
Завершаем цикл статей, посвященный правилам корреляции, работающим «из коробки». Мы ставили цель сформулировать подход, который бы позволил создавать правила корреляции, способные работать «из коробки» с минимальным количеством ложных срабатываний.

Изображение: Software Marketing
Все ключевые моменты статьи доступны в выводе, там же данная методология представлена в виде графической схемы.
Коротко о том, что было в предыдущих статьях: описали, как должен выглядеть набор полей нормализованного события — схема; какую систему категоризации событий использовать; как оперируя системой категоризации и схемой унифицировать процесс нормализации событий. Также рассмотрели контекст исполнения правил корреляции и разобрали, что должен знать SIEM об Автоматизированной системе (АС), за которой он наблюдает, и почему.
Все перечисленные выше подходы и рассуждения — блоки, из которых строится методология разработки правил корреляции. Пришло время собрать их вместе и посмотреть на всю картину целиком.
Вся методология разработки правил корреляции состоит из четырех блоков:
Правила корреляции оперируют событиями, которые генерируют источники. В связи с этим крайне важно, чтобы требуемые для правил корреляции источники присутствовали в АС и были корректно настроены.
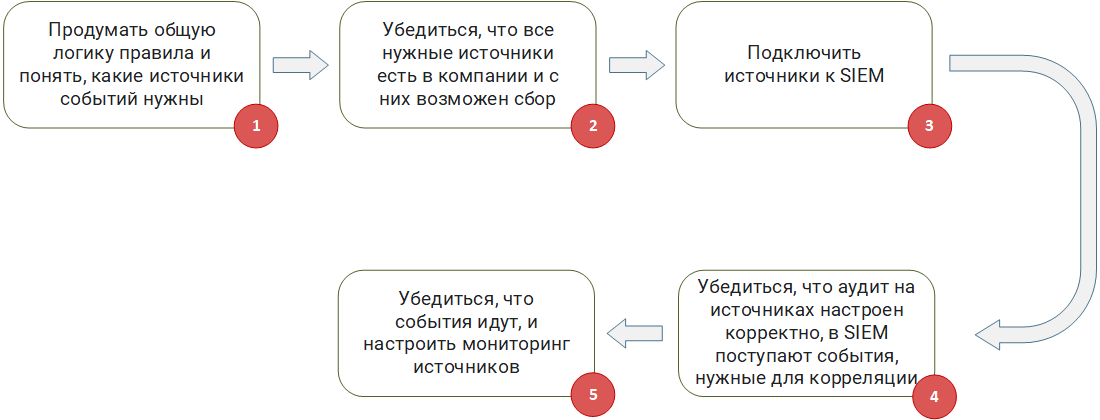
Подготовка источников и окружения
Шаг 1: Продумать общую логику правила и понять, какие источники событий нужны. Если вы разрабатываете с нуля или берете уже готовое Sigma-правило корреляции, то необходимо понять, на основе событий из каких источников оно будет работать.
Шаг 2: Убедиться, что все нужные источники есть в компании и с них возможен сбор. Возможна такая ситуация, когда правило оперирует цепочкой событий от нескольких источников вида (событие A от источника 1) — (событие B от источника 2) — (событие C от источника 3) в течение 5 минут. Если в вашей компании нет хотя бы одного источника, такое правило становится бесполезным, так как никогда не сработает. Необходимо понимать, возможен ли в принципе сбор событий с необходимых источников и может ли его обеспечить ваш SIEM. Например, источник пишет события в файл, но файл шифруется, или на источнике для хранения используется нестандартная база, доступ к которой невозможно обеспечить через штатный ODBC/JDBC драйвер.
Шаг 3: Подключить источники к SIEM. Как бы это банально не звучало, но на данном шаге необходимо реализовать сам сбор событий. Здесь часто возникает множество проблем. Например, организационные проблемы, когда руководство ИТ категорически запрещает подключаться к mission critical – системам. Или технические, когда без дополнительных настроек агент SIEM (SmartConnector, Universal Forwarder) при сборе событий попросту «убивает» источник, приводя к отказу в обслуживании. Такое часто можно наблюдать при подключении высоконагруженных СУБД к SIEM.
Шаг 4: Убедиться, что аудит на источниках настроен корректно, в SIEM поступают события, нужные для корреляции. Правила корреляции ожидают определенные типы событий. Их должен генерировать источник. Зачастую бывает так, что для генерации необходимых для правил событий, источник должен быть дополнительно настроен: включен расширенный аудит и настроен вывод логов в определенном формате.
Включение расширенного аудита часто сказывается на объеме потока событий (EPS), поступающих в SIEM от источника. В связи с тем, что сам источник и SIEM находятся в зоне ответственности разных подразделений, всегда есть риск того, что расширенный аудит может быть отключен и, как следствие, в SIEM прекратят приходить необходимые типы событий. Отчасти выявить эту проблему может мониторинг потока событий для каждого источника, а точнее, контроль изменения Events per Second (EPS).
