
Сейчас все больше говорят о статическом анализе для поиска уязвимостей как необходимом этапе разработки. Однако многие говорят и о проблемах статического анализа. Об этом много говорили на прошлом Positive Hack Days, и по итогам этих дискуссий мы уже писали о том, как устроен статический анализатор. Если вы пробовали какой-нибудь серьезный инструмент, вас могли отпугнуть длинные отчеты с запутанными рекомендациями, сложности настройки инструмента и ложные срабатывания. Так все-таки нужен ли статический анализ?
Наш опыт подсказывает, что нужен. И многие проблемы, которые возникают при первом взгляде на инструмент, вполне можно решить. Попробую рассказать, что может делать пользователь и каким должен быть анализатор, чтобы его использование было полезным, а не вносило «еще один ненужный инструмент, который требуют безопасники».

Итак, мы уже говорили о теоретических ограничениях статического анализа. Например, глубокий статический анализ пытается решить экспоненциальные по сложности задачи. Поэтому каждый инструмент ищет компромисс между временем работы, затрачиваемыми ресурсами, количеством найденных уязвимостей и количеством ложных срабатываний.
Зачем вообще нужен глубокий анализ? Любая IDE очень быстро находит ошибки, иногда даже связанные с безопасностью – какие вообще экспоненциальные задачи? Классический пример – SQL-инъекция (да и любая другая инъекция, типа XSS, RCE и подобного), которая проходит через несколько функций (то есть чтение данных от пользователя и выполнение запроса происходят в разных функциях). Для ее поиска нужен межпроцедурный анализ потока данных, а это задача экспоненциальной сложности. Согласитесь, без поиска таких уязвимостей анализ не может считаться глубоким. По этой же причине анализировать нужно код целиком, а не частями – иначе можно упустить межпроцедурные уязвимости.
В последние годы я получил немало опыта общения с (потенциальными) заказчиками разных статических анализаторов. В том числе мы обсуждаем претензии к инструментам по результатам первого использования (пилота). Большинство претензий так или иначе следуют из теоретических ограничений технологии. Помимо этого, инструменты могут просто не иметь нужного пользователю функционала. Однако, по моему мнению, анализаторы могут двигаться (и двигаются) в сторону пользователя в плане решения обозначенных дальше проблем. Но и нужно уметь пользоваться анализаторами, нивелируя последствия этих же проблем – как оказывается, это не так сложно. Давайте по порядку.
Можно представить модельную ситуацию: вы решили попробовать технологию в действии или выбираете статический анализатор – проводите пилот. Конечно, вы не доверяете тестовым примерам вендора и хотите попробовать проанализировать свой код (заодно можно найти реальные уязвимости и исправить их). Вам предоставляют инсталлятор или готовую виртуальную машину с системой на небольшой срок.
Сперва надо запустить анализ. Вы заходите в интерфейс, и, вроде бы, все должно быть понятно: загружаем в форму архив с исходным кодом и нажимаем «анализировать». Но нет: вы получаете несколько форм с разными полями, которые нужно как-то заполнить. Надо указать языки программирования, какие-то настройки анализатора, выбрать пакеты уязвимостей (откуда вы знаете, что в них входит?) и так далее. Вы проходите это испытание, и анализ начинается. А, нет – ошибка сканирования. «Формат не соответствует требованиям», «Для данного языка требуется сборка кода», «Не найдено файлов для сканирования»… Если вы не сами писали этот код, надо будет еще идти за помощью к разработчикам.

Разработчик сдает исходный код на тестирование
Отдельного внимания заслуживают требования к сборке кода. Большинство анализаторов для ряда языков требуют, чтобы код собирался во время анализа (JVM-языки — Java, Scala, Kotlin и тому подобные, C/C++, Objective-C, C#). Сами понимаете, какая это боль: воспроизвести окружение большого проекта для сборки на новой машине. С другой стороны, эти требования оправданы, они следуют из технологии анализа и специфики данных языков.
Как решают эти проблемы анализаторы? Во-первых, делают запуск анализа максимально автоматизированным. В идеале, достаточно загрузить файл любого формата, и анализатор сам должен понять, какие там языки, как попробовать провести сборку и как проставить по умолчанию остальные настройки, чтобы результаты были максимально полными. Понятно, что нельзя предусмотреть все – однако можно постараться обрабатывать большую часть случаев.
