
Давным-давно, в далёкой-далёкой Солнечной галактике, ещё до того, как она стала частью вселенной Ростелеком, в небольшом продукте webProxy возникла потребность не только фильтровать сетевой трафик, но и строить по нему статистику с последующим ее хранением. На тот момент колоночные БД ещё не были так популярны, как сейчас. Единственным подходящим аналогом оказалась платная БД HP Vertica. Как в Солнечной галактике решили эту задачу и к чему в итоге пришли, расскажем под катом.

Сначала мы решили создать собственную БД. В итоге, она была написана на OCaml с бинарным хранением колонок (текстовые представления сжимались через lz4) и собственным, довольно гибким, языком запросов на S-выражениях. Партиционирование осуществлялось за сутки.
Пример запроса: 
Это был не самый удобный и быстрый, но расширяемый и кастомизируемый вариант.
Время шло, как и потребность ускорить построение статистики и отчётов по трафику. Поэтому мы стали рассматривать и другие варианты:
- чистый Postgres;
- Postgres + cstore_fdw;
- Сlickhouse;
- Elastic.
Сравнение Postgres vs Elastic
На первом этапе мы сравнивали Elastic и Postgres + cstore. Postgres рассматривался наиболее пристально, потому что он уже использовался в системе, и была в наличии экспертиза по работе с ним.
Elastic тоже активно использовался в компании. Несмотря на «привлекательность» полнотекстового поиска и его скорости, от Elastic пришлось отказаться ввиду слишком большого объёма, занимаемого данными на диске. В плане скорости Elastic выигрывал на простых запросах примерно в 3 раза, например, по запросу «ТОП 20 сайтов за неделю». А на более сложных – до 9-ти раз: «ТОП 20 сайтов по трафику за месяц».
Однако это было лучше собственной базы, у которой уходили на это минуты против 5-6 секунд в Elastic и 15-55 секунд в Postgres.
Сравнение Postgres vs Clickhouse
Исходные данные
С https://github.com/wizardjedi/clickhouse-test мы взяли контейнеры с Postgres и Clickhouse. Эти контейнеры были предназначены для создания таблицы.
Вид таблицы для Postgres'а:

Primary key пришлось убрать, так как foreign table в Postgres не позволяет это делать.
Для Clickhouse создание такой таблицы имеет следующий вид:
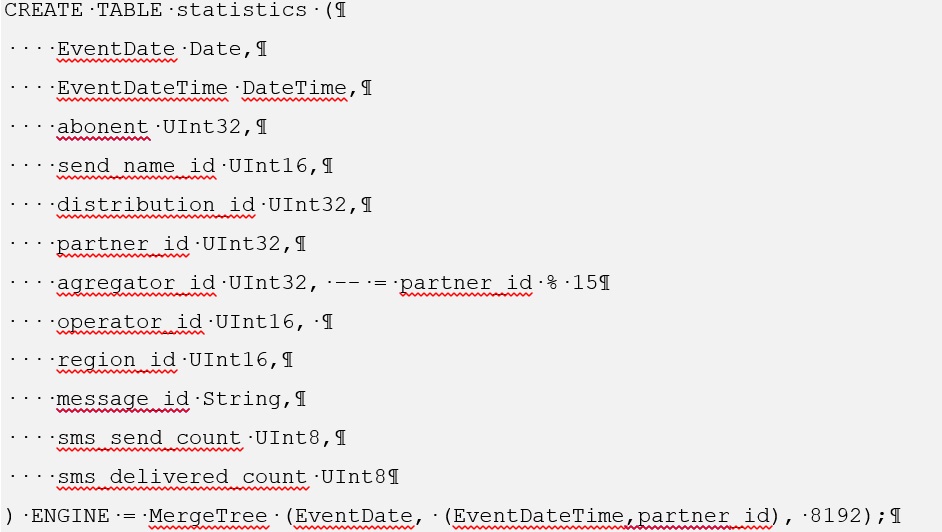
Для ознакомления с процессом установки сstore для Postgres следует перейти по ссылке https://github.com/citusdata/cstore_fdw .
Также при установке cstore нужно установить пакет postgresql-server-dev-X.Y.
При сравнении производительности были использованы следующие размеры данных (в мегабайтах):

Исходные данные – это просто sql-запрос с перечислением всех кортежей, т.е. сырые данные.
Во время выполнения запросов, особенно тяжелых, помимо данных замерялись размеры БД.
Выявлено, что для Clickhouse они точно не увеличивались.

