
Check Point: оптимизация CPU и RAM
Здравствуйте, коллеги!
Сегодня я хотел бы обсудить очень актуальную для многих администраторов Check Point тему «Оптимизация CPU и RAM». Нередки случаи, когда шлюз и/или менеджмент сервер потребляют неожиданно много этих ресурсов и хотелось бы понять, куда они “утекают” и по возможности грамотнее использовать их.

1. Анализ
Для анализа загрузки процессора полезно использовать следующие команды, которые вводятся в экспертном режиме:
top // показывает все процессы, количество потребляемых ресурсов CPU и RAM в процентах, uptime, приоритет процесса и другое в реальном времени

cpwd_admin list //Check Point WatchDog Daemon, который показывает все модули апплайнса, их PID, состояние и количество запусков

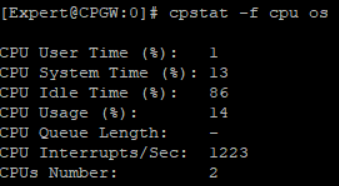
cpstat -f cpu os // использование CPU, их количество и распределение процессорного времени в процентах
cpstat -f memory os // использование виртуальной RAM, сколько всего активной, свободной RAM и другое

ps auxwf // длинный список всех процессов, их ID, занимаемую виртуальную память и память в RAM, CPU

Другая вариации команды:
ps -aF // покажет самый затратный процесс

fw ctl affinity -l -a // распределение ядер под разные инстанции фаервола, то есть технология CoreXL

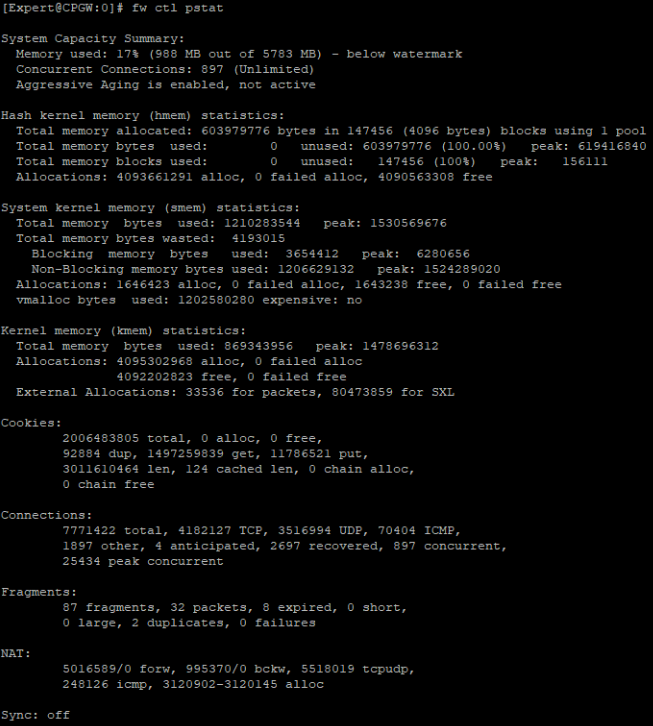
fw ctl pstat // анализ RAM и общие показатели соединений, cookies, NAT
free -m // буфер RAM