Требования к сборке нужно делать максимально мягкими. Например, для JVM-языков не нужно требовать сборки во время анализа – достаточно просить подгружать артефакты, то есть собранный код вместе с исходниками (а это существенно проще). Для XCode в случае Objective-C сборку можно автоматизировать для большинства случаев. Если не получилось собрать код, анализатор может попробовать провести частичный анализ. Его результаты будут не настолько полными, но это лучше, чем никаких результатов вообще. Также удобно, если модуль анализа можно поставить на машину к разработчику, где сборка кода уже настроена, при этом архитектура должна позволять вынести остальные модули и интерфейсную часть на другую машину.
Наконец, анализатор должен выдвигать максимально мягкие требования к формату и сам разбираться со входными файлами. Архив с исходным кодом, вложенные архивы, архив из репозитория, ссылка на репозиторий, архив с продуктива, исполняемый файл с продуктива – хорошо, если все это анализатор поддерживает.
Однако не стоит забывать, что анализатор не обладает искусственным интеллектом и всего предусмотреть не может. Поэтому при возникновении ошибок стоит ознакомиться с мануалом – там бывает много полезного по подготовке кода для анализа. Ну, и вся эта работа по запуску сканирования при внедрении анализатора проделывается только один раз для каждой кодовой базы. Чаще всего анализатор вообще встраивается в цикл CI, то есть проблем со сборкой не будет.
Ладно, сканирование запустили. Проходит час – результатов нет. Прогресс бар висит где-то посередине, непонятно с каким процентом и каким прогнозом по завершению. Проходит второй час – прогресс сдвинулся на 99 процентов и висит там уже полчаса. Проходит третий час – и анализатор падает, сообщая о нехватке оперативной памяти. Или висит еще час и завершается. Вы могли ожидать, что анализ пройдет с той же скоростью, как ваш checkstyle, и тут ожидания сильно разойдутся с реальностью.

Да, хороший статический анализатор может потреблять немало ресурсов, одну из причин выше я указал: нахождение сложных уязвимостей – экспоненциально сложная задача. Так что чем больше будет ресурсов и чем больше времени, тем качественнее будут результаты (при хорошем движке, конечно). И время анализа, и требуемые ресурсы предсказать действительно трудно – время работы алгоритмов статического анализа сильно зависит от языковых конструкций, от сложности кода, от глубины вызовов – от характеристик, которые сложно заранее просчитать.
Проблема с ресурсами – необходимое зло. Нужно внимательно относиться к выделению необходимых ресурсов, терпеливо ждать окончания сканирования, а также понимать, что точно спрогнозировать необходимые для анализатора ресурсы, даже при заданной кодовой базе, никто не сможет, и надо быть готовым к изменению этих параметров. Более того, требуемые параметры могут измениться даже без обновления кодовой базы – из-за обновления анализатора.
Все же и с этой проблемой анализатор может немного помочь. Он способен разделять по разным машинам ресурсоемкую часть (движки) и интерфейс. Это позволит не загружать машины лишними программами, которые будут тормозить их работу, при этом можно будет пользоваться интерфейсом системы при любой загруженности по сканированиям (например, для просмотра и редактирования результатов). Еще это позволит легко масштабироваться без переустановок всей системы (поднимаем анализатор на новой виртуалке, указываем IP основной машины – и вуаля).
Помимо этого, анализатор может разрешать выбирать глубину анализа, отключать тяжеловесные проверки, использовать инкрементальный анализ (при котором проверяется не весь код, а только изменившийся). Этими вещами нужно пользоваться очень аккуратно, так как они могут сильно влиять на результаты сканирования. Если вы пользуетесь такой функциональностью, рекомендуется с некоторой периодичностью проводить полный анализ.
Перейдем к результатам сканирования (долго же мы до них шли). Вы с трепетом ждете количества уязвимостей в окошке анализатора, и очень удивляетесь, увидев его. 156 критических, 1260 среднего и 3210 низкого уровня. Вы заходите на страницу с результатами и утопаете в количестве найденных проблем. Вы выгружаете pdf-отчет – и видите несколько тысяч страниц текста. Угадайте, что скажет разработчик кода, увидев такое полотно?