Шаг 5: Убедиться, что события идут, и настроить мониторинг источников. В любой инфраструктуре, рано или поздно появляются сбои в работе сети или самого источника. В этот момент SIEM теряет с источником связь и не может получать события. Если источник пассивный и пишет свои логи в файл или базу, при сбое события не потеряются и при восстановлении связи SIEM сможет их получить. Если источник активный и сам шлет в SIEM события, например, по syslog, при этом никуда их дополнительно не сохраняя, то при сбое события будут потеряны, а ваше правило корреляции попросту не сработает, так как не дождется нужного события. Копнув глубже, можно заметить, что, работая даже с пассивным источником, при восстановлении с ним связи после сбоя нет гарантий, что правила корреляции отработают, особенно те, которые оперируют временными окнами. Рассмотрим описанный выше пример правила: (событие A от источника 1) — (событие B от источника 2) — (событие C от источника 3) в течение 5 минут. Если сбой произойдет после события Б и связь восстановится через час, корреляция не отработает, так как в ожидаемые 5 минут событие C так и не придет.
Помня эти особенности, следует настроить мониторинг источников, с которых происходит сбор событий. Данный мониторинг должен следить за доступностью источников, своевременностью прихода с них событий, мощностью потока собираемых событий (EPS).
Срабатывание системы мониторинга — первый звонок, говорящий о появлении негативного фактора, влияющего на работоспособность всех или части правил корреляции.
Собрать необходимые для корреляции события – не достаточно. Поступающие в SIEM события необходимо нормализовать строго в соответствии с принятыми правилами. О проблемах нормализации и формировании методологии нормализации мы писали в отдельной статье. В целом же данный блок можно охарактеризовать как борьбу с garbage in, garbage out ( GIGO).

Нормализация и обогащения событий
Шаг 6 и Шаг 7: Категоризация событий и нормализация событий в соответствии с категорией, на базе методологии. Не будем на них подробно останавливаться, так как эти шаги мы детально рассмотрели в статье «Методология нормализации событий».
Шаг 8: Обогащение событий недостающей и дополнительной информацией, в соответствии с категорией. Часто приходящие события не всегда содержат информацию в объеме, необходимом для работы правил корреляции. Например, событие содержит только IP-адрес хоста, но в нем нет информации о его FQDN или Hostname. Другой пример: событие содержит ID пользователя, но имени пользователя в событии нет. В таком случае необходимую информацию следует извлекать из внешних источников — баз данных, контроллеров домена или иных справочников и добавлять ее в событие.
Важно отметить, что категоризация событий идет в самом начале — до нормализации. Помимо того, что категория определяет правила нормализации события, она же задает тот перечень данных, которые необходимо искать во внешних источниках, если их нет в самом событии.
После того, как вы подготовили входные данные (события) и перешли к разработке правил корреляции, необходимо учесть специфику поступающих событий, самой АС и ее изменчивость. Подробнее об этом было в статье «Модель системы как контекст правил корреляции».
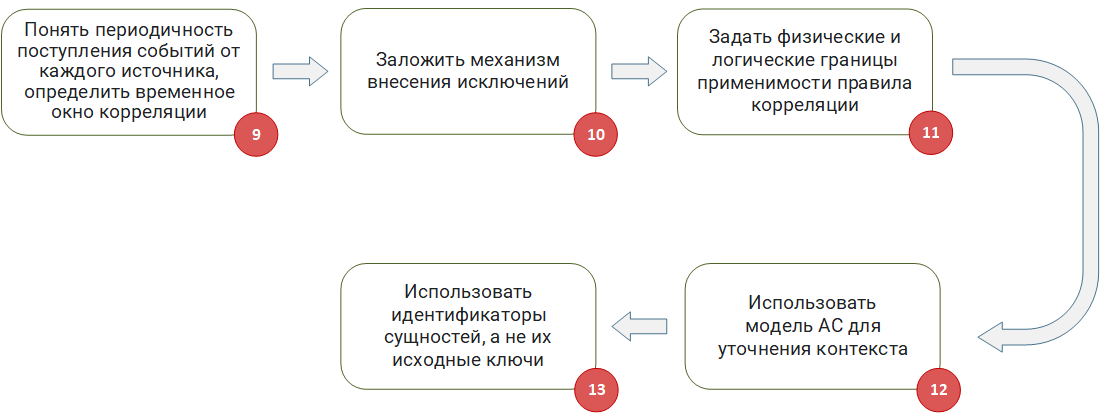
Адаптация правил корреляции к контексту АС
Шаг 9: Понять периодичность поступления событий от каждого источника, определить временное окно корреляции. Достаточно часто в правилах корреляции используются временные окна, когда необходимо ожидать прихода определенного события в течение заданного временного интервала. Разрабатывая подобные правила важно учитывать задержку получения событий. Они, как правило, вызваны двумя факторами.
Во-первых, сам источник может не сразу записывать события в базу, в файл или отсылать его по syslog. Время этой задержки надо оценить и учесть в правиле.
