

В апреле 2026 года рынок больших языковых моделей получил редкий сюжет без натяжки. 16 апреля Anthropic выпустила Claude Opus 4.7. Через неделю, 23 апреля, OpenAI ответила GPT-5.5. Две лаборатории, две старшие модели, одна неделя между анонсами. Для отрасли, где каждый новый выпуск обычно пытаются продать как «исторический», на этот раз историчность не пришлось натягивать на пресс-релиз.
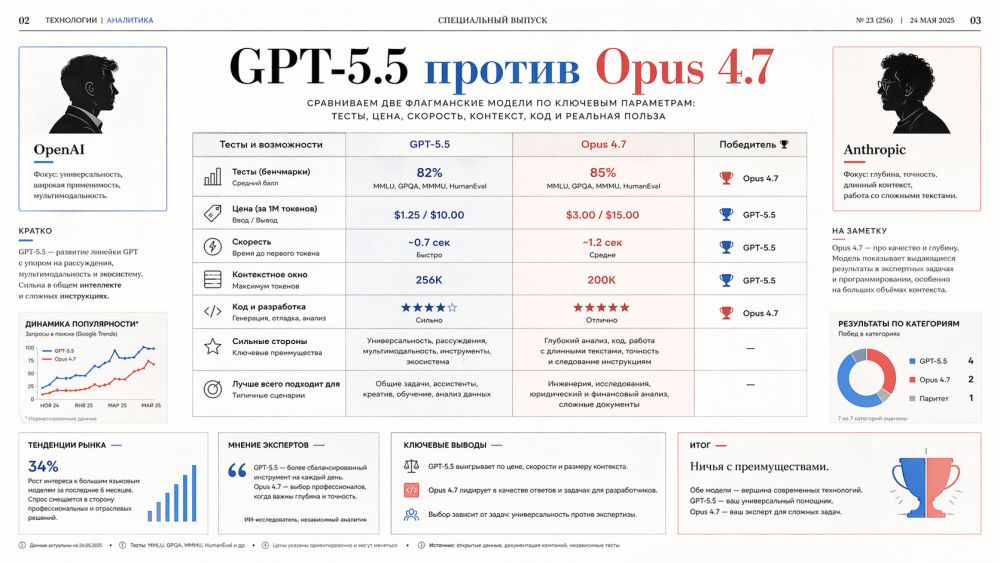
Сравнение получилось неприятным для всех, кто любит простые ответы. GPT-5.5 заметно сильнее в задачах, где модель должна действовать как исполнитель: держать план, пользоваться инструментами, управлять средой, не бросать работу на середине. Claude Opus 4.7 выглядит убедительнее там, где нужна аккуратная инженерная работа, строгое следование инструкции и спокойная честность вместо уверенного сочинительства. Победитель есть, но только если заранее назвать задачу.
Главный вывод звучит скучно, зато полезно: эпоха «одной лучшей модели на всё» закончилась. Дальше компании будут собирать наборы из нескольких моделей, а не спорить о единственной короне. GPT-5.5 и Opus 4.7 хороши не одинаково. В этом и начинается настоящая интрига.
Что вообще произошло за эти семь дней
Claude Opus 4.7 вышел для Anthropic не просто как очередное улучшение. Компания несколько месяцев жила под раздражённый шум разработчиков, которые жаловались на деградацию прежних версий Claude. Пользователи говорили, что модель стала осторожнее, чаще теряет нить в длинных задачах и хуже держит сложную инженерную работу. Anthropic отрицала намеренное ослабление модели, но сам фон был неприятный: когда разработчики перестают доверять инструменту, красивые графики уже не лечат репутацию.
Opus 4.7 стал ответом на эту боль. В официальном описании Anthropic делает упор на сложные задачи по коду, долгие рабочие циклы, более строгие инструкции, улучшенное зрение и способность проверять собственные действия перед финальным ответом. Модель получила поддержку изображений до 2576 пикселей по длинной стороне, то есть примерно до 3,75 мегапикселя. Для чтения плотных схем, скриншотов интерфейсов, таблиц и диаграмм такой рост важнее, чем очередная красивая формулировка про «интеллект».
