
Как мы заставили ИИ работать на безопасность: 4 кейса из практики

Искусственный интеллект (ИИ) стал доступным инструментом для решения корпоративных и повседневных задач, и специалисты по информационной безопасности используют его возможности — а также контролируют то, как его используют другие. Но где именно ИИ действительно приносит пользу, а где остается просто модным словом маркетологов или СМИ? Делюсь практическими кейсами из нашей работы.
Меня зовут Сергей Божков, я главный специалист отдела информационной безопасности. Работаю в условиях кадрового дефицита и большого объема задач, поэтому постоянно приходится оптимизировать рабочие процессы.
Важное уточнение: мы не внедряли сложные коммерческие решения на базе ИИ. В работе применяем публичные и локальные языковые модели (LLM) как вспомогательный инструмент. При этом строго соблюдаем правила безопасности: обезличиваем документы, не передаем персональные данные, конфиденциальную информацию, учетные записи, пароли и API-ключи.
От «сырых» логов до готовых правил межсетевого экрана
После внедрения межсетевых экранов и сегментации сети мы столкнулись с сотнями тысяч строк логов межсетевых экранов, из которых нужно было сформировать правила доступа для систем, на которые отсутствует документация. Разобрать такой объем вручную — это несколько дней монотонной работы.
Загрузить весь массив логов в LLM нельзя — это переполнит контекст, и система не справится с обработкой. Поэтому мы показали модели несколько примеров строк из логов и то, какие правила должны получиться на выходе. За час работы с помощью LLM написали набор Python-скриптов, которые поэтапно обрабатывают данные:
- извлекают нужные поля (протокол, IP-адреса источника и назначения, порты);
- очищают данные от шума (например, UDP-порты с менее чем 10 обращениями);
- группируют записи по подсетям и сервисам;
- оптимизируют правила, объединяя последовательные порты в диапазоны.
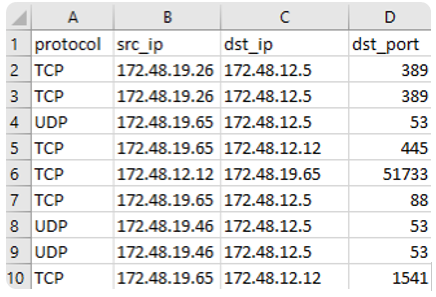
На выходе получаем структурированную таблицу с правилами в формате: protocol, src_ip, dst_ip, dst_port — готовую для загрузки в межсетевой экран.
Архитектором решения остается специалист. Надо четко формулировать, что нужно сделать и какую логику применить, а ИИ выступит исполнителем, помогая быстро написать необходимый код.
Документы и киберграмотность: от шаблонов до памяток
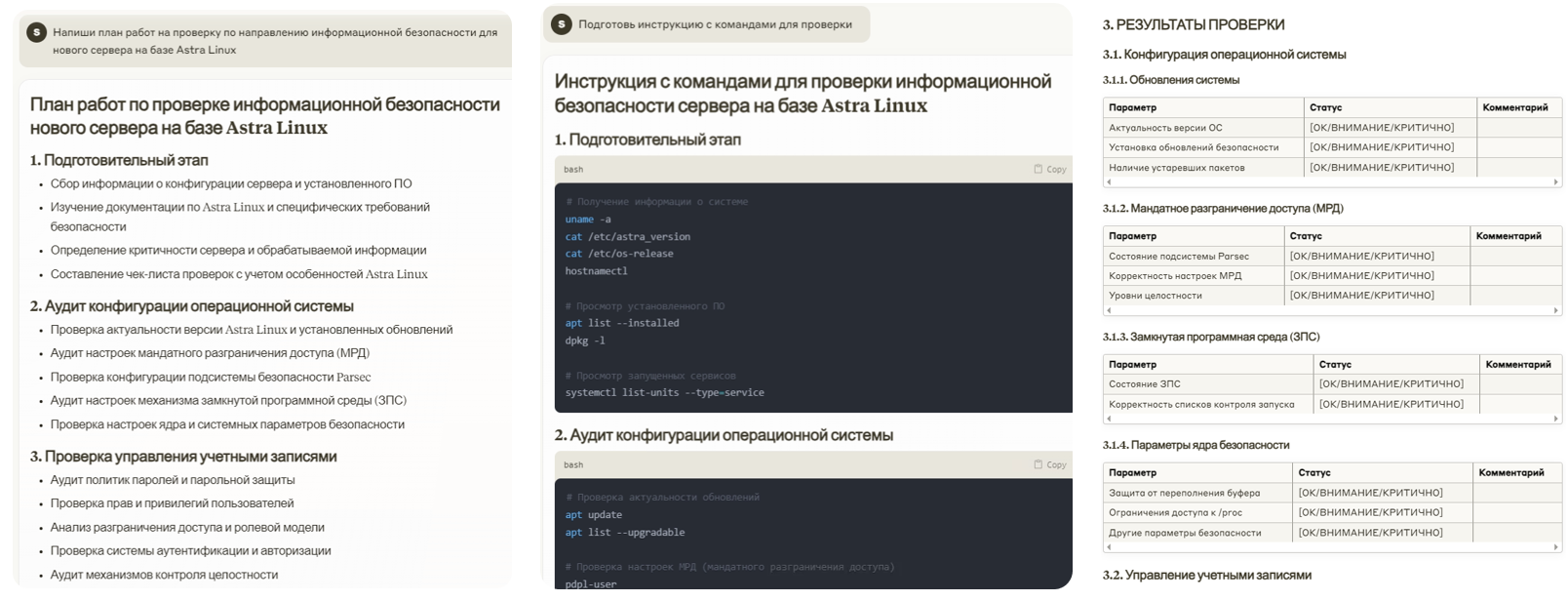