Во-вторых, есть задержка доставки событий в SIEM. Например, сбор событий из базы данных настроен так, что запрос событий выполняется 1 раз в 10 мин, естественно, что окно корреляции в 5 мин в такой ситуации не лучшее решение.
Проблема усугубляется, когда необходимо разработать правило корреляции, которое работает с событиями сразу от нескольких источников. В таком случае важно понимать, что время доставки у них может быть разное. В худшем случае события будут приходить в произвольном порядке с нарушением хронологии. В такой ситуации разработчику правил корреляции необходимо четко понимать, в каком времени SIEM реализует корреляцию (в событийном времени или времени поступления события в SIEM). Отмечу, что корреляция во времени поступления событий — самый технически простой и распространенный вариант для обработки событий в режиме псевдо-реального времени. Однако данный вариант лишь усугубляет вышеописанные проблемы, а не решает их.
Если ваш SIEM обеспечивает корреляцию в событийном времени, то, скорее всего, там есть механизмы переупорядочивания событий, способные восстановить действительную хронологию событий.
В случае, когда вы понимаете, что временное окно слишком большое, чтобы делать корреляцию на потоке, необходимо использовать механизм ретро корреляции, при котором уже сохраненные события выбираются из базы SIEM по расписанию и прогоняются через правила корреляции.
Шаг 10: Заложить механизм внесения исключений. В реальном мире всегда найдется объект с особым поведением, который не должен обрабатываться конкретным правилом корреляции, так как это приводит к ложному срабатыванию. Следовательно, на этапе разработки правил должны быть заложены механизмы для внесения подобных объектов в исключения. Например, если ваше правило работает с IP-адресами машин, необходим табличный список, куда можно будет добавить адреса, для которых правило не будет срабатывать. Аналогично, если правило работает с логинами пользователей или именами процессов, необходимо заранее заложить в логику правила работу с табличными списками исключений.
Такой подход позволит автоматически или вручную вносить объекты в исключения, не переписывая самого тела правила.
Шаг 11: Задать физические и логические границы применимости правила корреляции. При разработке правила корреляции важно изначально понять границы применимости (область действия) правила, и есть ли они вообще. Прорабатывая логику и отлаживая правило, необходимо акцентировать свое внимание на специфики данной области. Если правило начинает работать с данными, которые выходят за рамки этой области, — повышается вероятность ложных срабатываний.
Можно выделить два типа области действия: физическая и логическая. Физическая область действия — сети компании и смежные сети, а логическая область — части АС, бизнес-приложения или бизнес-процессы. Примеры физической области: DMZ-сегмент, внутренние и внешние подсети, сети удаленного доступа. Примеры логической области действия правил: АСУ ТП, бухгалтерия, PCI DSS-сегмент, ПДн-сегмент или просто конкретные роли оборудования — контроллеры домена, коммутаторы доступа, маршрутизаторы ядра.
Задавать области действия для правил корреляции возможно через табличные списки. Они могут быть заполнены как вручную, так и автоматически. Если в своей компании вы находите время на управление активами (Asset management), то все необходимые данные могут уже содержаться в модели АС, создаваемой в SIEM. Автоматическое формирование таких табличных списков позволяет динамически включать в область действия новые активы, появляющиеся в компании. К примеру, если у вас было правило, которое работало исключительно с контроллерами домена, добавление нового контроллера в доменный лес будет зафиксировано в модели и попадет в область действия вашего правила.
В целом табличные списки, используемые для исключений, можно рассматривать как черные, а списки, отвечающие за область действия правил, как белые списки.
Шаг 12: Использовать модель АС для уточнения контекста. В процессе разработки правила корреляции, выявляющего зловредные действия, важно убедиться в том, что они действительно могут быть реализованы. Если этого не учитывать, срабатывание правила, выявившего потенциальную атаку, окажется ложным, так как такой вид атаки может быть попросту не применим к вашей инфраструктуре. Поясню на примере:
В процессе расследования вы быстро выясняете, что на myserver.local 3389 закрыт и никогда не открывался никаким сервисом и там стоит Linux. Это ложное срабатывание правила, отнявшее у вас время на расследование.
Другой пример: IPS присылает событие о срабатывании сигнатуры по попытке эксплуатации уязвимости CVE-2017-0144, однако в процессе расследования выясняется, что на атакуемой машине установлен соответствующий патч и на такой инцидент нет необходимости реагировать с наивысшим приоритетом.
Использование данных из модели АС помогут нивелировать эту проблему.
Шаг 13: Использовать идентификаторы сущностей, а не их исходные ключи. Как уже было описано в статье «Модель системы как контекст правил корреляции» IP-адрес, FQDN и даже MAC актива может меняться. Таким образом, если использовать в правиле корреляции или табличном списке исходные идентификаторы актива, то высок шанс через некоторое время получить ложные срабатывания по вполне банальной причине, к примеру DHCP-сервер просто выдал данный IP другой машине.
