
 Решение задачи распознавания изображений (OCR) сопряжено с различными сложностями. То картинку не получается распознать из-за нестандартной цветовой схемы или из-за искажений. То заказчик хочет распознавать все изображения без каких-либо ограничений, а это далеко не всегда возможно. Проблемы разные, и решить их сходу не всегда удается. В этом посте мы дадим несколько полезных советов, исходя из опыта разруливания реальных ситуаций у заказчиков.
Решение задачи распознавания изображений (OCR) сопряжено с различными сложностями. То картинку не получается распознать из-за нестандартной цветовой схемы или из-за искажений. То заказчик хочет распознавать все изображения без каких-либо ограничений, а это далеко не всегда возможно. Проблемы разные, и решить их сходу не всегда удается. В этом посте мы дадим несколько полезных советов, исходя из опыта разруливания реальных ситуаций у заказчиков.Но сначала немного истории. Прошло немало времени с момента выхода статьи о том, как мы переписывали сервис фильтрации. В ней мы немного рассказали о фильтрации и обработке сообщений, о том, как устроен наш сервис фильтрации в целом. В этот раз мы постараемся ответить на вопрос «А как же мы обрабатываем изображения, как взаимодействуют сервисы, и что происходит с системой под нагрузкой?» Если оперировать статьей про сервис фильтрации, то сейчас мы будем рассматривать только одну ветку взаимодействия сервисов – это взаимодействие сервиса фильтрации и OCR.
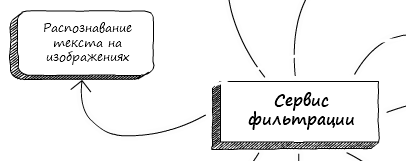
Что такое OCR?
Прежде чем говорить о взаимодействии сервисов и проблемах применения OCR попробуем понять, что такое OCR. Возьмем
Оптическое распознавание символов (англ. optical character recognition, OCR) — механический или электронный перевод изображений рукописного, машинописного или печатного текста в текстовые данные, использующиеся для представления символов в компьютере (например, в текстовом редакторе).
Если говорить просто, то взяли картинку, отправили на распознавание,

Еще можно взять опредление OCR с сайта ABBYY, которое выглядит проще.
Оптическое распознавание символов (англ. Optical Character Recognition – OCR) – это технология, которая позволяет преобразовывать различные типы документов, такие как отсканированные документы, PDF-файлы или фото с цифровой камеры, в редактируемые форматы с возможностью поиска.
А зачем оно (распознавание изображений) нам нужно?
Распознавание изображений мы можем использовать хоть на домашнем ПК для преобразования цифровых изображений в редактируемые текстовые данные.Но стоящая перед нами задача гораздо шире (DLP-система все-таки): нам нужно контролировать поток информации в организации.
DLP-системы давно появились на рынке и сейчас входят в привычный арсенал корпоративных СЗИ (средств защиты информации). Перед DLP стоит задача контроля движения графической информации (отсканированных документов, скриншотов, фотографий). Причем не просто контроля движения графических файлов, а в первую очередь, анализа их содержимого. Система должна уметь понимать, с какой именно информацией она столкнулась, сравнить с образцами защищаемой информации и обеспечить возможности для дальнейшего поиска этой информации пользователем. Применение других средств анализа, таких, как сравнение с цифровыми отпечатками, вычисление хэша, анализ по формату, размеру и структуре файла, также являются ценными источниками информации, но не позволяют ответить на вопрос: «а какой текст передается в данной картинке?» А между тем текст все еще является самым распространённым носителем структурированной информации, в том числе в графических файлах.
Традиционно для распознавания графической информации используют технологию OCR (что это такое мы уже определили). На самом деле OCR – это вообще единственный класс технологий, которые предоставляют возможности извлечения текстовой информации из изображений. Поэтому тут речь не то чтобы о традиционном подходе, а скорее об отсутствии выбора.
Сколько изображений приходит на обработку в DLP-систему?
Неужели нельзя обойтись без OCR? На самом ли деле так много изображений приходит в DLP, что нужно применять OCR? Ответ на этот вопрос – «Да!». За сутки в систему может попадать более миллиона изображений, и во всех этих изображениях может содержаться текст.
