
На одном из мероприятий завязалась у меня интересная дискуссия на тему полезности решений класса NTA (Network Traffic Analysis), которые по полученной с сетевой инфраструктуры телеметрии Netflow (или иных flow-протоколов) позволяет выявлять широкий спектр атак. Мои оппоненты утверждали, что при анализе заголовков и сопутствующей информации (а NTA не занимается анализом тела данных пакетов в отличие от классических систем обнаружения атак, IDS) нельзя увидеть многое. В данной статьей я попробую опровергнуть это мнение и чтобы разговор был более предметным, приведу несколько реальных примеров, когда NTA действительно помогает выявлять различные аномалии и угрозы, пропущенные на периметре или вообще минувшие периметр. А начну я с угрозы, которая вышла на первые места в рейтинге угроз прошлого года и, думаю, останется таковой в этом году. Речь пойдет об утечках информации и возможности их обнаруживать по сетевой телеметрии.
Я не буду рассматривать ситуацию с кривыми руками админов, оставивших смотрящие в Интернет незащищенные Elastic или MongoDB. Поговорим о целенаправленных действия злоумышленников, как это было в нашумевшей истории с бюро кредитных историй Equifax. Напомню, что в этом кейсе злоумышленники сначала проникли через непатченную уязвимость на публичный Web-портал, а затем уже и на внутренние сервера баз данных. Оставаясь в течение нескольких месяцев незамеченными они смогли украсть данные по 146 миллионам клиентов бюро кредитных историй. Можно ли было выявить такой инцидент с помощью DLP-решений? Скорее всего нет, так как классические DLP не заточены под задачу мониторинга трафика из баз данных по специфическим протоколам, да еще и прии условии, что этот трафик зашифрованный. А вот решение класса NTA может достаточно легко выявить такого рода утечки по превышению некоего порогового значения объема скачиваемой с базы данных информации. Дальше я покажу как это все настраивается и обнаруживается с помощью решения Cisco Stealthwatch Enterprise.
Итак, первое что мы должны сделать, это понять, где у нас в сети находятся сервера баз данных, определить их адреса и сгруппировать их. В Cisco Stealthwatch задачу инвентаризации можно осуществлять как вручную, так и с помощью специального классификатора, который анализирует трафик и по используемым протоколам и поведению узла позволяет отнести его к той или иной категории.
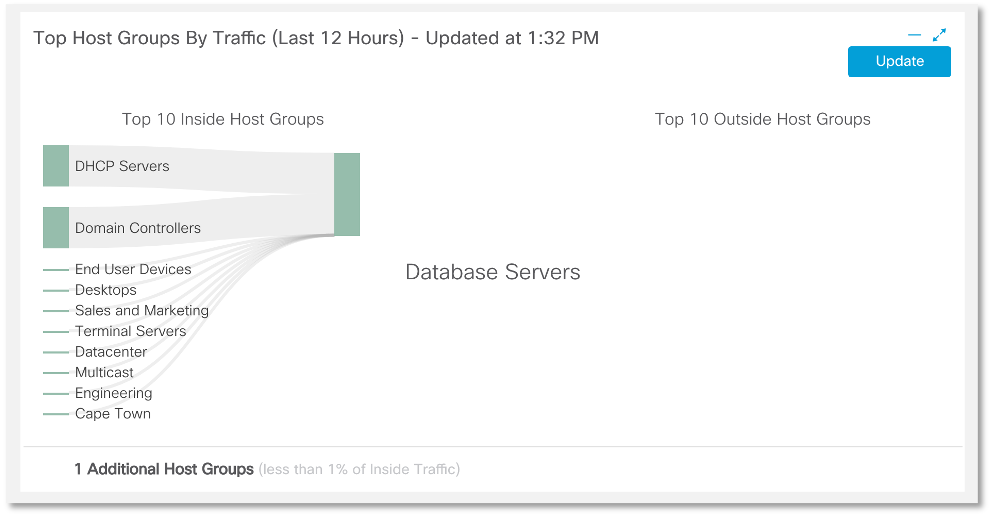
После того, как мы имеем информацию обо всех серверах баз данных, мы начинаем расследование с целью выяснить, не осуществляется ли у нас утечка больших объемов данных с нужной группы узлов. Мы видим, что в нашем случае БД наиболее активно общаются с DHCP-серверами и контроллерами доменов.
Злоумышленники часто устанавливают контроль над каким-либо из узлов сети и используют его в качестве плацдарма для развития своей атаки. На уровне сетевого трафика это выглядит как аномалия — учащается сканирование сети с этого узла, осуществляется захват данных с файловых шар или взаимодействие с какими-либо серверами. Поэтому наша следующая задача понять, с кем конкретно чаще всего общаются наши базы данных.