Если ваш SIEM имеет механизм идентификации активов, отслеживания их изменений и позволяет оперировать их идентификаторами, следует использовать именно идентификаторы, а не исходные ключи актива.
Подходя к заключительному блоку создания правила корреляции, напомним, что результатом работы правила является инцидент, заведенный в SIEM. На такой инцидент должны реагировать ответственные специалисты. Хотя в цели данного цикла статей и не входит рассмотрение процесса реагирования на инциденты, следует отметить, что часть информации по инциденту формируется уже на этапе создания соответствующего правила корреляции.
Далее рассмотрим базовые моменты, которые необходимо учесть при настройке параметров срабатывания правила корреляции и порождении инцидента.

Формирование соглашения о срабатываниях
Шаг 14: Определить условия агрегации и отключения в случае большого числа ложных срабатываний. На этапе отладки, да и в процессе своего функционирования, если не придерживаться данной методики :), могут происходить ложные срабатывания правил. Хорошо, если таких один или два срабатывания за день, но что делать, если у одного правила тысячи или десятки тысяч срабатываний? Конечно, это говорит о том, что правило необходимо дорабатывать. Однако необходимо сделать так, чтобы в подобных ситуациях такое массовое ложное срабатывание:
Проблемы такого рода могут быть решены, если при создании правила корреляции на уровне всей системы в целом или для каждого правила в отдельности задать условия агрегации инцидентов и условия аварийного отключения правила.
Механизм агрегации инцидентов позволит не создавать миллионы одинаковых инцидентов, а «подклеивать» новые инциденты к одному, при условии их идентичности. В крайних случаях, когда даже агрегация инцидентов дает значительную нагрузку, рекомендуется настроить автоматическое отключение правила корреляции при превышении заданного количества срабатываний в единицу времени (минута, час, сутки).
Шаг 15: Определить правила формирования названия инцидента. Этим пунктом часто пренебрегают, особенно если разрабатывают правила не для своей компании, например, если за внедрение SIEM и разработку правил отвечает сторонняя компания. Имя правила корреляции, а также порожденного им инцидента должно быть коротким и четко отражать суть конкретного правила.
Если в вашей компании с инцидентами и правилами корреляции работает не один человек, рекомендуется разработать правила именования. Они должны быть понятны и приняты всей командой, работающей с SIEM.
Шаг 16: Определить правила формирования важности инцидента. Большинство SIEM-решений на последнем этапе создания инцидента позволяют задать его важность и значимость. Часть решений даже вычисляет важность автоматически, исходя из контекста инцидента и участвующих в нем объектов.
В случае, если в вашем SIEM работает исключительно автоматическое вычисление важности инцидентов, стоит разобраться на основании чего и по какой формуле она рассчитывается. К примеру, если важность рассчитывается на основе значимости активов, участвующих в инциденте, необходимо заранее серьезно подойти к вопросам управления активами (Asset Management) в компании.
Если вы задаете важность инцидента вручную, рекомендуется выработать формулу расчета, учитывающую как минимум следующее:
Также, как и в именовании инцидентов, важно, чтобы все заинтересованные лица четко и одинаково понимали, по каким правилам формируется важность инцидента.
name="Conclusions">
Подводя итоги нашего цикла статей, отмечу, что создать правила корреляции, работающих «из коробки», на мой взгляд, возможно. Выходом может стать сплав организационных и технических подходов. Что-то должен уметь сам SIEM, а что-то должны выполнять и знать эксплуатирующие его специалисты.
Подытожим:
name="Schema">
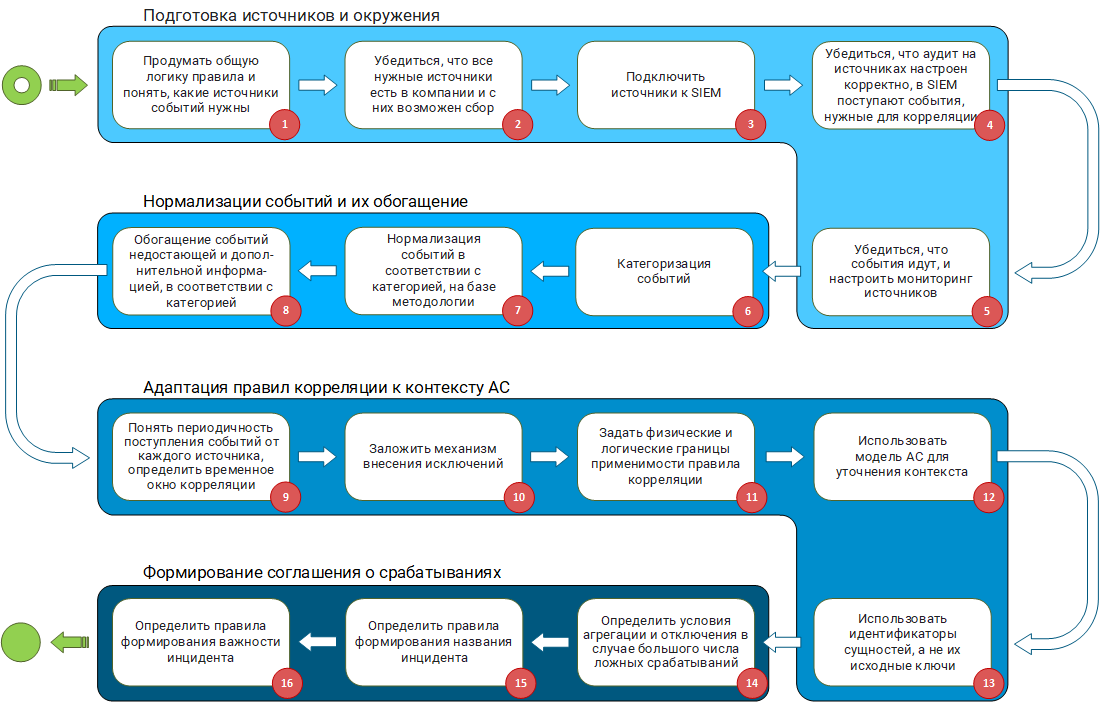
Методология разработки правил корреляции, работающих «из коробки»
Большое спасибо всем, кто осилил весь цикл статей, или хотя бы дочитал до этих строк. Если у вас возникнут вопросы — пишите в личку или задавайте их в комментариях. Буду рад обсудить.
