

Кадр из м/ф «Инспектор Гаджет»
У людей, занимающихся обнаружением и расследованием компьютерных инцидентов, есть неписаная истина: «Инцидент рождается и умирает на хосте». Сегодня подавляющее большинство статей, исследований и правил детекта связаны именно с хостовыми логами (поэтому на рынке и появился EDR). Тем не менее очевидно, что события с хоста не дают полной картины происходящего и необходимо анализировать то, что происходит не только на конечных точках, но и в сети. Не так давно появился Network Traffic Analysis (NTA) – относительно молодой класс решений, который помогает обнаружить злоумышленника, «живущего в сети». Четкого понимания о функционале NTA у ИБ-сообщества пока не сформировалось, но мы со стороны центра мониторинга и реагирования на кибератаки все-таки попробуем рассказать, какой должна быть такая система и как она должна работать в идеале, чтобы полностью решать свои задачи.
Для анализа сетевого трафика традиционно использовались системы обнаружения атак IDS, работающие по сигнатурному принципу. С появлением SOC сетевые детекты стали обрастать правилами корреляции, которые базировались на различных событиях сетевого оборудования (Netflow, NGFW) и их встроенных механизмах (например, DPI – Application Control). Уже эти технологии дали большое преимущество при обнаружении и расследовании инцидентов. Например:
— хостовой детект, вероятно, покажет нам что-то подозрительное,
но без IDS-правил мы, скорее всего, не сможем однозначно идентифицировать угрозу (например, по детекту активности «подозрительный процесс -> сетевая активность», мы сможем понять, что имеем дело с Downloader, но без детекта на уровне сети не сможем определить семейство);
— некоторые хостовые детекты имеют альтернативное отображение в IDS-правилах, и при наличии известных проблем покрытия и масштабирования (которые возникают, когда надо собирать логи или отслеживать состояния того же EDR на большом количестве хостов) возможно перенести детектирующую логику с хостов на сеть, не потеряв таким образом детект события;
— злоумышленники стремятся обходить детекты, построенные на хостовых логах. Например, выгружают Enpdoint Drivers, отключают Kernel Callback, перенаправляют логи во временный файл, а после выполнения вредоносных действий возвращают поток логов в старое место, после чего удаляют временный файл. А вот сетевым детектам они противостоят реже и лишь в собственном «кастомном» инструментарии;
— некоторые IDS-правила не имеют прямого альтернативного отображения в детектах, построенных на хостовых логах (речь, конечно, про эксплуатацию уязвимостей различных сетевых протоколов (SMB, RDP) для запуска постороннего кода);
— анализ сетевой активности способен решить проблему профилирования пользовательских действий внутри корпоративной инфраструктуры, а значит, увеличивает вероятность обнаружения злоумышленника;
— технология Application Control может выявить использование злоумышленником вполне легитимных Remote Access Tool, в то время как хостовый детект, скорее всего, промолчит, так как подозрительная активность отсутствует.
Почему появился NTA
Но, к сожалению, в современных играх в «кошки-мышки» со злоумышленником даже указанных выше преимуществ недостаточно, чтобы своевременно обнаружить его присутствие. На то есть несколько причин.
Во-первых, при том, что IDS-правила достаточно эффективны при обнаружении инцидента, «слабости» сигнатурного подхода и принципов работы современных IDS-систем очевидны. Например, сигнатуру можно сбить даже простейшей операцией XOR, а задетектировать распределенное по времени сканирование крайне сложно.
Кроме того, при сработке IDS-правил обычно сохраняются только несколько сетевых пакетов или сессий (если говорить о распространенных Snort и Suricata). Но для правильного построения работы системы часто требуется дополнительный контекст происходящего, то есть аналитику нужно смотреть внутрь сетевого трафика.
Также у многих организаций нет выделенного IDS-решения. Вместо этого у них стоит обычный модуль в составе навороченного NGFW или UTM-комбайна, который из-за высокой загруженности и вовсе часто отключают. В случае же с подключением событий сетевой активности из NGFW или UTM в SIEM-систему остро встает вопрос количества EPS и стоимости ресурсов для их обработки. Ведь, как мы знаем, данный источник генерирует огромное количество событий.