OpenAI вышла через неделю с другим тезисом. GPT-5.5 в анонсе описывают как модель для «реальной работы за компьютером»: код, исследование, анализ данных, документы, таблицы, программы и переход между инструментами до завершения задачи. Меньше ручного сопровождения, больше самостоятельного движения. Если Opus 4.7 обещает быть очень сильным инженером, то GPT-5.5 пытается стать сотрудником, которому можно поручить запутанный кусок работы и не стоять над душой.
| Параметр | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Дата выпуска | 23 апреля 2026 года | 16 апреля 2026 года |
| Главная ставка | Агентная работа, управление инструментами, сложные многошаговые задачи | Код, строгие инструкции, проверка собственных выводов, работа с изображениями |
| Цена входящих токенов | $5 за миллион | $5 за миллион |
| Цена выходящих токенов | $30 за миллион | $25 за миллион |
| Контекст | До 1 миллиона токенов | До 1 миллиона токенов |
| Главный риск для бюджета | Высокая цена выходящих токенов, особенно у версии Pro | Новый разбор текста на токены может увеличить фактический расход |
GPT-5.5: модель, которая хочет работать, а не отвечать
Самая сильная часть GPT-5.5 не в том, что модель лучше пишет объяснения или аккуратнее держит стиль. Главная заявка OpenAI лежит в другом месте. Модель должна брать плохо оформленную задачу, сама уточнять план через действия, пользоваться инструментами, проверять промежуточный результат и доводить работу до конца. Не «вот вам совет», а «вот готовый набор изменений, отчёт, таблица, проверка и следующий шаг».
Поэтому GPT-5.5 особенно интересно смотреть не как чат-бот, а как исполнитель в среде. В Codex модель, по данным OpenAI, лучше справляется с внедрением изменений, переработкой кода, поиском ошибок, проверками и переносом правок через несколько частей проекта. Ранние тестировщики описывали ровно этот сдвиг: GPT-5.5 дольше держит задачу, меньше останавливается раньше времени и лучше предугадывает, какие проверки понадобятся перед сдачей работы.
Здесь важна не только «умность», но и выносливость. Много моделей красиво стартуют: пишут план, создают первые файлы, бодро объясняют ход мысли. Проблемы начинаются на двадцатой минуте, когда надо связать изменения, исправить побочный сбой, повторно прогнать проверку и не забыть исходную цель. GPT-5.5 бьёт именно в эту зону. Для бизнеса такая способность дороже красивого ответа на один сложный вопрос.
Opus 4.7: реванш Anthropic в инженерной работе
Claude Opus 4.7 выглядит менее зрелищно, если ждать от модели образа универсального цифрового сотрудника. Зато Anthropic явно целилась в разработчиков, аналитиков и команды, которые уже используют Claude в серьёзной работе и устали от маленьких, но дорогих провалов. Модель стала точнее следовать инструкциям, лучше ловит противоречия и чаще говорит, что данных не хватает, вместо того чтобы подставлять правдоподобную выдумку.
Для инженерной работы такое поведение критично. Плохая модель не всегда та, которая ошиблась. Намного опаснее модель, которая ошиблась уверенно, красиво завернула ошибку в пояснение и заставила человека поверить. В этом смысле похвала Opus 4.7 от ранних пользователей звучит практично: меньше лишних обёрток в коде, меньше бессмысленных запасных веток, больше проверки перед выполнением. Не вау-эффект на сцене, а меньше грязи в рабочем проекте.
Anthropic в анонсе отдельно подчёркивает, что Opus 4.7 сильнее прежней версии в долгих задачах, лучше использует файловую память и точнее работает с изображениями высокого разрешения. Компания также добавила уровни усилия и «бюджеты задач»: разработчик может задать предел расхода токенов на длинный цикл, а модель должна распределить ресурс между размышлением, вызовами инструментов и финальным ответом. Идея здравая: если не поставить лимит, старшие модели иногда рассуждают так, будто счёт оплачивает кто-то другой. Обычно так и есть, пока не приходит счёт.