name="Articles">
Цикл статей:
Глубины SIEM: корреляции «из коробки». Часть 1: Чистый маркетинг или нерешаемая проблема?
Глубины SIEM: корреляции «из коробки». Часть 2. Схема данных как отражение модели «мира»
Глубины SIEM: корреляции «из коробки». Часть 3.1. Категоризация событий
Глубины SIEM: корреляции «из коробки». Часть 3.2. Методология нормализации событий
Глубины SIEM: корреляции «из коробки». Часть 4. Модель системы как контекст правил корреляции
Глубины SIEM: корреляции «из коробки». Часть 5. Методология разработки правил корреляции (Данная статья)
Изображение: Software Marketing
Все ключевые моменты статьи доступны в выводе, там же данная методология представлена в виде графической схемы.
Коротко о том, что было в предыдущих статьях: описали, как должен выглядеть набор полей нормализованного события — схема; какую систему категоризации событий использовать; как оперируя системой категоризации и схемой унифицировать процесс нормализации событий. Также рассмотрели контекст исполнения правил корреляции и разобрали, что должен знать SIEM об Автоматизированной системе (АС), за которой он наблюдает, и почему.
Все перечисленные выше подходы и рассуждения — блоки, из которых строится методология разработки правил корреляции. Пришло время собрать их вместе и посмотреть на всю картину целиком.
Вся методология разработки правил корреляции состоит из четырех блоков:
- подготовка источников и окружения;
- нормализация событий и их обогащение;
- адаптация правил корреляции к контексту АС;
- формирование соглашения о срабатываниях.
Подготовка источников и окружения
Правила корреляции оперируют событиями, которые генерируют источники. В связи с этим крайне важно, чтобы требуемые для правил корреляции источники присутствовали в АС и были корректно настроены.
Подготовка источников и окружения
Шаг 1: Продумать общую логику правила и понять, какие источники событий нужны. Если вы разрабатываете с нуля или берете уже готовое Sigma-правило корреляции, то необходимо понять, на основе событий из каких источников оно будет работать.
Шаг 2: Убедиться, что все нужные источники есть в компании и с них возможен сбор. Возможна такая ситуация, когда правило оперирует цепочкой событий от нескольких источников вида (событие A от источника 1) — (событие B от источника 2) — (событие C от источника 3) в течение 5 минут. Если в вашей компании нет хотя бы одного источника, такое правило становится бесполезным, так как никогда не сработает. Необходимо понимать, возможен ли в принципе сбор событий с необходимых источников и может ли его обеспечить ваш SIEM. Например, источник пишет события в файл, но файл шифруется, или на источнике для хранения используется нестандартная база, доступ к которой невозможно обеспечить через штатный ODBC/JDBC драйвер.
Шаг 3: Подключить источники к SIEM. Как бы это банально не звучало, но на данном шаге необходимо реализовать сам сбор событий. Здесь часто возникает множество проблем. Например, организационные проблемы, когда руководство ИТ категорически запрещает подключаться к mission critical – системам. Или технические, когда без дополнительных настроек агент SIEM (SmartConnector, Universal Forwarder) при сборе событий попросту «убивает» источник, приводя к отказу в обслуживании. Такое часто можно наблюдать при подключении высоконагруженных СУБД к SIEM.
Шаг 4: Убедиться, что аудит на источниках настроен корректно, в SIEM поступают события, нужные для корреляции. Правила корреляции ожидают определенные типы событий. Их должен генерировать источник. Зачастую бывает так, что для генерации необходимых для правил событий, источник должен быть дополнительно настроен: включен расширенный аудит и настроен вывод логов в определенном формате.
