
Можно ли полностью защититься от кибератак? Наверное, можно, если окружить себя всеми существующими средствами защиты и нанять огромную команду экспертов управлять процессами. Однако понятно, что в реальности это невозможно: бюджет на информационную безопасность не бесконечный, и инциденты все же будут происходить. А раз они будут происходить, значит, к ним нужно готовиться!
В этой статье мы поделимся типовыми сценариями расследования инцидентов, связанных с вредоносным ПО, расскажем, что искать в логах, и дадим технические рекомендации в отношении того, как настроить средства защиты информации, чтобы повысить шансы на успех расследования.

Классический процесс по реагированию на инцидент, связанный с вредоносным ПО, подразумевает такие стадии как обнаружение, сдерживание, восстановление и т.д., однако все ваши возможности, по сути, определяются еще на стадии подготовки. Например, скорость выявления заражений напрямую зависит от того, насколько хорошо в компании настроен аудит.
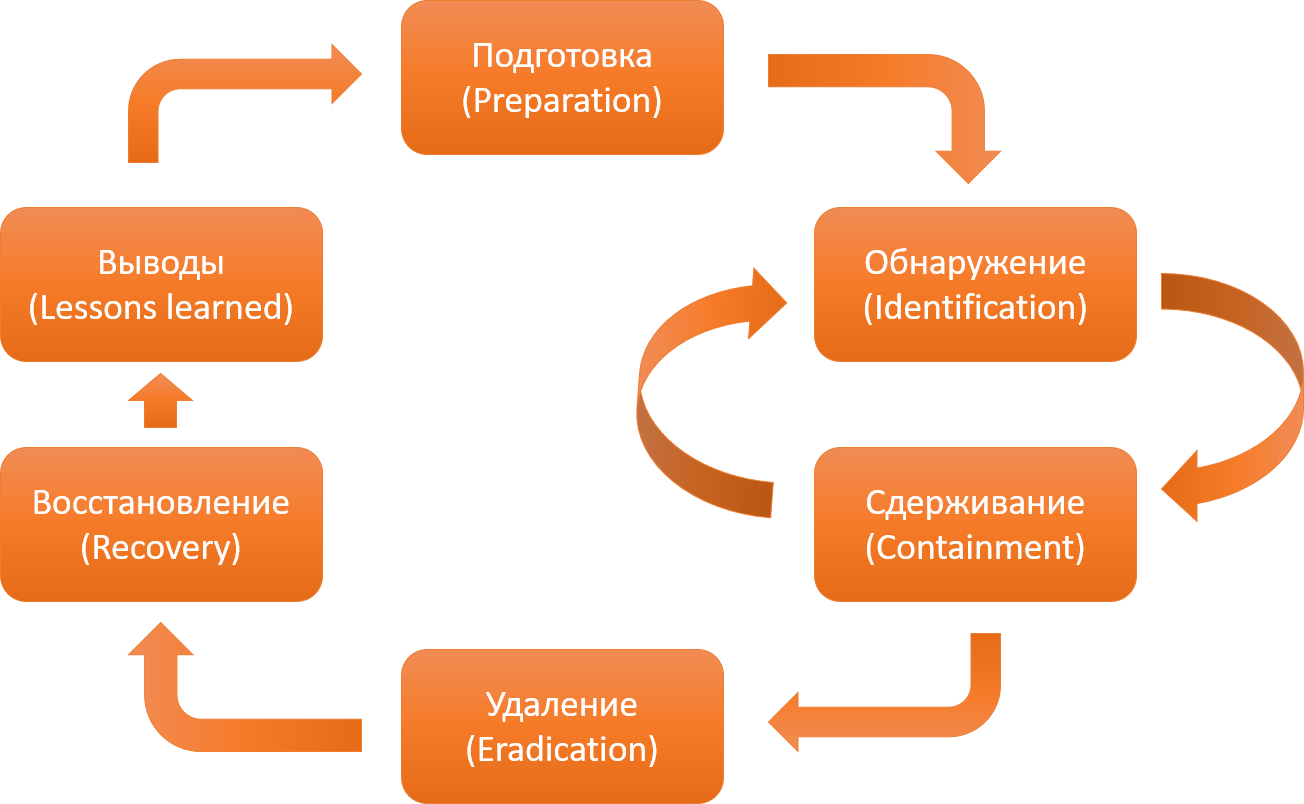
Классический цикл реагирования на инциденты по методике SANS
В общих чертах действия аналитиков в ходе расследования выглядят следующим образом:
Разумеется, все-все возможные гипотезы проверять нет смысла — как минимум, из-за того, что время ограничено. Поэтому и здесь мы рассмотрим наиболее вероятные версии и типовые сценарии расследования инцидентов, связанных с вредоносным ПО.
