
Свою первую SIEM-систему я внедрял в 1998-м или 1999-м году (сам термин Gartner ввел только в 2005 году), и тогда от этого класса продуктов ожидать многого было сложно: они собирали события безопасности от систем обнаружения вторжения и сканеров уязвимостей и коррелировали их, снижая тем самым число ложных срабатываний и позволяя специалистам по ИБ фокусироваться именно на том, что имело значение для организации с точки зрения реальных киберугроз. Прошло 25 лет, и что мы видим сейчас? Насколько изменился рынок средств управления событиями безопасности и как он будет развиваться в ближайшие годы? Я попробовал немного пофантазировать, посмотреть не столько на российский рынок SIEM-систем, сколько выйти за его пределы и оглядеться в целом на рынке средств анализа данных ИБ, в том числе и зарубежных. В итоге я сформулировал некоторые направления развития, которые могут стать реальностью в обозримом будущем. Их можно разделить на несколько крупных блоков:
Сбор данных.
Хранение данных.
Анализ данных.
Принятие решений на основе данных.
Расширение числа источников данных
Не имея нужных данных для анализа, SIEM-система не способна корректно проанализировать цепочку событий и связанный с ними контекст и уведомить об инциденте. Ретроспективный анализ мы тоже не сможем провести, если у нас нет нужных данных, которые могут храниться в источниках телеметрии, не подключенных к SIEM-системе. Причин этой проблемы может быть несколько:
У нас нет необходимых источников телеметрии. Проблема не имеет решения до замены решения ИТ или ИБ, которое может отдавать свои журналы вовне в том или ином виде.
Источники данных у нас есть, но нет соответствующих коннекторов к ним. Об этом мы поговорим ниже.
Источники данных у нас есть, но мы не знаем, какие из них нам полезны, а какие нет. Тут можно порекомендовать обратиться к проекту MITRE ATT&CK, который подсказывает, какие источники данных помогают обнаруживать те или иные техники хакеров (на русском языке с этим проектом можно ознакомиться на специальном портале Positive Technologies, который мы планируем развивать еще больше).
У нас есть соответствующие коннекторы, но мы не знаем, какие данные нам нужны. И вновь нам поможет MITRE и его проект SMAP (Sensor Mappings to ATT&CK Project), который еще больше облегчает специалистам по обнаружению инцидентов ИБ маппинг различных типов событий, регистрируемых популярными инструментами, с техниками из матрицы MITRE ATT&CK. Иными словами, этот проект вам подскажет, какие события безопасности из источников телеметрии (например, auditd, osquery, Sysmon, CloudTrail, Zeek) помогут обнаружить техники, соответствующие вашей модели угроз.
У нас есть соответствующие коннекторы, мы знаем, что нам нужно, но у нас нет доступа к нужным источникам. Тут вам стоит плотно поработать с ИТ-службой, своей или внешней (если нужные источники принадлежат не вам).
Расширение числа источников телеметрии позволяют системам SIEM более полно анализировать информацию, включая данные из источников, таких как облачные платформы, сетевое оборудование, пользовательские устройства и другие, обеспечивая всесторонний мониторинг и последующее принятие решений, направленных на снижение числа угроз и блокирование инцидентов до нанесения ими катастрофических для бизнеса последствий.
Доступ к «облакам» для нас может быть пока не очень актуален (по крайней мере, для большинства компаний), но вот весь мир за пределами России уже давно встал на рельсы движения к «облакам», и поэтому системы SIEM, которые разработаны за рубежом или продаются за рубеж просто обязаныработать как с популярными облачными платформами (например, AWS, GCP, Microsoft Azure), так и с их подсистемами.
Бизнес-приложения — это еще один важнейший источник, который позволит ИБ подняться с уровня инфраструктуры на уровень бизнеса и увязать все, что происходит на них обоих с тем, что действительно волнует современное предприятие и его руководителей. Вряд ли их волнует незащищенный протокол RDP, захват Active Directory, компрометации коммутатора или повышение привилегий на сервере баз данных. Они вообще мало что понимают из этой тарабарщины. А вот кража денежных средств, остановка технологического процесса, уничтожение биллинга, срыв контракта на поставку продукции им не только понятен, но это именно то, чего они опасаются и считают недопустимым.
Чтобы обнаруживать такие события, причиной которых может быть и уровень ИТ или ИБ, система SIEM (или такое решение будет уже называться как-то иначе?) должна уметь работать с событиями от прикладных решений и коррелировать их с событиями ИБ, а также бизнес-процессами предприятия. Сегодня это возможно только для обнаружения мошенничеств в антифрод-решениях, интегрированных с SIEM-системой (есть даже системы с модулями для антифрода), или для обнаружения инцидентов в АСУ ТП. Да и то, эти два сценария все-таки ближе к традиционной ИБ, чем к обнаружению недопустимых для бизнеса событий. Но в перспективе такая функциональность может появиться по мере увеличения числа рядовых атак и необходимости приоритизации на более важных событиях.
Но как подключать такие источники? Ждать, когда все-все-все вендоры ИТ-решений начнут поддерживать стандартизованные форматы журналов регистрации или будут отдавать по API свою телеметрию? Утопия. Надеяться на производителей систем SIEM, что они будут по первому требованию подключать нужные вам источники данных? Неплохо бы. Многие вендоры так и делают, но все-таки подключение нового источника — задача не всегда быстрая, а иногда и требующая соответствующей оплаты (особенно если источник уникальный и производитель SIEM-системы не получит от разработки коннектора ничего, кроме головной боли и траты своих ресурсов). Есть и третий вариант, когда поддержку того или иного источника разрабатывают отдельные специалисты или компании и выкладывают свои модули либо на GitHub, либо распространяют через соответствующие маркетплейсы, о которых мы еще поговорим ниже.