Безопасник везет разработчику отчет об уязвимостях
Но давайте все-таки попробуем посмотреть результаты, дадим ему шанс. Изучив повнимательнее несколько десятков вхождений, вы начинаете понимать, почему уязвимостей так много. Несколько уязвимости и правда выглядят серьезными, вы понимаете, что их нужно исправлять. Однако сходу вы находите с десяток ложных. А еще – огромное количество уязвимостей в коде библиотек. Не будете же вы исправлять библиотеки! И тут вы понимаете, сколько времени вы потратите на разбор результатов. И эту процедуру надо повторять каждую день, неделю, ну или как минимум каждый релиз. (На самом деле нет).
Начнем с того, что ложность срабатывания можно понимать очень по-разному. Кто-то не будет считать ложными только критические уязвимости, которые можно эксплуатировать прямо сейчас. Кто-то будет считать ложными только откровенные ошибки анализатора. Многое зависит от того, чего вы хотите от инструмента. Мы рекомендуем рассматривать практически все вхождения, так как даже уязвимость низкого уровня, которую сейчас нельзя проэксплуатировать, завтра может обернуться серьезной проблемой – например, при изменениях кода и внешних условий.
Ок, смотреть надо все вхождения, но это все еще огромный объем работы. И вот здесь анализаторы могут помочь очень хорошо. Важнейшая функция анализатора – это умение отслеживать уязвимости между сканированиями одного проекта, при этом отслеживать устойчиво к небольшим изменениям, стандартным для разработки кода. Это снимает проблему того, что длительный разбор уязвимостей нужно повторять: в первый раз вы потратите больше времени, удаляя ложные срабатывания и меняя критичность вхождений, однако далее вам нужно будет просматривать только новые уязвимости, которых будет в разы меньше.
Хорошо, но нужно ли в первый раз просматривать все уязвимости? Мы рекомендуем это делать, но, вообще говоря, это необязательно. Во-первых, анализаторы позволяют фильтровать результаты по директориям и файлам: например, при запуске сканирования вы можете сразу исключить из анализа какие-то компоненты, библиотеки, тестовый код. Это повлияет и на скорость анализа. Во-вторых, анализаторы позволяют фильтровать результаты по уязвимостям, то есть при старте сканирования можно ограничить набор уязвимостей. Наконец, помимо критичности анализатор может выдавать что-то вроде вероятности ложности уязвимости (то есть свою уверенность в данной уязвимости). Используя эту метрику, можно фильтровать результаты.
Отдельно стоит отметить технологию Software Composition Analysis (ее сейчас начинает поддерживать все большее количество инструментов на разном уровне). Технология позволяет обнаруживать использование библиотек в вашем коде, определять названия и версии, показывать известные уязвимости, а также лицензии. Эта технология может отделить библиотечный код от вашего собственного, что также позволит фильтровать результаты.
Получается, с проблемой обильных результатов анализа бороться можно, и это не очень сложно. И хотя первый просмотр результатов действительно может занять время, далее при пересканировании его будет тратиться все меньше. Однако еще раз отмечу, что к любой фильтрации результатов надо относиться осторожно – вы можете пропустить уязвимость. Даже если библиотека является известной, не значит, что в ней нет уязвимости. Если сейчас данная уязвимость обнаруживается плохо (то есть инструмент показывает много ложных срабатываний этой уязвимости), и вы ее отключаете, при обновлении анализатора вы можете пропустить уже настоящую уязвимость.
Разобрались с большим отчетом и ложными срабатываниями. Но вы хотите пойти дальше – убедиться, что анализатор находит те уязвимости, о наличии которых вы точно знаете (вы могли их заложить намеренно, или их нашел другой инструмент).

Для начала важно понимать, что анализатор мог не найти уязвимость по разным причинам. Самое простое – сканирование было неверно сконфигурировано (нужно обращать внимание на сообщения об ошибках). Но и с точки зрения технологии анализа причины могут быть разные. Статический анализатор состоит из двух важных компонентов: движок (в нем кроется вся алгоритмическая сложность и математика) и база правил поиска уязвимостей. Одна ситуация, когда движок позволяет находить уязвимость такого класса, но в базе правил уязвимости нет. В таком случае добавить правило обычно не составляет труда. Совсем другая ситуация, если движок в принципе не поддерживает такие уязвимость – тут доработка может быть очень существенной. Пример я приводил в начале статьи: SQL-инъекцию никогда не найдешь без алгоритмов анализа потока данных.
Статический анализатор должен реализовывать в движке набор алгоритмов, покрывающий доступные классы уязвимостей для данного языка программирования (анализ потока управления, потока данных, интервальный анализ и т.п.). Важным моментом является возможность добавлять в инструмент свои правила поиска уязвимостей – это позволит устранить первую причину пропуска уязвимости.