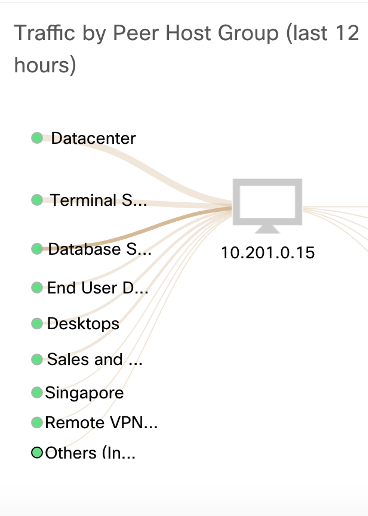
В группе DHCP-серверов оказывается, что это узел с адресом 10.201.0.15, на взаимодействие с которым приходится около 50% всего трафика от серверов баз данных.

Следующий логичный вопрос, который мы себе задаем в рамках расследования: “А что это за узел такой 10.201.0.15? С кем он взаимодействует? Как часто? По каким протоколам?”
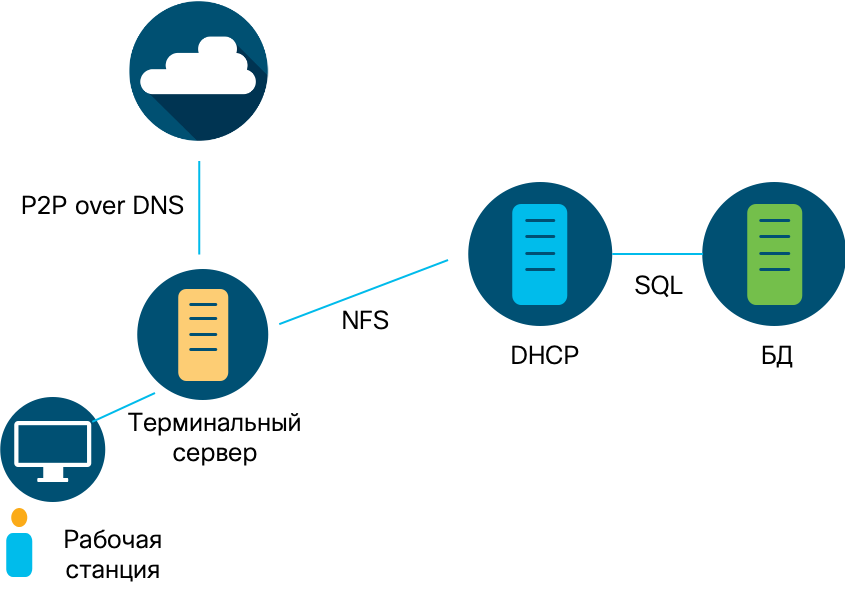
Выясняется, что интересующий нас узел общается с различными сегментами и узлами нашей сети (что немудрено, раз это DHCP-сервер), но при этом вопрос вызывает излишне активное взаимодействие с терминальным сервером с адресом 10.201.0.23. Нормально ли это? Налицо явно какая-то аномалия. Не может DHCP-сервер столь активно общаться с терминальным сервером — 5610 потоков и 23,5 ГБ данных.
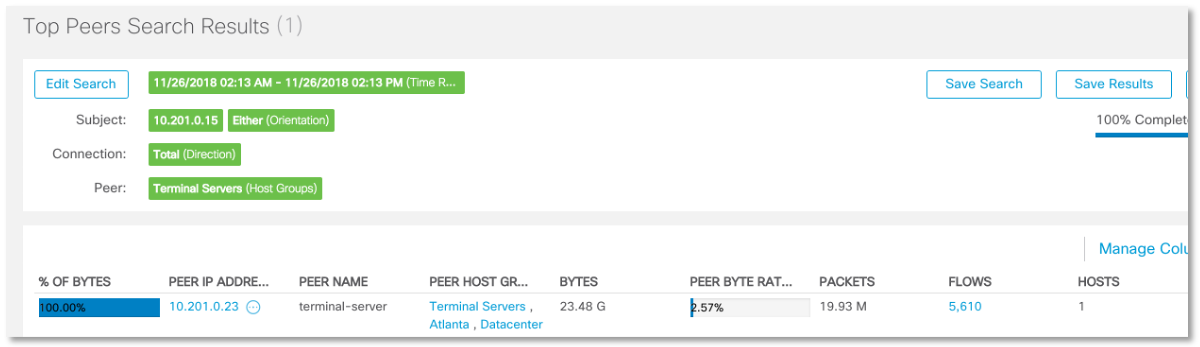
И взаимодействие это осуществляется через NFS.

Делаем следующий шаг и пытаемся понять, с кем взаимодействует наш терминальный сервер? Оказывается, что у него достаточно активное общение идет с внешним миром — с узлами в США, Великобритании, Канаде, Дании, ОАЭ, Катаре, Швейцарии и т.п.
