
Эта статья является продолжением нашего цикла материалов, посвященных описанию формата Sigma-правил. Кратко напомним структуру цикла. В предыдущей публикации мы привели пример простого правила и подробно рассмотрели секцию описания источников событий. Теперь у нас есть общие представления о структуре правил, а также мы умеем указывать, откуда и какую информацию необходимо поставлять в правило для выявления подозрительной активности.
Теперь необходимо научиться описывать логику, которая будет оперировать полученными данными и выдавать вердикт о том, сработает ли наше правило в той или иной ситуации. Именно этой секции правила и ее особенностям посвящена данная статья. Описание секции логики детектирования — это наиболее важная часть синтаксиса, знание которой необходимо для понимания существующих правил и написания собственных.
В следующей публикации мы подробно остановимся на описании метаинформации (атрибуты, которые имеют информативный или инфраструктурный характер, такие, например, как описание или идентификатор) и коллекций правил. Следите за нашими публикациями!
Условия срабатывания правил задаются в атрибуте detection. В его подполях описывается основная техническая часть правила. Важно отметить, что в правиле может быть только одна описательная часть и несколько logsource и detection. Поскольку в секции детектирования описывается критерий срабатывания на основе данных из секции источников, то эти две секции имеют отношение 1 к 1.
В общем случае содержимое поля detection состоит из двух логических частей:

Описание предположений о содержимом полей события осуществляется через задание идентификаторов поиска (search identifiers). Такой идентификатор может быть один (как тут) или же их может быть несколько (как тут.
Вторая часть может быть трех видов:
Синтаксис элементов каждой из частей описан в соответствующем разделе данной статьи.
Идентификатор поиска представляет из себя пару «ключ — значение», где ключом является название идентификатора поиска, а значением является список или словарь (он же ассоциативный массив). По аналогии с языками программирования — list или map. Формат задания списков и словарей определен стандартом на язык YAML, который можно найти тут. Стоит отметить, что формат Sigma-правил не фиксирует названия идентификаторов поиска, однако чаще всего можно встретить вариации со словом selection.
Есть общие требования, которые применяются и к элементам списка, и к элементам словаря:
Идентификатор поиска в виде списка значений
Списки значений содержат строки, которые ищутся во всем сообщении события. Элементы списка объединяются логическим ИЛИ.

Примеры правил, содержащих идентификаторы поиска в виде списка значений:
Словари состоят из набора пар «ключ — значение», где ключом является название поля из события, а значение может быть строкой, целым числом или списком одного из этих типов (списки строк или чисел объединены логическим ИЛИ). Наборы словарей объединяются логическим И.
Общая схема:
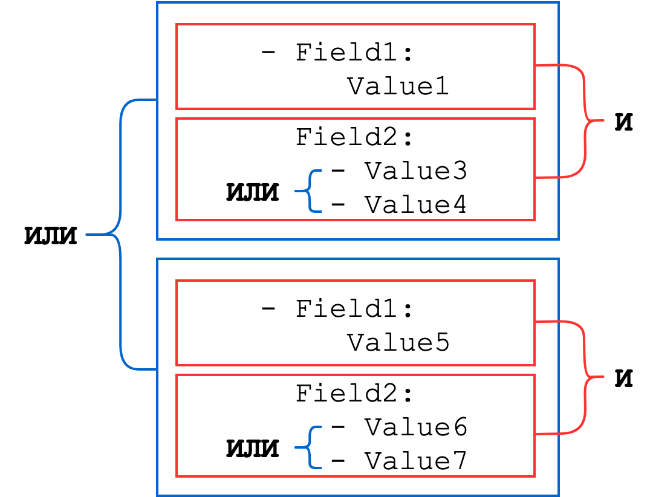
Рассмотрим несколько примеров.
Данное правило сработает, если событие удовлетворяет условию:
EventID=517 ИЛИ EventID=1102
В правиле это выглядит следующим образом:
Здесь selection — название единственного идентификатора поиска, а остальные подполя являются его значением, причем это значение имеет тип «словарь». В этом словаре EventID — ключ, а числа 517 и 1102 образуют список, который являются значением этого ключа словаря.