В рамках проработки этой версии следует выполнить три простых действия:

Вывод всех запущенных процессов и служб в Event Log Explorer
В теории это достаточно тривиальный процесс. Однако на практике встречается ряд подводных камней, к которым следует подготовиться.
Во-первых, стандартная настройка аудита Windows не логирует факты запуска процессов (событие 4688), поэтому его надо включить заблаговременно в доменной групповой политике. Если же так получилось, что этот аудит не был включен заранее, можно попробовать получить список исполняемых файлов из других артефактов Windows, например, из реестра Amcache. Извлечь данные из этого файла реестра можно с помощью утилиты AmcaheParser.
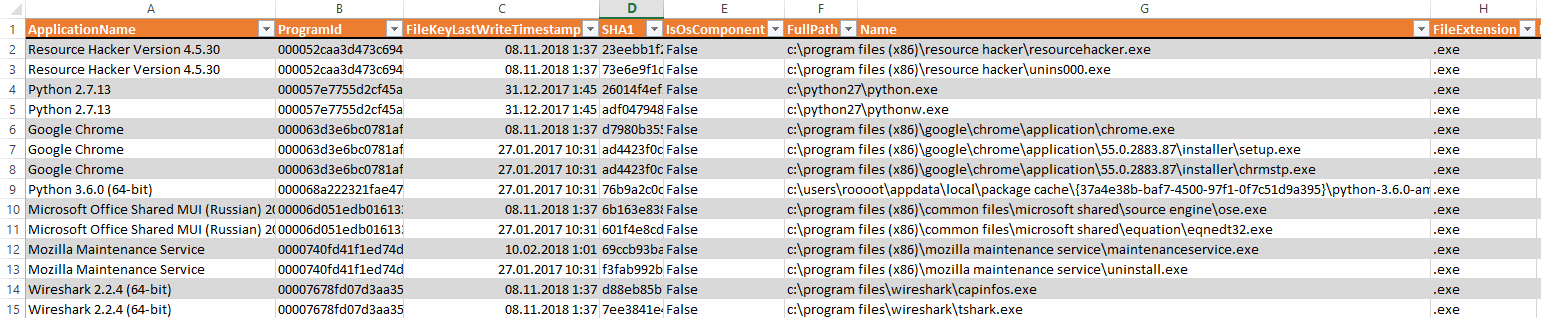
Пример извлечения фактов запуска процессов из Amcache.hve
Однако этот метод не очень надежен, поскольку он не дает точной информации о том, когда конкретно и сколько раз запускался процесс.
Во-вторых, свидетельства запуска таких процессов, как cmd.exe, powershell.exe, wscript.exe и других интерпретаторов, принесет мало пользы без информации о командной строке, с которой процессы были запущены, т.к. в ней содержится путь к потенциально вредоносному файлу-скрипту.
