

Кадр из мультфильма For the Birds (Pixar)
Деятельность аналитиков центров мониторинга и реагирования на кибератаки (Security Operations Center) чем-то похожа на деятельность любой службы поддержки. Те же линии с инженерами различной экспертизы, тикеты, приоритеты, SLA и тайминги. Но то, с чем приходится сталкиваться менеджменту SOC, не приснится и в ночных кошмарах службе поддержки продукта/сервиса: экстремально короткие SLA, абсолютно непредсказуемая скважность входящего потока, отсутствие понятия «массовая проблема», возможности пообещать решение в следующем релизе и много других фишек, делающих жизнь менеджера SOC ну ооочень интересной. Про отсутствие возможности прогонять инцидент последовательно через линии мы уже писали, настало время поговорить о других особенностях организации процесса. Итак, скважность, короткий SLA и распределение критичностей.
Линии SOC и техподдержка: найдите 10 отличий
В продуктовой техподдержке входящий поток и приоритизация работ так или иначе привязаны к релизному циклу. При выпуске новых релизов обычно наблюдается как всплеск частоты обращений, так и повышение критичности инцидентов – велика вероятность наступления на грабли в свежем релизе. По мере его стабилизации, багфиксинга и обкатки пользователями новых фич число заявок снижается и основной объем работ приходится уже на консультации с длительными или вообще не определенными SLA-таймингами. Этими волнами нагрузки можно пользоваться и управлять загрузкой линий, планировать тренинги, обучения и отпуска на межрелизье. Не скажу, что это просто, но можно.
SOC… A вот тут кино и немцы… Да, мы тоже фиксируем определенные волны – летом обычно нагрузка меньше, и мы этим пользуемся для внедрения серьезных изменений в процессы/технологии. Но в остальном все сильно интереснее: если посчитать среднюю нагрузку и ее распределение по часам и соотнести это со средней ресурсоемкостью линий, то все выглядит очень неплохо (мы же формировали емкость линий, ориентируясь в том числе на эти данные). Нагрузка вполне себе перевариваемая и находится в диапазоне 60-80% ресурсоемкости. Если же посмотреть на распределение внутри дня, то нередки всплески нагрузки, в разы превышающие емкость линий (на моей памяти рекордом было превышение в 12 раз). Если бы мы были техподдержкой, то подобные всплески демпфировались бы «длинными» консультационными запросами с SLA в неделю, а то и больше, а также запросами средней критичности с SLA в несколько суток.
У нас же максимальный тайминг по низкокритичным инцидентам – пара часов, не раздемпфируешься. Раздувать емкость линии, чтобы она могла переваривать эти пики – тоже сомнительное удовольствие. И дело не только в экономике – что будет делать вся эта орава после того, как разгребет пик?
Как быть готовым к шквалу инцидентов и не раздуть штат
Мы пробовали разные варианты – в конечном счете у нас появилась процедура ресурсной эскалации: к разбору вала инцидентов на первой линии стали привлекаться все линии аналитики. Изначально процесс прихрамывал, не было четких триггеров для запуска механизма эскалации, часто инженеры до последнего боролись с нагрузкой на линии, стесняясь привлечь к разбору тикетов «небожителей» четвертой линии. Бывали моменты, когда, напротив, эскалация инициировалась без веских на то оснований и вызывала праведный гнев инженеров старших линий аналитики.
На помощь снова пришла статистика времени обработки инцидентов по типам (мы копим ее с 2016-го и используем много где). Мы реализовали статистическую метрику LA (реверанс в сторону линуксового Load Average), которая показывает отношение матожидания временных ресурсов, требуемых для решения текущего пула инцидентов в работе, к текущим ресурсам на линии. Метрика вычисляется с усреднением за 5, 20 и 60 минут. 5-минутная является оперативным инструментом online-инженера, 20-минутная – зона внимания тимлида, часовая – зона внимания руководителей отдела и департамента.

Вот так отображается нагрузка в нашей тикет-системе. В выделенном тикете: 81% – это средняя нагрузка за 5 минут, 106% и 102% – средняя нагрузка за 20 и 60 минут соответственно. Таким образом, видно, что совсем недавно на линии был всплеск по инцидентам, но их успели разобрать до показателя 81%. Нормальной считается нагрузка в 80% и ниже. Все, что выше, допустимо лишь на краткий промежуток времени (мы дорожим здоровьем наших инженеров).