Если включен блейд monitoring, то можно смотреть данные показатели графически в SmartConsole нажав на объект и выбрав пункт Device & License Information.
На постоянное основе блейд monitoring включать не рекомендуется, но на день для теста вполне можно.
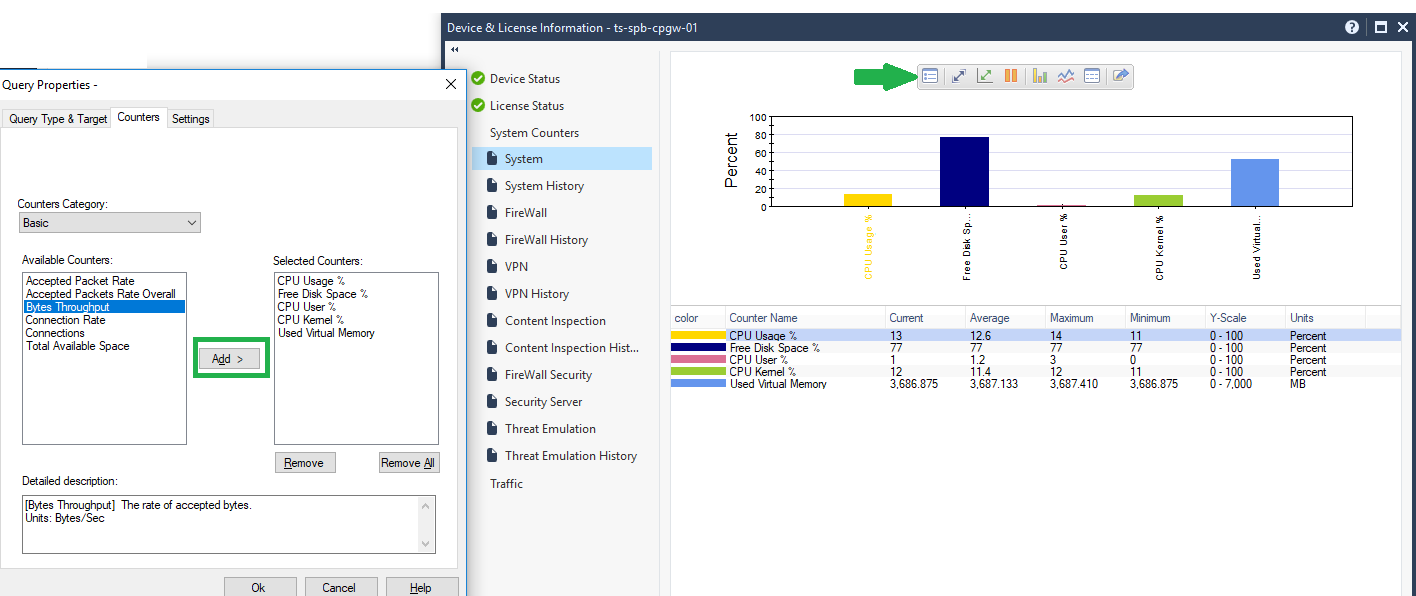
Более того, можно добавлять больше параметров для мониторинга, один из них очень полезный — Bytes Throughput (пропускная способность апплайнса).
Если есть какая-то другая система мониторинга, например бесплатный Zabbix, основанная на SNMP, она тоже подойдет для выявления данных проблем.
2. “Утечка” RAM со временем
Часто встает вопрос, что со временем шлюз или менеджмент сервер начинает все больше и больше потреблять RAM. Хочу успокоить, это нормальная история для Linux подобных систем.
Посмотрев вывод команд free -m и cpstat -f memory os на апплайнсе из экспертного режима, можно посчитать и посмотреть все параметры, относящиеся к RAM.
По факту доступной памяти на шлюзе на данный момент Free Memory + Buffers Memory + Cached Memory = +-1.5 Гб, как правило.
Как говорит СР, со временем шлюз/менеджмент сервер оптимизируется и использует все больше памяти доходя до примерно 80% использования и останавливается. Вы можете перезагрузить устройство, и тогда показатель сбросится. 1.5 Гб свободной ОЗУ шлюзу точно хватает на выполнение всех задач, а менеджмент редко доходит до таких пороговых значений.
Также выводы упомянутых команд покажут, сколько у вас Low memory (оперативная память в user space) и High memory (оперативная память в kernel space) использовано.
Процессы kernel (включая active modules, такие как Check Point kernel modules) используют только Low memory. Однако пользовательские процессы могут использовать как Low, так и High memory. Более того Low memory примерно равна Total Memory.
Беспокоится следует только если в логах будут сыпаться ошибки «modules reboot or processes being killed to reclaim memory due to OOM (Out of memory)», тогда следует перезагрузить шлюз и обратиться в поддержку, если не поможет.
Полное описание можно найти в sk99547 и sk99593.
3. Оптимизация
Ниже приведены вопросы и ответы по оптимизации CPU и RAM. На них стоит честно ответить самому себе и прислушаться к рекомендациям.
3.1. Правильно ли апллайнс был подобран? Был ли пилотный проект?
Несмотря на грамотный сайзинг, сеть могла банально разрастись и данное оборудование просто не справляется с нагрузкой. Второй вариант, если сайзинга как такого не было.
3.2. Включена ли HTTPS инспекция? Если да, то настроены ли технология по best practice?
Обратиться к статьe, если вы наш клиент, или к sk108202.Порядок расположения правил в политике HTTPS инспекции играет большое значение в оптимизации открытия HTTPS сайтов.
Рекомендуемый порядок расположения правил:
1) Правила bypass с категориями/URL
2) Правила inspect с категориями/URL
3) Правила inspect для всех остальных категорий
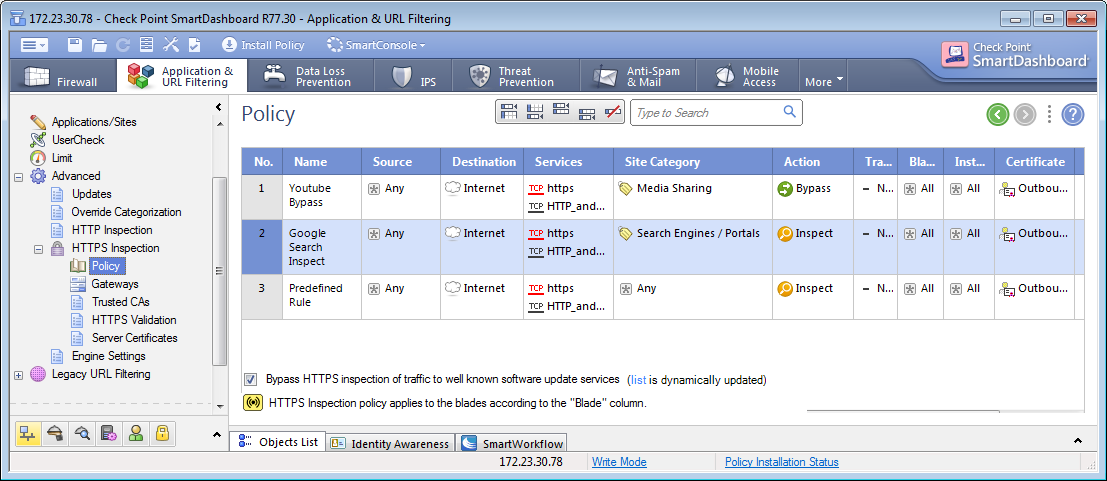
По аналогии с фаервольной политикой Check Point ищет совпадение пакеты сверху вниз, поэтому bypass правила лучше расположить вверху, так как шлюз не будет тратить ресурсы на прогонку по всем правилам, если в конце концов этот пакет надо пропустить.
