
Объем трафика в интернете растет ( особенно в последние месяцы, когда мы все оказались на удаленке и многие перевели свои активности в онлайн). Увеличивается и число автоматических средств взаимодействия с контентом на веб-сайтах и, как следствие, все большую актуальность получает фильтрация нежелательной автоматизированной активности. Сегодня до 50% интернет-активности генерится автоматически с помощью так называемых веб-ботов (или просто ботов). И в данном случае речь о любой активной в сети программе, вне зависимости от целей ее использования. Обычно такие программы выполняют повторяющиеся, простые в автоматизации действия. Например, поисковые движки Google или Yandex используют краулеры для периодического сбора контента и индексации страниц в интернете.
Итак, есть два типа веб-ботов — легитимные и зловредные. К легитимным можно отнести поисковые движки, RSS-ридеры. Примеры зловредных веб-ботов ― сканеры уязвимостей, скрейперы, спамеры, боты для DDoS-атак, трояны для мошенничества с платежными картами. После определения типа веб-бота к нему могут быть применены различные политики. Если бот легитимный, можно уменьшить приоритет его запросов к серверу или снизить уровень доступа к определенным ресурсам. Если бот определен как зловредный, можно его заблокировать или отправить в песочницу для дальнейшего анализа. Обнаруживать, анализировать и классифицировать веб-боты важно, так как они могут нанести вред: например, вызвать утечку важных для бизнеса данных. А также это снизит нагрузку на сервер и сократит так называемый шум в трафике, ведь до 66% трафика веб-ботов — это именно зловредный трафик.
Есть разные техники обнаружения веб-ботов в сетевом трафике, начиная от лимитирования частоты запросов к узлу, черных списков IP-адресов, анализа значения HTTP-заголовка User-Agent, снятия отпечатков устройства — и заканчивая внедрением CAPTCHA, и поведенческим анализом сетевой активности с помощью машинного обучения.
Но сбор репутационной информации об узле и поддержка в актуальном состоянии черных списков с помощью различных баз знаний и threat intelligence — затратный, требующий больших усилий процесс, и при использовании прокси-серверов он не целесообразен.
Анализ поля User-Agent в первом приближении может показаться полезным, но ничто не мешает веб-боту или пользователю изменить значения этого поля на валидное, замаскировавшись под обычного пользователя и используя валидный User-Agent для браузера, или под легитимный бот. Назовем такие маскирующиеся веб-боты impersonators. Использование различных отпечатков устройства (отслеживание движения мыши или проверка возможности рендеринга HTML-страницы клиентом) позволяет выделять более сложные в обнаружении веб-боты, имитирующие поведение человека, например запрашивающие дополнительные страницы (файлы стилей, иконки и т. п.), парсящие JavaScript. Этот подход основан на внедрении кода на стороне клиента, что часто недопустимо, так как ошибка при вставке дополнительного скрипта может нарушить работу веб-приложения.
Следует отметить, что обнаруживать веб-боты можно и онлайн: оценка сессии будет производиться в режиме реального времени. Описание такой постановки задачи можно найти у Кабри и соавторов [1], а также в работах Зи Чу [2]. Другой подход — анализировать только после завершения сессии. Наиболее интересен, очевидно, первый вариант, который позволяет принимать решения быстрее.
Для выявления и классификации веб-ботов мы использовали техники машинного обучения и стек технологий ELK (Elasticsearch Logstash Kibana). Объектами исследования стали HTTP-сессии. Сессия — последовательность запросов от одного узла (уникальное значение IP-адреса и поля User-Agent в HTTP-запросе) в фиксированном временном интервале. Дерек и Гохале для определения границ сессий используют 30-минутный интервал [3]. Илиу и др. утверждают, что такой подход не гарантирует реальной уникальности сессии, но все же допустимо. В силу того, что поле User-Agent может быть изменяемым, могут появиться больше сессий, чем есть на самом деле. Поэтому Никифоракис и соавторы предлагают более тонкую настройку, основанную на том, поддерживается ли ActiveX, включен ли Flash, разрешение экрана, версия ОС.