Ну и, наконец, четвертый вариант — наличие аналитического движка, который способен самостоятельно разбирать форматы различных источников телеметрии, размечать хранящиеся в них данные и подгружать их в SIEM-систему. Это нетривиальная задача, и она пока еще требует помощи аналитиков, но уже есть определенные наработки в этой области. Например, израильский стартап Avalor утверждает, что их AnySource Connector способен собирать любые данные в любых форматах, независимо от того, насколько понятен и кастомизирован источник данных. Конечно, есть доля маркетинга (или только доля правды) в этих заявлениях, но и в российских разработках систем SIEM, насколько я знаю, ведутся работы по автоматизации процесса разбора различных форматов журналов регистрации или сетевого трафика, которые затем подключаются к системе анализа событий ИБ.
Работа с неструктурированными данными
Некоторое время назад стали появляться упоминания о так называемых fusion centers — комплексных решениях, способных анализировать не только данные от решений ИБ, но и от средств физической безопасности (хотя интеграцию системы контроля доступа в помещения по бейджам с системой аутентификации пользователей в ИТ-приложениях и сейчас сделать не так уж и сложно). Реализовать такое не составит большого труда, и это может быть востребовано у компаний, у которых все виды безопасности (например, экономическая, физическая, информационная, пожарная) находятся в одном подчинении.
Если не выходить за пределы ИБ, но посмотреть на задачу шире, то мы увидим, что сегодня события ИБ «приходят» не только из средств защиты, но и из других источников, среди которых и каналы в Телеграме, и сообщения в социальных сетях и на маркетплейсах, и форумы в даркнете, и электронная почта, и обратная связь от клиентов. Такие гетерогенные данные тоже необходимо анализировать, чего традиционные системы SIEM, привычные к четко описанным структурам и форматам журналов регистрации событий, не умеют.
В ряде зарубежных и одном российском SOC я несколько лет назад видел, как на дашборды аналитиков ИБ выводились сообщения из X (ранее Twitter) и других соцсетей, в которых использовался тег с названием компании. Дальнейший анализ проводился уже вручную, но первичный сбор проходил полностью автоматически. Сегодня технологии шагнули дальше, и можно предположить, что ИИ-движки на базе языковых моделей будут становиться неотъемлемой частью систем анализа событий ИБ, которые язык уже не поворачивается называть просто SIEM-системой (но про искусственный интеллект мы поговорим дальше). Что может быть проще — давать на вход такому движку поток неструктурированной информации с задачей оценки тональности сообщения (позитивное или негативное) и указанием времени и места, о котором идет речь; или, например, определять готовящиеся на компанию атаки путем анализа сообщений в даркнете, а затем уже выводить соответствующие предупреждения аналитикам безопасности, которые, следуя латинской поговорке Praemonitus praemunitus («Кто предупрежден, тот вооружен»), смогут встретить нападающих во всеоружии.
В любом случае системы, позволяющие анализировать различные типы структурированных и неструктурированных данных, которые больше похожи на отечественные ситуационные центры, будут интересовать все большее число компаний.
Поддержка озер и фабрик данных
Современные решения SIEM стремятся обеспечить более гибкую и масштабируемую инфраструктуру для хранения и обработки больших объемов данных и поэтому собирают очень много информации и потоков данных из разных источников. Это данные об активах, багах, уязвимостях, сигналах тревоги, атомарных событиях из ИТ-инфраструктуры и бизнес-приложений и многое другое. И эти данные могут быть использованы не только специалистами по ИБ, но и сетевиками, командами DevOps, теми, кто отвечает за приложения, ML- и BI-подразделениями.
Все они могут работать со своими копиями данных, но это слишком расточительно и нерационально (например, из-за множества избыточных хранилищ, отсутствия единого доверенного источника, несогласованности данных, рассинхронизации). Одним из вариантов выхода из такой ситуации могло бы стать использование какого-нибудь «монстра» типа Splunk, который бы накапливал все данные, а за счет ролевой модели доступа мог бы обеспечивать к ним доступ разным подразделениям. Такой вариант, кстати, достаточно часто и реализуется.
Но более перспективно было бы, если бы компания собирала все данные в единое хранилище (озеро или фабрику), которое могло бы использоваться разными подразделениями под свои нужды, сценарии и инструментарий. В том числе и SIEM-системы могли бы обращаться к этому озеру за информацией не только об атомарных событиях, но и о контексте их возникновения, которым можно было бы обогащать события, снижая число ложных срабатываний, повышая эффективность работы аналитиков ИБ и снижая нагрузку на них. Правда, пока традиционные системы SIEM не могут работать с озерами данных, так как первые ориентированы на работу с журналами регистрации структурированных событий, а вторые оперируют любыми типами данных — структурированными и нет, в том числе и неподготовленными для анализа, что сложно для типичных СУБД.
В качестве систем SIEM нового поколения, которые поддерживают Snowflake, Databricks lakehouse и AWS, можно назвать недоступные в России Panther и Hunters. При этом системы этого типа по-прежнему собирают события безопасности от различных сенсоров, но хранят их не в собственной проприетарной СУБД, а в облачном озере данных, которое предоставляет и продвинутые аналитические возможности. Однако не стоит думать, что такие SIEM-системы могут решить все проблемы. Пока они тоже не обладают широким перечнем коннекторов, а также требуют совсем иной зрелости и квалификации от аналитиков ИБ. Последнее, кстати, часто является основным ограничителем при переходе с обычных SIEM-систем на что-то более прогрессивное. И, кстати, облачное озеро данных — это еще и проблема с точки зрения соответствия требованиям. Не каждый регулятор настолько продвинут, что допускает распределенное по разным юрисдикциям хранение событий и иной чувствительной информации о безопасности во внешнем хранилище. Уж в России-то точно надо постараться, чтобы ФСТЭК или НКЦКИ разрешили такое решение в качестве ядра центра мониторинга или центра ГосСОПКИ.