Таким образом, если вы не нашли имеющуюся уязвимость в результатах сканирования, для начала нужно разобраться в причине пропуска – обычно с этим может помочь вендор. Если причина в базе правил или в конфигурации сканирования, то ситуацию можно достаточно легко устранить. Важнее всего – оценить глубину анализа, то есть то, что в принципе позволяет искать движок.
Прочитав статью до этого места, можно предположить, что для работы с инструментом нужна глубокая экспертиза разработчика, ведь нужно понимать, какие срабатывания ложные, а какие истинные. По моему мнению, все зависит от того, насколько дружественно себя ведет инструмент. Если он предоставляет удобный и понятный функционал, понятные описания уязвимостей с примерами, ссылками и рекомендациями на разных языках, если инструмент показывает трассы для уязвимостей, связанных с анализом потока данных – для работы с ним не потребуется глубокая экспертиза разработчика с пониманием всех тонкостей языка программирования и фреймворков. Однако минимальный бэкграунд в разработке для того, чтобы читать код, все-таки должен быть.
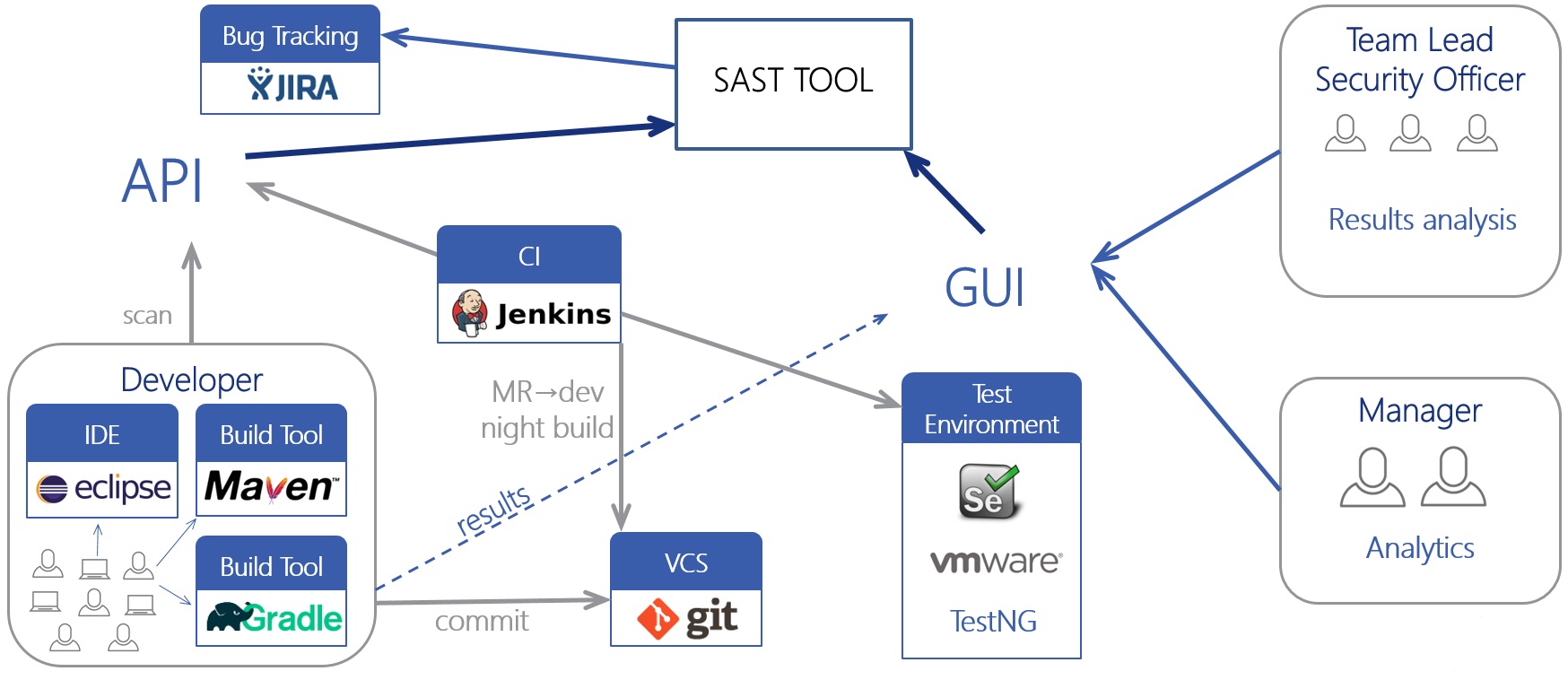
В конце статьи кратко коснемся одного из самых важных вопросов использования инструмента, а подробно его рассмотрим в следующих статьях. Допустим, вы решили использовать статический анализатор. Однако у вас есть налаженный процесс разработки, как технологический, так и организационный, и его менять не хочется (да никто и не даст).