Рутина ИБ-отдела — не только логи и инциденты. Ещё мы берем на целевое обучение студентов и должны организовывать для них работу. LLM мы использовали для генерации плана аудита и шаблона отчета по проверке серверов на Astra Linux. Модель сгенерировала структурированный план с командами, пояснениями и разделами по настройке ОС, управлению учетными записями, сетевой безопасности, журналированию и другим аспектам. План и шаблон практически не потребовал доработки.
Другое, более творческое, направление — повышение осведомленности сотрудников о киберугрозах. Подготовка доступных и понятных памяток по видам атак и опасностям в сети теперь занимает около 45 минут вместо нескольких часов. Специалист задает тезисы и исходные материалы, LLM развивает их в связный и понятный материал. Остается только сгенерировать картинки — чтобы выглядело современно, с видимым применением ИИ, а не как скучный листок из прошлого века, — и оформить под корпоративный стиль.

Протокол за полчаса: как ИИ берет на себя самую нудную работу
Наш офис находится на Дальнем Востоке, головной — в центре. Совещания проходят регулярно, длятся от получаса до двух часов, а протоколы ведутся не всегда. Из-за разницы во времени не на каждое совещание удается попасть — а переслушивать утром запись совещания — не лучший способ продуктивно начать день.
Решение пришло после появления в DLP-системе «СёрчИнформ КИБ» модуля распознавания голоса. В нее встроен движок ASR, в тот момент это был VOSK, он преобразует речь в текст для дальнейшего анализа и поиска угроз, мы протестировали его, изучили используемую технологию и решили сделать подобное решение для наших задач.
В итоге разработали инструмент на базе другой модели — Whisper AI, который транскрибирует аудиозаписи. Распознавание часового совещания занимает 10-15 минут. Затем текст загружается в языковую модель, которая формирует структурированный протокол с ключевыми тезисами и решениями. Финальная проверка документа занимает минимум времени. Вся система работает локально.

Все по букве закона
Мы работаем на территории опережающего развития и имеем зону таможенного контроля. Оформление материальных пропусков и допуск для субподрядчиков требует соблюдения требований нескольких регуляторов, включая 152-ФЗ «О персональных данных».
В качестве эксперимента мы решили проверить, как ИИ справится с нормативкой, и загрузили в LLM текст ФЗ-152, рекомендации Роскомнадзора и приказы Минфина России (№ 71 от 29.05.2024 и № 16н от 27.02.2024). Модель выдала детальный алгоритм согласований: кто, кому и какие данные передает, на каком этапе формируются реестры.
Результат оказался близок к реальности, хотя были некоторые неточности. Как итог эксперимента это показало: ИИ может помочь создать рабочий черновик процесса, но финальная проверка специалистами и юристами остается обязательной.