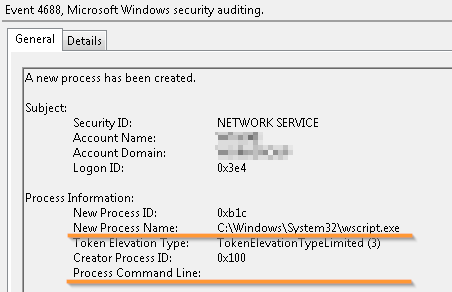
Запуск интерпретатора скриптов без информации о том, что за скрипт был запущен
Еще одна особенность Windows заключается в том, что аудит командной строки запускаемого процесса производится отдельной настройкой доменной групповой политики: Computer Configuration -> Policies -> Administrative Templates -> System -> Audit Process Creation -> Include command line in process creation events. При этом довольно популярная Windows 7/2008 не логирует командную строку без установленного обновления KB3004375, поэтому поставьте его заранее.
Если же так получилось, что вы заранее ничего не настроили или забыли про обновление, можно попытаться узнать расположение скрипта в файлах Prefetch ( утилита в помощь). В них содержится информация о всех файлах (в основном DLL), загруженных в процесс в первые 10 секунд жизни. И скрипт, содержащийся в аргументах командной строки интерпретатора, наверняка будет присутствовать там же.

Пример поиска «потерянного» аргумента командной строки в Prefetch
Но и этот метод совсем не надежен — при очередном запуске процесса кеш Prefetch перезатрется.
Подготовка к расследованию:
Один из вариантов реагирования на подобные сигналы тревоги может сводиться к проверке того, какой процесс осуществил соединение — если это интернет-браузер, то при отсутствии других фактов, указывающих на компрометацию, инцидент можно считать ложной тревогой.
Существует много способов узнать, какой процесс инициировал соединение: можно запустить netstat и увидеть текущие сокеты или собрать дамп памяти и потом натравить на него volatility, которая может показать в том числе уже завершенные соединения. Но все это долго, не масштабируемо и самое главное — не надежно. Намного надежнее получать всю необходимую информацию из security-журнала Windows.
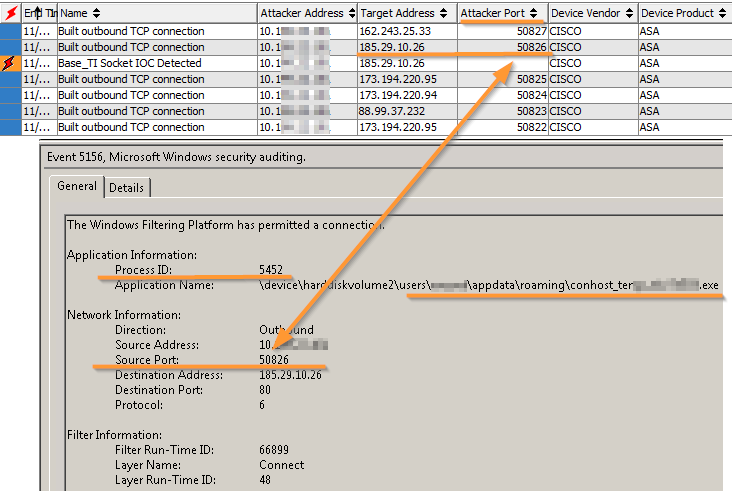
Корреляция события «обращение к вредоносному IP-адресу» в SIEM-системе HPE Arcsight и соответствующий обращению процесс в security-логе Windows
Подготовка к расследованию
Чтобы отработать этот сценарий на пользовательской машине, следует включить запись в журнал security всех сетевых соединений. Сделать это можно на основе событий аудита платформы фильтрации и аудита отбрасывания пакетов.
При этом журнал может начать быстро забиваться, поэтому увеличьте его размер до 2-3 Гб. По нашему опыту, на обычном пользовательском хосте такого объема хватает примерно на 3 дня записи всех сокетов, а этого срока вполне достаточно для успешного расследования.
На высоконагруженных серверах, вроде контроллеров домена, web-серверов и т.п., так делать не стоит, журнал переполнится намного быстрее.