Мы же будем считать допустимой погрешность в формировании отдельной сессии, если поле User-Agent меняется динамически. А для выявления сессий ботов построим четкую бинарную модель классификации и будем использовать:
Для классификации веб-ботов по типу активности построим многоклассовую модель из таблицы ниже.
Также будем решать задачу онлайн-обучения модели.
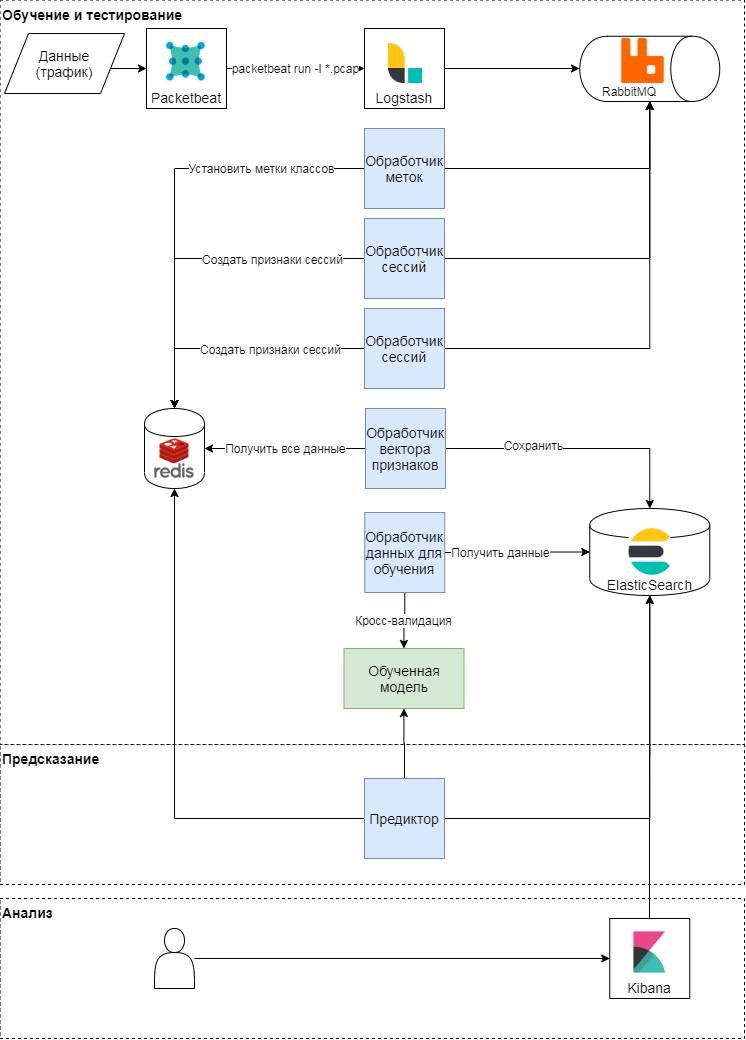
Концептуальная схема предлагаемого подхода
Данный подход имеет три этапа: обучение и тестирование, предсказание, анализ результатов. Рассмотрим первые два подробнее. Концептуально подход следует классической схеме обучения и применения моделей машинного обучения. Сначала определяют метрики качества и признаки для классификации. После формируют вектор признаков и проводят серии экспериментов (различные перекрестные проверки) для валидации модели и подбора гиперпараметров. На последнем этапе выбирают наилучшую модель и проверяют качество модели на отложенной выборке.
С помощью модуля packetbeat осуществляется парсинг трафика. Сырые HTTP-запросы отправляются в logstash, где с помощью Ruby-скрипта формируются задачи в терминах Celery. Каждая из них оперирует идентификатором сессии, временем запроса, телом и заголовками запроса. Идентификатор сессии (ключ) — значение хеш-функции от конкатенации IP-адреса и User-Agent. На этом этапе создаются два вида задач:
Эти задачи отправляются в очередь, где обработчики сообщений их выполняют. Так, обработчик labeler выполняет задачу простановки метки класса, используя экспертную оценку и открытые данные из сервиса browscap на основе используемых User-Agent; результат записывает в key-value storage. Session processor формирует вектор признаков (см. таблицу ниже) и записывает результат для каждого ключа в key-value storage, а также устанавливает время жизни ключа (TTL).