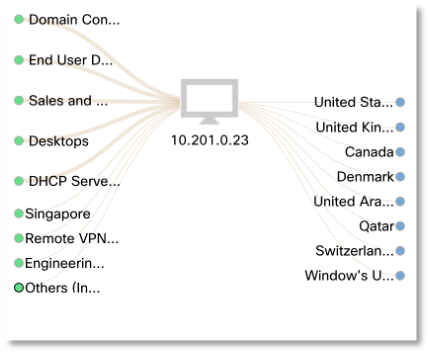
Подозрение вызвал факт P2P-взаимодействия с Пуэрто-Рико, на которое пришлось 90% всего трафика. Причем наш терминальный сервер передал более 17 ГБ данных в Пуэрто-Рико по 53-му порту, который у нас связан с протоколом DNS. Вы можете себе представить, чтобы у вас такой объем данных передавался по DNS? А я напомню, что согласно исследованиям Cisco, 92% вредоносных программ используют именно DNS для скрытия своей активности (загрузки обновлений, получения команд, слива данных).

И если на МСЭ DNS-протокол не просто открыт, но и не инспектируется, то мы имеем огромную дыру в нашем периметре.

Коль скоро узел 10.201.0.23 вызвал у нас такие подозрения, то давайте посмотрим с кем он еще общается?
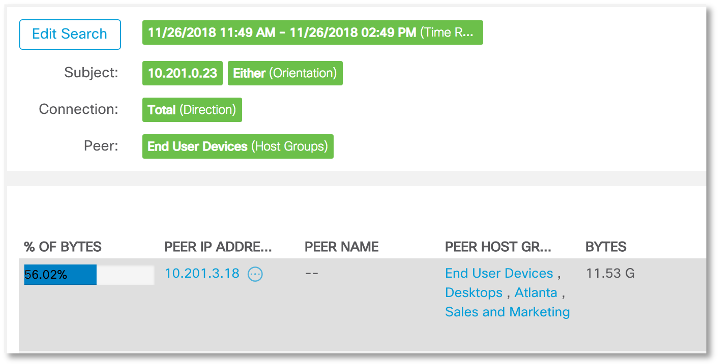
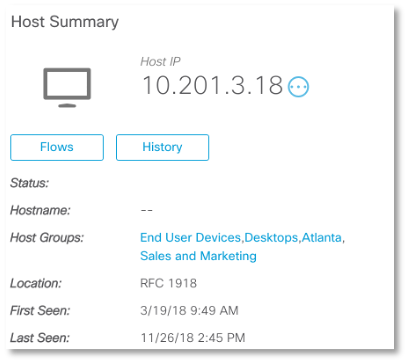
Половиной всего трафика наш “подозреваемый” обменивается с узлом 10.201.3.18, который помещен в группу рабочих станций сотрудников отдела продаж и маркетинга. Насколько эти типично для нашей организации, чтобы терминальный сервер “общался” с компьютером продавца или маркетолога?
Итак, мы провели расследование и выяснили следующую картину. Данные с сервера баз данных “сливались” на DHCP-сервер с последующей их передачей по NFS на терминальный сервер внутри нашей сети, а затем на внешние адреса в Пуэрто-Рико по протоколу DNS. Это явное нарушение политик безопасности. При этом терминальный сервер также взаимодействовал с одной из рабочих станций внутри сети. Что послужило причиной этого инцидента? Украденная учетная запись? Инфицированное устройство? Мы не знаем. Это потребует продолжения расследования, основу которого заложило решение класса NTA, позволяющее анализировать аномалии сетевого траффика.
А нас сейчас интересует, что мы будем делать с выявленными нарушениями политики безопасности? Можно регулярно проводить анализ согласно приведенной выше схемы, а можно настроить политику NTA таким образом, чтобы он сразу сигнализировал при обнаружении схожих нарушений. Делается это либо через соответствующее общее меню, либо для каждого выявленного в процессе расследования соединения.
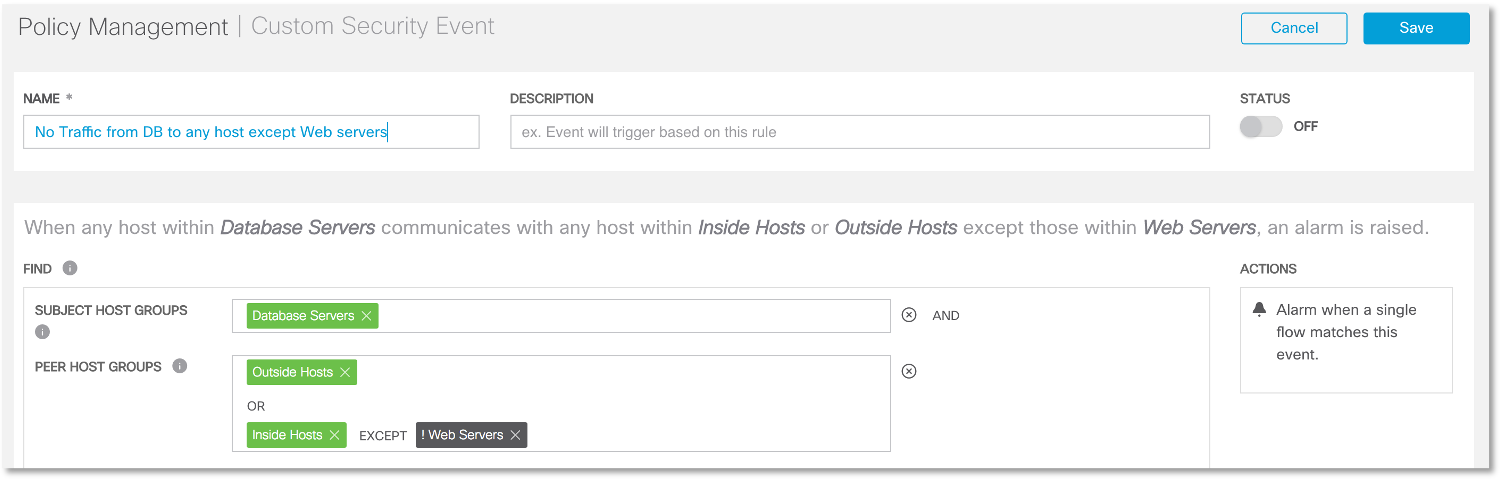
Вот как будет выглядеть правило обнаружения взаимодействия, источником которого являются сервера баз данных, а пунктом назначения любые внешние узлы, а также любые внутренние, исключая Web-сервера.
