам надо отслеживать, какие инциденты передаются на L2 и по какой причине, например, так:
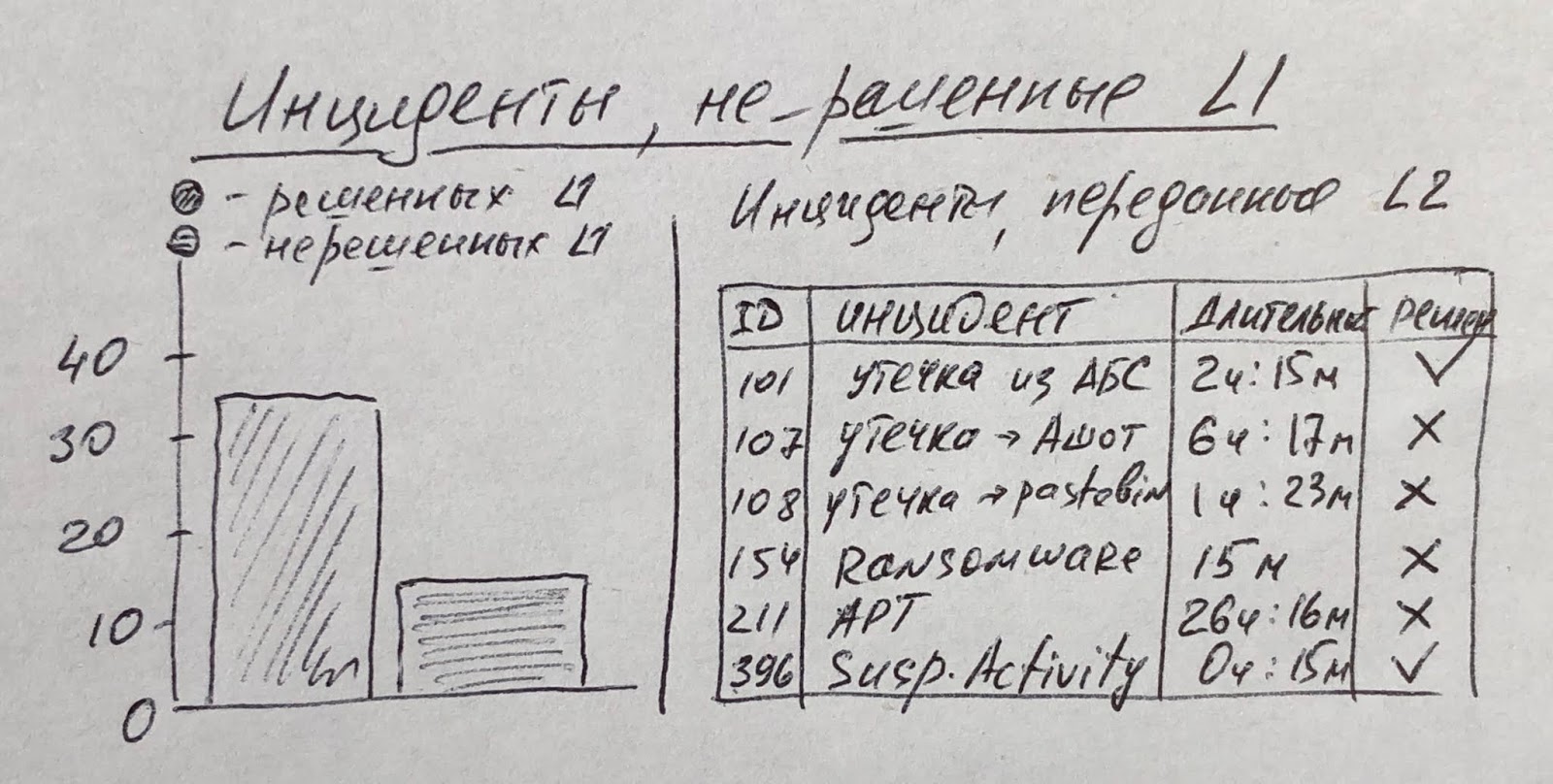
По идее у вас должна быть выстроена воронка инцидентов, когда по мере перехода от L1 к L2 и L3 число инцидентов существенно сокращается.