Где сухие цифры ломают простую картину
Таблица тестов быстро охлаждает желание объявить одного победителя. GPT-5.5 уверенно забирает сценарии, где надо управлять средой, действовать через инструменты и выполнять длинные цепочки. Opus 4.7 сильнее смотрится в реальных задачах по коду из репозиториев и в рассуждениях без внешних инструментов. Разница не косметическая, но и не тотальная.
С тестами надо обращаться аккуратно. Лаборатории сами выбирают условия, режимы рассуждения, наборы задач и конкурентов для сравнения. Часть оценок идёт из внутренних испытаний, часть из публичных наборов, часть из независимых таблиц. Поэтому честнее читать цифры как карту специализаций, а не как спортивную таблицу чемпионата мира.
| Тест | Что проверяет | GPT-5.5 | Claude Opus 4.7 | Практический смысл |
|---|---|---|---|---|
| Terminal-Bench 2.0 | Работа в командной строке, планирование, инструменты | 82,7% | 69,4% | GPT-5.5 сильнее как исполнитель в технической среде |
| SWE-bench Pro | Реальные задачи из GitHub | 58,6% | 64,3% | Opus 4.7 лучше подходит для сложных задач по коду |
| OSWorld-Verified | Управление реальной компьютерной средой | 78,7% | 78,0% | Почти ничья, формально впереди GPT-5.5 |
| Humanity's Last Exam без инструментов | Сложные вопросы без внешней помощи | 41,4% | 46,9% | Opus 4.7 лучше рассуждает в закрытом режиме |
| FrontierMath Tier 4 | Очень сложная математика | 35,4% | 22,9% | GPT-5.5 заметно сильнее на тяжёлой математике |
| MCP Atlas | Организация работы с инструментами | 75,3% | 79,1% | Opus 4.7 лучше в части связки инструментов по этому тесту |
| MRCR v2, 512K-1M | Поиск и удержание сведений в огромном контексте | 74,0% | 32,2% | GPT-5.5 резко прибавил в длинном контексте |
Самый важный результат для GPT-5.5 - Terminal-Bench 2.0. 82,7% против 69,4% у Opus 4.7 показывают, что OpenAI действительно продвинулась в задачах, где модель не просто отвечает, а действует. Такой класс задач ближе к будущим рабочим агентам, чем привычная переписка в чате.
Самый неприятный для OpenAI результат - SWE-bench Pro. Там Opus 4.7 набирает 64,3% против 58,6% у GPT-5.5. Для разработчика этот тест звучит приземлённее многих академических наборов: исправить реальную задачу в реальном проекте, не потерять зависимости, не сломать соседние части. Если команда выбирает модель именно для тяжёлого кода, Opus 4.7 нельзя списывать даже после громкого выхода GPT-5.5.
Деньги: прайс-лист врёт не потому, что врёт
На первый взгляд Claude Opus 4.7 дешевле. Входящие токены у обеих моделей стоят одинаково, по $5 за миллион, а выходящие у Opus 4.7 стоят $25 против $30 у GPT-5.5. Разница 17% в пользу Anthropic. Для больших объёмов такой разрыв уже похож на финансовый аргумент, а не на мелочь в таблице.
Но цена за токен и цена готовой задачи - разные вещи. У Opus 4.7 появился новый способ разбирать текст на токены. Токен - это фрагмент текста, за который модель считает стоимость и объём работы. Anthropic прямо пишет, что один и тот же ввод может превращаться в 1,0-1,35 раза больше токенов в зависимости от типа данных. Для обычного текста прирост может быть почти незаметным, а для кода, таблиц, разметки и структурированных данных счёт способен вырасти уже ощутимо.