Помимо коммерческих решений для организации озер данных ИБ на рынке присутствуют, как это часто бывает, и их открытые аналоги. Например, Matano, которая позволяет построить озеро данных ИБ на базе Apache Iceberg (само хранилище размещается в AWS). Такой открытый формат позволяет использовать собственный стек аналитических технологий (например, Athena, Spark, Snowflake). После анонса собственного озера данных ИБ от самого Amazon эксперты гадают, как будет развиваться Matano и не сменит ли она прописку с AWS на какое-либо другое озеро, что может оказаться непростой задачей.
Но ситуация с озерами пока не такая красивая, как это описывается в маркетинговых материалах провайдеров подобных услуг. Достаточно глупо переходить на новую SIEM-систему только ради этого. Озера данных решают множество задач, и ИБ — это только малая их часть. Поэтому обычно (хотя не знаю, насколько в данной ситуации можно использовать это слово) в организациях параллельно реализуются два процесса — внедрение озера данных и уход со старой SIEM-системы. А вот на что уходить — это отдельная тема. Это может быть как какая-нибудь SIEM-система следующего поколения data lake ready (те же Panther, Hunters или что-то еще), так и использование озера данных в качестве самостоятельного аналитического уровня параллельно с обычной системой SIEM. Но второй вариант подходит обычно только для сильных духом и богатых бюджетом.
Между озером данных и обычной СУБД есть и промежуточное решение — облачное хранилище типа Google BigQuery для Chronicle SIEM или Azure Monitor Log Analytics для Microsoft Sentinel SIEM. В этом случае уровень хранения уже отделен от уровня сбора и аналитики, но при этом еще рано говорить об озере данных со всеми его преимуществами… И недостатками.
Bring your own database
А что делать, если вы пользовались облачной системой SIEM по модели SIEM-as-a-service (или даже аутсорсинговым SOC) и хотели бы завершить ваши отношения с аутсорсером? Как вам забрать накопленные чужой SIEM-системой ваши данные? Как их перенести в новую систему? Вообще возможно ли это? Наверное, большинство вендоров скажут «нет», но это не совсем так. Скорее, это так, но именно для традиционных производителей средств аналитики ИБ. Большинство, годами присутствующие на рынке SIEM-системы, например тот же Splunk, недавно купленный Cisco, используют собственные, проприетарные форматы баз данных, позволяющие вендорам по максимуму использовать их для своих целей; но не более. И по максимуму же привязывают пользователей к своим решениям — перенес накопленных данных в какой-либо другой формат становится очень проблематичным делом (либо стоящим баснословных денег).
Но если вы не планируете никуда переходить, то нужно ли вам думать о том, где и как хранятся ваши данные и можно ли их оттуда достать? Возможно, все равно нужно. Привычные нам системы SIEM, включая так разрекламированные ArcSight, QRadar и многие другие, создавались в те времена, когда средств защиты, которые должны были отдавать свои журналы, было немного, как и данных, которые надо было собирать, анализировать и хранить. В связи с этим старые реляционные базы данных вполне справлялись со своей задачей. Кроме того, и сама SIEM-система был конечной точкой сбора данных, неподразумевающей, что данные надо оттуда еще куда-то отдать (например, в мастер-SIEM или в иное средство анализа).
Потом на смену «старым» базам данных стали приходить транзакционные СУБД типа mySQL или PostgresSQL, но для обработки действительно больших объемов данных сегодня многие переходят на СУБД с поддержкой колоночных форматов хранения, например ClickHouse и Vertica. Если транзакционные базы хороши в случаях регулярного добавления или изменения одной или нескольких записей, что активно используется при внесении событий ИБ в хранилище системы SIEM, то при необходимости проведения аналитической работы с собранными данными (например, в рамках threathunting) мы имеем прямо противоположную картину: относительно редкие, но при этом «тяжелые» выборки сотен тысяч или миллионов записей. Поэтому колоночные базы данных, ориентированные именно на аналитическую работу, сегодня начинают применяться при построении SIEM-систем все чаще, а в случае с тем же ClickHouse это получать преимущества от тысяч разработчиков по всему миру и использовать разработанные ими инструменты. Кстати, на базе ClickHouse можно построить и озеро данных, упомянутое в предыдущем разделе.
По такому пути пошел, например, американский стартап RunReveal, предлагающий подход, названный ими bring your own database. По сути, это облачное хранилище журналов на базе ClickHouse, но разработанное для целей ИБ. Правда, они ориентированы на работу преимущественно с облачными журналами и на безопасников, которым знакомы слова Jupyter Notebook, Grafana, API, терминал. Можно сказать, что это SIEM-система, разработанная разработчиками для разработчиков и имеющая открытый формат хранилища данных; может быть, за таким подходом будущее? Ведь давно говорят, что безопасник, не умеющий кодить, — не безопасник. Тем более что в чистом виде система SIEM — это агрегатор данных, а ценность такого агрегатора появляется с большим объемом детектирующей логики, которую пишет либо производитель, либо сам заказчик. Так что подход от RunReveal — это всего лишь один из способов написания детектов, только вместо графического конструктора no-code и low-code вы используете Jupyter.
Компания Positive Technologies выбрала промежуточный вариант, разработав свою СУБД LogSpace для хранения и анализа собираемых ИТ и ИБ событий на базе форка одной из первых публичных версий СУБД ClickHouse. За прошедшие годы решения настолько сильно разошлись в кодовой базе и своих возможностях, что компания говорит теперь о полной самостоятельности разработки хранилища событий безопасности для MaxPatrol SIEM.
Кстати, со «старыми» СУБД была еще и проблема со стоимостью: цены на лицензии для многих SIEM-систем зависели от объема данных, что привело к предсказуемой дилемме — увеличивать бюджет или выбирать, что отдавать в SIEM-систему. Причем обе задачи не имеют удачного решения, но большинство все-таки выбрало второй путь, либо сокращая число источников данных или событий с каждого из них, либо используя промежуточные решения типа EDR, XDR, NDR, которые берут на себя часть обработки событий, отдавая в SIEM-систему только реальные срабатывания. Нельзя сказать, что при использовании ClickHouse вопрос цены не стоит, но при масштабировании (а ClickHouse и не имеет большого смысла в малом бизнесе) этот аспект уходит на второй, а то и на третий план.