Если потенциальная разведка осуществляется с одного хоста, расследовать ее можно, в том числе, с помощью журналов запущенных процессов. Однако если хостов много, а атаки однотипные (произошли в одно и то же время, или запрашивался одинаковый набор сущностей из AD), то имеет смысл в первую очередь исключить типовое ложное срабатывание. Для этого надо сформировать и проверить следующие версии:
Обнаружить эти узловые точки (общего пользователя или процесс) поможет статистический анализ логов. Это метод мы демонстрировали в одной из прошлых статей применительно к журналам DNS-серверов. Однако использовать подобные эффективные методы расследования не получится, если хранение данных не было организовано заранее.
Подготовка к расследованию
Необходимо организовать долговременное хранение, как минимум, следующих данных из журналов общих сервисов сети:
 Предположим случилось страшное: вы обнаружили, что учетная запись доменного администратора скомпрометирована.
Предположим случилось страшное: вы обнаружили, что учетная запись доменного администратора скомпрометирована.
Реагирование на такой инцидент включает в себя очень большой пласт работ, в том числе анализ всех действий, совершенных из-под этой учетной записи. Часть подобного расследования можно провести, используя только журналы контроллера домена. Например, можно изучить события, связанные выдачей тикетов Kerberos, чтобы понять, куда ходили из-под этой учетки. Или же можно проанализировать события, связанные с изменением критичных объектов AD, чтобы проверить, не изменялся ли состав высокопривилегированных групп (тех же доменных администраторов). Естественно, все это требует заранее настроенного аудита.
Однако существует проблема, связанная с тем, что злоумышленник, имеющий права доменного администратора, может изменять объекты AD с помощью техники DCShadow, которая основана на механизме репликации между контролерами домена.
Суть ее заключается в том, что злоумышленник сам представляется контролером домена, вносит изменения в AD и затем реплицирует (синхронизирует) эти изменения с легитимными контроллерами, таким образом обходя настроенный на них аудит изменений объектов. Результатом подобной атаки может быть добавление пользователя в группу доменных администраторов или более хитрые закрепления через изменение атрибута SID History либо модификацию ACL-объекта AdminSDHolder.
Для того чтобы проверить версию о наличии незафиксированных изменений в AD, требуется изучить журналы репликации контроллеров: если в репликации участвовали IP-адреса, не являющиеся контроллерами домена, можно с высокой долей уверенности утверждать, что атака была успешной.
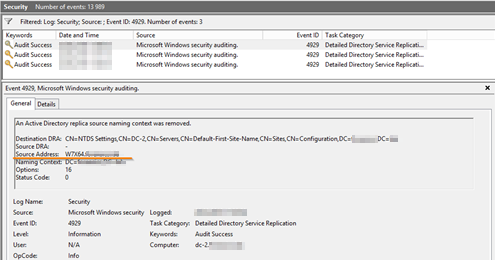
Удаление неизвестного контроллера домена из репликации AD
Подготовка к расследованию:
В этой статье мы рассказали о некоторых типовых сценариях расследования инцидентов ИБ и мерах превентивной подготовки к ним. Если вам интересна эта тема и вы готовы пойти дальше, рекомендую обратить внимание вот на этот документ, описывающий, в каких событиях Windows можно обнаружить следы применения популярных хакерских техник.
Закончить хотел бы цитатой из недавнего исследования одной компании, работающей в сфере кибербезопасности:
В этой статье мы поделимся типовыми сценариями расследования инцидентов, связанных с вредоносным ПО, расскажем, что искать в логах, и дадим технические рекомендации в отношении того, как настроить средства защиты информации, чтобы повысить шансы на успех расследования.
Классический процесс по реагированию на инцидент, связанный с вредоносным ПО, подразумевает такие стадии как обнаружение, сдерживание, восстановление и т.д., однако все ваши возможности, по сути, определяются еще на стадии подготовки. Например, скорость выявления заражений напрямую зависит от того, насколько хорошо в компании настроен аудит.