Инструмент должен иметь полноценный неграфический интерфейс (например, CLI или REST API), с помощью которого вы сможете встроить анализатор в любой свой процесс. Хорошо, если у анализатора есть готовые интеграции с различными компонентами: плагины для IDE или систем сборки, интеграции с системами контроля версий, плагины для CI/CD серверов (Jenkins, TeamCity), интеграции с системами управления проектами (JIRA) или работы с пользователями (Active Directory).
Интеграция статического анализа в процесс разработки (так называемый SDLC) – наиболее эффективный способ использования, если процесс хорошо налажен и все участники договорились и знают, зачем это нужно. Постоянный анализ кода после его изменений или обновлений анализатора позволит находить уязвимости как можно раньше. Разделение ролей разработчиков и специалистов ИБ, четкое указание требований ИБ и мягкая интеграция в текущий процесс (например, в первое время – рекомендательный характер системы) позволит использовать инструмент безболезненно и полезно. Однако никто не отменял и ручное использование инструмента, если ваша модель разработки не подразумевает подобного процесса.
В статье собраны основные рекомендации по началу использования статического анализатора. Хороший анализатор работает на порядок лучше любого легковесного чекера, он ищет проблемы принципиально другой сложности. Поэтому нужно считаться с особенностями статического анализа как технологии, но при этом выбирать конкретный инструмент так, чтобы его функционал максимально сглаживал все такие особенности.
Наш опыт подсказывает, что нужен. И многие проблемы, которые возникают при первом взгляде на инструмент, вполне можно решить. Попробую рассказать, что может делать пользователь и каким должен быть анализатор, чтобы его использование было полезным, а не вносило «еще один ненужный инструмент, который требуют безопасники».
Про статический анализ
Итак, мы уже говорили о теоретических ограничениях статического анализа. Например, глубокий статический анализ пытается решить экспоненциальные по сложности задачи. Поэтому каждый инструмент ищет компромисс между временем работы, затрачиваемыми ресурсами, количеством найденных уязвимостей и количеством ложных срабатываний.
Зачем вообще нужен глубокий анализ? Любая IDE очень быстро находит ошибки, иногда даже связанные с безопасностью – какие вообще экспоненциальные задачи? Классический пример – SQL-инъекция (да и любая другая инъекция, типа XSS, RCE и подобного), которая проходит через несколько функций (то есть чтение данных от пользователя и выполнение запроса происходят в разных функциях). Для ее поиска нужен межпроцедурный анализ потока данных, а это задача экспоненциальной сложности. Согласитесь, без поиска таких уязвимостей анализ не может считаться глубоким. По этой же причине анализировать нужно код целиком, а не частями – иначе можно упустить межпроцедурные уязвимости.
В последние годы я получил немало опыта общения с (потенциальными) заказчиками разных статических анализаторов. В том числе мы обсуждаем претензии к инструментам по результатам первого использования (пилота). Большинство претензий так или иначе следуют из теоретических ограничений технологии. Помимо этого, инструменты могут просто не иметь нужного пользователю функционала. Однако, по моему мнению, анализаторы могут двигаться (и двигаются) в сторону пользователя в плане решения обозначенных дальше проблем. Но и нужно уметь пользоваться анализаторами, нивелируя последствия этих же проблем – как оказывается, это не так сложно. Давайте по порядку.
Можно представить модельную ситуацию: вы решили попробовать технологию в действии или выбираете статический анализатор – проводите пилот. Конечно, вы не доверяете тестовым примерам вендора и хотите попробовать проанализировать свой код (заодно можно найти реальные уязвимости и исправить их). Вам предоставляют инсталлятор или готовую виртуальную машину с системой на небольшой срок.
