
Google TurboQuant - не новый чат-бот, не отдельный сервис и не волшебная кнопка «ускорить ИИ». Речь идет о способе сильнее сжимать данные, которые большая языковая модель держит в памяти во время ответа. В публичном блоге Google объясняет TurboQuant как набор алгоритмов для очень плотного сжатия векторов, прежде всего в KV-кэше и системах векторного поиска.
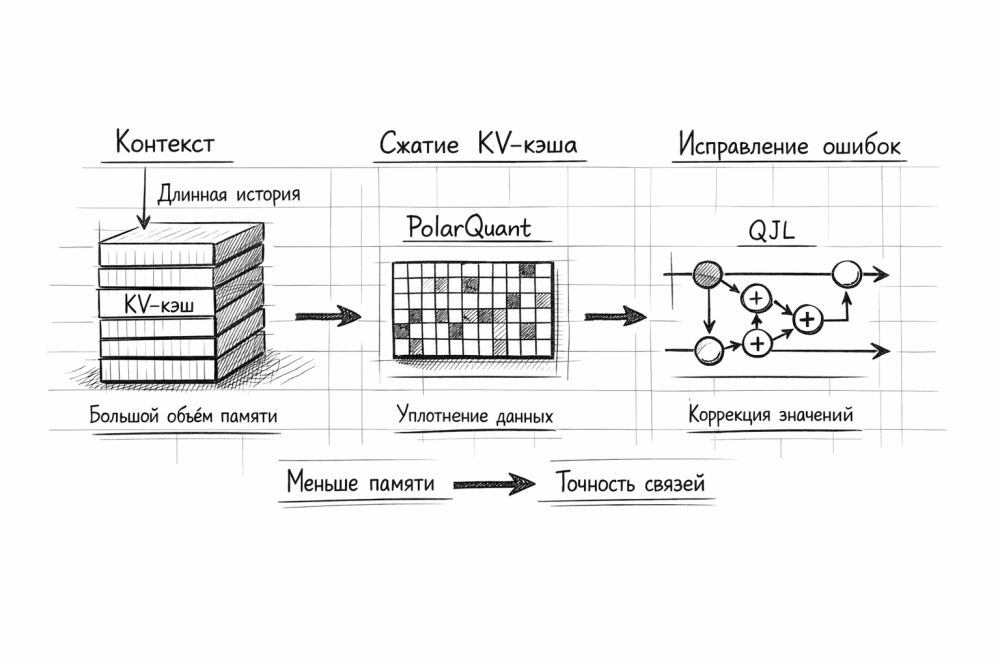
Если убрать математику, смысл такой: модель во время генерации ответа постоянно хранит рядом промежуточные результаты, чтобы не пересчитывать все заново. Такая «оперативная память» для ИИ очень полезна, но на длинных диалогах быстро раздувается. TurboQuant нужен, чтобы упаковать эти данные заметно плотнее и по возможности не испортить качество ответа.
Google TurboQuant простыми словами: что именно сжимают
Самая частая ошибка в обсуждении TurboQuant - думать, что Google научилась ужимать всю модель почти бесплатно. На самом деле речь в первую очередь не о весах модели, а о KV-кэше. KV-кэш - часть механики трансформеров, где модель хранит уже посчитанный контекст, чтобы быстрее продолжать ответ.
Пока диалог короткий, проблема выглядит терпимо. Когда контекст растет до сотен тысяч или миллионов токенов, KV-кэш начинает съедать огромный объем памяти. В длинных сессиях и агентных сценариях именно память, а не «голая» вычислительная мощность, часто становится бутылочным горлышком.
Поэтому TurboQuant решает довольно практичную задачу: как хранить больше контекста в той же памяти, как уменьшить цену инференса и как не потерять слишком много в точности поиска нужных связей между токенами.
Как работает TurboQuant без формул
Классическое квантование давно не новость. Идея простая: вместо хранения чисел с высокой точностью хранить более грубое, но сильно более компактное представление. Проблема в том, что грубое сжатие ломает точность, а часть методов еще и добавляет служебные накладные расходы, которые съедают часть выгоды.
В случае TurboQuant Google пытается обойти обе проблемы сразу. В научной работе описан двухступенчатый подход. Сначала данные переводят в более удобную форму для сжатия. Затем отдельный механизм компенсирует остаточную ошибку, чтобы итоговые inner product и attention scores меньше плыли.