3.3. Как настроена политика Threat Prevention?
В первую очередь, Check Point рекомендует выносить IPS в отдельный профиль и создавать отдельные правила под этот блейд.
Например, сегмент DMZ администратор считает, что необходимо защищать только с помощью IPS. Поэтому чтобы шлюз не тратил ресурсы на обработку пакетов другими блейдами, необходимо создать правило конкретно под данный сегмент с профилем, в котором включен только IPS.
По поводу настройки профилей, то рекомендуется настраивать его по лучшим практикам в этой статье страницы 17-20.
3.4. В настройках IPS как много сигнатур в режиме Detect?
Рекомендуется усиленно проработать сигнатуры, в том плане, что следует отключить неиспользуемые (например, сигнатуры на эксплуатацию продуктов Adobe требуют много вычислительной мощности и если у заказчика таких продуктов нет, сигнатуры имеет смысл отключить). Далее поставить Prevent вместо Detect там, где возможно, потому что шлюз тратит ресурсы на обработку всего соединения в режиме Detect, в режиме Prevent он сразу отбрасывает соединение и не тратит ресурсы на полную обработку пакета.
3.5. Какие файлы обрабатываются блейдами Threat Emulation, Threat Extraction, Anti-Virus?
Не имеет смысла эмулировать и анализировать файлы расширений, которые ваши пользователи не скачивают или вы считаете ненужными в вашей сети (например, bat, exe файлы легко заблокировать с помощью блейда Content Awareness на уровне фаервола, поэтому ресурсы шлюза будут тратятся меньше). Более того, в настройках Threat Emulation можно выбирать Environment (операционную систему) для эмуляции угроз в песочнице и ставить Environment Windows 7, когда все пользователи работают с 10-ой версией тоже не имеет смысла.
3.6. Расположены ли фаервольные правила и правила уровня Application в соответствии с best practice?
Если у правила много хитов (совпадений), то их рекомендуется ставить в самый верх, а правила с малым количеством хитов в самый низ. Главное — это следить за тем, чтобы они не пересекались и не перекрывали друг друга. Рекомендуемая архитектура фаервольной политики:
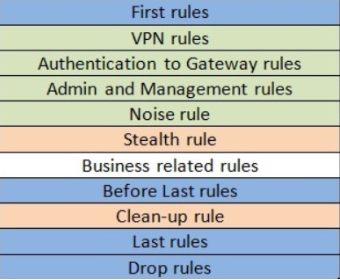
Пояснения:
First Rules — сюда помещаются правила с самым большим количеством совпадений
Noise Rule — правило для отбрасывания паразитного трафика такого как NetBIOS
Stealth Rule — запрет обращений к шлюзам и менеджментам всем, кроме тех источников, которые были указаны в правилах Authentication to Gateway Rules
Clean-Up, Last и Drop Rules как правило объединяются в одно правило для запрета всего, что не разрешено было ранее
Данные Best practice описаны в sk106597.
3.7. Какие настройки стоят у созданных администраторами сервисов?
Например, создается какой-то сервис TCP по определенному порту и имеет смысл в Advanced настройках сервиса поставить галочку “Match for Any”. В этом случае данный сервис будет попадать конкретно под правило, в котором он фигурирует и не участвовать в правилах, где в колонке Services стоит Any.