Классический цикл реагирования на инциденты по методике SANS
В общих чертах действия аналитиков в ходе расследования выглядят следующим образом:
- Формирование версий, объясняющих причины возникновения инцидента (например, «вредоносное ПО установилось на хост, потому что пользователь запустил его из фишингового письма» или «инцидент — ложная тревога, потому что пользователь посетил легитимный сайт, располагающийся на том же хостинге, что и сервер управления вредоносным ПО»).
- Приоритизация версий по степени вероятности. Вероятность рассчитывается (а скорее — прикидывается) на основе статистики прошлых инцидентов, критичности инцидента или системы, а также на базе собственного опыта.
- Проработка каждой версии, поиск фактов, доказывающих или опровергающих ее.
Разумеется, все-все возможные гипотезы проверять нет смысла — как минимум, из-за того, что время ограничено. Поэтому и здесь мы рассмотрим наиболее вероятные версии и типовые сценарии расследования инцидентов, связанных с вредоносным ПО.
Сценарий 1
У вас есть подозрение, что некритичная система была скомпрометирована вредоносным ПО. Ввиду некритичности системы на проверку отведено совсем немного времени.Первое, что делают большинство инженеров реагирования, — запускают проверку антивирусом. Однако, как мы знаем, антивирус не так уж сложно обойти. Поэтому стоит сформировать и проработать следующую высоковероятную версию: вредоносное ПО представляет собой отдельный исполняемый файл или службу.
В рамках проработки этой версии следует выполнить три простых действия:
- Отфильтровать журнал Security по событию 4688 — так мы получим список всех запускавшихся процессов.
- Отфильтровать журнал System по событию 7045 — так мы получим список установок всех служб.
- Определить новые процессы и службы, которых раньше в системе не было. Скопировать эти модули и проанализировать их на предмет наличия вредоносного кода (просканировать несколькими антивирусами, проверить действительность цифровой подписи, декомпилировать код и т.п.).
Вывод всех запущенных процессов и служб в Event Log Explorer
В теории это достаточно тривиальный процесс. Однако на практике встречается ряд подводных камней, к которым следует подготовиться.
Во-первых, стандартная настройка аудита Windows не логирует факты запуска процессов (событие 4688), поэтому его надо включить заблаговременно в доменной групповой политике. Если же так получилось, что этот аудит не был включен заранее, можно попробовать получить список исполняемых файлов из других артефактов Windows, например, из реестра Amcache. Извлечь данные из этого файла реестра можно с помощью утилиты AmcaheParser.
Пример извлечения фактов запуска процессов из Amcache.hve
Однако этот метод не очень надежен, поскольку он не дает точной информации о том, когда конкретно и сколько раз запускался процесс.
Во-вторых, свидетельства запуска таких процессов, как cmd.exe, powershell.exe, wscript.exe и других интерпретаторов, принесет мало пользы без информации о командной строке, с которой процессы были запущены, т.к. в ней содержится путь к потенциально вредоносному файлу-скрипту.
Запуск интерпретатора скриптов без информации о том, что за скрипт был запущен
Еще одна особенность Windows заключается в том, что аудит командной строки запускаемого процесса производится отдельной настройкой доменной групповой политики: Computer Configuration -> Policies -> Administrative Templates -> System -> Audit Process Creation -> Include command line in process creation events. При этом довольно популярная Windows 7/2008 не логирует командную строку без установленного обновления KB3004375, поэтому поставьте его заранее.
Если же так получилось, что вы заранее ничего не настроили или забыли про обновление, можно попытаться узнать расположение скрипта в файлах Prefetch ( утилита в помощь). В них содержится информация о всех файлах (в основном DLL), загруженных в процесс в первые 10 секунд жизни. И скрипт, содержащийся в аргументах командной строки интерпретатора, наверняка будет присутствовать там же.