Наконец, классический вопрос «Сколько хранить данные?» в традиционных SIEM-системах тоже не имеет нормального решения, так как после 60–90 дней хранения становится невозможно нормально пользоваться данными (а мы помним, как при расследовании многих инцидентов выяснялось, что злоумышленники находились в инфраструктуре месяцами, а то и годами). Технология холодного, теплого и горячего разделения данных, возникшая как способ устранения проблемы длительности хранения, тоже является скорее заплаткой, чем полноценным решением. Наконец, собственная таксономия событий и их атрибутов в каждой системе SIEM также добавляет проблем в общую корзину под названием «Хранение данных».
Поэтому-то почти все решения, которые можно было бы отнести условно к классу NG-SIEM, в качестве хранилища используют какой-либо открытый формат, а не проприетарный (да еще и, как правило, в «облаке»). Но при этом они же пока не могут похвастаться лидирующими позициями на рынке.
Поддержка облачной архитектуры
Описанное выше направление с облачными хранилищами активно продвигается некоторыми компаниями на Западе. Оно позволяет вынести все данные в центральное облачное озеро, которое обеспечит эффективное хранение больших объемов данных, поиск в них и анализ. При этом рост капитальных затрат по сравнению с on-prem SIEM должен быть ниже (по крайней мере, такие доводы приводят почти все облачные производители средств управления событиями ИБ). В России большая активность в этом направлении пока не замечена, но надо сказать, что и таких объемов данных у нас почти ни у кого из компаний нет, чтобы производителям пришлось идти в эту сторону и чтобы очень остро вставал вопрос цены. Однако, если вендор SIEM-системы смотрит в сторону глобальной экспансии, закрывать глаза на облачную историю невозможно. Главное не путать cloud-native и cloud-hosted SIEM, когда традиционная система SIEM просто переносится в «облако» с сохранением всех присущих ей проблем.
Сегодня SIEM-система должна уметь интегрироваться не только с облачными сенсорами (например, AWS CloudTrail или Azure Synapse Analytics), но и поддерживать облачную архитектуру как с точки зрения хранилища, так и с точки зрения иных модулей — аналитики, создания отчетов и многих других. Например, SecOps Cloud Platform от LimaCharlie представляет собой облачный Lego для аналитиков ИБ. Это решение состоит из набора примитивов (их около 100), помогающих в обнаружении, автоматизации, реагировании, поиске угроз, сборе событий ИБ, threat intelligence. При этом эта платформа имеет коннекторы (пока ограниченное число) к средствам защиты, установленным как в «облаке», так и в корпоративной инфраструктуре, а в качестве хранилища может использовать озера данных Google. В целом, истинно облачные SIEM-системы являются эластичными, то есть адаптирующими рабочую нагрузку под изменяющиеся требования, масштабируемыми в обе стороны и отказоустойчивыми.
Правда, у облачных хранилищ есть и свои ограничения, о которых никогда не пишут производители облачных SIEM-систем и часть из которых мы все наблюдали весной 2022 года, когда все зарубежные облачные провайдеры одномоментно покинули нашу страну и оставили своих клиентов (уже бывших) у разбитого корыта. Пока еще слабый интернет в отдаленных регионах тоже не внушает оптимизма в историю с передачей всех событий ИБ в централизованное «облако»: каналы просто не выдержат такой нагрузки. Но в любом случае архитектура современной системы SIEM при прочих равных должна иметь возможность либо использовать облачное хранилище, либо, как минимум, использовать облачные сервисы в качестве сенсоров.
Кстати, 5 лет назад я на Хабре уже обращался к теме подключения облачных сенсоров к SIEM (часть 1 и 2) и, если у иностранных игроков ситуация существенно продвинулась вперед, то для многих российских производителей решений SIEM такая функциональность пока в новинку, что лишний раз доказывает невысокую востребованность облаков у заказчиков.
Распределенная архитектура сбора, хранения и анализа данных
Современные SIEM-системы переходят к распределенным архитектурам, что позволяет обеспечить более высокую отказоустойчивость, гибкость и масштабируемость. Это улучшает способность системы обрабатывать большие объемы данных и обеспечивает эффективную работу в средах с высокой нагрузкой и со сложными сетевыми структурами. Но можно отметить и иную тенденцию.
Подход, предложенный RunReveal и упомянутый выше, востребован в тех случаях, когда аналитики ИБ хотят иметь определенную свободу, а не быть привязанным к SIEM-экосистеме, выгодной производителю, но не потребителю. Поэтому можно предположить, что будущее за решениями (язык не поворачивается называть их системами), которые будут собираться как конструктор: хранение будет реализовано на том же ClickHouse, коннекторы — на базе какого-нибудь Avalor или самописные, а детекты будут создавать сами аналитики, опираясь среди прочего и на правила на стандартных языках типа того же SIGMA или RootA. Кроме того, это позволит учесть желание работать с одними и теми же данными разным командам внутри организации (например, ИБ, ИТ, маркетингу, BI, СЭБ, продуктовым командам).
Уровень аналитики, отделенный от уровня хранения и сбора данных, может быть реализован как в облачной (например, в LimaCharlie), так и внутри корпоративной инфраструктуры. При этом и точки назначения данных могут отличаться в зависимости от сценария их использования. Например, сигналы тревоги для оперативного реагирования на инциденты можно сразу направлять в SIEM- или SOAR-систему, журналы и телеметрию, требуемые для выполнения законодательства, можно направлять в дешевое долговременное хранилище, совокупная статистика об инцидентах может отдаваться в различные BI-инструменты для отображения на дашбордах, а какие-то данные (например, по утечкам информации) никогда не должны попадать в систему SIEM — только в какое-то определенное решение.