В случае обнаружения такого события система анализа сетевого трафика сразу генерит соответствий сигнал тревоги и, в зависимости от настроек, отправляет его в SIEM, с помощью средств коммуникаций администратору, или может даже автоматически блокировать выявленное нарушение (Cisco Stealthwatch это делает за счет взаимодействия с Cisco ISE).

Вспомним, когда я упоминал кейс с Equifax, то упомянул, что злоумышленники использовали зашифрованный канал для слива данных. Для DLP такой трафик становится неразрешимой задачей, а для решений класса NTA нет — они отслеживают любое превышение трафика или неразрешенное взаимодействие между узлами, независимо от использования шифрования.

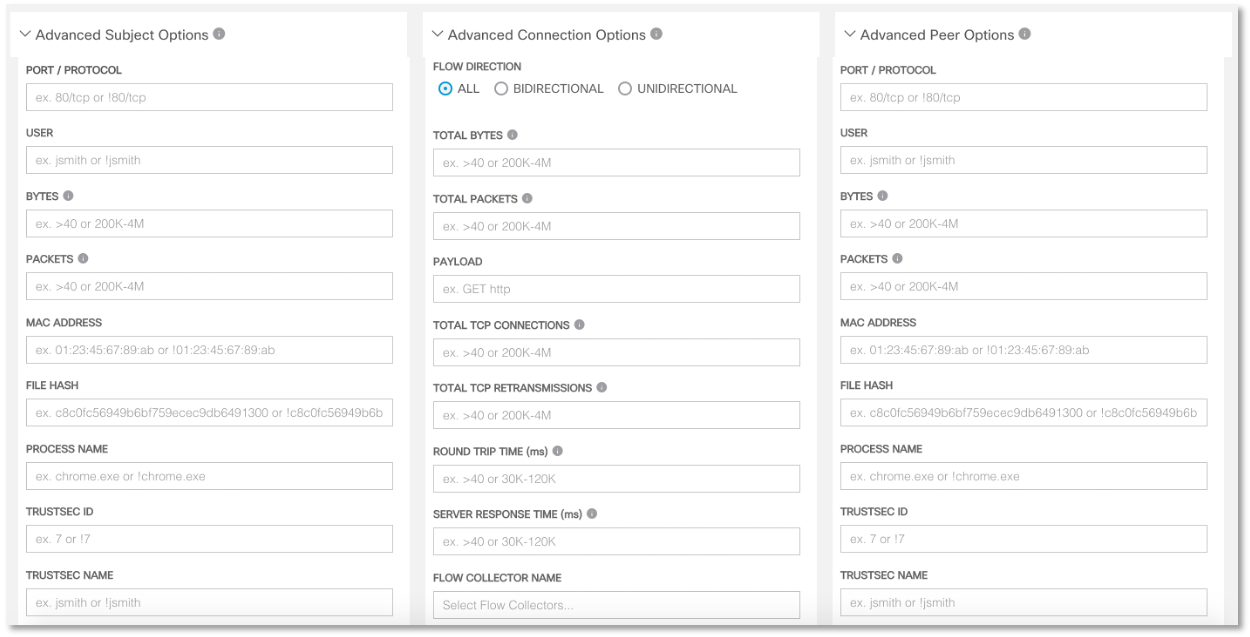