Данное правило сработает, если событие удовлетворяет условию:
EventID=4679 И TicketOptions=0x40810000 И TicketEncryption=0x17 И ServiceName не заканчивается на знак ‘$’
В правиле это выглядит следующим образом:
Существуют два специальных значения поля, которые могут быть использованы:
Применение этих значений зависит от целевой SIEM-системы. Чтобы описать условие not null, необходимо создать отдельный идентификатор поиска с пустым значением и взять от него отрицание в условии (поле condition, оно описывается в конце статьи). Рассмотрим далее примеры правил, в которых используется описание пустого поля.
Указанное правило сработает, если событие удовлетворяет условию:
EventID=8 И TargetImage='C:WindowsSystem32lsass.exe' И StartModule является пустым полем
В правиле это выглядит следующим образом:
Рассматриваемое правило является примером правильного обозначения непустого значения. Данное правило сработает, если событие удовлетворяет условию:
EventID=15 И I
В правиле это выглядит следующим образом:
Как и было сказано выше, отрицание теперь необходимо ставить в условии (поле condition), а не в идентификаторах поиска.
Интерпретация значений полей в правиле может быть изменена посредством модификаторов. Модификаторы добавляются после названия поля, каждому модификатору предшествует вертикальная черта (пайп) — “|”. Их можно сцеплять для построения цепочек (конвейеров) модификаторов:

Значение поля модифицируется в соответствии с порядком следования модификаторов в цепочке. Модификаторы могут быть двух типов: трансформирующие и модификаторы типа.
Трансформирующие модификаторы — это такие, которые конвертируют исходное значение поля в некое другое значение или трансформируют логику обработки списков значений в идентификаторах поиска. Примером первого типа являются Base64-модификаторы, а второго — модификатор all. Обо всех модификаторах подробнее будет рассказано далее.
Рассмотрим каждый из трансформирующих модификаторов. Для наглядности будем схематично показывать, как именно тот или иной модификатор изменяет исходное значение.
Модификатор startswith используется для сверки начала строки c искомым значением.

Примеры использования:
Модификатор endswith используется для сверки конца строки с искомым значением.

Примеры использования:
Модификатор contains проверяет вхождение подстроки в значении поля. По сути, данный модификатор преобразует значение поля следующим образом:

То есть, если рассматривать результаты применения рассмотренных модификаторов, можно написать следующую формулу:
startswith + endswith = contains
Примеры:
Обычно элементы листов объединяются логическим ИЛИ. Модификатор all меняет логическое ИЛИ на логическое И. То есть должны присутствовать все элементы списка. Посмотрим, как изменились бы условия в общей схеме, которая была в начале раздела:
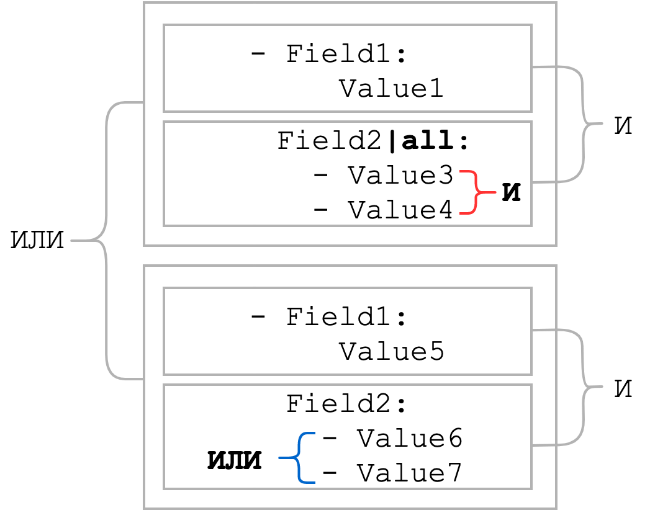
Как видим, при применении модификатора all логическая связь между элементами списка стала И. Обычно модификатор all используется в связке с модификатором contains. Такая связка может служить заменой паттерну с метасимволами подстановки в случае, если неизвестен порядок следования статических частей.