По сути, мы говорим о гибкой маршрутизации данных, которую могут взять на себя решения таких стартапов, как Cribl, Tenzir, Substation, Monad, Tarsal или Vector (да, все они зарубежные). У этих решений, относящихся к классу ETL (extraction, transformation, loading), часто есть свой язык описания логики маршрутизации данных, свои правила, распределенная и модульная архитектура, механизмы обезличивания и шифрования данных для обеспечения приватности, а также возможность трансформации и нормализации данных в соответствии с различными схемами, как открытыми, например OCSF ( Open Cybersecurity Schema Framework) или ECS ( Elastic Commom Schema), так и проприетарными, такими как Monad Object Model или Tarsal Schema. Кстати, упомянутое выше решение Matano для организации озера данных ИБ использует внутри себя Vector Remap Language от Vector для трансформации и первичной обработки входящих журналов регистрации с событиями ИБ.
Помимо основных компонентов SIEM-системы (сбор, хранение, аналитика) могут существовать и отдельные инструменты, которые помогают решать специфические задачи в области управления событиями безопасности. Например, решение Query.AI обеспечивает единый поиск в хранилищах средств защиты (преимущественно зарубежных). Вместо того чтобы заходить в каждое средство отдельно, Query.AI выполняет роль поисковой системы, которая самостоятельно заходит во все инструменты ИБ и ищет ответ на заданный вопрос.
Решение Dassana позволяет приоритизировать множество срабатываний разных средств защиты с точки зрения их эффективности для защищаемой организации. А LogSlash (не путать с инструментом сбора, обработки и передачи логов LogStash и базой данной LogSpace в MaxPatrol SIEM) встраивается в цепочку передачи данных от сенсоров ИБ до хранилищ данных или SIEM-системы и уменьшает объемы передаваемых журналов без снижения их качества для процесса принятия решений. Существуют также решения для выстраивания отдельных процессов в рамках разных плейбуков, инструменты реализации концепции detection-as-a-code, тестирования эффективности созданного контента обнаружения или тестирования use cases. Иногда эти инструменты могут быть частью и более крупного решения. Например, многие из уже упомянутых решений, например от Panther или LimaCharlie, поддерживают detection-as-a-code «из коробки».
Правда, в этом случае уже нельзя говорить о будущем SIEM-систем как о развитии какого-то одного продукта. Скорее, речь пойдет о построении функции мониторинга и анализа событий безопасности, использующей разные инструменты, к которым привыкли аналитики, а не об использовании одного монолитного решения, вокруг которого строится соответствующая функция. В конце концов, заказчики хотят решать свою проблему, а не покупать какой-то продукт, пусть и разрекламированный.
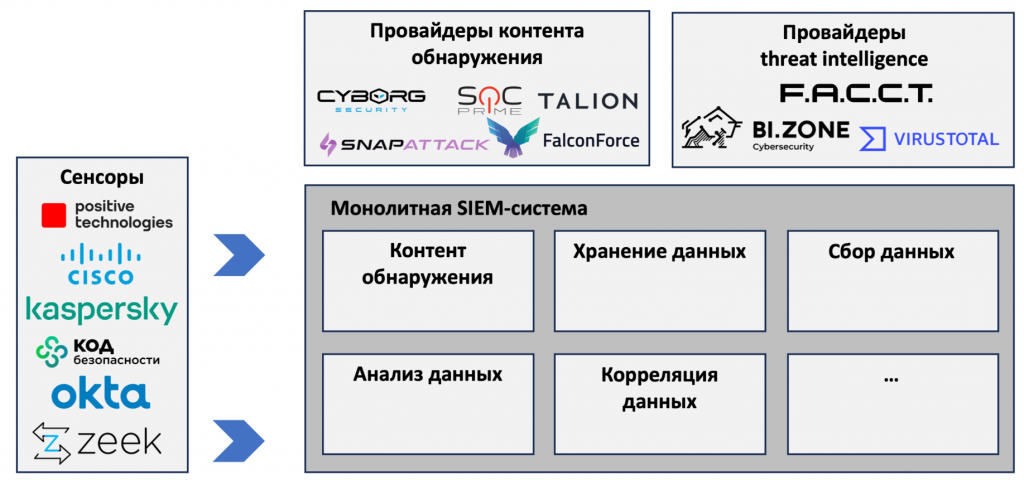
Монолитный SIEM
Интересным способом реализации распределенной архитектуры SIEM-системы является не просто разделение хранилища и анализатора данных, например в LimaCharlie, а подключение к имеющимся разрозненным источникам данных, появившихся в результате холдинговой структуры, активного процесса слияний и поглощений, а также несогласованных процессов внутри организации, когда разные команды (даже ИБ) используют разные хранилища данных. Решение Anvilogic может подключаться к различным БД, традиционным SIEM-системам типа Splunk и даже к озерам данных (например, Snowflake) и проводить необходимый анализ и поиск признаков атак за счет встроенных полутора тысяч детектов и no-code-конструктора собственного контента обнаружения. Можно сказать, что Anvilogic может стать промежуточным шагом при миграции в озеро данных, о котором я упоминал выше.
Разработка контента обнаружения на базе экспертизы в области атак
Но какие бы хранилище и архитектуру мы не выбрали, ключевым вопросом будет «А как мы обнаруживаем угрозы и инциденты?». С SIEM-системами нового поколения или облачными платформами по анализу данных ИБ, построенных на основе озер или фабрик данных, мы решаем одну проблему, но получаем другую. Эти решения пока редко обладают достаточным объемом контента обнаружения. У традиционных SIEM-систем проблема другого свойства — качество этого самого контента.