Выше был показан только один кейс (в следующих материалах мы рассмотрим другие примеры использования NTA в целях ИБ), но на самом деле современные решения класса Network Traffic Analysis позволяют вам создавать очень гибкие правила и учитывать не только базовые параметры заголовка IP-пакета:
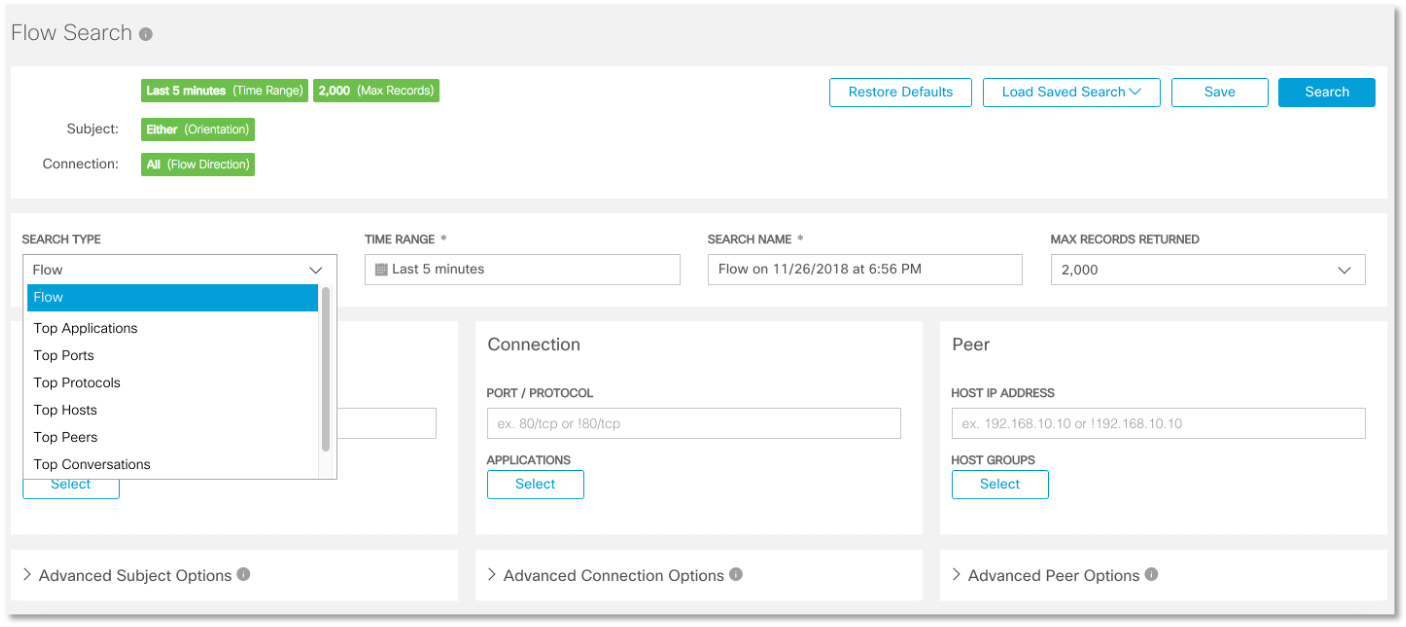
но и проводить более глубокий анализ, вплоть до привязки инцидента к имени пользователя из Active Directory, поиска вредоносных файлов по хэшу (например, полученному в виде индикатора компрометации от ГосСОПКА, ФинЦЕРТ, Cisco Threat Grid и т.п.) и т.п.
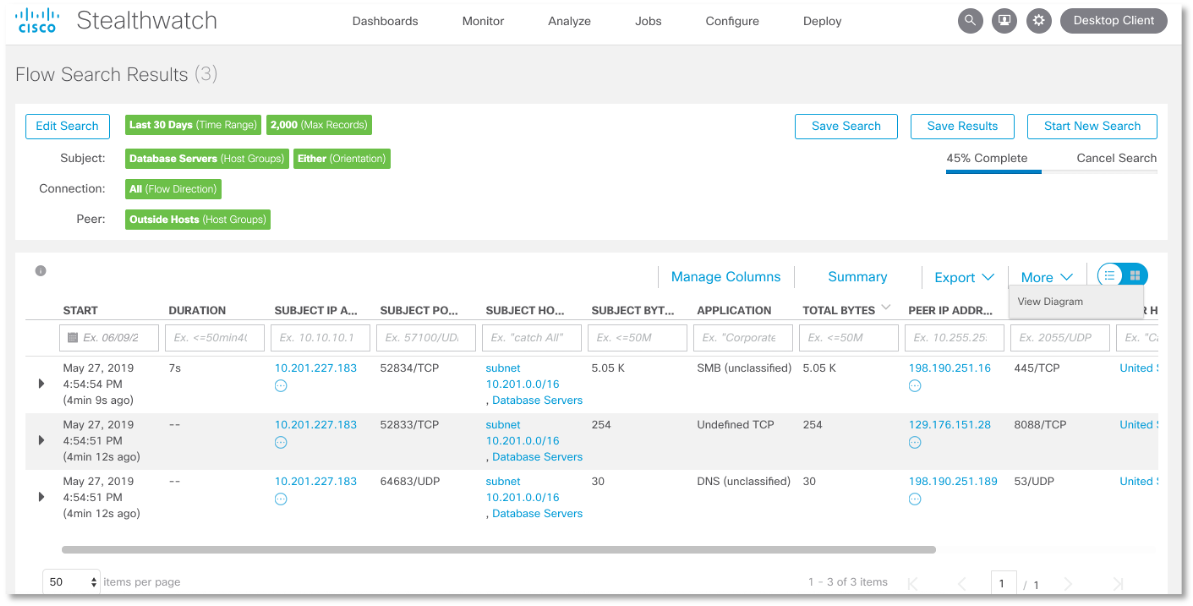
Реализуется это несложно. Например, вот так выглядит обычное правило для обнаружения всех видов взаимодействия серверов баз данных с внешними узлами по любому протоколу за последние 30 дней. Мы видим, что наши базы данных «общались» с внешними по отношению к сегменту СУБД узлами по протоколам DNS, SMB и порту 8088.