Примеры использования модификатора all:
Данный модификатор применяется, когда значение поля закодировано в Base64, а мы для наглядности в правиле пишем закодированный текст, а не результирующую Base64-строку.

Данный модификатор предполагает точное соответствие поля закодированной строке. Обычно полезнее выявлять признаки подозрительной активности в исходных данных, чем искать точное соответствие закодированному результату. Поэтому примеров применения модификатора base64 пока нет.
Из-за особенностей кодирования алгоритмом Base64 для поиска закодированной подстроки нельзя использовать конвейер из base64 и contains. Именно для этой цели создан модификатор base64offset. Он применяется, когда строка кодируется алгоритмом Base64, а мы хотим найти подстроку закодированной строки. Более того, заранее неизвестны символы, которые окружают искомую подстроку, и неизвестно смещение подстроки относительно начала строки. Наглядно посмотреть, о чем идет речь, можно тут.
Почти всегда данный модификатор применяется вместе с модификатором contains:

Примеры использования:
Модификаторы utf16le и wide являются синонимами. Они трансформируют строковое значение поля в кодировку UTF-16LE, то есть

Модификатор utf16be трансформирует строковое значение поля в UTF-16BE, то есть

Модификатор utf16 добавляет метку порядка байтов (BOM) и кодирует строку в UTF-16, то есть

Модификатор типа на данный момент только один — re.
Данный модификатор типа интерпретирует значение поля как шаблон регулярного выражения. Пока что он поддерживается только конвертором в запрос Elasticsearch, поэтому в публичных правилах практически не встречается.
Примеры использования:
Дополнительно логика детектирования может быть уточнена при помощи указания временного интервала, в течение которого должны появиться идентификаторы поиска. Для обозначения единиц измерения времени используются стандартные сокращения:
Примеры использования:
Согласно официальной документации на Sigma, часть правила, содержащая условие срабатывания, является наиболее сложной и будет изменяться с течением времени. На данный момент доступны следующие выражения.
Обозначаются ключевыми словами and и or соответственно. Данные выражения являются основными элементами выстраивания логической взаимосвязи между идентификаторами поиска.
Примеры использования:
Одно из значений идентификатора поиска / все значения идентификатора поиска (1/all of search-identifier)
То же самое, как и для предыдущего случая, если идентификатор поиска
По умолчанию
Примеры использования:
Один из идентификаторов поиска / все идентификаторы поиска (1/all of them)
Логическое ИЛИ (1 of them) или логическое И (all of them) среди всех заданных идентификаторов поиска. По умолчанию идентификаторы поиска связаны логическим И, если они являются элементами словаря, или логическим ИЛИ, если они являются элементами списка. Для изменения этих взаимосвязей и создана данная конструкция. Таким образом условие, condition: 1 of them значит, что хотя бы один из идентификаторов поиска должен появиться в событии.
Примеры использования:
То же, что для предыдущего пункта, но выборка ограничивается идентификаторами поиска, имена которых соответствуют шаблону. Такие шаблоны строятся при помощи метасимвола подстановки * (любое количество символов) на определенной позиции в паттерне имени.
Синтаксис следующий:
Примеры использования:
Логические отрицания строятся при помощи ключевого слова not. Как отмечалось выше, выражение «не пусто» необходимо описывать в поле condition, а не в описании идентификатора поиска. Следующий пример наглядно показывает правильный вариант описания выражения «значение поля не пусто».

Примеры использования:
Вертикальная черта (или пайп) обозначает, что результат выражения будет передан в агрегатную функцию, результат которой, вероятно, будет сравниваться с каким-то значением.
Общая схема:
Примеры использования:
Скобки используются для задания подвыражения. Это может быть полезно для задания порядка вычисления логического выражения или для отрицания предиката, содержащего несколько выражений. Они имеют максимальный приоритет операции.