Существует подкрепленное множеством экспертов мнение, что от 70% до 80% всех правил, поставляемых с SIEM-системой «из коробки», абсолютно бесполезны и плохо применимы на практике. Но связано это часто не с тем, что вендор плохо разбирается в ИБ (хотя и такое бывает, поэтому всегда стоит уточнять, кто пишет детекты в выбираемом вами продукте и какова квалификация этих специалистов), а с тем, что написать универсальные правила для продаваемого продукта — это не то же самое, что написать правила для конкретного окружения, в котором будет работать купленная система. Производитель пишет правила для 50–100 корпоративных сред, ища баланс между персонификацией и широким охватом (часто не в пользу персонификации). Согласно исследованию TAdviser, проведенном в 2023 году, 86% пользователей SIEM-систем либо используют правила «из коробки», либо донастраивают их под свои нужды. Написанием правил с нуля занимается только 5% пользователей, а оставшиеся 9% обращаются в сервисы по написанию контента обнаружения на заказ.
Поэтому в этой части у SIEM-систем есть несколько путей развития:
Усиление функциональности самой системы SIEM по самообучению в инфраструктуре компании, а также по автоматической доработке существующих правил обнаружения угроз.
Автоматическое создание правил обнаружения.
Расширение возможностей по описанию контента обнаружения.
Использование чужого контента обнаружения.
Усиление соответствующей экспертизы у производителя и оперативная доставка контента обнаружения.
Первый вариант знаком пользователям систем обнаружения вторжений (IDS, СОВ, СОА), в которых присутствует режим обучения на сетевом трафике в течении двух-четырех недель, после чего система сама рекомендует включать одни сигнатуры и отключать другие для снижения числа ошибок первого и второго рода (ложных обнаружений и необнаружений). Такой режим в SIEM-системе требует наличия встроенного модуля управления активами или интеграции с внешним решением, чтобы понимать, какие системы в организации есть, а каких нет и для каких соответствующий контент обнаружения будет нерелевантен.
Второй вариант, базирующийся на применении искусственного интеллекта, мы рассмотрим чуть позже, а пока посмотрим на третий, который получает популярность у продвинутых аналитиков ИБ. В современных SIEM-системах контент обнаружения представляет собой набор правил, который обычно создается самим производителем. При этом изменение существующих или создание новых детектов не требуют каких-либо особых знаний (кроме тех, что по ИБ, конечно) и реализуются с помощью встроенных в систему SIEM инструментов no-code или low-code. Это очень удобно для быстрого старта работы с решением и аналитиков с невысокой квалификацией. Но что делать, если мы хотим сложные кастомизированные правила против продвинутых злоумышленников?
В некоторых SIEM-системах нового поколения такие детекты пишутся с помощью Jupyter Notebook (например, в RunReveal) или сразу на Python (например, в Panther или Matano), поддерживая при этом концепцию detection-as-a-code, то есть реализуя полноценный конвейер разработки правил обнаружения, включая, например, их тестирование и проверку работоспособности. По различным оценкам, существует только от 1% до 5% способных на это команд, но и этот небольшой процент необходимо обеспечить соответствующей экспертизой и инструментарием.
Такой вариант развития, поддерживаемый, например, в MaxPatrol SIEM, остается предпочтительнее для массового потребителя, которому не нужно будет тратить свое время на разработку и доработку контента обнаружения.
Использование чужого контента обнаружения
Четвертый из описанных выше вариантов расширения объема и качества контента обнаружения в системах SIEM также может быть реализован различными способами.
Первый из них базируется на использовании маркетплейсов, в которых можно приобрести не только модули и коннекторы к различным средствам защиты, но и новый контент обнаружения, в том числе разработанный другими пользователями системы мониторинга событий безопасности (например, такое есть в Splunk, QRadar, MaxPatrol SIEM, LimaCharlie).
Второй вариант не требует больших финансовых затрат (а иногда и вообще каких-либо затрат), но при этом он чуть сложнее, и для его реализации необходима определенная квалификация аналитиков ИБ. Речь идет об использовании кем-то написанного и распространяемого контента обнаружения, поддерживаемого в SIEM-системе. У систем обнаружения атак таким стандартом де-факто стал формат правил Snort. В случае с SIEM-системами таким форматом является SIGMA. В публичном репозитории правил SIGMA (на самом деле таких коллекций несколько в интернете — публичных и приватных), содержится несколько тысяч правил, которые можно использовать в качестве контента обнаружения; правда, при условии, что SIEM-система поддерживает этот формат, а это бывает далеко не всегда (поддерживают, например, LimaCharlie, Splunk, SumoLogic или QRadar). Промежуточным вариантом решения может быть использование специальных конвертеров (например, uncoder.io или sigconverter.io), которые позволяют транслировать правила SIGMA в правила для популярных средств обнаружения угроз (SIEM, EDR, NDR).
В любом случае возможность использования чужого контента обнаружения расширяет возможности системы SIEM и ее аналитиков, которые, как показывает статистика, не часто самостоятельно пишут правила, полагаясь на внешние источники информации. Это же позволило начать формироваться рынку threat content-as-a-service, зачатки которого присутствуют и в России, где есть компании, предлагающие написание своих правил для систем обнаружения вторжений или NGFW, в которые встроены собственные модули IDS.
Обогащение событий
Отдельно стоит остановиться на вопросе обогащения событий, попадающих в систему SIEM. У многих производителей эта функция ограничена только некоторыми индексируемыми полями, описанными в соответствующей схеме данных. В противном случае требуются колоссальные вычислительные возможности, что приводит к росту требований и стоимости итогового продукта. Решением могло бы стать обогащение всех данных в процессе их сбора и хранение уже таких данных (так делает, например, Chronicle), что требует иной внутренней архитектуры решения. Зато мы сможем сразу связывать IP-адреса из событий:
с автономными системами (ASN);
семплами вредоносного кода, распространяемыми с этих IP-адресов;
доменами, «висящими» на указанном адресе, полученными с помощью пассивного DNS;
фидами threat intelligence;
другими адресами из той же самой системы ASN;
учетными записями, созданными в Active Directory с этого IP-адреса во время регистрации события.