Пример поиска «потерянного» аргумента командной строки в Prefetch
Но и этот метод совсем не надежен — при очередном запуске процесса кеш Prefetch перезатрется.
Подготовка к расследованию:
- Включите расширенный аудит создания и завершения процессов.
- Включите логирование аргументов командной строки процессов.
- Установите обновление KB3004375 на Windows 7/Server 2008.
Сценарий 2
На периметровом маршрутизаторе зафиксировано обращение к серверу управления вредоносным ПО. IP-адрес вредоносного сервера получен из подписки threat intelligence средней надёжности.В одной из прошлых статей мы рассказывали, что TI-аналитики грешат добавлением в списки индикаторов компрометации IP-адресов серверов, которые хостят одновременно и центры управления вредоносным ПО, и легитимные веб-сайты. Если вы только начали формировать процессы реагирования, то на первых этапах лучше отказаться от использования подобных индикаторов, потому что каждая попытка пользователя зайти на легитимный веб-сайт будет выглядеть как полноценный инцидент.
Один из вариантов реагирования на подобные сигналы тревоги может сводиться к проверке того, какой процесс осуществил соединение — если это интернет-браузер, то при отсутствии других фактов, указывающих на компрометацию, инцидент можно считать ложной тревогой.
Существует много способов узнать, какой процесс инициировал соединение: можно запустить netstat и увидеть текущие сокеты или собрать дамп памяти и потом натравить на него volatility, которая может показать в том числе уже завершенные соединения. Но все это долго, не масштабируемо и самое главное — не надежно. Намного надежнее получать всю необходимую информацию из security-журнала Windows.
Корреляция события «обращение к вредоносному IP-адресу» в SIEM-системе HPE Arcsight и соответствующий обращению процесс в security-логе Windows
Подготовка к расследованию
Чтобы отработать этот сценарий на пользовательской машине, следует включить запись в журнал security всех сетевых соединений. Сделать это можно на основе событий аудита платформы фильтрации и аудита отбрасывания пакетов.
При этом журнал может начать быстро забиваться, поэтому увеличьте его размер до 2-3 Гб. По нашему опыту, на обычном пользовательском хосте такого объема хватает примерно на 3 дня записи всех сокетов, а этого срока вполне достаточно для успешного расследования.
На высоконагруженных серверах, вроде контроллеров домена, web-серверов и т.п., так делать не стоит, журнал переполнится намного быстрее.
Сценарий 3
Ваша NG/ML/Anti-APT система детектирования аномалий сообщает, что с 30 хостов происходит разведка с целью получения одних и тех же учетных записей.При попадании в новую сеть злоумышленники, как правило, пытаются узнать, какие сервисы присутствуют в ней и какие учетные записи используются — это очень помогает в процессе дальнейшего движения по инфраструктуре. В частности, эту информацию можно получить из самой Active Directory с помощью команды net user /domain.

Если потенциальная разведка осуществляется с одного хоста, расследовать ее можно, в том числе, с помощью журналов запущенных процессов. Однако если хостов много, а атаки однотипные (произошли в одно и то же время, или запрашивался одинаковый набор сущностей из AD), то имеет смысл в первую очередь исключить типовое ложное срабатывание. Для этого надо сформировать и проверить следующие версии:
- Разведка зафиксирована на 30 хостах в отношении одних и тех же объектов AD, потому что команду net запустил один и тот же легитимный пользователь — администратор.
- Разведка зафиксирована на 30 хостах в отношении одних и тех же объектов AD, потому что это сделало одно и тоже легитимное ПО.
Обнаружить эти узловые точки (общего пользователя или процесс) поможет статистический анализ логов. Это метод мы демонстрировали в одной из прошлых статей применительно к журналам DNS-серверов. Однако использовать подобные эффективные методы расследования не получится, если хранение данных не было организовано заранее.