Пример использования:
Агрегационные выражения (или выражения на основе функции агрегации) используются для оценки количественных характеристик произошедших событий.
Схема агрегационного выражения:

Все агрегатные функции, за исключением count, требуют указания имени поля в качестве параметра. Функция count подсчитывает все совпадающие события, если имя поля не указано. Если имя поля указано, то функция считает различные значения в этом поле. Например, следующее выражение подсчитывает количество различных портов, на которые происходили подключения с одного IP-адреса, и если это количество превышает 10, то правило срабатывает:
Примеры использования:
Ключевое слово near используется для генерации запроса (если такая функциональность поддерживается целевой системой и бэкендом), который распознает появление всех указанных идентификаторов поиска в пределах заданного временного интервала после нахождения первого идентификатора.
Общая схема:
Пример синтаксиса:
К выражению поиска, стоящему после слова near, применяются те же правила, что и к выражению поиска, которое находится до вертикальной черты и которое мы подробно разобрали выше.
Примеры использования:
Приоритет операций, заданный по умолчанию:
Таким образом, самый высокий приоритет у скобок, а самый низкий у пайпа.
В этом материале мы описали логику детектирования. Следите за нашими публикациями, в следующей статье мы рассмотрим оставшиеся поля правила. В большинстве своем они несут информационный или инфраструктурный характер. Помимо полей с метаинформацией остановимся на такой особенности компоновки правил, которая называется коллекции правил. Людям, мало знакомым с тонкостями языка YAML, рассмотрение этого аспекта синтаксиса будет полезно при чтении чужих и написании своих правил.
Теперь необходимо научиться описывать логику, которая будет оперировать полученными данными и выдавать вердикт о том, сработает ли наше правило в той или иной ситуации. Именно этой секции правила и ее особенностям посвящена данная статья. Описание секции логики детектирования — это наиболее важная часть синтаксиса, знание которой необходимо для понимания существующих правил и написания собственных.
В следующей публикации мы подробно остановимся на описании метаинформации (атрибуты, которые имеют информативный или инфраструктурный характер, такие, например, как описание или идентификатор) и коллекций правил. Следите за нашими публикациями!
Описание логики детектирования (атрибут detection)
Условия срабатывания правил задаются в атрибуте detection. В его подполях описывается основная техническая часть правила. Важно отметить, что в правиле может быть только одна описательная часть и несколько logsource и detection. Поскольку в секции детектирования описывается критерий срабатывания на основе данных из секции источников, то эти две секции имеют отношение 1 к 1.
В общем случае содержимое поля detection состоит из двух логических частей:
- описание предположений о полях события (идентификаторы поиска),
- логическая взаимосвязь между этими описаниями (timeframe и выражение в поле condition).
Описание предположений о содержимом полей события осуществляется через задание идентификаторов поиска (search identifiers). Такой идентификатор может быть один (как тут) или же их может быть несколько (как тут.
Вторая часть может быть трех видов:
- обычное условие,
- условие с агрегатным выражением (как в примере выше),
- условие с ключевым словом near.
Синтаксис элементов каждой из частей описан в соответствующем разделе данной статьи.
Идентификаторы поиска
Идентификатор поиска представляет из себя пару «ключ — значение», где ключом является название идентификатора поиска, а значением является список или словарь (он же ассоциативный массив). По аналогии с языками программирования — list или map. Формат задания списков и словарей определен стандартом на язык YAML, который можно найти тут. Стоит отметить, что формат Sigma-правил не фиксирует названия идентификаторов поиска, однако чаще всего можно встретить вариации со словом selection.
Есть общие требования, которые применяются и к элементам списка, и к элементам словаря:
- Все значения трактуются как регистронезависимые строки, то есть нет разницы между заглавными и строчными буквами.
- В строках допускается использование метасимволов подстановки (wildcards) ‘*’ и ‘?’. Причем ‘*’ — любое количество произвольных символов (от нуля до максимального значения), ‘?’ — один произвольный символ (или отсутствие символа).