Еще одним интересным виджетом может стать "занятость аналитика". Обычно мы считаем, что человек работает весь рабочий день, с 9-ти до 6-ти или с 9-ти до 9-ти или в каком-то ином режиме, в зависимости от длительности смен. На самом же деле, может оказаться так, что аналитик отлынивает от работы, много времени отдыхает, перекуривает и т.п. Поэтому занятость аналитика, которая оценивается как отношение суммарного времени, затраченного на работу с инцидентами (легко оценивается в IRP/SOAR-платформе), к общей длительности смены, является очень хорошим показателем. На виджете ниже вы видите, как его можно визуализировать. Мы видим не только текущее значение для всех аналитиков или какого-то конкретного из них, но и целевое значение. В рабочей версии виджета мы можем использовать фотографии аналитиков и цифровую дифференциацию в зависимости от попадания или нет в целевые значения.

С занятостью напрямую связана производительность аналитика, когда мы оцениваем и число взятых в обработку инцидентов и среднее время взятия в обработку или длительность обработки инцидента. Сопоставление этих позиций нам помогает понять, кто из аналитиков работает хорошо, а кому нужен волшебный пендаль или отправка на повышение квалификации. Кстати, на виджете ниже, показана прикольная фишка, которую мы реализовывали в одном из SOCов - геймификация. Исходя из показателей оценки работы аналитика вычислялись баллы, которые ранжировались по диапазонам и каждому из них присваивались соответствующие статусы (SOC Master, COS Newbie, SOC Expert и т.п.). Учитывая возраст аналитиков в этом SOC и некий соревновательный дух среди его состава, такая геймификация позволила улучшить показатели реагирования на инциденты (без снижения его качества).

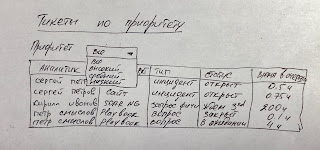
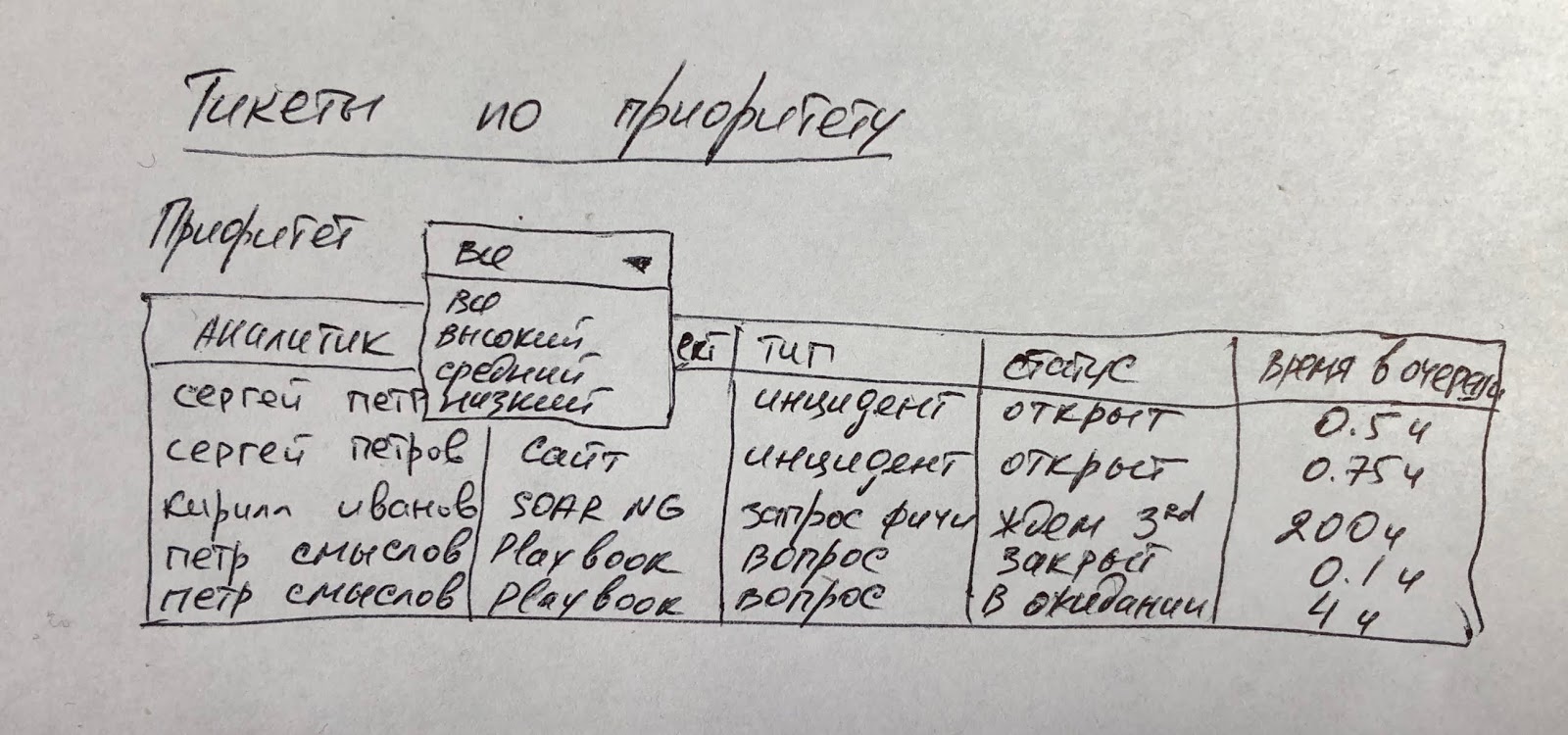