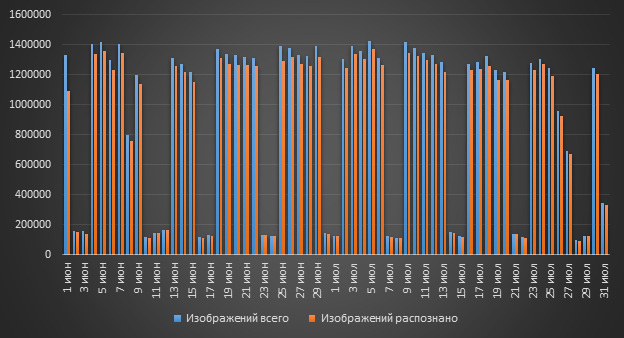
OCR в составе DLP-системы «Ростелеком–Солар» используются в компаниях нефтегазовой отрасли и госструктурах. Все заказчики используют возможности OCR для детектирования конфиденциальных данных в отсканированных документах. Что может содержаться в такой «графике»? Да все, что угодно. Это могут быть сканы различных внутренних документов, например, содержащие ПДн. Или информация из категории коммерческой тайны, ДСП (для служебного пользования), финансовая отчетность и т.п.
Как OCR распознает изображения?
Процесс выглядит следующим образом: DLP перехватывает сообщение, содержащее изображение (скан документа, фотографию и т.п.), определяет, что изображение действительно есть в сообщении, извлекает его и отправляет на распознавание в модуль OCR. На выходе DLP получает информацию о содержимом изображения (да и сообщения в целом) в виде извлеченного TEXT/PLAIN.
Если говорить о взаимодействии сервисов непосредственно в нашей системе Solar Dozor, то сервис фильтрации отправляет изображения (если они есть) из сообщения в сервис извлечения текста изображений (OCR). Последний, после завершения распознавания, отдаёт полученный текст в mailfilter. Получается что-то вроде жонглирования изображениями и текстом.

Рассмотрим механизм распознавания глубже на примере работы OCR-технологий ABBYY, которые мы используем в собственной DLP.
Пожалуй, главной проблемой для OCR при распознавании текста является написание того или иного символа. Если взять любую букву алфавита (например, русского или английского), то для каждой мы найдем несколько вариантов написания. OCR-движки решают эту задачу несколькими способами:
- Нахождение символа по паттерну. Например, с использованием различных шрифтов написания.
- Выявление признаков написания символа.
Если приводить достаточно грубый пример работы, то OCR разбивает текст на символы, которые он предварительно выявил в изображении, и накладывает их на готовые шаблоны. Дальше проверяется, похож символ на шаблонное написание или нет. Когда символ идентифицирован, он преобразуется в код символа в применяемой кодировке. В результате такого процесса символы складываются в слова, предложения в итоговый текст.
Про работу OCR достаточно много различных статей. Подробно о работе OCR можно почитать, например, здесь https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/
Как готовить OCR в целом для распознавания?
Мы уже выяснили, что в DLP может попадать более миллиона изображений. Но все ли изображения из этого миллиона нам полезны?
Ответ на вопрос более чем очевиден – конечно, нет. Но почему нам будут полезны не все изображения? Ответ на этот вопрос тоже достаточно прозрачен: в почте «гуляет» очень много картинок из подписей в сообщениях. Наверное, 90% сообщений (если не больше) будут содержать логотип компании.
Подобные картинки слишком мелкие для распознавания, текста в них может не быть совсем. Здесь мы можем посоветовать (и даже настойчиво порекомендовать) задавать ограничения на размер распознаваемых изображений. При этом ограничения необходимо задавать как по нижней границе, так и по верхней. Вероятность отправки на обработку тяжелых файлов ниже, чем для картинок из подписи, но все же достаточно высока.
Стоит отметить, что цифровые изображения часто имеют разные дефекты. Маловероятно, что в DLP всегда будут попадать сканы документов в хорошем разрешении. Скорее наоборот, сканы всегда будут не в лучшем качестве и с большим количеством дефектов.
Например, в цифровом фото может быть искажена перспектива, оно может оказаться засвеченным или перевернутым, строки скана – изогнутыми. Такие искажения могут усложнять распознавание. Поэтому OCR-движки могут предварительно обрабатывать изображения, чтобы подготовить их к распознаванию. Например, изображение можно покрутить, преобразовать в ч/б, инвертировать цвета, скорректировать перекосы строк. Все это можно задать в настройках OCR и, как следствие, эти инструменты могут помочь улучшить распознавание текста в изображениях.