3.8. Какие тайм-ауты стоят в Menu > Global Properties > Stateful Inspection?
Разобравшись что за что отвечает, имеет смысл урезать тайм-ауты и поставить дропы на out of state пакеты. Например, TCP Timeout в 3600 секунд мало кому нужен и его можно уменьшить, тем самым потребление CPU сократиться, шлюз не будет держать сессии TCP слишком долго.

3.9. Используется ли SecureXL и каков процент ускорения?
Проверить качество работы SecureXL можно основными командами в экспертном режиме на шлюзе fwaccel stat и fw accel stats -s. Далее нужно разбираться, что за трафик ускоряется, какие templates (шаблоны) можно создать еще.
По умолчанию Drop Templates не включены их включение благоприятно скажется на работе SecureXL. Для этого зайдите в настройки шлюза и во вкладку Optimizations:
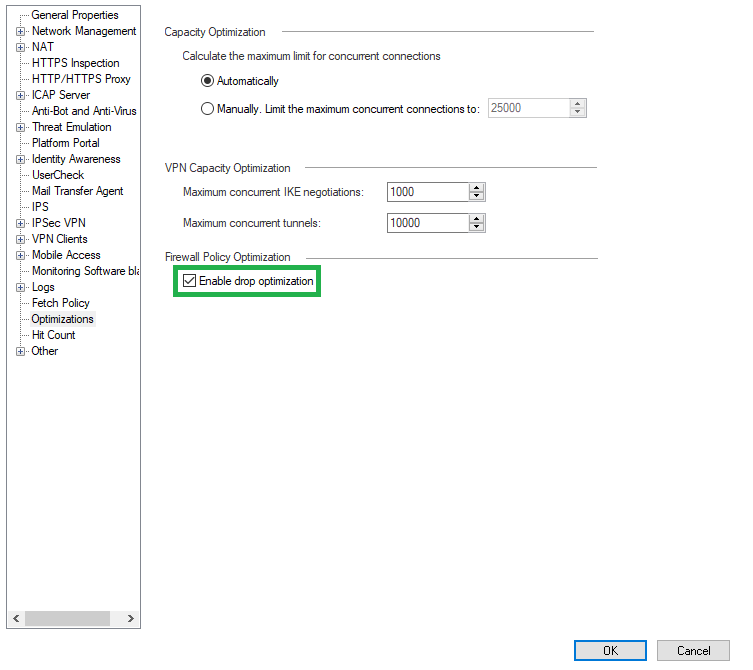
Также при работе с кластером для оптимизации CPU можно отключить синхронизацию некритичных сервисов таких как UDP DNS, ICMP и другие. Для этого стоит зайти в настройки сервиса > Advanced > Synchronize connections of State Synchronization is enabled on the cluster.
Все Best Practice описаны в sk98348.
3.10. Как используется CoreXl?
На практике очень редко доходит до сюда, тем не менее подстроить приоритеты обработки трафика разными ядрами бывает нужно. Хорошая история — это поставить хотфикс на включение Multi-Queue было бы хорошо, так как на CoreXL появилась бы возможность подстраивать приоритеты для разного трафика на уровне ядра. Методики описаны также в sk98348.
В заключение хотелось бы сказать, что это далеко не все Best Practices по оптимизации работы Check Point, однако самые популярные. Если вы хотите заказать аудит вашей политики безопасности или решить проблему связанную с Check Point, то обращайтесь пожалуйста на sales@tssolution.ru.
Спасибо за внимание!