20-минутная метрика по первой и второй линиям выведена на дашборд:
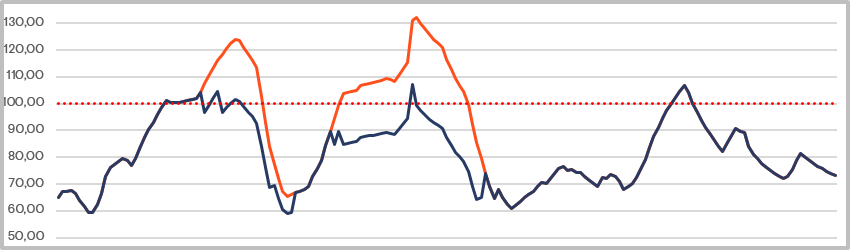
Дашборд LA (нагрузки на линии). Красная линия – показатель отношения нагрузки к ресурсам линии. Синяя – показатель отношения нагрузки к совокупным ресурсам линии и всех привлеченных дополнительных ресурсов. Разница между ними отражает эффективность ресурсной эскалации.
Кроме визуального контроля, реализовали карточку внутреннего инцидента о превышении нагрузки на линии, в рамках которого online-инженер проводит и протоколирует эскалацию:

Прописаны пороги нагрузки, при которой ресурсная эскалация продолжается, захватывая все более экспертные линии и пороги высвобождения привлеченных ресурсов. Естественно, эскалация ступенчатая – привлечение идет от младших линий к старшим.
Особенно востребованной эта процедура была во времена, когда мы еще не вышли на большие числа по количеству заказчиков и емкости линий. Тогда эскалация часто выбирала все доступные ресурсы, до которых могла дотянуться. Теперь ситуация более прогнозируемая, поскольку нагрузка при большом числе заказчиков демпфируется, но и сейчас ресурсная эскалация запускается с завидной периодичностью, правда, до TIER4 уже не добирается (хотя возможность осталась).
Как было сказано выше, процедура ресурсной эскалации инициируется онлайн-инженером – это особая роль на линии. Появилась она практически с самого старта JSOC как закрепление ответственности за верный процессинг тикетов. С течением времени функционал онлайн-инженера много раз дополнялся и к текущему моменту времени это инженер, основная задача которого – поддержание на линии необходимого числа ресурсов для эффективной утилизации текущей нагрузки. Плюс выполнение различных внутренних процедур и контролей, обеспечивающих верный процессинг тикетов и выполнение SLA всей командой. Онлайн тоже занимается решением инцидентов, но выбирает из очереди не самые “горячие” а “самые короткие из горячих”, поскольку для него недопустимо глубоко нырять в пролонгированное расследование сложных и трудоемких инцидентов.
Кстати, роль онлайн-инженера закрепляется в нашей тикетной системе особым тикетом “JSOC Мониторинг-дежурный” – тем самым, куда мы выводим оперативные показатели LA (см. рис.1.). У этого тикета есть одна интересная особенность – его можно взять на себя, но нелья передать кому-то или просто снять с себя. Можно только “убедить” взять себе этот тикет следующего по графику онлайн-инженера в процессе передачи смены. “Убедить” на самом деле не очень сложно: если на линии порядок, все особенности, необходимые к передаче на пересеменке описаны, то это просто прохождение небольшого чек-листа. Если же онлайн не очень качественно сопровождал смену и к моменту передачи на линии бардак, то ему придется навести порядок, прежде чем сменщик заберет с него тикет. Это позволяет решить множество спорных ситуаций, которые периодически возникали при пересменке до внедрения этого механизма.
Занимательная статистика: закономерности нагрузки на SOC
При составлении расписания мы дополнительно оперируем статистикой нагрузки в разрезе дней недели и месяцев. Длительное наблюдение выявило довольно странную закономерность: вторник и четверг являются самыми насыщенными днями, понедельник и среда – средняя нагрузка и пятница дает возможность немного расслабиться перед ожидаемо низконагруженными выходными. Соответственно и наше расписание выглядит так, что во вторник и четверг линии максимально укомплектованы и роли онлайн-инженеров отводятся опытным бойцам, четко оценивающим текущую ситуацию и без тени рефлексии готовых привлечь в бой дополнительных легионеров.
Понедельник и среда – обычные среднестатистические дни. Пятница – день особый: с одной стороны мы заступаем на смену в облегченном составе, достаточном для утилизации пятничной нагрузки, а с другой – пятничный онлайн-инженер должен быть весьма опытен и очень внимательно держать руку на пульсе. Во-первых, чтобы вовремя обеспечить усилением команду, если пятница окажется не совсем типовой. Во-вторых, вечер пятницы – это излюбленное время темной стороны для начала своих темных делишек.
Также статистически подтверждается традиционный летний спад нагрузки – обычно мы используем его для реализации наших планов по перестройке процессов и тяжеловесной перестройке инструментария. Но COVID'ное лето 20-го выбилось из статистики и было для нас достаточно жарким, поскольку заказчики были вынуждены для обеспечения массовой удаленной работы сотрудников перекраивать как свои процессы, так и средства доступа к корпоративным ресурсам. Спад нагрузки наметился только к августу. Но мы рассчитываем, что к следующему году картинка статистики вернется на круги своя, поскольку самые тяжелые и болезненные изоляционные изменения уже успешно произошли как у заказчиков, так и у нас самих. Как говориться, все что не убивает – делает нас.