Включение расширенного аудита часто сказывается на объеме потока событий (EPS), поступающих в SIEM от источника. В связи с тем, что сам источник и SIEM находятся в зоне ответственности разных подразделений, всегда есть риск того, что расширенный аудит может быть отключен и, как следствие, в SIEM прекратят приходить необходимые типы событий. Отчасти выявить эту проблему может мониторинг потока событий для каждого источника, а точнее, контроль изменения Events per Second (EPS).
Шаг 5: Убедиться, что события идут, и настроить мониторинг источников. В любой инфраструктуре, рано или поздно появляются сбои в работе сети или самого источника. В этот момент SIEM теряет с источником связь и не может получать события. Если источник пассивный и пишет свои логи в файл или базу, при сбое события не потеряются и при восстановлении связи SIEM сможет их получить. Если источник активный и сам шлет в SIEM события, например, по syslog, при этом никуда их дополнительно не сохраняя, то при сбое события будут потеряны, а ваше правило корреляции попросту не сработает, так как не дождется нужного события. Копнув глубже, можно заметить, что, работая даже с пассивным источником, при восстановлении с ним связи после сбоя нет гарантий, что правила корреляции отработают, особенно те, которые оперируют временными окнами. Рассмотрим описанный выше пример правила: (событие A от источника 1) — (событие B от источника 2) — (событие C от источника 3) в течение 5 минут. Если сбой произойдет после события Б и связь восстановится через час, корреляция не отработает, так как в ожидаемые 5 минут событие C так и не придет.
Помня эти особенности, следует настроить мониторинг источников, с которых происходит сбор событий. Данный мониторинг должен следить за доступностью источников, своевременностью прихода с них событий, мощностью потока собираемых событий (EPS).
Срабатывание системы мониторинга — первый звонок, говорящий о появлении негативного фактора, влияющего на работоспособность всех или части правил корреляции.
Нормализация событий и их обогащение
Собрать необходимые для корреляции события – не достаточно. Поступающие в SIEM события необходимо нормализовать строго в соответствии с принятыми правилами. О проблемах нормализации и формировании методологии нормализации мы писали в отдельной статье. В целом же данный блок можно охарактеризовать как борьбу с garbage in, garbage out ( GIGO).
Нормализация и обогащения событий
Шаг 6 и Шаг 7: Категоризация событий и нормализация событий в соответствии с категорией, на базе методологии. Не будем на них подробно останавливаться, так как эти шаги мы детально рассмотрели в статье «Методология нормализации событий».
Шаг 8: Обогащение событий недостающей и дополнительной информацией, в соответствии с категорией. Часто приходящие события не всегда содержат информацию в объеме, необходимом для работы правил корреляции. Например, событие содержит только IP-адрес хоста, но в нем нет информации о его FQDN или Hostname. Другой пример: событие содержит ID пользователя, но имени пользователя в событии нет. В таком случае необходимую информацию следует извлекать из внешних источников — баз данных, контроллеров домена или иных справочников и добавлять ее в событие.
Важно отметить, что категоризация событий идет в самом начале — до нормализации. Помимо того, что категория определяет правила нормализации события, она же задает тот перечень данных, которые необходимо искать во внешних источниках, если их нет в самом событии.
Адаптация правил корреляции к контексту АС
После того, как вы подготовили входные данные (события) и перешли к разработке правил корреляции, необходимо учесть специфику поступающих событий, самой АС и ее изменчивость. Подробнее об этом было в статье «Модель системы как контекст правил корреляции».
Адаптация правил корреляции к контексту АС
Шаг 9: Понять периодичность поступления событий от каждого источника, определить временное окно корреляции. Достаточно часто в правилах корреляции используются временные окна, когда необходимо ожидать прихода определенного события в течение заданного временного интервала. Разрабатывая подобные правила важно учитывать задержку получения событий. Они, как правило, вызваны двумя факторами.
Во-первых, сам источник может не сразу записывать события в базу, в файл или отсылать его по syslog. Время этой задержки надо оценить и учесть в правиле.
Во-вторых, есть задержка доставки событий в SIEM. Например, сбор событий из базы данных настроен так, что запрос событий выполняется 1 раз в 10 мин, естественно, что окно корреляции в 5 мин в такой ситуации не лучшее решение.
Проблема усугубляется, когда необходимо разработать правило корреляции, которое работает с событиями сразу от нескольких источников. В таком случае важно понимать, что время доставки у них может быть разное. В худшем случае события будут приходить в произвольном порядке с нарушением хронологии. В такой ситуации разработчику правил корреляции необходимо четко понимать, в каком времени SIEM реализует корреляцию (в событийном времени или времени поступления события в SIEM). Отмечу, что корреляция во времени поступления событий — самый технически простой и распространенный вариант для обработки событий в режиме псевдо-реального времени. Однако данный вариант лишь усугубляет вышеописанные проблемы, а не решает их.
Если ваш SIEM обеспечивает корреляцию в событийном времени, то, скорее всего, там есть механизмы переупорядочивания событий, способные восстановить действительную хронологию событий.