Подготовка к расследованию
Необходимо организовать долговременное хранение, как минимум, следующих данных из журналов общих сервисов сети:
- Контроллеры домена — входы, выходы учетных записей и выдача билетов Kerberos (категория Account Logon в расширенных настройках аудита).
- Прокси-серверы — адреса, порты источника и внешнего сервера, а также полный URL.
- DNS-серверы — успешные и неуспешные DNS-запросы и их источник внутри сети.
- Периметровые маршрутизаторы — Built и Teardown для всех TCP/UDP-соединений, а также соединений, пытающихся нарушить правила логического доступа: например, попытки отправить DNS-запрос наружу напрямую, минуя корпоративный DNS-сервер.
Сценарий 4
Ваш домен скомпрометировали, и вас беспокоит, что злоумышленник мог закрепиться в инфраструктуре с использованием техники DCShadow.
Предположим случилось страшное: вы обнаружили, что учетная запись доменного администратора скомпрометирована. Реагирование на такой инцидент включает в себя очень большой пласт работ, в том числе анализ всех действий, совершенных из-под этой учетной записи. Часть подобного расследования можно провести, используя только журналы контроллера домена. Например, можно изучить события, связанные выдачей тикетов Kerberos, чтобы понять, куда ходили из-под этой учетки. Или же можно проанализировать события, связанные с изменением критичных объектов AD, чтобы проверить, не изменялся ли состав высокопривилегированных групп (тех же доменных администраторов). Естественно, все это требует заранее настроенного аудита.
Однако существует проблема, связанная с тем, что злоумышленник, имеющий права доменного администратора, может изменять объекты AD с помощью техники DCShadow, которая основана на механизме репликации между контролерами домена.
Суть ее заключается в том, что злоумышленник сам представляется контролером домена, вносит изменения в AD и затем реплицирует (синхронизирует) эти изменения с легитимными контроллерами, таким образом обходя настроенный на них аудит изменений объектов. Результатом подобной атаки может быть добавление пользователя в группу доменных администраторов или более хитрые закрепления через изменение атрибута SID History либо модификацию ACL-объекта AdminSDHolder.
Для того чтобы проверить версию о наличии незафиксированных изменений в AD, требуется изучить журналы репликации контроллеров: если в репликации участвовали IP-адреса, не являющиеся контроллерами домена, можно с высокой долей уверенности утверждать, что атака была успешной.
Удаление неизвестного контроллера домена из репликации AD
Подготовка к расследованию:
- Для расследования действий, совершенных скомпрометированной учетной записью, необходимо заранее включить:
- Аудит входов, выходов учетной записи и выдачу билетов Kerberos (категория Account Logon в расширенных настройках аудита).
- Аудит изменений учетных записей и групп (категория Account Management).
- Для расследования версий, связанных с возможными применениями атаки DCShadow:
- Включить подробный аудит репликации службы каталогов.
- Организовать долговременное хранение событий 4928/4929, в которых источник событий не является легитимным контроллером домена (признак DCShadow).
Заключение
В этой статье мы рассказали о некоторых типовых сценариях расследования инцидентов ИБ и мерах превентивной подготовки к ним. Если вам интересна эта тема и вы готовы пойти дальше, рекомендую обратить внимание вот на этот документ, описывающий, в каких событиях Windows можно обнаружить следы применения популярных хакерских техник.
Закончить хотел бы цитатой из недавнего исследования одной компании, работающей в сфере кибербезопасности:
«Российские директора по информационной безопасности в большинстве своём склонны давать пессимистичные ответы [на вопросы исследования]. Так, половина (48%) полагает, что бюджет не изменится никак, а 15% думают, что финансирование сократится».Для меня лично это сигнал к тому, что оставшийся бюджет в новом году лучше потратить не на покупку новомодных СЗИ вроде Machine Learning детекторов, очередной IDS нового поколения и т.д., а на тонкую настройку тех СЗИ, которые уже есть. А лучшее СЗИ — это правильно настроенные логи Windows. IMHO.