Если все-таки завести NGFW или UTM в качестве источника в SIEM, то можно потенциально профилировать сетевую активность, но проблема обнаружения аномалий останется открытой, ведь таких возможностей у SIEM нет. Да и не должно быть. Скорее всего, мы сможем лишь отслеживать попытки постучаться на порты или адреса, не прописанные в легитимной активности (а теперь представьте, сколько времени это займет в крупной компании со сложной инфраструктурой).
Все это привело ИБ-сообщество к пониманию, что для эффективного обеспечения сетевого мониторинга и анализа сетевой активности как на периметре, так и в сегментах корпоративной сети необходим обособленный класс решений. Он был назван Network Traffic Analysis — NTA (или NDR).
Как и на заре EDR, у сообщества пока нет четкого понимания в части функционала, закладываемого в NTA/NDR, так что к этой категории относят совершенно разные продукты и решения.
Мы же со своей стороны хотели бы пофантазировать о том, каким может быть идеальный коммерческий NTA/NDR в современных реалиях и какие задачи
он должен решать, чтобы своевременно обнаруживать злоумышленника и помогать
при расследовании и реагировании на инциденты.
Что умеет идеальный NTA при обнаружении
Мы опишем задачи, с которыми должны справляться современные NTA/NDR-решения, в формате противодействия подходам, применяемым злоумышленниками.
Подход №1
— Злоумышленник использует известные хакерские утилиты/инструменты/ВПО, 1-day уязвимости
— Противодействие: IDS-правила
— Как решается сейчас: модули IDS в NGFW или UTM
В данном пункте может быть огромное количество примеров, но мы просто отметим, что наш опыт мониторинга и расследований инцидентов подсказывает, что в 2020 году все еще можно поймать злоумышленника посредством IDS-правил. И вот почему:
— злоумышленники до сих пор очень часто используют 1-day уязвимости EternalBlue и начинают брать на вооружение BlueKeep, SMBGhost;
— злоумышленники зачастую ленивы и редко переписывают протоколы общения известного ВПО с серверами управления;
— злоумышленники используют известные инструменты BloodHound, Impacket и другие, которые работают с протоколами и компонентами ОС – SMB, WMI, LDAP.
Пункт в общем-то очевидный. Остается лишь решить вопрос доверия к источнику IDS-правил, если вы вдруг их не пишите сами.
Подход №2
— Злоумышленник использует легитимные средств удаленного управления
— Противодействие: Application Control
— Как решается сейчас: модули Application Control в NGFW или UTM
Злоумышленники часто используют легитимные средства удаленного управления: UltraVnc, TeamViewer, Ammyy Admin, Radmin, AnyDesk и др. Без капли сомнения (и стеснения) они устанавливают эти утилиты на хост, еще и разбавляют инструментарий различными «ухищрениями»: проксируют трафик через определенные порты для преодоления Firewall, используют Dll Hijacking/Dll SideLoading для подгрузки утилитами своих библиотек и скрытной работы, прячут данные утилиты вглубь бинарных файлов, рассылаемых по электронной почте.
Вопрос количества протоколов и ПО, определяемых компонентом Application Control в идеальном NTA/NDR всегда останется открытым – ему ведь не нужно поддерживать их столько же, сколько NGFW или UTM… Или все-таки нужно? Но детектировать самые известные легитимные средства удаленного управления оно точно должно.
Подход №3
— Злоумышленники используют административные протоколы управления (RDP, SSH)
— Противодействие: профилирование сетевой активности с использованием
статистических алгоритмов
— Как решается сейчас: события с NGFW или UTM в SIEM и попытка «ручного профилирования»
Для осознания того, что происходит в сети, нужно профилирование сетевой активности на уровне хоста. Это аксиома. Вы наверняка слышали про систему UEBA (User and Entity Behavior Analytics). К сожалению, ее работающих вариантов пока не так много, но искреннее верим, что именно в продуктах класса NTA/NDR эта технология должна раскрыться – ведь она призвана улучшить и дополнить функционал обнаружения.