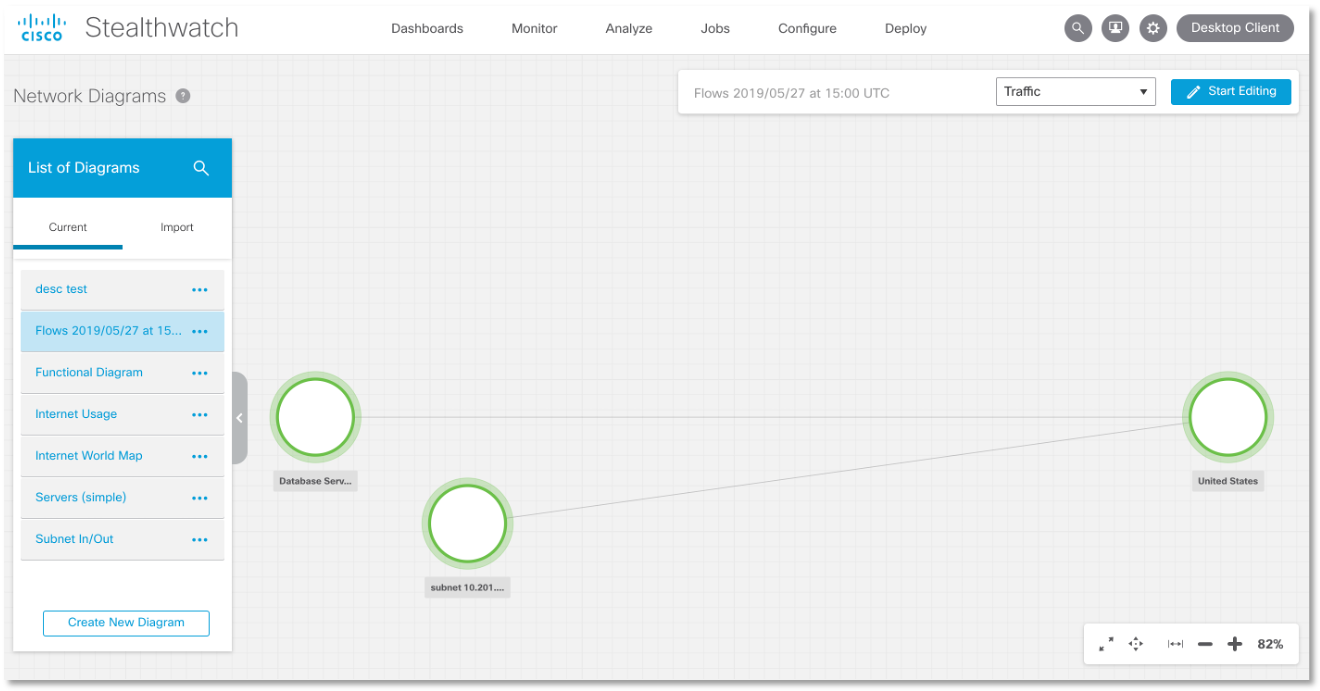
Помимо табличной формы представления результатов расследования или поиска, мы можем и визуализировать их. Для нашего сценария фрагмент схемы сетевых потоков может выглядеть так:
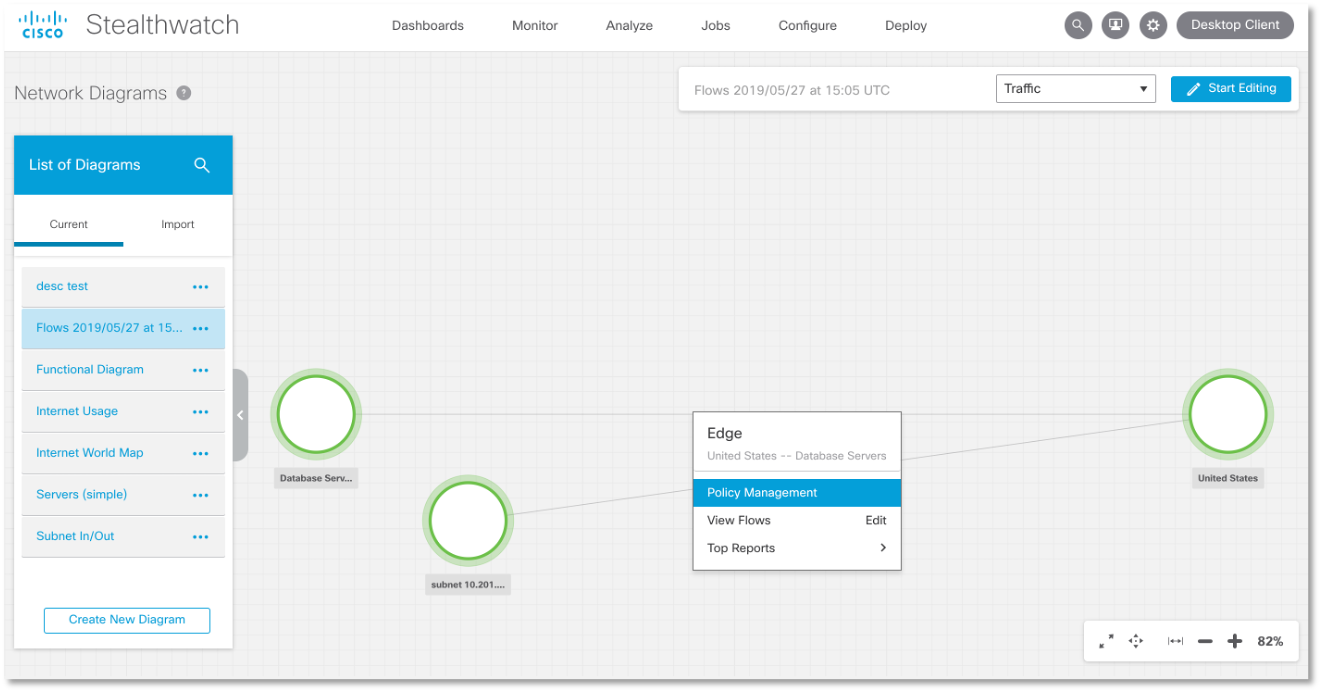
И сразу из этой же карты мы можем управлять политиками — блокировать соединения или автоматизировать процесс создания правил мониторинга для интересующих нас потоков.
Вот такой, достаточно интересный и живой пример использования инструментов по мониторингу Netflow (и иных flow-протоколов) для целей кибербезопасности. В следующих заметках я планирую показать, как можно использовать NTA для обнаружения вредоносного кода (на примере Shamoon), вредоносных серверов (на примере кампании DNSpionage), программ удаленного доступа (RAT), обхода корпоративных прокси и т.п.
Я не буду рассматривать ситуацию с кривыми руками админов, оставивших смотрящие в Интернет незащищенные Elastic или MongoDB. Поговорим о целенаправленных действия злоумышленников, как это было в нашумевшей истории с бюро кредитных историй Equifax. Напомню, что в этом кейсе злоумышленники сначала проникли через непатченную уязвимость на публичный Web-портал, а затем уже и на внутренние сервера баз данных. Оставаясь в течение нескольких месяцев незамеченными они смогли украсть данные по 146 миллионам клиентов бюро кредитных историй. Можно ли было выявить такой инцидент с помощью DLP-решений? Скорее всего нет, так как классические DLP не заточены под задачу мониторинга трафика из баз данных по специфическим протоколам, да еще и прии условии, что этот трафик зашифрованный. А вот решение класса NTA может достаточно легко выявить такого рода утечки по превышению некоего порогового значения объема скачиваемой с базы данных информации. Дальше я покажу как это все настраивается и обнаруживается с помощью решения Cisco Stealthwatch Enterprise.