- Метасимволы подстановки экранируются при помощи символа ‘’, например ‘*’. Если нужно найти метасимвол подстановки после бэкслеша, то бэкслеш нужно экранировать: ‘*’. Это обычные правила экранирования служебных символов в любом привычном нам языке программирования.
- По умолчанию регулярные выражения чувствительны к регистру символов, то есть существует разница между заглавными и строчными буквами в шаблоне поиска.
- Кроме символа одинарной кавычки ‘ и метасимволов экранирования другие символы экранирования не требуют.
Идентификатор поиска в виде списка значений
Списки значений содержат строки, которые ищутся во всем сообщении события. Элементы списка объединяются логическим ИЛИ.
detection: keywords: - EVILSERVICE - svchost.exe -n evil condition: keywords Примеры правил, содержащих идентификаторы поиска в виде списка значений:
- rules/web/web_apache_segfault.yml (список может состоять из одного элемента)
- rules/windows/powershell/powershell_clear_powershell_history.yml
- rules/linux/lnx_shell_susp_log_entries.yml
Идентификатор поиска в виде словаря
Словари состоят из набора пар «ключ — значение», где ключом является название поля из события, а значение может быть строкой, целым числом или списком одного из этих типов (списки строк или чисел объединены логическим ИЛИ). Наборы словарей объединяются логическим И.
Общая схема:
Рассмотрим несколько примеров.
Пример 1. Правило детектирования очистки журналов событий
rules/windows/builtin/win_susp_security_eventlog_cleared.yml
Данное правило сработает, если событие удовлетворяет условию:
EventID=517 ИЛИ EventID=1102
В правиле это выглядит следующим образом:
detection: selection: EventID: - 517 - 1102 condition: selection Здесь selection — название единственного идентификатора поиска, а остальные подполя являются его значением, причем это значение имеет тип «словарь». В этом словаре EventID — ключ, а числа 517 и 1102 образуют список, который являются значением этого ключа словаря.
Пример 2. Подозрительный запрос билета, скорее всего Kerberoasting
rules/windows/builtin/win_susp_rc4_kerberos.yml
Данное правило сработает, если событие удовлетворяет условию:
EventID=4679 И TicketOptions=0x40810000 И TicketEncryption=0x17 И ServiceName не заканчивается на знак ‘$’
В правиле это выглядит следующим образом:
detection: selection: EventID: 4769 TicketOptions: '0x40810000' TicketEncryption: '0x17' reduction: - ServiceName: '*$' condition: selection and not reduction Специальные значения полей
Существуют два специальных значения поля, которые могут быть использованы:
- Пустое значение, задаваемое двумя одинарными кавычками ''
- Значение null, задаваемое ключевым словом null
Замечание: непустое значение не может быть задано через конструкцию not null
Применение этих значений зависит от целевой SIEM-системы. Чтобы описать условие not null, необходимо создать отдельный идентификатор поиска с пустым значением и взять от него отрицание в условии (поле condition, оно описывается в конце статьи). Рассмотрим далее примеры правил, в которых используется описание пустого поля.
Пример 3. Подозрительный запуск удаленного потока
rules/windows/sysmon/sysmon_password_dumper_lsass.yml
Указанное правило сработает, если событие удовлетворяет условию:
EventID=8 И TargetImage='C:WindowsSystem32lsass.exe' И StartModule является пустым полем
В правиле это выглядит следующим образом:
detection: selection: EventID: 8 TargetImage: 'C:WindowsSystem32lsass.exe' StartModule: null condition: selection Пример 4. Запись исполняемого файла в альтернативный файловый поток NTFS
rules/windows/sysmon/sysmon_ads_executable.yml
Рассматриваемое правило является примером правильного обозначения непустого значения. Данное правило сработает, если событие удовлетворяет условию:
EventID=15 И I
mphash != '00000000000000000000000000000000' И Imphash не пустое поле В правиле это выглядит следующим образом:
detection: selection: EventID: 15 filter: Imphash: - '00000000000000000000000000000000' - null condition: selection and not filter Как и было сказано выше, отрицание теперь необходимо ставить в условии (поле condition), а не в идентификаторах поиска.