Так формируется матрица признаков и выставляется целевая метка класса для каждой сессии. На основе этой матрицы происходят периодическое обучение моделей и последующий подбор гиперпараметров. Для обучения использовали: логистическую регрессию, метод опорных векторов, деревья принятия решений, градиентный бустинг над деревьями принятия решений, алгоритм случайного леса. Наиболее релевантные результаты мы получили с помощью алгоритма случайного леса.
Во время парсинга трафика обновляется вектор признаков сессии в key-value storage: c появлением нового запроса в сессии пересчитываются признаки, ее описывающие. Например, признак среднее количество заголовков в сессии (mean_headers) вычисляется каждый раз, когда в сессию добавляется новый запрос. Predictor отправляет вектор признаков сессий в модель, а ответ от модели записывает в Elasticsearch для анализа.
Свое решение мы проверяли на трафике портала SecurityLab.ru. Объем данных — более 15 ГБ, более 130 часов. Количество сессий — более 10 000. В силу того, что предлагаемая модель использует статистические признаки, сессии, содержащие менее 10 запросов, не участвовали в обучении и тестировании. В качестве метрик качества мы использовали классические метрики качества ― точность, полнота и F-мера для каждого класса.
Построим и оценим модель бинарной классификации, то есть будем обнаруживать ботов, а потом уже классифицировать их по типу активности. По результатам пятикратной стратифицированной перекрестной проверки (именно такая требуется для рассматриваемых данных, так как присутствует сильный дисбаланс классов) можно сказать, что построенная модель довольно хорошо (точность и полнота — более 98%) умеет разделять классы пользователей-людей и ботов.
Результаты тестирования модели на отложенной выборке представлены в таблице ниже.
Значения метрик качества на отложенной выборке примерно совпадают со значениями метрик качества при валидации модели, значит модель на этих данных умеет обобщать знания, полученные при обучении.
Рассмотрим ошибки первого рода. Если экспертно разметить эти данные, то матрица ошибок существенно изменится. Это значит, что при разметке данных для модели были допущены некоторые ошибки, но модель все равно смогла распознать такие сессии корректным образом.
Рассмотрим пример сессии impersonators. Она содержит 12 похожих запросов. Один из запросов представлен на рисунке ниже.
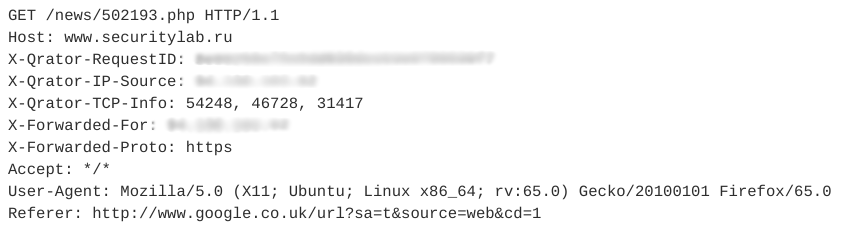
Все последующие запросы в этой сессии имеют такую же структуру и отличаются только URI.
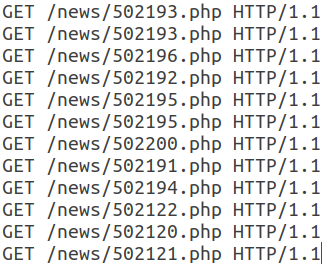
Отметим, что этот веб-бот использует валидный User-Agent, добавляет поле Referer, обычно использующееся неавтоматическими средствами, и количество заголовков в сессии невелико. Кроме того, временные характеристики запросов — время сессии, среднее время на запрос — позволяют говорить о том, что эта активность автоматическая и относится к классу RSS-ридеров. При этом сам бот маскируется под обычного пользователя.