Итак, первое что мы должны сделать, это понять, где у нас в сети находятся сервера баз данных, определить их адреса и сгруппировать их. В Cisco Stealthwatch задачу инвентаризации можно осуществлять как вручную, так и с помощью специального классификатора, который анализирует трафик и по используемым протоколам и поведению узла позволяет отнести его к той или иной категории.
После того, как мы имеем информацию обо всех серверах баз данных, мы начинаем расследование с целью выяснить, не осуществляется ли у нас утечка больших объемов данных с нужной группы узлов. Мы видим, что в нашем случае БД наиболее активно общаются с DHCP-серверами и контроллерами доменов.
Злоумышленники часто устанавливают контроль над каким-либо из узлов сети и используют его в качестве плацдарма для развития своей атаки. На уровне сетевого трафика это выглядит как аномалия — учащается сканирование сети с этого узла, осуществляется захват данных с файловых шар или взаимодействие с какими-либо серверами. Поэтому наша следующая задача понять, с кем конкретно чаще всего общаются наши базы данных.
В группе DHCP-серверов оказывается, что это узел с адресом 10.201.0.15, на взаимодействие с которым приходится около 50% всего трафика от серверов баз данных.
Следующий логичный вопрос, который мы себе задаем в рамках расследования: “А что это за узел такой 10.201.0.15? С кем он взаимодействует? Как часто? По каким протоколам?”
Выясняется, что интересующий нас узел общается с различными сегментами и узлами нашей сети (что немудрено, раз это DHCP-сервер), но при этом вопрос вызывает излишне активное взаимодействие с терминальным сервером с адресом 10.201.0.23. Нормально ли это? Налицо явно какая-то аномалия. Не может DHCP-сервер столь активно общаться с терминальным сервером — 5610 потоков и 23,5 ГБ данных.