В итоге мы пришли к базовым принципам подготовки OCR к распознаванию:
- Определить размеры изображений, которые мы будем распознавать, как в pixels, так и в Мб.
- Включить препроцессинг изображений.
Для повышения эффективности работы OCR можно ещё кэшировать распознанные данные, чтобы не отправлять одни и те же изображения по несколько раз на распознавание.
На что еще следует обращать внимание при подготовке OCR, мы ниже расскажем на примерах использования этой технологии в боевой практике.
Какие челленджи возможны при эксплуатации OCR в DLP под большой нагрузкой?
1. Слишком широкие лимиты на размеры распознаваемых изображений
Начнем с того, о чем мы уже упомянули, – с лимитов.
Исходя из нашей практики, заказчики часто устанавливают слишком широкие лимиты на размеры распознаваемых графических файлов. Да, чтобы OCR работал хорошо, нужно ограничивать размеры изображений. Но заказчики стремятся контролировать все подряд, полагая, что даже в картинке размером 100x100 pixels и 5 Кб могут утечь ценные данные. В целом, конечно, 100х100 pixels и 5 Кб тоже ограничения, но слишком уж низки эти пороги.
Другая крайность – стремление распознать тяжелые файлы по несколько сотен Мб. Понятно, что через корпоративную почту такие изображения не пролезут из-за ограничений на размер пересылаемых сообщений. Но вот по другим каналам перехвата (например, с корпоративных сетевых шар) увесистые файлы настойчиво стремятся распознавать. Если же заказчик хочет добавить к этому еще и большой объем high-res изображений, то для этого нужно иметь соответствующие серверные мощности. В итоге, при столь широких минимальных и максимальных порогах на размер распознаваемых файлов создается высокая нагрузка на процессор на серверах, что замедляет работу всех подсистем.
Что здесь можно порекомендовать? Прежде всего проанализировать, в какой используемой в компании «графике» содержатся конфиденциальные данные, после чего прикинуть разумные минимальные и максимальные ограничения на размеры контролируемых изображений. Обычно мы рекомендуем заказчикам зафиксировать нижнюю границу разрешения изображения от 200 pixels, в идеале от 400 pixels (по осям X и Y), и размера файлов не меньше 20 Кб, лучше больше. Также не имеет смысла отправлять в OCR тяжеловесные изображения – они элементарно перегрузят ваши сервера и не факт, что будут распознаны.
2. Очереди на фильтрацию и таймауты обработки запросов
Чрезмерная нагрузка на серверы, возникающая по вышеописанным причинам, ведет по цепочке к увеличению времени распознавания изображений и обработки запросов в целом. В результате в DLP-системе начинает увеличиваться очередь сообщений на фильтрацию. Кроме того, в OCR-модуль могут приходить графические файлы, которые в принципе невозможно распознать (тяжелые файлы, низкое качество и т.п.), в результате чего возникают таймауты обработки изображений. Если нераспознаваемых файлов поступает много, а в системе установлены высокие таймауты на распознавание, сервис фильтрации ждёт, пока этот таймаут наступит, и только потом приступает к обработке следующего запроса. Весь процесс обработки может серьезно тормозиться.
Что можем посоветовать? При возникновении очереди на обработку графических изображений нужно посмотреть настройки OCR в DLP-системе и попробовать найти причину торможения. Это может происходить, например, из-за проблем межпроцессного взаимодействия на самом сервере. Вообще, эти проблемы заслуживают отдельного разговора. Некоторые подробности по общим вопросам можно узнать из статьи «Знакомство с межпроцессным взаимодействием на Linux».
Кроме этого важным моментом при настройке OCR является выставление адекватных таймаутов на распознавание изображений. В общем случае достаточно 90 секунд, чтобы изображение точно распозналось. Если из изображения не извлекся текст за 90 секунд, то можно предположить, что OCR не распознает изображение в принципе. В этом месте также могут возникать проблемы конфигурирования OCR, когда выставляют высокие таймауты на распознавание и тем самым делаются попытки распознать нераспознаваемое.
Что еще может стать причиной таймаута? Здесь мы снова вернемся к вопросу конфигурирования системы. Сервис фильтрации, как и сервис OCR, оперирует тредами, которые обрабатывают сообщения и изображения. Система может быть некорректно сконфигурирована в части количества обработчиков сервиса фильтрации и количества обработчиков OCR. Например, у сервиса фильтрации будет много тредов-обработчиков, а у OCR всего один. В такой ситуации в какие-то моменты OCR может просто не успевать обрабатывать все запросы на распознавание, и таким образом будут появляться таймауты обработки изображений.