Для классификации веб-ботов по типам активности будем использовать те же данные и тот же алгоритм, что в предыдущем эксперименте. Результаты тестирования модели на отложенной выборке представлены в таблице ниже.
Качество для категории libs_tools низкое, но недостаточный объем примеров для оценки не позволяет говорить о корректности результатов. Следует провести повторную серию экспериментов по классификации веб-ботов на большем количестве данных. С уверенностью можно сказать, что текущая модель с довольно высокой точностью и полнотой умеет разделять классы RSS-ридеров, поисковых движков и ботов общей направленности.
Согласно этим экспериментам на рассматриваемых данных, более 22% сессий (при общем объеме более 15 ГБ) созданы автоматически, и среди них 87% относятся к активности ботов общей направленности, неизвестных ботов, RSS-ридеров, веб-ботов, использующих различные библиотеки и утилиты. Таким образом, если фильтровать сетевой трафик веб-ботов по типу активности, то предлагаемый подход позволит снизить нагрузку на используемые серверные ресурсы минимум на 9–10%.
Суть этого эксперимента в следующем: в режиме реального времени после парсинга трафика выделяются признаки и формируются вектора признаков для каждой сессии. Периодически каждая сессия отправляется в модели для предсказания, результаты которого сохраняются.
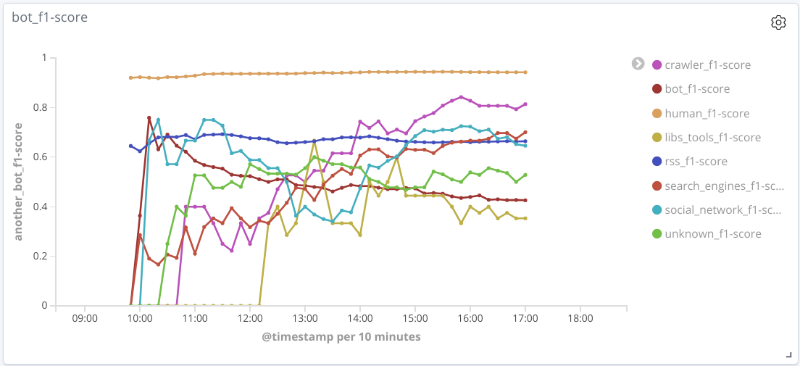
F-мера модели во времени для каждого класса
Графики ниже иллюстрируют изменение значения метрик качества во времени для наиболее интересных классов. Размер точек на них связан с числом сессий в выборке в конкретный момент времени.

Точность, полнота, F-мера для класса search engines

Точность, полнота, F-мера для класса libs tools
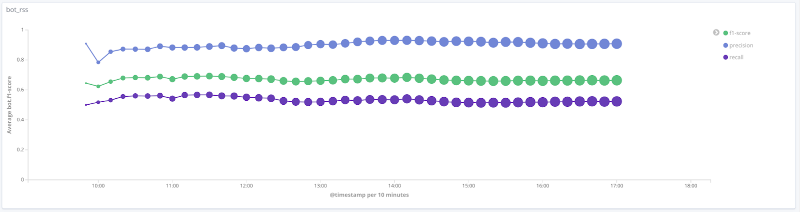
Точность, полнота, F-мера для класса rss

Точность, полнота, F-мера для класса crawler

Точность, полнота, F-мера для класса human
Для ряда классов (human, rss, search_engines) на рассматриваемых данных качество работы модели является допустимым (точность и полнота более 80%). Для класса crawler с увеличением числа сессий и качественным изменением вектора признаков для этой выборки качество работы модели растет: полнота увеличилась с 33% до 80%. Для класса libs_tools невозможно сделать разумных выводов, так как количество примеров для этого класса невелико (менее 50); поэтому отрицательный результат (низкое качество) не может быть подтвержден.
Мы описали один подход к обнаружению и классификации веб-ботов с помощью алгоритмов машинного обучения и использования статистических признаков. На рассматриваемых данных средняя точность и полнота предлагаемого решения для бинарной классификации — более 95%, что говорит о перспективности подхода. Для определенных классов веб-ботов средняя точность и полнота составляют около 80%.