Над технической реализацией пусть фантазируют вендоры, но мы уверены, что в NTA/NDR нужен компонент, который будет анализировать сетевые потоки, «гуляющие» как внутри инфраструктуры, так и за ее пределы. И результатом этого анализа хочется видеть статистическую обработку: кто, как, когда и куда ходил, делал ли он это раньше, как часто.
История из жизни. В одном из наших расследований злоумышленник, получив доступ к хосту, стал расширять свое присутствие в инфраструктуре, заражая ВПО интересные ему серверы, при этом серверы он определял по факту – после захода на них по протоколу RDP. Логи на серверах хранились последние полгода (да, злоумышленник лентяй и не стал заметать следы), и по результатам их анализа стало ясно, что за последние три месяца с зараженного хоста на эти серверы ни разу не ходили по протоколу RDP.
К сожалению, на момент, когда мы подключились к расследованию, злоумышленник уже «обжился» в инфраструктуре. Но если бы был механизм профилирования сетевой активности, то он бы смог выявить аномалию: ведь за три месяца с заражённого хоста не было RDP-сессий в сторону этих серверов, а тут сразу восемь за короткий период. Сводный график из результатов расследования выглядел так:

Подход №4
— Злоумышленник использует модифицированный (обход сигнатурного детекта) или неизвестный ранее инструментарий
— Противодействие: профилирование сетевой активности с использованием
статистических алгоритмов, применение неточных алгоритмов определения «схожести» трафика
— Как решается сейчас: экспортом различных сетевых событий (трафика) и обработкой их самописными обработчикамискриптами
Это самый интересный кейс, ведь указанный подход злоумышленника говорит о его высокой квалификации. Противодействие с помощью «идеального» NTA/NDR проиллюстрируем двумя примерами.
Первый пример – выявление зараженных систем путем анализа обращений к серверам управления CNC.
Итак, у нас есть хост, зараженный неизвестным типом ВПО, и он периодически обращается (в данном примере достаточно «шумно») к своему CNC через http. Вот так:

Здесь мы оставляем за рамками обсуждения тематику обнаружения чего-либо в зашифрованном трафике и считаем, что наш «идеальный» NTA/NDR работает в режиме SSL-инспекции.
Как мы можем задетектировать такую активность, если, например, сервер управления CNC не входит в список известных индикаторов компрометации и не стоит у нас на мониторинге? Тут нам поможет профилирование сетевой активности (вряд ли сервер управления CnC будет самым популярным по числу обращений, а количество и интервал запросов подсветят нам «не пользовательские» запросы) и алгоритмы определения «похожести» сетевого трафика (техническую реализацию оставим на усмотрение вендора).
Если обратить внимание на рисунок выше, то можно заметить, что у всех запросов схожий размер сетевых пакетов, небольшие интервалы времени, путь обращения в коротких запросах хоть и рандомный, но имеет одинаковую длину, путь в длинных запросах имеет общую часть (до второго знака =). Этих данных должно хватить «идеальному» NTA/NDR для того, чтобы подсветить подозрительную активность и своевременно обнаружить присутствие злоумышленника в инфраструктуре.
Второй пример – выявление зараженных систем путем анализа внутреннего трафика инфраструктуры и выявление паттернов схожести.