У GPT-5.5 обратная история. OpenAI подняла цену по сравнению с GPT-5.4, но одновременно утверждает, что модель тратит меньше токенов на выполнение тех же задач в Codex и чаще доходит до результата без повторных прогонов. Если дорогая модель экономит два лишних запуска и один час инженера, формальный прайс-лист перестаёт быть главным аргументом.
| Сценарий | Что смотреть в счёте | Кто выглядит выгоднее |
|---|---|---|
| Много коротких ответов | Цена выходящих токенов и лимиты подписки | Чаще Opus 4.7 |
| Долгий агентный цикл | Количество повторных запусков, обрывы, исправления | Чаще GPT-5.5 |
| Код и структурированные данные | Фактический рост числа токенов после перехода на Opus 4.7 | Нужно мерить на своём трафике |
| Задачи с дорогой ошибкой | Цена проверки человеком и стоимость неверного вывода | Зависит от предметной области |
| Поток дешёвых типовых задач | Нужна ли вообще старшая модель | Чаще ни одна из двух |
Самая взрослая стратегия выглядит так: не выбирать модель по цене в таблице, а прогнать свой набор задач через обе системы. Считать надо не стоимость миллиона токенов, а стоимость результата. Сколько запросов ушло на готовый ответ. Сколько раз человек исправлял модель. Сколько задач пришлось перезапускать. Сколько ошибок прошли дальше по цепочке. Без такой проверки спор о цене превращается в гадание по рекламным страницам.
Какую модель брать для кода
Для разработки ответ зависит от типа работы. Если нужно исправлять реальные задачи в больших репозиториях, аккуратно следовать правилам проекта, не плодить лишние абстракции и честно признавать нехватку данных, Claude Opus 4.7 выглядит сильным первым выбором. SWE-bench Pro подтверждает это цифрами, а отзывы ранних пользователей сходятся в одном: модель стала строже, тщательнее и меньше пытается «угодить» любой ценой.
Если нужно поручить модели длинную работу в среде, где надо ходить по файлам, запускать проверки, менять несколько частей проекта и держать общий план, GPT-5.5 выглядит опасно сильным кандидатом. Terminal-Bench 2.0 и заявления OpenAI про Codex указывают именно на такой профиль. Модель лучше подходит для задач, где важна не только точность отдельного исправления, но и способность тащить рабочий процесс до конца.
Поэтому для команды разработки разумная схема выглядит не как «выбрали одну модель и забыли», а как маршрутизация. Opus 4.7 - на сложный разбор кода, проверку архитектурных решений, поиск скрытых ошибок, строгие инструкции. GPT-5.5 - на длинные цепочки действий, массовые изменения, связку кода с документами, проверками и рабочими инструментами. Младшие модели - на черновики, простые объяснения и рутинные задачи, где старший флагман просто сжигает бюджет.
Где GPT-5.5 выглядит особенно сильной
GPT-5.5 выигрывает там, где задача плохо помещается в один запрос. Например, «разбери шесть месяцев заявок, найди повторяющиеся причины отказов, собери таблицу, предложи правила маршрутизации и проверь пограничные случаи». Старые модели часто хорошо выполняли первый кусок, затем начинали терять цель. GPT-5.5 создавали именно для таких цепочек.
OpenAI приводит показательный внутренний пример: финансовая команда использовала Codex с GPT-5.5 для проверки 24 771 налоговой формы K-1 на 71 637 страницах, убрав персональные данные из процесса. Работа ускорилась на две недели по сравнению с прошлым годом. Даже если относиться к корпоративным примерам с холодной головой, класс задачи понятен: большой объём документов, много шагов, нужна проверка, результат должен лечь в рабочий процесс.
Ещё одна сильная зона - длинный контекст. На MRCR v2 при диапазоне 512 тысяч - 1 миллион токенов GPT-5.5 получила 74,0% против 36,6% у GPT-5.4. Такой скачок важен для юридических архивов, внутренних баз знаний, больших переписок, длинных технических отчётов и исследовательских материалов. Но длинный контекст не отменяет проверку: модель может удерживать больше сведений, но человек всё равно должен понимать, какие выводы критичны.
Где Opus 4.7 может быть лучше
Opus 4.7 особенно интересен там, где модель должна быть не громкой, а надёжной. Разбор сложной задачи по коду, поиск логической ошибки, работа с противоречивыми данными, аккуратная проверка вывода, создание интерфейсов и документов с хорошей структурой - всё это лежит в зоне силы Anthropic. В тестах и отзывах снова и снова появляется одна мысль: Opus 4.7 меньше притворяется, что знает ответ.