Модификаторы значений
Интерпретация значений полей в правиле может быть изменена посредством модификаторов. Модификаторы добавляются после названия поля, каждому модификатору предшествует вертикальная черта (пайп) — “|”. Их можно сцеплять для построения цепочек (конвейеров) модификаторов:
Значение поля модифицируется в соответствии с порядком следования модификаторов в цепочке. Модификаторы могут быть двух типов: трансформирующие и модификаторы типа.
Трансформирующие модификаторы — это такие, которые конвертируют исходное значение поля в некое другое значение или трансформируют логику обработки списков значений в идентификаторах поиска. Примером первого типа являются Base64-модификаторы, а второго — модификатор all. Обо всех модификаторах подробнее будет рассказано далее.
Рассмотрим каждый из трансформирующих модификаторов. Для наглядности будем схематично показывать, как именно тот или иной модификатор изменяет исходное значение.
startswith
Модификатор startswith используется для сверки начала строки c искомым значением.
Примеры использования:
- rules/windows/builtin/win_ad_replication_non_machine_account.yml
- rules/windows/process_creation/win_apt_winnti_mal_hk_jan20.yml
- rules/windows/powershell/powershell_downgrade_attack.yml
endswith
Модификатор endswith используется для сверки конца строки с искомым значением.
Примеры использования:
- rules/windows/process_creation/win_local_system_owner_account_discovery.yml
- rules/windows/sysmon/sysmon_minidumwritedump_lsass.yml
- rules/windows/process_creation/win_susp_odbcconf.yml
contains
Модификатор contains проверяет вхождение подстроки в значении поля. По сути, данный модификатор преобразует значение поля следующим образом:
То есть, если рассматривать результаты применения рассмотренных модификаторов, можно написать следующую формулу:
startswith + endswith = contains
Примеры:
- rules/windows/process_creation/win_hack_bloodhound.yml
- rules/windows/process_creation/win_mimikatz_command_line.yml
- rules/windows/sysmon/sysmon_webshell_creation_detect.yml
all
Обычно элементы листов объединяются логическим ИЛИ. Модификатор all меняет логическое ИЛИ на логическое И. То есть должны присутствовать все элементы списка. Посмотрим, как изменились бы условия в общей схеме, которая была в начале раздела:
Как видим, при применении модификатора all логическая связь между элементами списка стала И. Обычно модификатор all используется в связке с модификатором contains. Такая связка может служить заменой паттерну с метасимволами подстановки в случае, если неизвестен порядок следования статических частей.
Примеры использования модификатора all:
- rules/windows/builtin/win_meterpreter_or_cobaltstrike_getsystem_service_installation.yml
- rules/windows/powershell/powershell_suspicious_profile_create.yml
- rules/windows/powershell/powershell_suspicious_download.yml
base64
Данный модификатор применяется, когда значение поля закодировано в Base64, а мы для наглядности в правиле пишем закодированный текст, а не результирующую Base64-строку.
Данный модификатор предполагает точное соответствие поля закодированной строке. Обычно полезнее выявлять признаки подозрительной активности в исходных данных, чем искать точное соответствие закодированному результату. Поэтому примеров применения модификатора base64 пока нет.
base64offset
Из-за особенностей кодирования алгоритмом Base64 для поиска закодированной подстроки нельзя использовать конвейер из base64 и contains. Именно для этой цели создан модификатор base64offset. Он применяется, когда строка кодируется алгоритмом Base64, а мы хотим найти подстроку закодированной строки. Более того, заранее неизвестны символы, которые окружают искомую подстроку, и неизвестно смещение подстроки относительно начала строки. Наглядно посмотреть, о чем идет речь, можно тут.