Не секрет, что при написании протоколов общения клиентских и серверных частей ВПО разработчики, как правило, формируют статический формат передаваемых данных,
в котором у каждого позиционного байта, слова или двойного слова есть своя интерпретация. При этом зачастую все данные могут быть зашифрованы на одном ключе или иметь, например, имитовставку, которую вредонос будет искать при обработке сетевого пакета. Приведем пример общения зараженных хостов внутри инфраструктуры (пакеты на рисунке уже отфильтрованы по содержанию payload, поэтому Wireshark думает, что это NetBIOS ):
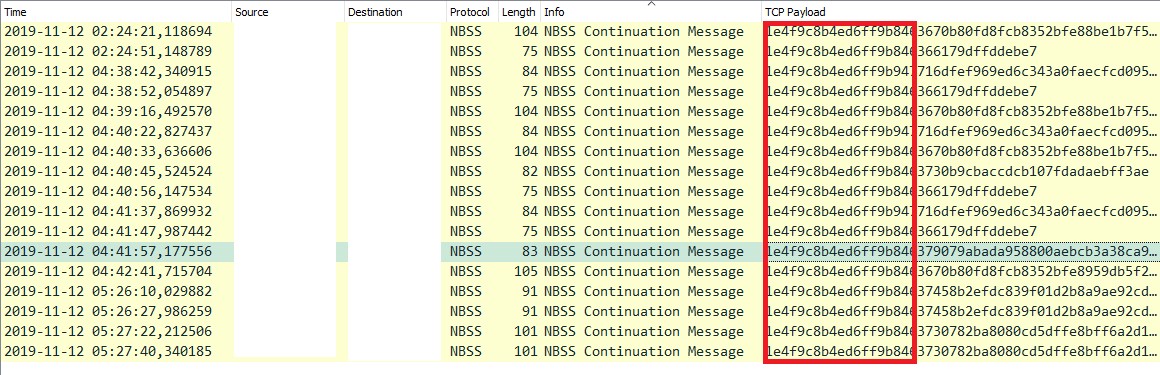
Во всех TCP-сессиях (здесь отдельные пакеты) между зараженными хостами передавался TCP payload, который начинался с двух одинаковых dword. Именно так модуль ВПО, работающий на зараженной системе, узнавал предназначенные для себя сетевые пакеты.
Так как же обнаружить применение подобного инструментария злоумышленником, если мы еще не проводили реверс сэмпла, разбор протокола общения модулей, да и вообще не знаем, что заражены? Здесь нам также поможет механизм нашего NTA/NDR, который сможет обнаружить паттерн среди передаваемых данных в TCP payload внутри инфраструктуры, принимая во внимание дополнительные условия (хосты, порты, размеры сессий, протоколы).
Конечно, говоря о данном подходе, мы осознаем потенциальный уровень False Positive при разработке или применении вендором статистических алгоритмов обработки как сетевой активности, так и сетевого трафика, но ведь NTA/NDR – это отдельный класс решений, и он призван решить в первую очередь имеющиеся проблемы с обнаружением и расследованием инцидентов в сети (и False Positive – не такая уж высокая цена за это). Да и к тому же даже сигнатурный подход порой порождает ложные события.
Экспорт данных и трафика
Классический процесс в ходе расследования и реагирования на инцидент информационной безопасности – это расшифровка трафика с зараженного хоста (если он, конечно, хранится). Это помогает восстановить полную хронологию действий злоумышленника.
Вернемся к последнему рисунку: предположим, что мы сумели обнаружить модуль ВПО на хосте, провели его реверсивный анализ, обнаружили ключ шифрования и восстановили формат передаваемых данных между модулями. Теперь мы можем написать скрипт, расшифровать TCP payload, получить список команд, передаваемых на зараженный хост, и результат их работы. Для этого нам надо получить все TCP payload`ы, содержащие в начале два magic dword, через API «идеального» NTA/NDR и передать результат нашему скрипту для расшифровки.
Другой вариант: экспорт отдельных сущностей (пакетов или сессий).
Но в таком случае наш скрипт обрастет парочкой (а, может, и не парочкой) лишних строк, которые будут парсить трафик.
Насколько это реально?
Конечно, такое описание функционала «идеального» NTA/NDR может вызывать споры, но мы лишь рассказали, чего ждем от данного класса решений и какие проблемы в обнаружении и расследовании инцидентов, на наш взгляд, он сможет решить.
И все-таки не хочется, чтобы завтра инструментарий, работающий исключительно на сигнатурном анализе из 90-x, вдруг начали называть NTA или NDR. Этому молодому классу решений (который, к слову, является одним из краеугольных камней современного SOC наряду с SIEM и EDR) нужен глоток свежего воздуха в виде новых подходов к глубокому анализу трафика, новых методов выявления угроз и возможностей по хранению и экспорту данных для расследования и ретроспективного анализа.
Игорь Залевский, руководитель отдела расследования киберинцидентов JSOC CERT