Для аналитика или инженера такая черта дороже эффектного стиля. Когда модель сообщает «данных не хватает», работа замедляется на минуту, но система не получает фальшивый вывод. Когда модель подставляет правдоподобное значение, ошибка уходит в документ, код, расчёт или письмо клиенту. Потом ошибку ищут уже люди, обычно в плохом настроении.
Улучшенное зрение Opus 4.7 тоже не декоративная функция. Модель может читать более плотные изображения, а значит лучше работать со сложными скриншотами, диаграммами, интерфейсами, техническими схемами и документами, где важны мелкие элементы. Для задач компьютерного управления, проверки макетов и извлечения данных из визуальных материалов такой рост разрешения даёт практическую пользу.
Mythos Preview: третий игрок, которого нельзя просто игнорировать
Сравнение GPT-5.5 и Opus 4.7 осложняет третья модель Anthropic - Claude Mythos Preview. Широкого доступа к ней нет. По данным Axios, Anthropic прямо признаёт, что Opus 4.7 уступает Mythos по общей мощности, но держит более сильную модель в ограниченном доступе из-за рисков кибербезопасности.
Эта деталь меняет политический смысл гонки. OpenAI выводит GPT-5.5 на рынок и делает ставку на широкое распространение при усиленных ограничениях. Anthropic выпускает Opus 4.7 как публичный флагман, но сильнейший козырь оставляет за закрытой дверью. Для клиентов доступная модель важнее мифической сверхмодели, но для стратегической гонки вопрос остаётся открытым.
По данным VentureBeat, GPT-5.5 узко обходит Mythos Preview на Terminal-Bench 2.0: 82,7% против 82,0%. Зато на Humanity's Last Exam без инструментов Mythos Preview набирает 56,8%, тогда как Opus 4.7 получает 46,9%, а GPT-5.5 Pro - 43,1%. Получается странная картина: OpenAI сильнее в публичном агентном продукте, Anthropic, возможно, держит более мощную систему в запасе.
Безопасность стала частью продукта, а не сноской
Оба выпуска показывают новый порядок вещей. Сильную модель уже нельзя просто выкатить и сказать «пользуйтесь». Чем лучше система пишет код, ищет ошибки, управляет инструментами и рассуждает о биологии или химии, тем больше вопросов к доступу, фильтрам и проверке пользователей. Безопасность перестала быть скучным разделом в конце анонса. Теперь безопасность влияет на то, кто получит модель, в каком режиме и с какими ограничениями.
OpenAI пишет, что GPT-5.5 получила самые строгие на момент выпуска меры защиты компании, включая более жёсткие классификаторы для киберрисков. Компания заранее предупреждает, что часть пользователей может столкнуться с раздражающими отказами, пока ограничения будут настраивать. Признание неприятное, зато честное: чем сильнее модель, тем выше вероятность ложных срабатываний на границе легитимного исследования безопасности.
Anthropic использует Opus 4.7 как испытательный полигон для ограничителей, которые в будущем могут помочь выпустить модели класса Mythos шире. В Opus 4.7 встроены блокировки для запрещённых и высокорисковых киберсценариев, а специалисты по безопасности могут проходить отдельную проверку для расширенного доступа. Рынок постепенно приходит к модели «сильные возможности плюс проверенный доступ». Старый подход «один чат для всех задач» трещит под весом собственных возможностей.
Практический выбор без религиозной войны
Если нужна короткая рекомендация, то GPT-5.5 стоит первым делом пробовать для многошаговых задач, автоматизации рабочих процессов, анализа больших массивов документов, управления инструментами и задач, где модель должна дойти до результата почти как исполнитель. Особенно если команда уже живёт в экосистеме OpenAI и использует Codex, ChatGPT Business или Enterprise.