Соломонова справедливость, или Как мы составляем графики дежурств
Мы с самого начала не видели применимости каких-либо стандартных схем ротации типа день/ночь/отсыпной/выходной или сутки/трое. Все подобные схемы не могут обеспечить эффективное покрытие часов наибольшей нагрузки максимумом инженерных ресурсов, оставив на часы затишья минимум бойцов. Поэтому с самого начала у нас был плавающий график дежурств. Он составлялся за 3 недели вперед, при этом мы руководствовались несколькими правилами:
• необходимо соблюсти равномерное распределение ночных и выходных смен по всем инженерам в пролонгированном расчете;
• крайне желательно минимизировать частоту переключения между дневными и ночными сменами (т.е. если уж вышел на этой неделе в ночь, то, скорее всего, и все смены будут ночными);
•
Совместить все эти правила, при этом создав график, соответствующий распределению часов наибольшей нагрузки – целое искусство, процесс отнимал много времени лидов, но до поры до времени был подъемен на “ручном приводе”.
С ростом команды, открытием новых филиалов, появлением в команде 1-й линии студентов старших курсов и дипломников, для которых важно учесть их обязательства по учебе – трудоемкость составления расписания выросла настолько, что впору было переименовывать тимлидов в специалистов по составлению этого самого расписания. Да и горизонт планирования схлопнулся с трех недель до пары дней – расписание на следующую неделю нередко высылалось поздно вечером в пятницу.
На помощь снова пришла любовь к автоматизации и фантазия. Было составлено расписание в ролевой модели, т.е. мы стали оперировать при составлении шаблона расписания не Ивановым/Петровым/Сидоровым, а ролями – A/B/C/etc…:
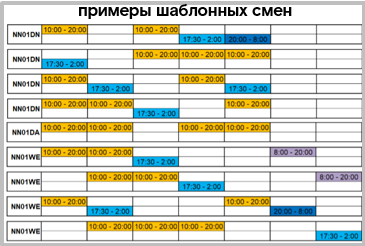
Столбец слева как раз и содержит те самые роли
В неделю нам требуется определенное число инженеров на каждую роль. Соответственно, ребята в онлайн-форме заранее выбирают для себя роль дежурства на неделю. А также указывают блоки на тайм-слотах, где их дежурство крайне нежелательно, если по тем или иным причинам выбранная роль достанется другому. Как она может достаться другому? Да очень просто: на нее может претендовать большее число инженеров, чем на этой роли требуется. Возникает конфликт интересов, который мы сперва пробовали решать по принципу “кто первый встал, того и тапки”. Но все же искали более адекватную схему
Как оказалось, инженеры тоже любят автоматизацию – в результате разгорелась отчаянная борьба роботов, стремящихся забучить “вкусные смены”. Для подогревания азарта борьбы реализовали капчи, и через какое-то время нас осенило – ведь капчи можно использовать не только для осложнения работы роботов, но и для более справедливого распределения смен между инженерами. И сделать это можно за счет смещения фокуса с “гонки за временем” в сторону “гонки за экспертизой”.
В результате капчи сейчас выглядят примерно следующим образом:
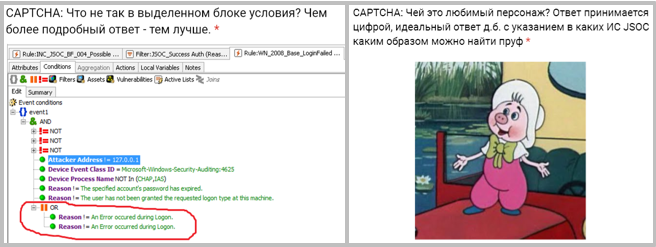
Ребята, давшие максимально точные и полные ответы, увеличивают свои шансы занять желаемые шаблонные роли в расписании. Те же, кому в этот раз не повезло, закрывают менее популярные смены и готовятся к следующим интеллектуальным играм. Да, мы снова тратим часть ресурса тимлидов на составление расписания (придумывание капчей и обработку ответов), но это интересная и полезная активность, которая не висит дамокловым мечом, как прежний ручной процесс.
Таким образом мы реализовали систему, которая с одной стороны считается справедливой всеми инженерами, а с другой – мотивирует на изучение различных технических аспектов, лежащих в профессиональной области знаний и навыков.
Алексей Кривоногов, заместитель директора Solar JSOC по развитию региональной сети