Почти всегда данный модификатор применяется вместе с модификатором contains:
Примеры использования:
- rules/windows/process_creation/win_encoded_frombase64string.yml
- rules/windows/process_creation/win_encoded_iex.yml
Важно! Следующие три модификатора трансформации кодировки используются только вместе с Base64-модификаторами.
utf16le или wide
Модификаторы utf16le и wide являются синонимами. Они трансформируют строковое значение поля в кодировку UTF-16LE, то есть
“123” -> 0x31 0x00 0x32 0x00 0x33 0x00. utf16be
Модификатор utf16be трансформирует строковое значение поля в UTF-16BE, то есть
“123” -> 0x00 0x31 0x00 0x32 0x00 0x33. utf16
Модификатор utf16 добавляет метку порядка байтов (BOM) и кодирует строку в UTF-16, то есть
“123” -> 0xFF 0xFE 0x31 0x00 0x32 0x00 0x33 0x00.Модификатор типа на данный момент только один — re.
re
Данный модификатор типа интерпретирует значение поля как шаблон регулярного выражения. Пока что он поддерживается только конвертором в запрос Elasticsearch, поэтому в публичных правилах практически не встречается.
Примеры использования:
- rules/windows/process_creation/win_invoke_obfuscation_obfuscated_iex_commandline.yml
- rules/windows/builtin/win_invoke_obfuscation_obfuscated_iex_services.yml
- rules/windows/builtin/win_mal_creddumper.yml
Временной интервал (атрибут timeframe)
Дополнительно логика детектирования может быть уточнена при помощи указания временного интервала, в течение которого должны появиться идентификаторы поиска. Для обозначения единиц измерения времени используются стандартные сокращения:
15s (15 секунд) 30m (30 минут) 12h (12 часов) 7d (7 дней) 3M (3 месяца) Примеры использования:
- rules/linux/modsecurity/modsec_mulitple_blocks.yml
- rules-unsupported/net_possible_dns_rebinding.yml
- rules/windows/builtin/win_rare_service_installs.yml
Описание условий срабатывания правила (атрибут condition)
Согласно официальной документации на Sigma, часть правила, содержащая условие срабатывания, является наиболее сложной и будет изменяться с течением времени. На данный момент доступны следующие выражения.
Логические операции И, ИЛИ
Обозначаются ключевыми словами and и or соответственно. Данные выражения являются основными элементами выстраивания логической взаимосвязи между идентификаторами поиска.
detection: keywords1: - EVILSERVICE - svchost.exe -n evil keywords2: - SERVICEEVIL - svchost.exe -n live condition: keywords1 or keywords2 Примеры использования:
Одно из значений идентификатора поиска / все значения идентификатора поиска (1/all of search-identifier)
То же самое, как и для предыдущего случая, если идентификатор поиска
- 1 — логическое ИЛИ среди альтернатив,
- all — логическое И среди альтернатив.
По умолчанию
condition: keywords означает, что значения, перечисленные в идентификаторе keywords, объединяются логическим ИЛИ, то есть это то же самое, что написать condition: 1 of keywords. Если же мы хотим, чтобы значения объединились логическим И, то нужно написать condition: all of keywords.Примеры использования:
Один из идентификаторов поиска / все идентификаторы поиска (1/all of them)
Логическое ИЛИ (1 of them) или логическое И (all of them) среди всех заданных идентификаторов поиска. По умолчанию идентификаторы поиска связаны логическим И, если они являются элементами словаря, или логическим ИЛИ, если они являются элементами списка. Для изменения этих взаимосвязей и создана данная конструкция. Таким образом условие, condition: 1 of them значит, что хотя бы один из идентификаторов поиска должен появиться в событии.
Примеры использования:
- rules/windows/process_creation/win_hack_bloodhound.yml
- rules/windows/powershell/powershell_psattack.yml
- rules/cloud/aws_ec2_download_userdata.yml
Один из идентификаторов поиска, подходящих под паттерн имени / все идентификаторы поиска, подходящие под паттерн имени (1/all of search-identifier-pattern)
То же, что для предыдущего пункта, но выборка ограничивается идентификаторами поиска, имена которых соответствуют шаблону. Такие шаблоны строятся при помощи метасимвола подстановки * (любое количество символов) на определенной позиции в паттерне имени.