Claude Opus 4.7 стоит первым делом пробовать для сложного кода, строгого анализа, проверки противоречивых данных, работы с большими проектами и сценариев, где уверенная ошибка стоит дороже медленного ответа. Особенно если команда уже использует Claude Code, ценит буквальное следование инструкциям и хочет меньше «красивых догадок».
| Задача | Лучший первый кандидат | Почему |
|---|---|---|
| Долгая автоматизация с несколькими инструментами | GPT-5.5 | Сильнее в агентных сценариях и работе с компьютерной средой |
| Сложное исправление в репозитории | Claude Opus 4.7 | Лучше результат на SWE-bench Pro и сильная репутация в инженерных задачах |
| Анализ огромного набора документов | GPT-5.5 | Резкий рост на длинном контексте и хорошая связка с рабочими инструментами |
| Проверка кода и поиск тонких ошибок | Claude Opus 4.7 | Ставка на точность, самопроверку и честное признание ограничений |
| Математика высокого уровня | GPT-5.5 | Заметное преимущество на FrontierMath Tier 4 |
| Рассуждение без инструментов | Claude Opus 4.7 | Выше результат на Humanity's Last Exam без инструментов |
| Дешёвая рутина | Ни одна из старших моделей | Лучше брать младшие модели и не платить за лишнюю мощность |
Лучший практический ход - собрать 30-50 реальных задач своей команды и прогнать через обе модели. Не демо-запросы, не красивые загадки, не «напиши змейку на языке Python», а настоящие рабочие случаи: грязная таблица, старый модуль, спорный документ, длинная переписка, неполное техническое задание, задача с противоречивыми вводными. После такого теста спор быстро станет тише.
Что проверить перед переходом
Переход на старшую модель без измерений почти гарантирует сюрпризы. Нужно считать не только качество ответов, но и цену, задержку, число повторов, количество ручных исправлений и типовые отказы. Для Opus 4.7 отдельно стоит измерить рост числа токенов на своих данных. Для GPT-5.5 отдельно стоит проверить, окупает ли агентная автономность более дорогой выход.
Командам разработки полезно держать две корзины задач. В первой - задачи, где модель должна дать точный вывод или правку. Во второй - задачи, где модель должна выполнить цепочку действий. Opus 4.7 чаще выиграет в первой корзине, GPT-5.5 чаще выиграет во второй. Попытка оценивать обе модели одним усреднённым баллом просто сотрёт главное различие.
- Возьмите реальные задачи за последние две недели, а не искусственные примеры.
- Сравните результат, число повторных запусков и объём ручной правки.
- Отдельно посчитайте входящие и выходящие токены.
- Проверьте, как модель ведёт себя при нехватке данных.
- Посмотрите, где модель уверенно ошибается, а где честно останавливается.
- Не отдавайте старшим моделям дешёвую рутину без причины.
Итог: корона теперь лежит не на голове, а в маршрутизаторе
GPT-5.5 не убила Claude Opus 4.7. Claude Opus 4.7 не пережил неделю и не стал вчерашней новостью. Сравнение получилось гораздо интереснее. OpenAI сильнее двигает идею модели-исполнителя, которая берёт сложную работу и тащит процесс через инструменты. Anthropic сильнее защищает образ модели-инженера, которая аккуратно работает с кодом, лучше держит инструкцию и меньше врёт уверенным голосом.
Для пользователя хороший ответ теперь звучит не «бери GPT» и не «бери Claude». Хороший ответ звучит так: маршрутизируй. Отправляй агентные цепочки и длинные рабочие процессы в GPT-5.5. Отправляй сложный код, строгий анализ и задачи с высокой ценой уверенной ошибки в Opus 4.7. Для простых задач используй младшие модели. Для критичных выводов оставляй человеческую проверку, потому что ни одна таблица тестов не отменяет ответственность.
Апрель 2026 года показал не просто гонку двух лабораторий. Рынок стал взрослее. Старшие модели больше не отличаются только «умнее» и «ещё умнее». Они получают характер, профиль, цену ошибки и собственную экономику. Корона больше не принадлежит одной модели. Корона лежит в системе, которая умеет выбрать правильную модель для правильной задачи.