Запуск анализа
Сперва надо запустить анализ. Вы заходите в интерфейс, и, вроде бы, все должно быть понятно: загружаем в форму архив с исходным кодом и нажимаем «анализировать». Но нет: вы получаете несколько форм с разными полями, которые нужно как-то заполнить. Надо указать языки программирования, какие-то настройки анализатора, выбрать пакеты уязвимостей (откуда вы знаете, что в них входит?) и так далее. Вы проходите это испытание, и анализ начинается. А, нет – ошибка сканирования. «Формат не соответствует требованиям», «Для данного языка требуется сборка кода», «Не найдено файлов для сканирования»… Если вы не сами писали этот код, надо будет еще идти за помощью к разработчикам.
Разработчик сдает исходный код на тестирование
Отдельного внимания заслуживают требования к сборке кода. Большинство анализаторов для ряда языков требуют, чтобы код собирался во время анализа (JVM-языки — Java, Scala, Kotlin и тому подобные, C/C++, Objective-C, C#). Сами понимаете, какая это боль: воспроизвести окружение большого проекта для сборки на новой машине. С другой стороны, эти требования оправданы, они следуют из технологии анализа и специфики данных языков.
Как решают эти проблемы анализаторы? Во-первых, делают запуск анализа максимально автоматизированным. В идеале, достаточно загрузить файл любого формата, и анализатор сам должен понять, какие там языки, как попробовать провести сборку и как проставить по умолчанию остальные настройки, чтобы результаты были максимально полными. Понятно, что нельзя предусмотреть все – однако можно постараться обрабатывать большую часть случаев.
Требования к сборке нужно делать максимально мягкими. Например, для JVM-языков не нужно требовать сборки во время анализа – достаточно просить подгружать артефакты, то есть собранный код вместе с исходниками (а это существенно проще). Для XCode в случае Objective-C сборку можно автоматизировать для большинства случаев. Если не получилось собрать код, анализатор может попробовать провести частичный анализ. Его результаты будут не настолько полными, но это лучше, чем никаких результатов вообще. Также удобно, если модуль анализа можно поставить на машину к разработчику, где сборка кода уже настроена, при этом архитектура должна позволять вынести остальные модули и интерфейсную часть на другую машину.
Наконец, анализатор должен выдвигать максимально мягкие требования к формату и сам разбираться со входными файлами. Архив с исходным кодом, вложенные архивы, архив из репозитория, ссылка на репозиторий, архив с продуктива, исполняемый файл с продуктива – хорошо, если все это анализатор поддерживает.
Однако не стоит забывать, что анализатор не обладает искусственным интеллектом и всего предусмотреть не может. Поэтому при возникновении ошибок стоит ознакомиться с мануалом – там бывает много полезного по подготовке кода для анализа. Ну, и вся эта работа по запуску сканирования при внедрении анализатора проделывается только один раз для каждой кодовой базы. Чаще всего анализатор вообще встраивается в цикл CI, то есть проблем со сборкой не будет.
Процесс анализа
Ладно, сканирование запустили. Проходит час – результатов нет. Прогресс бар висит где-то посередине, непонятно с каким процентом и каким прогнозом по завершению. Проходит второй час – прогресс сдвинулся на 99 процентов и висит там уже полчаса. Проходит третий час – и анализатор падает, сообщая о нехватке оперативной памяти. Или висит еще час и завершается. Вы могли ожидать, что анализ пройдет с той же скоростью, как ваш checkstyle, и тут ожидания сильно разойдутся с реальностью.
Да, хороший статический анализатор может потреблять немало ресурсов, одну из причин выше я указал: нахождение сложных уязвимостей – экспоненциально сложная задача. Так что чем больше будет ресурсов и чем больше времени, тем качественнее будут результаты (при хорошем движке, конечно). И время анализа, и требуемые ресурсы предсказать действительно трудно – время работы алгоритмов статического анализа сильно зависит от языковых конструкций, от сложности кода, от глубины вызовов – от характеристик, которые сложно заранее просчитать.
Проблема с ресурсами – необходимое зло. Нужно внимательно относиться к выделению необходимых ресурсов, терпеливо ждать окончания сканирования, а также понимать, что точно спрогнозировать необходимые для анализатора ресурсы, даже при заданной кодовой базе, никто не сможет, и надо быть готовым к изменению этих параметров. Более того, требуемые параметры могут измениться даже без обновления кодовой базы – из-за обновления анализатора.