Синтаксис следующий:
condition: 1 of selection* или condition: all of selection* Примеры использования:
- rules/windows/builtin/win_user_added_to_local_administrators.yml
- rules/windows/process_creation/win_susp_eventlog_clear.yml
- rules/cloud/aws_iam_backdoor_users_keys.yml
Логическое отрицание
Логические отрицания строятся при помощи ключевого слова not. Как отмечалось выше, выражение «не пусто» необходимо описывать в поле condition, а не в описании идентификатора поиска. Следующий пример наглядно показывает правильный вариант описания выражения «значение поля не пусто».
Примеры использования:
- rules/windows/sysmon/sysmon_malware_backconnect_ports.yml
- rules/windows/process_creation/win_apt_gallium.yml
Пайп
Вертикальная черта (или пайп) обозначает, что результат выражения будет передан в агрегатную функцию, результат которой, вероятно, будет сравниваться с каким-то значением.
Общая схема:
предикат_поиска | предикат_агрегации условие condition: selection | count(category) by dst_ip > 30 Примеры использования:
- rules/windows/builtin/win_susp_failed_logons_single_source.yml
- rules/windows/other/win_rare_schtask_creation.yml
- rules/network/net_high_dns_requests_rate.yml
Скобки
Скобки используются для задания подвыражения. Это может быть полезно для задания порядка вычисления логического выражения или для отрицания предиката, содержащего несколько выражений. Они имеют максимальный приоритет операции.
condition: selection and (keywords1 or keywords2) или condition: selection and not (filter1 or filter2) Пример использования:
Выражения на основе функции агрегации
Агрегационные выражения (или выражения на основе функции агрегации) используются для оценки количественных характеристик произошедших событий.
Схема агрегационного выражения:
Все агрегатные функции, за исключением count, требуют указания имени поля в качестве параметра. Функция count подсчитывает все совпадающие события, если имя поля не указано. Если имя поля указано, то функция считает различные значения в этом поле. Например, следующее выражение подсчитывает количество различных портов, на которые происходили подключения с одного IP-адреса, и если это количество превышает 10, то правило срабатывает:
condition: selection | count(dst_port) by src_ip > 10 Примеры использования:
- rules/linux/lnx_susp_failed_logons_single_source.yml
- rules/windows/other/win_rare_schtask_creation.yml
- rules/network/net_susp_network_scan.yml
Агрегатное выражение near
Ключевое слово near используется для генерации запроса (если такая функциональность поддерживается целевой системой и бэкендом), который распознает появление всех указанных идентификаторов поиска в пределах заданного временного интервала после нахождения первого идентификатора.
Общая схема:
near search-id-1 [ [ and search-id-2 | and not search-id-3 ] ... ] Пример синтаксиса:
timeframe: 30s condition: selector | near dllload1 and dllload2 and not exclusion К выражению поиска, стоящему после слова near, применяются те же правила, что и к выражению поиска, которое находится до вертикальной черты и которое мы подробно разобрали выше.
Примеры использования:
- rules/windows/sysmon/sysmon_mimikatz_inmemory_detection.yml
- rules/windows/builtin/win_susp_samr_pwset.yml
Приоритет операций, заданный по умолчанию:
- (expression)
- X of search-pattern
- Not
- And
- Or
- |
Таким образом, самый высокий приоритет у скобок, а самый низкий у пайпа.
Замечание: если задано несколько полей condition, то итоговое значение получается применением логического ИЛИ ко всем значениям выражений.
В этом материале мы описали логику детектирования. Следите за нашими публикациями, в следующей статье мы рассмотрим оставшиеся поля правила. В большинстве своем они несут информационный или инфраструктурный характер. Помимо полей с метаинформацией остановимся на такой особенности компоновки правил, которая называется коллекции правил. Людям, мало знакомым с тонкостями языка YAML, рассмотрение этого аспекта синтаксиса будет полезно при чтении чужих и написании своих правил.