Если говорить совсем по-человечески, схема похожа на такую логику. Сначала данные перестраивают так, чтобы числа стали более «ровными» и лучше поддавались упаковке. Потом поверх добавляют очень дешевую корректировку, которая не дает модели слишком сильно ошибаться в важных совпадениях и связях.
У Google в этом наборе фигурируют два ключевых кирпича - PolarQuant и QJL. Первый помогает удобнее сжимать сами векторы, второй работает как математическая коррекция остаточной ошибки. За счет связки получается агрессивное сжатие без полного развала качества.
Почему вокруг TurboQuant столько шума
Причина не в красивом названии. Google заявляет, что подход позволяет заметно уменьшать размер KV-кэша, а в ряде сценариев сохранять качество на уровне, близком к полноточному базовому варианту. В блоге Google говорится о снижении потребления памяти как минимум примерно в шесть раз на тестах «needle in a haystack», а в статье на arXiv авторы пишут про «quality neutrality» на уровне 3,5 бита на канал и лишь небольшую деградацию на 2,5 бита.
Цифры звучат громко, потому что память сейчас стала одним из главных ограничителей длинного контекста. Если один и тот же GPU может держать больше полезного контекста, разработчик получает выбор: удешевить запуск, увеличить окно контекста или уместить более тяжелую задачу в тот же бюджет.
Отсюда и ажиотаж. TurboQuant обещает не косметическую оптимизацию, а удар по одному из самых дорогих узлов инференса современных LLM.
Что TurboQuant меняет на практике, а что не меняет
| Что меняется | Что не меняется |
|---|---|
| Меньше памяти уходит на KV-кэш | Модель не становится «маленькой» сама по себе |
| Длинный контекст становится дешевле или доступнее | Качество не гарантировано одинаковым во всех задачах |
| Снижается давление на память в инференсе | Проблемы задержек, стоимости GPU и пропускной способности не исчезают |
| Возможна более быстрая работа attention в отдельных сценариях | TurboQuant не равен автоматическому ускорению любого ИИ-приложения |
С практической точки зрения TurboQuant интересен прежде всего там, где модель много читает, долго держит историю и постоянно обращается к длинному контексту. Это RAG-системы, агентные цепочки, длинные диалоги, анализ документов, кодовые помощники и поиск по большим векторным индексам.
Но переоценивать технологию не стоит. TurboQuant не отменяет цену видеопамяти, не решает все проблемы длинного контекста и не превращает тяжелую модель в игрушку для слабого ноутбука. Хорошее сжатие памяти почти всегда сопровождается компромиссами, а выигрыш зависит от конкретной архитектуры, железа и профиля нагрузки.
Где заканчивается маркетинг и начинается реальность
Самый здравый взгляд на TurboQuant звучит так: разработка выглядит сильной, но смотреть нужно не на заголовок «в 6 раз меньше памяти», а на условия, в которых получен выигрыш. Часто в реальной системе рядом живут и другие расходы - пропускная способность памяти, задержки на распаковку, особенности ядра attention, качество на нестандартных задачах, длинные хвосты распределений и деградация на сложных промптах.
Второй важный нюанс - сравнение с чем именно ведут. В рекламной подаче легко сравнить новый метод с менее выгодной базой и получить впечатляющий процент. Для инженера главный вопрос другой: как TurboQuant выглядит рядом с уже хорошими 4-битными и 8-битными схемами, которые применяют в продакшене, и сколько реальной боли убирает именно в вашей конфигурации.
Третий момент - сама логика рынка. Даже если одна технология экономит память, индустрия обычно тратит освобожденный ресурс не на экономию счета, а на еще более длинные контексты, более сложные цепочки и более тяжелые модели. Именно такой скептический акцент есть и в недавнем разборе SecurityLab: хорошие алгоритмы часто не уменьшают общий аппетит рынка, а подталкивают к новым требованиям.
TurboQuant и KV-кэш: почему узкое место оказалось таким важным
Несколько лет назад многие смотрели в первую очередь на число параметров модели. Сейчас картина сложнее. Для инференса больших моделей не меньшее значение имеет то, сколько памяти уходит на хранение уже обработанного контекста. Чем длиннее разговор или документ, тем больше растет KV-кэш. Рост при этом может оказаться настолько неприятным, что именно память определяет предел системы раньше, чем арифметика на GPU.