Валидация построенных моделей требует реальной оценки сессии. Как было показано ранее, качество работы модели существенно возрастает при наличии корректной разметки для целевого класса. К сожалению, сейчас сложно автоматически построить такую разметку и приходится прибегать к экспертной, что усложняет построение моделей машинного обучения, но позволяет находить скрытые закономерности в данных.
Для дальнейшего развития задачи классификации и обнаружения веб-ботов целесообразно:
Автор: Николай Лыфенко, ведущий специалист группы перспективных технологий, Positive Technologies
Итак, есть два типа веб-ботов — легитимные и зловредные. К легитимным можно отнести поисковые движки, RSS-ридеры. Примеры зловредных веб-ботов ― сканеры уязвимостей, скрейперы, спамеры, боты для DDoS-атак, трояны для мошенничества с платежными картами. После определения типа веб-бота к нему могут быть применены различные политики. Если бот легитимный, можно уменьшить приоритет его запросов к серверу или снизить уровень доступа к определенным ресурсам. Если бот определен как зловредный, можно его заблокировать или отправить в песочницу для дальнейшего анализа. Обнаруживать, анализировать и классифицировать веб-боты важно, так как они могут нанести вред: например, вызвать утечку важных для бизнеса данных. А также это снизит нагрузку на сервер и сократит так называемый шум в трафике, ведь до 66% трафика веб-ботов — это именно зловредный трафик.
Существующие подходы
Есть разные техники обнаружения веб-ботов в сетевом трафике, начиная от лимитирования частоты запросов к узлу, черных списков IP-адресов, анализа значения HTTP-заголовка User-Agent, снятия отпечатков устройства — и заканчивая внедрением CAPTCHA, и поведенческим анализом сетевой активности с помощью машинного обучения.
Но сбор репутационной информации об узле и поддержка в актуальном состоянии черных списков с помощью различных баз знаний и threat intelligence — затратный, требующий больших усилий процесс, и при использовании прокси-серверов он не целесообразен.
Анализ поля User-Agent в первом приближении может показаться полезным, но ничто не мешает веб-боту или пользователю изменить значения этого поля на валидное, замаскировавшись под обычного пользователя и используя валидный User-Agent для браузера, или под легитимный бот. Назовем такие маскирующиеся веб-боты impersonators. Использование различных отпечатков устройства (отслеживание движения мыши или проверка возможности рендеринга HTML-страницы клиентом) позволяет выделять более сложные в обнаружении веб-боты, имитирующие поведение человека, например запрашивающие дополнительные страницы (файлы стилей, иконки и т. п.), парсящие JavaScript. Этот подход основан на внедрении кода на стороне клиента, что часто недопустимо, так как ошибка при вставке дополнительного скрипта может нарушить работу веб-приложения.
Следует отметить, что обнаруживать веб-боты можно и онлайн: оценка сессии будет производиться в режиме реального времени. Описание такой постановки задачи можно найти у Кабри и соавторов [1], а также в работах Зи Чу [2]. Другой подход — анализировать только после завершения сессии. Наиболее интересен, очевидно, первый вариант, который позволяет принимать решения быстрее.
Предлагаемый подход
Для выявления и классификации веб-ботов мы использовали техники машинного обучения и стек технологий ELK (Elasticsearch Logstash Kibana). Объектами исследования стали HTTP-сессии. Сессия — последовательность запросов от одного узла (уникальное значение IP-адреса и поля User-Agent в HTTP-запросе) в фиксированном временном интервале. Дерек и Гохале для определения границ сессий используют 30-минутный интервал [3]. Илиу и др. утверждают, что такой подход не гарантирует реальной уникальности сессии, но все же допустимо. В силу того, что поле User-Agent может быть изменяемым, могут появиться больше сессий, чем есть на самом деле. Поэтому Никифоракис и соавторы предлагают более тонкую настройку, основанную на том, поддерживается ли ActiveX, включен ли Flash, разрешение экрана, версия ОС.