Схема данных, в соответствии с которой работают многие традиционные SIEM-системы, тоже часто является ограничивающим фактором в современных условиях. Например, мы получаем событие, в котором указан домен, нам надо обогатить эту информацию, для чего мы запрашиваем IP-адрес, на котором этот домен «висит». Если нам возвращается один IP-адрес, то мы заносим его в хранилище в соответствии со схемой и можем использовать в поисковых запросах. Но что, если мы получаем несколько IP-адресов? Как будет работать с ними схема? Сохранит первый адрес? Последний? Все из них? Если все, тогда хранится они уже будут в свободном текстовом поле, которое не индексируется, тем самым увеличится время на обнаружения и расследование угроз. Поэтому в новых SIEM-системах поля схемы данных должны поддерживать списки и массивы, дающие большую гибкость в работе с событиями ИБ. Тогда мы сможем эффективно хранить наборы шифров протокола TLS, имена дочерних процессов и учетных записей, загруженные файлы.
Кстати, с точки зрения работы с семплами вредоносного кода аналитики нередко сталкиваются с так называемой проблемой hash aliasing, то есть эффективной трансляцией хешей (MD5, SHA-1, SHA-256 и, может быть, отечественный ГОСТ) между собой. В принципе, эту задачу можно возложить на платформу TIP, но почему бы не автоматизировать эту задачу внутри системы SIEM и не делать такое обогащение и трансляцию на лету?
Переход от атомарных к метасобытиям
Мы все знаем о том, что любая атака — это всегда цепочка действий, техник, которые реализует злоумышленник для достижения своей цели. Например, сначала он сканирует внешний периметр, затем эксплуатирует уязвимость на публично доступном сайте, далее повышает свои привилегии и попадает во внутреннюю инфраструктуру компании. Этот последовательный набор действий приводит к срабатыванию как минимум четырех событий, которые мы можем анализировать отдельно, добавляя к ним контекст вручную, а можем ожидать, что умная система SIEM сама объединит такие события в цепочку и обратит внимание аналитиков ИБ сразу на нее.
Такой механизм присутствовал в некоторых системах обнаружения атак, и там такие цепочки назывались метасобытиями. Вполне логично предположить, что и системы SIEM должны обладать такой возможностью. Конечно, обычная SIEM-система с помощью пользовательских правил корреляции может сделать то же самое, но было бы неплохо, если бы сам производитель смог оснастить свой продукт такой функциональностью «из коробки». Это позволит более полно и точно оценивать контекст и связи между событиями, что приведет к более глубокому пониманию угроз и более эффективному реагированию на них.
Думаю, вы уже неоднократно видели в отчетах схемы, отображающие распространение инцидента по инфраструктуре и показывающие точку входа злоумышленника, используемые уязвимости или украденные учетные записи, дальнейшие векторы атаки, а также временные метки, когда все это происходило. Обычно такие графы рисуются либо вручную, либо с помощью специализированного ПО (например, Maltego или графовых баз знаний типа Obsidian или Logseq), в которое подгружаются нужные данные.
А как было бы замечательно, если бы SIEM-система могла поддерживать такое графовое представление данных и на основе всей имеющейся информации (а она вся в БД есть) быстро визуализировать всю картину инцидента, что позволило бы не только быстро разобраться в причинах произошедшего, но и оперативно среагировать на него. По сути, речь идет о визуализации метасобытий. В системах SIEM (например, в LogRhythm или Chronicle) такое встречается, но глубина визуализации не очень большая. Обычно такая функциональность сегодня реализуется в виде отдельных решений, например, Graphistry, Picus Security Validation Platform или MaxPatrol O2. И если мы рассматриваем систему SIEM как монолитный продукт, то было бы неплохо иметь такой компонент внутри (что может утяжелить все решение). А вот если речь идет о распределенной функции мониторинга и управления событиями ИБ, то наличие такого отдельного «фрагмента» вполне укладывается в общий пазл.
Использование машинного обучения
Споры о применении искусственного интеллекта для обнаружения угроз ведутся уже не первый год, и есть как сторонники, так и противники этого подхода. Желание быстро и эффективно анализировать большие объемы данных, выявлять скрытые шаблоны и даже предсказывать потенциальные угрозы понятно; как и потребность в автоматической адаптации к новым видам атак и в обновлении своих алгоритмов. Но пока представленные на рынке решения показывают, что машинное обучение не может быть полной заменой традиционных способов обнаружения, построенных на сигнатурном или аномальном подходе.
Да, есть направления, где ИИ достаточно неплохо справляется со своими задачами. Например, ИИ идентифицирует аномалии и отклонения от нормального поведения узлов, трафика, пользователей, выявляет вредоносные домены в интернете, анализирует зашифрованный трафик. Но для обнаружения многих остальных атак пока не найдено эффективного решения с минимальным процентом ложных срабатываний: либо не хватает данных для обучения, либо не найдены подходящие модели, либо сам процесс обучения выстроен неверно. Но и отвергать это направление развития SIEM-систем неправильно: исследования ведутся и в решениях эти движки начинают занимать свое достойное место (например, в MaxPatrol SIEM есть модуль поведенческого анализа — Behavioral Anomaly Detection (BAD).
Другое применение машинное обучение нашло в анализе неструктурированных данных и разъяснении собранных в SIEM-системе данных на понятном человеку языке. Суммаризация и пересказ отчетов о расследовании инцидентов — это вполне очевидное направление использования ИИ в системах анализа событий безопасности, которое уже начинает внедряться в некоторые решения (например, подсистема Security Copilot у Microsoft, интегрированная в Microsoft Sentinel, и другие решения по ИБ от ИТ-гиганта, а также Elastic AI Assistant).
Среди других сценариев применения искусственного интеллекта в SIEM-системах можно назвать:
Exabeam Threat Explainer, который может обнаруживать ошибки в конфигурации источников телеметрии и подсказывать о них заказчикам.
LogRhythm AI Engine, который может предсказывать следующие шаги злоумышленников, опираясь на собранную телеметрию.
Fortinet Advisor for FortiSIEM, который интерпретирует собранную телеметрию, оценивает потенциальный ущерб от атак и готовит рекомендации по реагированию, а также позволяет аналитикам на обычном языке формировать сложные запросы к хранилищу событий и даже писать плейбуки.