В случае, когда вы понимаете, что временное окно слишком большое, чтобы делать корреляцию на потоке, необходимо использовать механизм ретро корреляции, при котором уже сохраненные события выбираются из базы SIEM по расписанию и прогоняются через правила корреляции.
Шаг 10: Заложить механизм внесения исключений. В реальном мире всегда найдется объект с особым поведением, который не должен обрабатываться конкретным правилом корреляции, так как это приводит к ложному срабатыванию. Следовательно, на этапе разработки правил должны быть заложены механизмы для внесения подобных объектов в исключения. Например, если ваше правило работает с IP-адресами машин, необходим табличный список, куда можно будет добавить адреса, для которых правило не будет срабатывать. Аналогично, если правило работает с логинами пользователей или именами процессов, необходимо заранее заложить в логику правила работу с табличными списками исключений.
Такой подход позволит автоматически или вручную вносить объекты в исключения, не переписывая самого тела правила.
Шаг 11: Задать физические и логические границы применимости правила корреляции. При разработке правила корреляции важно изначально понять границы применимости (область действия) правила, и есть ли они вообще. Прорабатывая логику и отлаживая правило, необходимо акцентировать свое внимание на специфики данной области. Если правило начинает работать с данными, которые выходят за рамки этой области, — повышается вероятность ложных срабатываний.
Можно выделить два типа области действия: физическая и логическая. Физическая область действия — сети компании и смежные сети, а логическая область — части АС, бизнес-приложения или бизнес-процессы. Примеры физической области: DMZ-сегмент, внутренние и внешние подсети, сети удаленного доступа. Примеры логической области действия правил: АСУ ТП, бухгалтерия, PCI DSS-сегмент, ПДн-сегмент или просто конкретные роли оборудования — контроллеры домена, коммутаторы доступа, маршрутизаторы ядра.
Задавать области действия для правил корреляции возможно через табличные списки. Они могут быть заполнены как вручную, так и автоматически. Если в своей компании вы находите время на управление активами (Asset management), то все необходимые данные могут уже содержаться в модели АС, создаваемой в SIEM. Автоматическое формирование таких табличных списков позволяет динамически включать в область действия новые активы, появляющиеся в компании. К примеру, если у вас было правило, которое работало исключительно с контроллерами домена, добавление нового контроллера в доменный лес будет зафиксировано в модели и попадет в область действия вашего правила.
В целом табличные списки, используемые для исключений, можно рассматривать как черные, а списки, отвечающие за область действия правил, как белые списки.
Шаг 12: Использовать модель АС для уточнения контекста. В процессе разработки правила корреляции, выявляющего зловредные действия, важно убедиться в том, что они действительно могут быть реализованы. Если этого не учитывать, срабатывание правила, выявившего потенциальную атаку, окажется ложным, так как такой вид атаки может быть попросту не применим к вашей инфраструктуре. Поясню на примере:
- Пусть у нас есть правило корреляции, выявляющее удаленные подключения по RDP к серверам.
- Межсетевой экран приносит событие о попытке подключения на TCP-порт 3389 сервера myserver.local.
- Правило срабатывает, и вы начинаете разбирать потенциальный инцидент с высоким приоритетом.
В процессе расследования вы быстро выясняете, что на myserver.local 3389 закрыт и никогда не открывался никаким сервисом и там стоит Linux. Это ложное срабатывание правила, отнявшее у вас время на расследование.
Другой пример: IPS присылает событие о срабатывании сигнатуры по попытке эксплуатации уязвимости CVE-2017-0144, однако в процессе расследования выясняется, что на атакуемой машине установлен соответствующий патч и на такой инцидент нет необходимости реагировать с наивысшим приоритетом.
Использование данных из модели АС помогут нивелировать эту проблему.
Шаг 13: Использовать идентификаторы сущностей, а не их исходные ключи. Как уже было описано в статье «Модель системы как контекст правил корреляции» IP-адрес, FQDN и даже MAC актива может меняться. Таким образом, если использовать в правиле корреляции или табличном списке исходные идентификаторы актива, то высок шанс через некоторое время получить ложные срабатывания по вполне банальной причине, к примеру DHCP-сервер просто выдал данный IP другой машине.
Если ваш SIEM имеет механизм идентификации активов, отслеживания их изменений и позволяет оперировать их идентификаторами, следует использовать именно идентификаторы, а не исходные ключи актива.
Формирование соглашения о срабатываниях
Подходя к заключительному блоку создания правила корреляции, напомним, что результатом работы правила является инцидент, заведенный в SIEM. На такой инцидент должны реагировать ответственные специалисты. Хотя в цели данного цикла статей и не входит рассмотрение процесса реагирования на инциденты, следует отметить, что часть информации по инциденту формируется уже на этапе создания соответствующего правила корреляции.
Далее рассмотрим базовые моменты, которые необходимо учесть при настройке параметров срабатывания правила корреляции и порождении инцидента.