Мы же будем считать допустимой погрешность в формировании отдельной сессии, если поле User-Agent меняется динамически. А для выявления сессий ботов построим четкую бинарную модель классификации и будем использовать:
- автоматическую сетевую активность, созданную веб-ботом (метка bot);
- сетевую активность, созданную человеком (метка human).
Для классификации веб-ботов по типу активности построим многоклассовую модель из таблицы ниже.
| Название | Описание | Метка | Примеры |
|---|---|---|---|
| Краулеры | Веб-боты, собирающие веб-страницы | crawler | SemrushBot, 360Spider, Heritrix |
| Социальные сети | Веб-боты различных социальных сетей | social_network | LinkedInBot, WhatsApp Bot, Facebook bot |
| RSS-ридеры | Веб-боты, собирающие информацию с помощью RSS | rss | Feedfetcher, Feed Reader, SimplePie |
| Поисковые движки | Веб-боты поисковых движков | search_engines | Googlebot, BingBot, YandexBot |
| Утилиты | Веб-боты, использующие различные библиотеки и утилиты для автоматизации | libs_tools | Curl, Wget, python-requests, scrapy |
| Веб-боты | Общая категория | bots | |
| Неизвестные | Такие сессии, для которых не была известна разметка или значение поля User-Agent было пустым или отсутствовало | unknown |
Также будем решать задачу онлайн-обучения модели.
Концептуальная схема предлагаемого подхода
Данный подход имеет три этапа: обучение и тестирование, предсказание, анализ результатов. Рассмотрим первые два подробнее. Концептуально подход следует классической схеме обучения и применения моделей машинного обучения. Сначала определяют метрики качества и признаки для классификации. После формируют вектор признаков и проводят серии экспериментов (различные перекрестные проверки) для валидации модели и подбора гиперпараметров. На последнем этапе выбирают наилучшую модель и проверяют качество модели на отложенной выборке.
Обучение и тестирование модели
С помощью модуля packetbeat осуществляется парсинг трафика. Сырые HTTP-запросы отправляются в logstash, где с помощью Ruby-скрипта формируются задачи в терминах Celery. Каждая из них оперирует идентификатором сессии, временем запроса, телом и заголовками запроса. Идентификатор сессии (ключ) — значение хеш-функции от конкатенации IP-адреса и User-Agent. На этом этапе создаются два вида задач:
- по формированию вектора признаков для сессии,
- по простановке меток класса на основе текста запроса и User-Agent.
Эти задачи отправляются в очередь, где обработчики сообщений их выполняют. Так, обработчик labeler выполняет задачу простановки метки класса, используя экспертную оценку и открытые данные из сервиса browscap на основе используемых User-Agent; результат записывает в key-value storage. Session processor формирует вектор признаков (см. таблицу ниже) и записывает результат для каждого ключа в key-value storage, а также устанавливает время жизни ключа (TTL).
| Признак | Описание |
|---|---|
| len | Количество запросов в сессии |
| len_pages | Количество запросов в сессии в страницах (URI заканчивается на .htm, .html, .php, .asp, .aspx, .jsp) |
| len_static_request | Количество запросов в сессии в статических страницах |
| len_sec | Время сессии в секундах |
| len_unique_uri | Количество запросов в сессии, содержащих уникальный URI |
| headers_cnt | Количество заголовков в сессии |
| has_cookie | Есть ли заголовок Сookie |
| has_referer | Есть ли заголовок Referer |
| mean_time_page | Среднее время на страницу в сессии |
| mean_time_request | Среднее время на запрос в сессии |
| mean_headers | Среднее количество заголовков в сессии |
Так формируется матрица признаков и выставляется целевая метка класса для каждой сессии. На основе этой матрицы происходят периодическое обучение моделей и последующий подбор гиперпараметров. Для обучения использовали: логистическую регрессию, метод опорных векторов, деревья принятия решений, градиентный бустинг над деревьями принятия решений, алгоритм случайного леса. Наиболее релевантные результаты мы получили с помощью алгоритма случайного леса.