Поэтому борьба вокруг KV-кэша стала отдельным фронтом оптимизации. Разработчики уменьшают точность, меняют представление данных, объединяют операции, подбирают новые kernels и ищут способы не хранить лишнее. TurboQuant хорошо вписывается в этот тренд. По сути Google предлагает более умный способ запихнуть тот же смысл в меньший объем памяти.
Повлияет ли TurboQuant на обычных пользователей
Непрямо - да. Если подобные методы приживутся, сервисы на базе LLM смогут дешевле обслуживать длинные запросы, реже упираться в память и увереннее работать с большими документами или длинной историей переписки. Пользователь увидит не кнопку «TurboQuant», а более длинный контекст, меньше обрезаний истории или более доступные тарифы для тяжелых сценариев.
Но ждать мгновенной революции не стоит. Между хорошей статьей и массовым продакшеном лежит длинный путь: интеграция в фреймворки, адаптация ядер, проверка качества, отладка на разных моделях, сравнение с альтернативами и банальная инженерная цена внедрения.
Главные ограничения TurboQuant
Первое ограничение - зависимость от сценария. На коротких запросах и легких задачах выигрыш от агрессивного сжатия может быть скромным или вообще не окупать сложность.
Второе - чувствительность к качеству. Там, где ошибка в attention особенно болезненна, даже небольшая деградация может оказаться заметной. Маркетинговая формула «почти без потерь» всегда требует проверки на ваших тестах, а не на усредненных бенчмарках.
Третье - технологический контекст. Один и тот же метод может выглядеть блестяще на H100 и гораздо скромнее на другой связке железа и софта. Публичные цифры ускорения полезны как ориентир, но не как гарантия.
Четвертое - TurboQuant не решает вопросы безопасности, приватности, достоверности ответов и качества самой модели. Сжатие памяти улучшает экономику работы, но не чинит фундаментальные слабые места LLM.
Короткий вывод: TurboQuant - важная инженерная оптимизация для памяти и длинного контекста, а не чудо-технология, которая делает любую модель дешевой, быстрой и идеальной.
Вывод: стоит ли следить за Google TurboQuant
Да, следить стоит. Не потому что Google показала очередной красивый бренд, а потому что TurboQuant бьет по реальному узкому месту современных LLM - памяти KV-кэша. Для индустрии длинного контекста и векторного поиска направление очень важное.
Но здравый вывод должен быть без перегрева. TurboQuant не отменяет компромиссы, не доказывает автоматическую победу над всеми другими схемами квантования и не гарантирует одинаковый выигрыш в каждой системе. Лучший способ смотреть на технологию - как на сильный инженерный инструмент для конкретного класса задач, а не как на универсальное решение всех проблем ИИ.
Если объяснить в одной фразе, Google TurboQuant - это умный способ плотнее упаковать «рабочую память» языковой модели, чтобы модель могла держать длинный контекст дешевле и без слишком заметной потери качества.
FAQ про Google TurboQuant
TurboQuant сжимает всю модель или только часть данных?
В первую очередь речь идет не о полном сжатии весов модели, а о KV-кэше и близких задачах работы с векторами. Это важное различие, потому что память на контексте и память на весах - разные статьи расхода.
TurboQuant уже используется в Gemini и Google Search?
Публично Google описывает такие сценарии как естественные области применения, но открытого подтверждения широкого продакшен-развертывания в пользовательских продуктах пока нет. Поэтому говорить «уже внедрили повсюду» было бы слишком смело.
Почему не оставить обычное 8-битное квантование?
Потому что борьба идет за каждый бит. Когда контекст очень длинный, разница между 8 битами, 4 битами и примерно 3 битами превращается в заметную разницу по памяти и экономике инференса.
TurboQuant полезен только для чат-ботов?
Нет. Подход интересен и для векторного поиска, где тоже нужно хранить и быстро сравнивать большие массивы векторов.
Значит ли TurboQuant, что проблема дефицита памяти решена?
Нет. Скорее рынок получит еще один способ потратить сэкономленный ресурс на более тяжелые задачи. История ИИ обычно развивается именно так.