Все же и с этой проблемой анализатор может немного помочь. Он способен разделять по разным машинам ресурсоемкую часть (движки) и интерфейс. Это позволит не загружать машины лишними программами, которые будут тормозить их работу, при этом можно будет пользоваться интерфейсом системы при любой загруженности по сканированиям (например, для просмотра и редактирования результатов). Еще это позволит легко масштабироваться без переустановок всей системы (поднимаем анализатор на новой виртуалке, указываем IP основной машины – и вуаля).
Помимо этого, анализатор может разрешать выбирать глубину анализа, отключать тяжеловесные проверки, использовать инкрементальный анализ (при котором проверяется не весь код, а только изменившийся). Этими вещами нужно пользоваться очень аккуратно, так как они могут сильно влиять на результаты сканирования. Если вы пользуетесь такой функциональностью, рекомендуется с некоторой периодичностью проводить полный анализ.
Результаты анализа
Перейдем к результатам сканирования (долго же мы до них шли). Вы с трепетом ждете количества уязвимостей в окошке анализатора, и очень удивляетесь, увидев его. 156 критических, 1260 среднего и 3210 низкого уровня. Вы заходите на страницу с результатами и утопаете в количестве найденных проблем. Вы выгружаете pdf-отчет – и видите несколько тысяч страниц текста. Угадайте, что скажет разработчик кода, увидев такое полотно?
Безопасник везет разработчику отчет об уязвимостях
Но давайте все-таки попробуем посмотреть результаты, дадим ему шанс. Изучив повнимательнее несколько десятков вхождений, вы начинаете понимать, почему уязвимостей так много. Несколько уязвимости и правда выглядят серьезными, вы понимаете, что их нужно исправлять. Однако сходу вы находите с десяток ложных. А еще – огромное количество уязвимостей в коде библиотек. Не будете же вы исправлять библиотеки! И тут вы понимаете, сколько времени вы потратите на разбор результатов. И эту процедуру надо повторять каждую день, неделю, ну или как минимум каждый релиз. (На самом деле нет).
Начнем с того, что ложность срабатывания можно понимать очень по-разному. Кто-то не будет считать ложными только критические уязвимости, которые можно эксплуатировать прямо сейчас. Кто-то будет считать ложными только откровенные ошибки анализатора. Многое зависит от того, чего вы хотите от инструмента. Мы рекомендуем рассматривать практически все вхождения, так как даже уязвимость низкого уровня, которую сейчас нельзя проэксплуатировать, завтра может обернуться серьезной проблемой – например, при изменениях кода и внешних условий.
Ок, смотреть надо все вхождения, но это все еще огромный объем работы. И вот здесь анализаторы могут помочь очень хорошо. Важнейшая функция анализатора – это умение отслеживать уязвимости между сканированиями одного проекта, при этом отслеживать устойчиво к небольшим изменениям, стандартным для разработки кода. Это снимает проблему того, что длительный разбор уязвимостей нужно повторять: в первый раз вы потратите больше времени, удаляя ложные срабатывания и меняя критичность вхождений, однако далее вам нужно будет просматривать только новые уязвимости, которых будет в разы меньше.
Хорошо, но нужно ли в первый раз просматривать все уязвимости? Мы рекомендуем это делать, но, вообще говоря, это необязательно. Во-первых, анализаторы позволяют фильтровать результаты по директориям и файлам: например, при запуске сканирования вы можете сразу исключить из анализа какие-то компоненты, библиотеки, тестовый код. Это повлияет и на скорость анализа. Во-вторых, анализаторы позволяют фильтровать результаты по уязвимостям, то есть при старте сканирования можно ограничить набор уязвимостей. Наконец, помимо критичности анализатор может выдавать что-то вроде вероятности ложности уязвимости (то есть свою уверенность в данной уязвимости). Используя эту метрику, можно фильтровать результаты.
Отдельно стоит отметить технологию Software Composition Analysis (ее сейчас начинает поддерживать все большее количество инструментов на разном уровне). Технология позволяет обнаруживать использование библиотек в вашем коде, определять названия и версии, показывать известные уязвимости, а также лицензии. Эта технология может отделить библиотечный код от вашего собственного, что также позволит фильтровать результаты.
Получается, с проблемой обильных результатов анализа бороться можно, и это не очень сложно. И хотя первый просмотр результатов действительно может занять время, далее при пересканировании его будет тратиться все меньше. Однако еще раз отмечу, что к любой фильтрации результатов надо относиться осторожно – вы можете пропустить уязвимость. Даже если библиотека является известной, не значит, что в ней нет уязвимости. Если сейчас данная уязвимость обнаруживается плохо (то есть инструмент показывает много ложных срабатываний этой уязвимости), и вы ее отключаете, при обновлении анализатора вы можете пропустить уже настоящую уязвимость.