Надо отметить, что активное применение машинного обучения и больших языковых моделей в системах SIEM началось только в 2023 году и пока сложно оценить весь потенциал, который может дать искусственный интеллект для управления событиями ИБ, а также отделить маркетинг от реального результата.
Система подсказок, облегчающая внедрение и настройку
Выше, в разделе про расширение числа источников телеметрии, я упомянул про проект MITRE ATT&CK, который позволяет связать вашу модель угроз с техниками хакеров, источниками телеметрии об этих техниках, а также с вариантами реагирования на них. Так вот, было бы неплохо, если бы SIEM-система могла принимать на вход формализованное описание модели угроз (например, в виде техник MITRE ATT&CK) и подсказывать, какие источники данных вам нужны для максимального покрытия всех TTP (Tactics, Technics, and Procedures). Ну а если система была бы интегрирована со средствами управления активами, то она могла бы еще и подсказывать, где именно в вашей инфраструктуре находятся нужные ей источники данных. Такого я пока нигде не видел, но мне кажется, это вполне очевидный вектор развития SIEM-систем.
Заключение
Материал получился достаточно объемным, но нельзя сказать, что он полностью раскрывает тему. Еще столько же можно смело написать про хранилище, на котором (или которых, так как иногда SIEM-системы используют сразу несколько типов баз данных (SQL и NoSQL) для хранения информации) базируется система управления событиями ИБ. Например, кто-то из вендоров будет отстаивать право использовать документоориентированную СУБД, например MongoDB, для хранения информации (по такому пути пошел тот же SearchInform SIEM), а кто-то скажет, что без графовых баз данных визуализировать и анализировать миллиарды событий ИБ невозможно (например, Uplevel Security, купленная недавно компанией Trellix, использует Neo4j).
Я также ни слова не написал про автоматизацию реагирования на выявленные инциденты, а отдельные аналитики считают, что будущее — за интегрированными решениями, для которых даже придумали очередную аббревиатуру — TDIR, Threat Detection & Incident Response, означающую, что в одном решении объединяются функции классической SIEM-системы и SOAR-системы. Gartner считает, что к 2025 году 75% производителей SIEM-систем начнут выпускать именно TDIR-продукты (для сравнения, в 2021 году этот показатель равнялся 44%).
Несмотря на все описанное, многие производители «устаревших» подходов продолжают занимать на рынке существенную долю, и этому есть вполне понятное объяснение — зависимость от вендора. Непросто перейти от одной SIEM-системы к другой: сложно перенести накопленные данные, написать новые коннекторы, изучить новый синтаксис правил, переписать контент обнаружения, мигрировать плейбуки. И все это требует соответствующих ресурсов, которых обычно нет, что и останавливает активное внедрение новых решений (там, где такая необходимость, конечно, назрела).
Поэтому кто-то продолжает использовать привычное SIEM-решение и строит вокруг него функцию управления событиями ИБ в организации. Кто-то пытается надстроить над SIEM-системой и подключаемыми к ней средствами защиты отдельные аналитические инструменты (например, платформу SnapAttack или MaxPatrol O2). Кто-то переходит на систему нового поколения, не скупясь на миграцию. Ну а кто-то перестает рассматривать систему SIEM как продукт и меняет точку зрения, согласно которой «SIEM — это функция работы с данными безопасности с помощью различных инструментов», строя этакий Lego-конструктор.
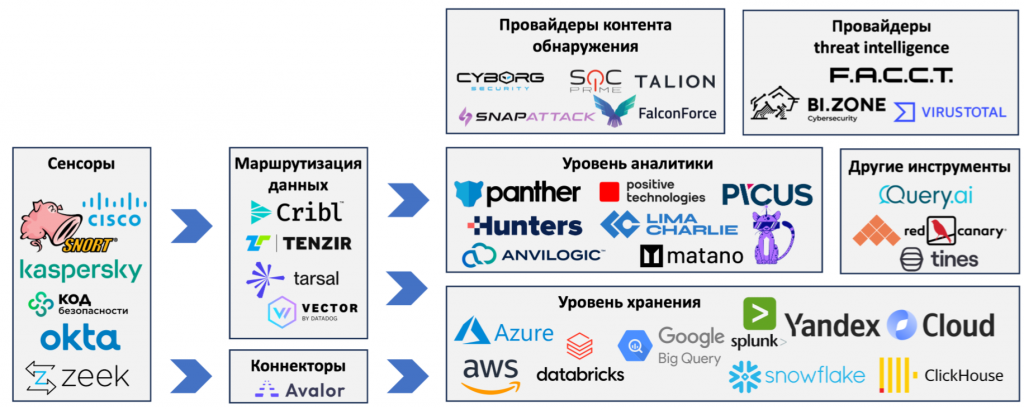
SIEM как функция работы с данными безопасности с помощью различных инструментов
В любом случае путь развития SIEM-системы в организации зависит во многом от самой организации, имеющихся у нее ресурсов и уровня зрелости. Кого-то и дальше будет устраивать монолитная система SIEM типа Splunk или ArcSight, являющаяся и хранилищем данных, и средством аналитики и генерации отчетов. Современные, динамично растущие компании, прочувствовавшие «облака», будут использовать привычный для себя подход и могут задействовать облачные платформы управления событиями ИБ типа LimaCharlie. Бигтехи могут начать строить собственные озера данных, к которым будут обращаться все их подразделения, включая и ИБ. Каждый выбирает для себя…
Время рассудит, какой из сценариев развития рынка SIEM-систем возьмет верх. Может быть, кто-то из тех, кто сегодня является лидером рынка традиционных систем, посмотрит чуть дальше своего настоящего и сможет привнести в свои решения по управлению событиями ИБ новые подходы? Кто знает… Выбор все равно за вами…
Алексей Лукацкий, Специалист по кибербезопасности