Подобное поведение системы наводит на мысли о проблемах проектирования и багах в архитектуре, но на самом деле это не так. Архитектура нашей DLP предоставляет возможности гибкой конфигурации системы и настройки её под нужды заказчиков. Например, мы можем достаточно просто настроить один OCR на работу с двумя сервисами фильтрации без ущерба производительности.
3. Нераспознаваемые изображения
Если в DLP-систему попадает на анализ изображение, которое OCR не может распознать, существует несколько вариантов решения проблемы.
По каким причинам изображения могут не распознаваться? Например, по следующим:
1. Нестандартная цветовая схема изображения.
2. Низкое разрешение изображения.
3. Неправильная ориентация изображения и содержащегося в нем текста в пространстве.
4. Перекосы строк и искажения пропорций текста в изображении и др.
Приведем пример: у одного из заказчиков в процессе мониторинга выяснилось, что OCR не распознает pdf-документы, выполненные в нестандартной цветовой схеме. То есть изображение извлекалось из PDF-документа в штатном режиме, но когда дело доходило до обработки OCR-модулем, тот не понимал цветовую схему картинки и выдавал на выходе «квадрат Малевича». В нашем интерфейсе картинка выглядела примерно так:

В OCR-движках заложены различные функции автоматической коррекции изображения, которые сильно повышают шансы на успешное распознавание содержащегося в нем текста. Однако, на практике эти волшебные инструменты не всегда срабатывают. В данном конкретном случае мы донастроили для заказчика OCR-модуль таким образом, чтобы он распознавал эту нестандартную цветовую схему.
5. Несоответствие одного из параметров документа заданным размерам распознаваемых
изображений.
Например, в конфигурации системы заданы границы размеров распознаваемых изображений 200х1000 pixels, а в OCR поступил файл размером 500х1500 pixels (верхний лимит превышен). В этом случае необходимо исправить настройки OCR для распознавания таких изображений.
Это, пожалуй, один из самых популярных сценариев донастройки системы после того, как нам говорят, что OCR не работает.
Почему OCR не на агентах?
OCR в DLP-системах реализуется в двух вариантах – на агентах и на серверах. Мы являемся сторонниками второго подхода, поскольку распознавание изображений прямо на рабочей станции создает высокую нагрузку на ее процессор и, соответственно, тормозит работу других приложений. OCR сама по себе весьма прожорливая технология даже для серверов, и её применение требует правильного планирования процессорных мощностей и контроля эффективности.
При этом многие отечественные компании, в особенности в госсекторе, до сих пор владеют достаточно старым парком ПК. Что происходит в этом случае? Пользователи начинают жаловаться ИТ-подразделению на «торможение» ПК, а айтишники в конце концов выясняют, что причиной торможения является OCR-модуль DLP-системы. Это раздражает и их, и пользователей, которые не могут оперативно решать рабочие задачи. В конечном итоге все это складывается в головную боль для безопасника, у которого и других задач полно.
Использование OCR на агентах оправдано лишь тогда, когда DLP-система работает «в разрыв». В этом случае распознавание изображения должно происходить ровно в тот момент, когда пользователь совершает действия с этим графическим файлом на своей рабочей станции. То есть DLP-система должна мгновенно решить судьбу документа, содержащего это изображение – разрешить его к отправке/копированию или запретить. Но на практике только единицы заказчиков используют DLP-систему в режиме активной блокировки, и это касается не только нашей собственной DLP. Здесь работает принцип «все, что можно вынести для проверок на сервер, должно выполняться на сервере».
Итого
Технологии OCR предоставляют возможности распознавания графических изображений, а мы в дополнение всегда даем общие рекомендации по конфигурированию системы. Однако в конкретном проекте может возникать необходимость донастройки работы OCR-модуля под специфические потребности заказчика как на этапе пилотирования и внедрения решения, так и на этапе его промышленной эксплуатации. Это не просто нормально – это единственно верный путь, который даст ощутимый результат, сделает работу OCR в компании максимально эффективной и снизит до минимума утечки конфиденциальной информации через графические изображения.
Никита Игонькин, ведущий инженер сервиса компании «Ростелеком-Солар»