Предсказание
Во время парсинга трафика обновляется вектор признаков сессии в key-value storage: c появлением нового запроса в сессии пересчитываются признаки, ее описывающие. Например, признак среднее количество заголовков в сессии (mean_headers) вычисляется каждый раз, когда в сессию добавляется новый запрос. Predictor отправляет вектор признаков сессий в модель, а ответ от модели записывает в Elasticsearch для анализа.
Эксперимент
Свое решение мы проверяли на трафике портала SecurityLab.ru. Объем данных — более 15 ГБ, более 130 часов. Количество сессий — более 10 000. В силу того, что предлагаемая модель использует статистические признаки, сессии, содержащие менее 10 запросов, не участвовали в обучении и тестировании. В качестве метрик качества мы использовали классические метрики качества ― точность, полнота и F-мера для каждого класса.
Тестирование модели обнаружения веб-ботов
Построим и оценим модель бинарной классификации, то есть будем обнаруживать ботов, а потом уже классифицировать их по типу активности. По результатам пятикратной стратифицированной перекрестной проверки (именно такая требуется для рассматриваемых данных, так как присутствует сильный дисбаланс классов) можно сказать, что построенная модель довольно хорошо (точность и полнота — более 98%) умеет разделять классы пользователей-людей и ботов.
| Средняя точность | Средняя полнота | Средняя F-мера | |
|---|---|---|---|
| bot | 0,86 | 0,90 | 0,88 |
| human | 0,98 | 0,97 | 0,97 |
Результаты тестирования модели на отложенной выборке представлены в таблице ниже.
| Точность | Полнота | F-мера | Количество примеров | |
|---|---|---|---|---|
| bot | 0,88 | 0,90 | 0,89 | 1816 |
| human | 0,98 | 0,98 | 0,98 | 9071 |
Значения метрик качества на отложенной выборке примерно совпадают со значениями метрик качества при валидации модели, значит модель на этих данных умеет обобщать знания, полученные при обучении.
Рассмотрим ошибки первого рода. Если экспертно разметить эти данные, то матрица ошибок существенно изменится. Это значит, что при разметке данных для модели были допущены некоторые ошибки, но модель все равно смогла распознать такие сессии корректным образом.
| Точность | Полнота | F-мера | Количество примеров | |
|---|---|---|---|---|
| bot | 0,93 | 0,92 | 0,93 | 2446 |
| human | 0,98 | 0,98 | 0,98 | 8441 |
Рассмотрим пример сессии impersonators. Она содержит 12 похожих запросов. Один из запросов представлен на рисунке ниже.
Все последующие запросы в этой сессии имеют такую же структуру и отличаются только URI.
Отметим, что этот веб-бот использует валидный User-Agent, добавляет поле Referer, обычно использующееся неавтоматическими средствами, и количество заголовков в сессии невелико. Кроме того, временные характеристики запросов — время сессии, среднее время на запрос — позволяют говорить о том, что эта активность автоматическая и относится к классу RSS-ридеров. При этом сам бот маскируется под обычного пользователя.
Тестирование модели классификации веб-ботов
Для классификации веб-ботов по типам активности будем использовать те же данные и тот же алгоритм, что в предыдущем эксперименте. Результаты тестирования модели на отложенной выборке представлены в таблице ниже.
| Точность | Полнота | F-мера | Количество примеров | |
|---|---|---|---|---|
| bot | 0,82 | 0,81 | 0,82 | 194 |
| crawler | 0,87 | 0,72 | 0,79 | 65 |
| libs_tools | 0,27 | 0,17 | 0,21 | 18 |
| rss | 0,95 | 0,97 | 0,96 | 1823 |
| search engines | 0,84 | 0,76 | 0,80 | 228 |
| social_network | 0,80 | 0,79 | 0,84 | 73 |
| unknown | 0,65 | 0,62 | 0,64 | 45 |
Качество для категории libs_tools низкое, но недостаточный объем примеров для оценки не позволяет говорить о корректности результатов. Следует провести повторную серию экспериментов по классификации веб-ботов на большем количестве данных. С уверенностью можно сказать, что текущая модель с довольно высокой точностью и полнотой умеет разделять классы RSS-ридеров, поисковых движков и ботов общей направленности.