Обрабатываемые инциденты можно визуализировать с помощью диаграммы, в которой показать соотношение между разными типами, приоритетами, источниками или аналитиками. Так как в данном случае у меня нет цели свести какой-то тип или приоритет инцидента к нулю (ну если начальство вдруг не поставило такую задачу ради PR), то диаграмма будет вполне к себе к месту. Ниже показан схожий пример, но вместо инцидента у нас отображаются тикеты в системе управления деятельностью SOC, которую иногда разворачивают на базе SOAR, а иногда применяют что-то самостоятельное, для чего даже придумали термин "Security GRC". Это вообще странная конструкция, но почему-то очень популярная у производителей ИБ, которые, видимо, хотят показать свою близость к бизнесу, в котором GRC применяются достаточно давно. Или они берут пример с производителей IT GRC?..

Ну а дальше мы можем визуализировать инциденты/тикеты по различным срезам и с привязкой к разным их атрибутам.
Вообще тема визуализации метрик ИБ в виде отчетов и дашбордов сегодня очень мало кем прорабатывается. Она гораздо сложнее, чем даже просто тема измерения эффективности SOC. Ну считаете вы классические TTD/TTC/TTR. Может быть вы добавляете к ним MTTI, MTTQ, MTTV или MTTM. А может быть вы все-таки оцениваете еще и другие параметры (число переданных на L2 инцидентов, число открытых инцидентов критического уровня, точность эскалации инцидентов или число пострадавших активов/устройств). Допускаю. Но вот правильно их сочетать и визуализировать - это совершенно иное умение, которое и помогает быстро принимать правильные решения, направленные на улучшение деятельности центра мониторинга.
ЗЫ. Прикинул тут на досуге - уже накопилось материала на отдельный курс по дашбордам в ИБ. Думаю, еще покумекаю над ним, добавлю про варианты реализации дашбордов, и запущу на какой-нибудь платформе для онлайн-обучения.