Формирование соглашения о срабатываниях
Шаг 14: Определить условия агрегации и отключения в случае большого числа ложных срабатываний. На этапе отладки, да и в процессе своего функционирования, если не придерживаться данной методики :), могут происходить ложные срабатывания правил. Хорошо, если таких один или два срабатывания за день, но что делать, если у одного правила тысячи или десятки тысяч срабатываний? Конечно, это говорит о том, что правило необходимо дорабатывать. Однако необходимо сделать так, чтобы в подобных ситуациях такое массовое ложное срабатывание:
- Не оказывало влияние на работоспособность SIEM.
- Среди массы ложных срабатываний не затерялись действительно важные инциденты. Существует даже отдельный тип атак, направленный на сокрытие основной зловредной активности за множеством ложных активностей.
Проблемы такого рода могут быть решены, если при создании правила корреляции на уровне всей системы в целом или для каждого правила в отдельности задать условия агрегации инцидентов и условия аварийного отключения правила.
Механизм агрегации инцидентов позволит не создавать миллионы одинаковых инцидентов, а «подклеивать» новые инциденты к одному, при условии их идентичности. В крайних случаях, когда даже агрегация инцидентов дает значительную нагрузку, рекомендуется настроить автоматическое отключение правила корреляции при превышении заданного количества срабатываний в единицу времени (минута, час, сутки).
Шаг 15: Определить правила формирования названия инцидента. Этим пунктом часто пренебрегают, особенно если разрабатывают правила не для своей компании, например, если за внедрение SIEM и разработку правил отвечает сторонняя компания. Имя правила корреляции, а также порожденного им инцидента должно быть коротким и четко отражать суть конкретного правила.
Если в вашей компании с инцидентами и правилами корреляции работает не один человек, рекомендуется разработать правила именования. Они должны быть понятны и приняты всей командой, работающей с SIEM.
Шаг 16: Определить правила формирования важности инцидента. Большинство SIEM-решений на последнем этапе создания инцидента позволяют задать его важность и значимость. Часть решений даже вычисляет важность автоматически, исходя из контекста инцидента и участвующих в нем объектов.
В случае, если в вашем SIEM работает исключительно автоматическое вычисление важности инцидентов, стоит разобраться на основании чего и по какой формуле она рассчитывается. К примеру, если важность рассчитывается на основе значимости активов, участвующих в инциденте, необходимо заранее серьезно подойти к вопросам управления активами (Asset Management) в компании.
Если вы задаете важность инцидента вручную, рекомендуется выработать формулу расчета, учитывающую как минимум следующее:
- Важность той области действия, в которой работает правило. Например, инцидент в зоне Mission critical систем может быть более критичен, по сравнению с тем, если бы точно такой же инцидент произошел в зоне Business important систем.
- Важность активов и учетных записей пользователей, участвующих в инциденте.
- Повторяемость данного инцидента в компании.
Также, как и в именовании инцидентов, важно, чтобы все заинтересованные лица четко и одинаково понимали, по каким правилам формируется важность инцидента.
name="Conclusions">
Выводы
Подводя итоги нашего цикла статей, отмечу, что создать правила корреляции, работающих «из коробки», на мой взгляд, возможно. Выходом может стать сплав организационных и технических подходов. Что-то должен уметь сам SIEM, а что-то должны выполнять и знать эксплуатирующие его специалисты.
Подытожим:
- Метод состоит из следующих блоков:
- Подготовка источников и окружения.
- Нормализация событий и их обогащение.
- Адаптация правил корреляции к контексту АС.
- Формирование соглашения о срабатываниях.
- Каждый блок имеет организационную и техническую составляющие.
- С технической точки зрения, описанные блоки затрагивают практический все базовые функции SIEM, начиная от сбора событий и заканчивая порождением инцидента.
- Практически вся техническая составляющая данной методологии, может быть обеспечена существующими зарубежными, а также некоторыми отечественными SIEM-решениями.
- Более детальное рассмотрение и обоснование шагов данной методологии было приведено в предыдущих статьях цикла. Ссылки на них приведены в конце статьи.
name="Schema">
Методология разработки правил корреляции, работающих «из коробки»
Большое спасибо всем, кто осилил весь цикл статей, или хотя бы дочитал до этих строк. Если у вас возникнут вопросы — пишите в личку или задавайте их в комментариях. Буду рад обсудить.
name="Articles">
Цикл статей:
Глубины SIEM: корреляции «из коробки». Часть 1: Чистый маркетинг или нерешаемая проблема?
Глубины SIEM: корреляции «из коробки». Часть 2. Схема данных как отражение модели «мира»
Глубины SIEM: корреляции «из коробки». Часть 3.1. Категоризация событий
Глубины SIEM: корреляции «из коробки». Часть 3.2. Методология нормализации событий
Глубины SIEM: корреляции «из коробки». Часть 4. Модель системы как контекст правил корреляции
Глубины SIEM: корреляции «из коробки». Часть 5. Методология разработки правил корреляции (Данная статья)