Согласно этим экспериментам на рассматриваемых данных, более 22% сессий (при общем объеме более 15 ГБ) созданы автоматически, и среди них 87% относятся к активности ботов общей направленности, неизвестных ботов, RSS-ридеров, веб-ботов, использующих различные библиотеки и утилиты. Таким образом, если фильтровать сетевой трафик веб-ботов по типу активности, то предлагаемый подход позволит снизить нагрузку на используемые серверные ресурсы минимум на 9–10%.
Тестирование модели классификации веб-ботов онлайн
Суть этого эксперимента в следующем: в режиме реального времени после парсинга трафика выделяются признаки и формируются вектора признаков для каждой сессии. Периодически каждая сессия отправляется в модели для предсказания, результаты которого сохраняются.
F-мера модели во времени для каждого класса
Графики ниже иллюстрируют изменение значения метрик качества во времени для наиболее интересных классов. Размер точек на них связан с числом сессий в выборке в конкретный момент времени.
Точность, полнота, F-мера для класса search engines
Точность, полнота, F-мера для класса libs tools
Точность, полнота, F-мера для класса rss
Точность, полнота, F-мера для класса crawler
Точность, полнота, F-мера для класса human
Для ряда классов (human, rss, search_engines) на рассматриваемых данных качество работы модели является допустимым (точность и полнота более 80%). Для класса crawler с увеличением числа сессий и качественным изменением вектора признаков для этой выборки качество работы модели растет: полнота увеличилась с 33% до 80%. Для класса libs_tools невозможно сделать разумных выводов, так как количество примеров для этого класса невелико (менее 50); поэтому отрицательный результат (низкое качество) не может быть подтвержден.
Основные результаты и дальнейшее развитие
Мы описали один подход к обнаружению и классификации веб-ботов с помощью алгоритмов машинного обучения и использования статистических признаков. На рассматриваемых данных средняя точность и полнота предлагаемого решения для бинарной классификации — более 95%, что говорит о перспективности подхода. Для определенных классов веб-ботов средняя точность и полнота составляют около 80%.
Валидация построенных моделей требует реальной оценки сессии. Как было показано ранее, качество работы модели существенно возрастает при наличии корректной разметки для целевого класса. К сожалению, сейчас сложно автоматически построить такую разметку и приходится прибегать к экспертной, что усложняет построение моделей машинного обучения, но позволяет находить скрытые закономерности в данных.
Для дальнейшего развития задачи классификации и обнаружения веб-ботов целесообразно:
- выделять дополнительные классы ботов и повторно обучать, тестировать модель;
- добавлять дополнительные признаки для классификации веб-ботов. Например, добавление признака robots.txt, являющегося бинарным и отвечающего за наличие или отсутствие обращения к странице robots.txt, позволяет повысить среднюю F-меру для класса веб-ботов на 3%, не ухудшая другие метрики качества для прочих классов;
- делать более корректную разметку для целевого класса с учетом дополнительных метапризнаков и экспертной оценки.
Автор: Николай Лыфенко, ведущий специалист группы перспективных технологий, Positive Technologies
Источники
[1] Cabri A. et al. Online Web Bot Detection Using a Sequential Classification Approach. 2018 IEEE 20th International Conference on High Performance Computing and Communications.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.
[2] Chu Z., Gianvecchio S., Wang H. (2018) Bot or Human? A Behavior-Based Online Bot Detection System. In: Samarati P., Ray I., Ray I. (eds) From Database to Cyber Security. Lecture Notes in Computer Science, vol. 11170. Springer, Cham.
[3] Derek D., Gokhale S. An integrated method for real time and offline web robot detection. Expert Systems 33. 2016.
[4] Iliou Ch., et al. Towards a framework for detecting advanced Web bots. Proceedings of the 14th International Conference on Availability, Reliability and Security. 2019.
[5] Nikiforakis N., Kapravelos A., Joosen W., Kruegel C., Piessens F. and Vigna G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, 2013, pp. 541—555.