Параметры вычислительной системы
Производитель: Intel
Линейка: сore i5
Модель: 8250U
Тактовая частота: 1.60GHz на ядро
Количество ядер: 4
RAM: 16 GB
SSD: 256 GB
Загрузка данных в БД
Для такого объема данных в Clickhouse они загрузились довольно быстро: 1 час 40 минут (это для 600 млн кортежей).
Сначала мы планировали загрузить все одним файлом, но отобразилась ошибка «bad_alloc». Видимо, из-за отсутствия возможности у Clickhouse выделить память. Решения проблемы не было найдено. Поэтому 600 млн кортежей были разбиты на 30 файлов по 20 млн. В этом случае каждый файл загружался чуть больше 3 минут.
С Postgres все было сложнее, но только вначале. Загрузка raw sql-файлов, в которых содержится команда INSERT INTO <table_name> (attributes) VALUES tuples весьма затратна по времени. Следовательно все было сконвертировано в csv-формат и выполнена команда COPY <table_name> FROM WITH CSV.
Стоит отметить, что сначала мы загрузили данные в обычную таблицу Postgres'а, откуда скопировали в foreign table, которой управляет cstore. В результате, загрузка в Postgres из файла csv-формата тоже заняла чуть меньше двух часов.
Сравнение производительности
Сравнение производительности Postgres и Clickhouse приведено в таблице ниже. Но без построения индексов и изменения параметров БД. В определенный момент память на диске почти кончилась, в связи с чем возникла необходимости удалить из Postgres'а не сжатую обычную таблицу. Сейчас в наличии имеются только таблицы в Clickhouse и в Postgres cstore.
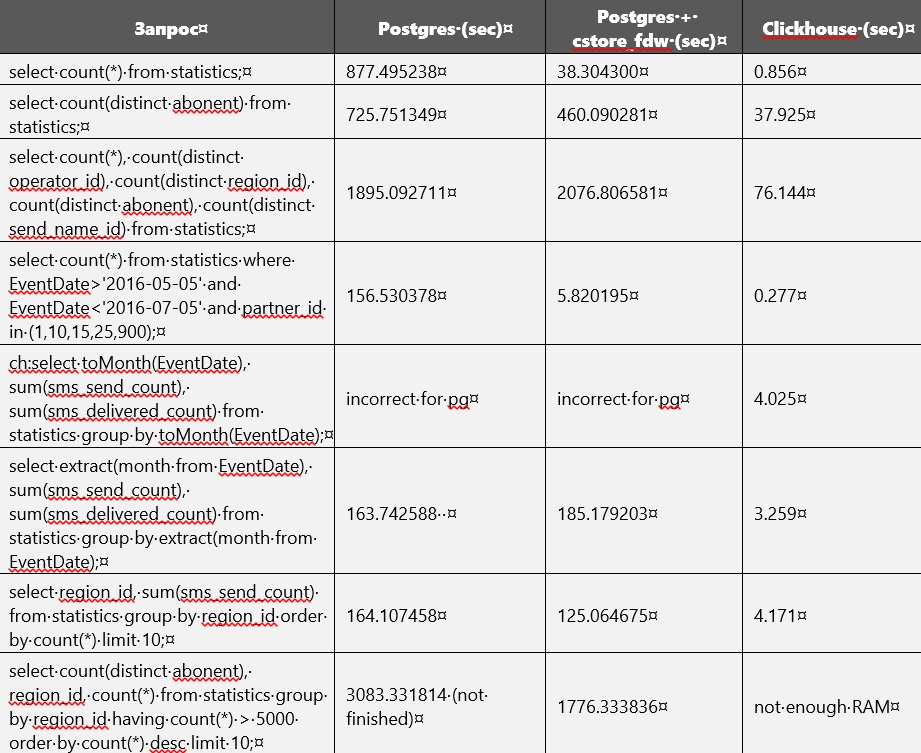
Видимо, cstore ориентируется на первый указанный при создании атрибут. Иными словами, все данные он сортирует по нему. Это можно легко заметить, так как запросы, связанные с EventDate, быстрее выполнялись в cstore, чем в Postgres.
При выполнении запросов Postgres иногда занимал до 27 GB на внешнем диске для временных файлов.
Clickhouse занимает много оперативной памяти.
В конфигурационном файле /etc/clickhouse/users.xml были указаны <max_memory_usage>12000000000</max_memory_usage> и <max_bytes_before_external_sort>1000000000</max_btes_before_external_sort>.
Для некоторых запросов оперативной памяти не хватало, из-за чего нам пришлось ее увеличить. После этого обработка запросов продолжилась, но на последнем запросе все равно прервалась. В наличии имелось еще несколько параметров для ограничения потребляемой памяти https://clickhouse.yandex/docs/ru/query_language/queries/ .
Так получилось, что в Clickhouse мы добавили чуть больше данных: 695_640_000 кортежей вместо 600_000_000, но это не помешало ему одержать победу.
У cstore_fdw можно настраивать различные параметры https://github.com/citusdata/cstore_fdw/issues/174, https://github.com/citusdata/cstore_fdw, которые влияют на производительность.
Партиционирование
Что касается партиционирования, оно есть и в Clickhouse https://github.com/yandex/ClickHouse/blob/master/docs/ru/table_engines/custom_partitioning_key.md, https://clickhouse.yandex/docs/ru/table_engines/custom_partitioning_key/, и в Postgres (10 и 11 версиях). Пример партиционирования в clickhouse можно посмотреть на https://github.com/yandex/ClickHouse/blob/master/dbms/tests/queries/0_stateless/00502_custom_partitioning_local.sql и https://github.com/yandex/ClickHouse/issues/1513.
Использование в Postgres партиционирования возможно при условии, что cstore работает только с foreign table, так как для него нужно создавать server, а server для обычных таблиц указывать нельзя. Foreign table нельзя разбивать на партиции, она сама может выступать как партиция. Следовательно, есть только один возможный способ использования партиционирования: создать обычную родительскую таблицу, к ней в виде партиций можно «прицепить» foreign table, которые уже работают на cstore_fdw.
В Clickhouse партиционирование работает из коробки.
Вывод
В результате мы решили использовать Clickhouse, поскольку он шустрый: всегда минимум в 10 раз быстрее аналогов. На серверах памяти обычно бывает больше 32 Gb, 64 и 128, так что запросы на таблицах около 50 Gb будут выполняться отлично. Если таблица будет очень большой, то есть партиционирование, либо же поможет тонкая настройка параметров clickhouse-server'а.