И взаимодействие это осуществляется через NFS.
Делаем следующий шаг и пытаемся понять, с кем взаимодействует наш терминальный сервер? Оказывается, что у него достаточно активное общение идет с внешним миром — с узлами в США, Великобритании, Канаде, Дании, ОАЭ, Катаре, Швейцарии и т.п.
Подозрение вызвал факт P2P-взаимодействия с Пуэрто-Рико, на которое пришлось 90% всего трафика. Причем наш терминальный сервер передал более 17 ГБ данных в Пуэрто-Рико по 53-му порту, который у нас связан с протоколом DNS. Вы можете себе представить, чтобы у вас такой объем данных передавался по DNS? А я напомню, что согласно исследованиям Cisco, 92% вредоносных программ используют именно DNS для скрытия своей активности (загрузки обновлений, получения команд, слива данных).
И если на МСЭ DNS-протокол не просто открыт, но и не инспектируется, то мы имеем огромную дыру в нашем периметре.
Коль скоро узел 10.201.0.23 вызвал у нас такие подозрения, то давайте посмотрим с кем он еще общается?
Половиной всего трафика наш “подозреваемый” обменивается с узлом 10.201.3.18, который помещен в группу рабочих станций сотрудников отдела продаж и маркетинга. Насколько эти типично для нашей организации, чтобы терминальный сервер “общался” с компьютером продавца или маркетолога?
Итак, мы провели расследование и выяснили следующую картину. Данные с сервера баз данных “сливались” на DHCP-сервер с последующей их передачей по NFS на терминальный сервер внутри нашей сети, а затем на внешние адреса в Пуэрто-Рико по протоколу DNS. Это явное нарушение политик безопасности. При этом терминальный сервер также взаимодействовал с одной из рабочих станций внутри сети. Что послужило причиной этого инцидента? Украденная учетная запись? Инфицированное устройство? Мы не знаем. Это потребует продолжения расследования, основу которого заложило решение класса NTA, позволяющее анализировать аномалии сетевого траффика.
А нас сейчас интересует, что мы будем делать с выявленными нарушениями политики безопасности? Можно регулярно проводить анализ согласно приведенной выше схемы, а можно настроить политику NTA таким образом, чтобы он сразу сигнализировал при обнаружении схожих нарушений. Делается это либо через соответствующее общее меню, либо для каждого выявленного в процессе расследования соединения.
Вот как будет выглядеть правило обнаружения взаимодействия, источником которого являются сервера баз данных, а пунктом назначения любые внешние узлы, а также любые внутренние, исключая Web-сервера.
В случае обнаружения такого события система анализа сетевого трафика сразу генерит соответствий сигнал тревоги и, в зависимости от настроек, отправляет его в SIEM, с помощью средств коммуникаций администратору, или может даже автоматически блокировать выявленное нарушение (Cisco Stealthwatch это делает за счет взаимодействия с Cisco ISE).
Вспомним, когда я упоминал кейс с Equifax, то упомянул, что злоумышленники использовали зашифрованный канал для слива данных. Для DLP такой трафик становится неразрешимой задачей, а для решений класса NTA нет — они отслеживают любое превышение трафика или неразрешенное взаимодействие между узлами, независимо от использования шифрования.
Выше был показан только один кейс (в следующих материалах мы рассмотрим другие примеры использования NTA в целях ИБ), но на самом деле современные решения класса Network Traffic Analysis позволяют вам создавать очень гибкие правила и учитывать не только базовые параметры заголовка IP-пакета:
но и проводить более глубокий анализ, вплоть до привязки инцидента к имени пользователя из Active Directory, поиска вредоносных файлов по хэшу (например, полученному в виде индикатора компрометации от ГосСОПКА, ФинЦЕРТ, Cisco Threat Grid и т.п.) и т.п.
Реализуется это несложно. Например, вот так выглядит обычное правило для обнаружения всех видов взаимодействия серверов баз данных с внешними узлами по любому протоколу за последние 30 дней. Мы видим, что наши базы данных «общались» с внешними по отношению к сегменту СУБД узлами по протоколам DNS, SMB и порту 8088.
Помимо табличной формы представления результатов расследования или поиска, мы можем и визуализировать их. Для нашего сценария фрагмент схемы сетевых потоков может выглядеть так:
И сразу из этой же карты мы можем управлять политиками — блокировать соединения или автоматизировать процесс создания правил мониторинга для интересующих нас потоков.
Вот такой, достаточно интересный и живой пример использования инструментов по мониторингу Netflow (и иных flow-протоколов) для целей кибербезопасности. В следующих заметках я планирую показать, как можно использовать NTA для обнаружения вредоносного кода (на примере Shamoon), вредоносных серверов (на примере кампании DNSpionage), программ удаленного доступа (RAT), обхода корпоративных прокси и т.п.