Проверим анализатор
Разобрались с большим отчетом и ложными срабатываниями. Но вы хотите пойти дальше – убедиться, что анализатор находит те уязвимости, о наличии которых вы точно знаете (вы могли их заложить намеренно, или их нашел другой инструмент).
Для начала важно понимать, что анализатор мог не найти уязвимость по разным причинам. Самое простое – сканирование было неверно сконфигурировано (нужно обращать внимание на сообщения об ошибках). Но и с точки зрения технологии анализа причины могут быть разные. Статический анализатор состоит из двух важных компонентов: движок (в нем кроется вся алгоритмическая сложность и математика) и база правил поиска уязвимостей. Одна ситуация, когда движок позволяет находить уязвимость такого класса, но в базе правил уязвимости нет. В таком случае добавить правило обычно не составляет труда. Совсем другая ситуация, если движок в принципе не поддерживает такие уязвимость – тут доработка может быть очень существенной. Пример я приводил в начале статьи: SQL-инъекцию никогда не найдешь без алгоритмов анализа потока данных.
Статический анализатор должен реализовывать в движке набор алгоритмов, покрывающий доступные классы уязвимостей для данного языка программирования (анализ потока управления, потока данных, интервальный анализ и т.п.). Важным моментом является возможность добавлять в инструмент свои правила поиска уязвимостей – это позволит устранить первую причину пропуска уязвимости.
Таким образом, если вы не нашли имеющуюся уязвимость в результатах сканирования, для начала нужно разобраться в причине пропуска – обычно с этим может помочь вендор. Если причина в базе правил или в конфигурации сканирования, то ситуацию можно достаточно легко устранить. Важнее всего – оценить глубину анализа, то есть то, что в принципе позволяет искать движок.
Компетенции
Прочитав статью до этого места, можно предположить, что для работы с инструментом нужна глубокая экспертиза разработчика, ведь нужно понимать, какие срабатывания ложные, а какие истинные. По моему мнению, все зависит от того, насколько дружественно себя ведет инструмент. Если он предоставляет удобный и понятный функционал, понятные описания уязвимостей с примерами, ссылками и рекомендациями на разных языках, если инструмент показывает трассы для уязвимостей, связанных с анализом потока данных – для работы с ним не потребуется глубокая экспертиза разработчика с пониманием всех тонкостей языка программирования и фреймворков. Однако минимальный бэкграунд в разработке для того, чтобы читать код, все-таки должен быть.
Интеграция в процесс разработки
В конце статьи кратко коснемся одного из самых важных вопросов использования инструмента, а подробно его рассмотрим в следующих статьях. Допустим, вы решили использовать статический анализатор. Однако у вас есть налаженный процесс разработки, как технологический, так и организационный, и его менять не хочется (да никто и не даст).
Инструмент должен иметь полноценный неграфический интерфейс (например, CLI или REST API), с помощью которого вы сможете встроить анализатор в любой свой процесс. Хорошо, если у анализатора есть готовые интеграции с различными компонентами: плагины для IDE или систем сборки, интеграции с системами контроля версий, плагины для CI/CD серверов (Jenkins, TeamCity), интеграции с системами управления проектами (JIRA) или работы с пользователями (Active Directory).
Интеграция статического анализа в процесс разработки (так называемый SDLC) – наиболее эффективный способ использования, если процесс хорошо налажен и все участники договорились и знают, зачем это нужно. Постоянный анализ кода после его изменений или обновлений анализатора позволит находить уязвимости как можно раньше. Разделение ролей разработчиков и специалистов ИБ, четкое указание требований ИБ и мягкая интеграция в текущий процесс (например, в первое время – рекомендательный характер системы) позволит использовать инструмент безболезненно и полезно. Однако никто не отменял и ручное использование инструмента, если ваша модель разработки не подразумевает подобного процесса.
Резюме
В статье собраны основные рекомендации по началу использования статического анализатора. Хороший анализатор работает на порядок лучше любого легковесного чекера, он ищет проблемы принципиально другой сложности. Поэтому нужно считаться с особенностями статического анализа как технологии, но при этом выбирать конкретный инструмент так, чтобы его функционал максимально сглаживал все такие особенности.