Трезвый взгляд на риски
ИИ — не кнопка «Сделай хорошо». Это мощный, но требующий знаний и контроля инструмент. На практике мы сталкиваемся с такими проблемами как:
-
Галлюцинации. ИИ может уверенно выдавать неверную информацию, если у него недостаточно данных.
Мы пытались построить на основе Retrieval-Augmented Generation внутреннюю базу знаний с чат-ботом. Смысл в том, что модель ищет ответы в наших документах, которые мы поместили в её базу. Но метод требует идеально структурированных и отформатированных материалов. Наши внутренние инструкции такими не были, а править их вручную оказалось трудозатратно.
На отдельных правильно подготовленных документах ИИ выдавал правдоподобные, но всё равно не точные ответы и на один и тот же вопрос отвечал по-разному. Вывод: на данном этапе, для строгих регламентов лучше вручную найти первоисточник, чем доверять генерации.
Слепо доверять нельзя — любой ответ ИИ требует проверки, особенно в технических и юридических вопросах.
-
Конфиденциальность — ключевой риск. Данные, загружаемые в публичные LLM, остаются на их серверах и могут быть использованы для обучения моделей, и потенциально стать доступными третьим лицам.
Согласно отчёту OpenAI от февраля 2025 года, компания выявила и заблокировала множество аккаунтов, использовавшихся для мошеннических схем трудоустройства и кибератак, потенциально связанных с КНДР. Также OpenAI поделились информацией о пресечённых мошеннических схемах с коллегами из отрасли и соответствующими органами.
Еще один пример. В мае 2023 года Samsung запретила сотрудникам использовать ChatGPT и другие генеративные ИИ-сервисы после того, как сотрудник загрузил внутренний исходный код в ChatGPT. Компания мотивировала это тем, что переданные данные хранятся на внешних серверах, их сложно удалить, и они могут быть раскрыты третьим лицам.
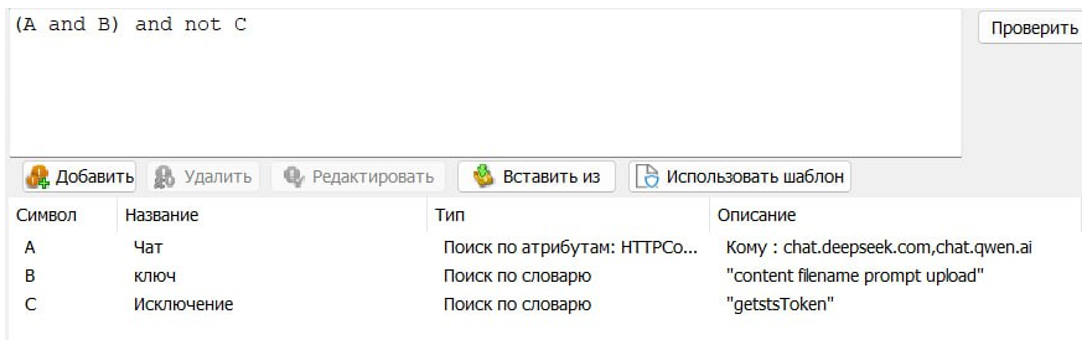
Чтобы исключить риски нарушения конфиденциальности, мы контролируем, какие данные выходят за пределы корпоративной сети. Для этого настроили в DLP «СёрчИнформ КИБ» правила, блокирующее загрузку файлов на домены популярных ИИ-сервисов. DLP-система также позволяет запретить передачу чувствительной информации через диалоговые интерфейсы и ограничить доступ к сайтам с инструментами ИИ. Дополнительно можно фрагментировать доступ к мессенджерам и соцсетям, через которые сотрудник может общаться с ИИ чат-ботами. Результатами мы довольны, вы тоже можете попробовать — вендор дает месяц на бесплатное тестирование.
Итог
ИИ — не замена специалисту, а его инструмент. Он отлично справляется с рутиной, генерацией простого кода или контента и первичной обработкой информации, но финальное решение и ответственность всегда остаются за человеком. Начинайте с малого: автоматизируйте самые трудоемкие и нудные процессы, тщательно проверяйте результаты и помните — безопасность важнее скорости.