

Долгое время считалось, что виртуальные продукты не способны сравниться по производительности с аппаратными аналогами. Особенно остро эта проблема проявляется в сегменте NGFW, где высокий трафик и глубокий анализ требуют значительных ресурсов. Но так ли это на самом деле? Действительно ли виртуальный межсетевой экран не способен обеспечить производительность в 5 Гбит/с и более, необходимую для современных корпоративных сетей и высоконагруженных систем?
Данная статья призвана ответить на эти вопросы. На примере решения PT NGFW мы не только продемонстрируем потенциал виртуальных межсетевых экранов, но и предоставим практические рекомендации по настройке виртуальной инфраструктуры. Разберем, как получить максимум от виртуального NGFW, поделимся практическими рекомендациями по настройке виртуальной инфраструктуры, а также подсветим важные нюансы, которые стоит учесть, при использовании NGFW в виртуальной среде.
1. Производительность NGFW в средах виртуализации
Начиная с версии PT NGFW 1.7 были зафиксированы показатели по производительности и технические характеристики виртуальных PT NGFW. Ознакомится с ними можно на официальном сайте Positive Technologies в разделе продукта PT NGFW.
В документации отмечены некоторые показатели по производительности, выделенные звездочкой (*). В сноске к этим данным указано, что для достижения заявленных значений необходимо правильно настроить среду виртуализации.
Давайте подробно рассмотрим, почему подготовка гипервизора имеет критическое значение, и как настроить PT NGFW для эффективной работы в виртуальной среде.
1.2 Ограничения виртуальных коммутаторов в гипервизорах
Для оценки ограничений виртуальных коммутаторов было проведено нагрузочное тестирование PT NGFW и Linux хоста при следующих условиях:
Генератор трафика:
CPU - 2 x Intel(R) Xeon(R) Gold 6230R CPU
RAM - 8 x 32Gb
NIC - 2 x Intel X710 2x10GbE SFP+
NIC - 2 x Intel X710 2x10GbE SFP+
Тип трафика: UDP 1500B IMIX, EMIX
Состав EMIX профиля:

Гипервизор VMware ESXi / KVM:
CPU - 2 x Intel(R) Xeon(R) Gold 6230R CPU
RAM - 8 x 32Gb
NIC - 2 x Intel X710 2x10GbE SFP+
NIC - 2 x Intel X710 2x10GbE SFP+
PT NGFW / Linux host:
CPU – 14 vCPU
RAM – 32Gb
Интерфейсы в KVM: 6 х Virtio (Ethernet interface)
Интерфейсы в VMware ESXi: 6 х 82574L Gigabit Network Connection
Рассмотрим результаты нагрузочного тестирования PT NGFW, запущенного на VMware ESXi.
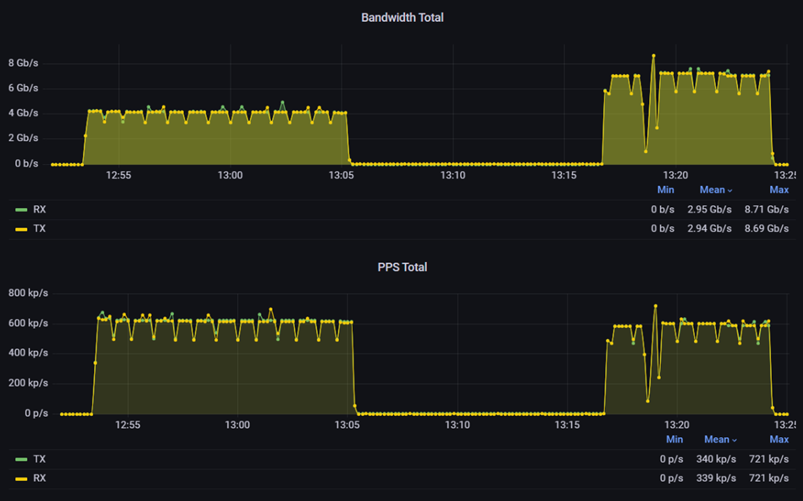
На графике «PPS Total» можно заметить, что при превышении 1,2 Mpp/s начинается расхождение между входящим (RX) и исходящим (TX) трафиком.
При анализе утилизации CPU самой виртуальной машины PT NGFW видно, что процессор ВМ (виртуальной машины) нагружен на уровне около 12%.
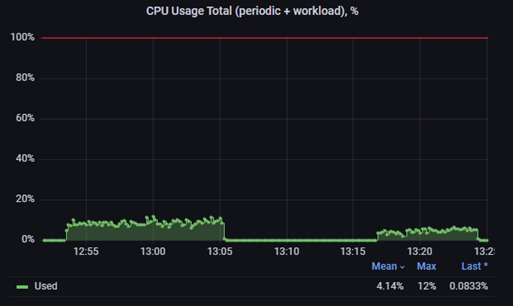
Это позволяет сделать вывод, что vSwitch VMware имеет ограничение по количеству пакетов в секунду (PPS), которые он может обработать, а именно порядка ~1,2 Mpps.
Данную цифру мы получаем из суммы RX и TX.
RX = 600 kp/s
TX = 600 kp/s
600 kp/s + 600 kp/s = 1,2 Mpp/s
Теперь рассмотрим аналогичный нагрузочный тест, но с ВМ, поднятой на KVM.
При подаче нагрузки на NGFW мы начинаем наблюдать потери после ~1.2 Mpps. Анализируя график CPU, демонстрирующий нагрузку на сервер с гипервизором, можно увидеть несколько процессов, которые полностью утилизируют процессор гипервизора.
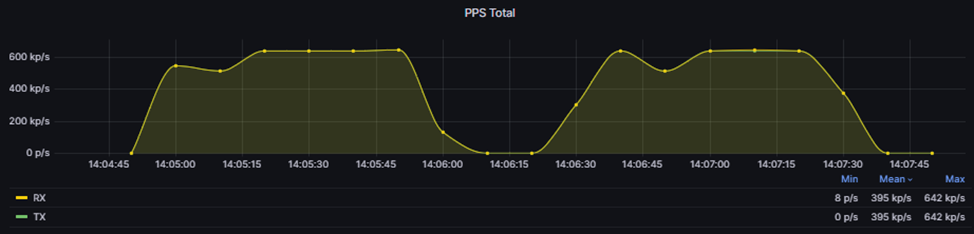
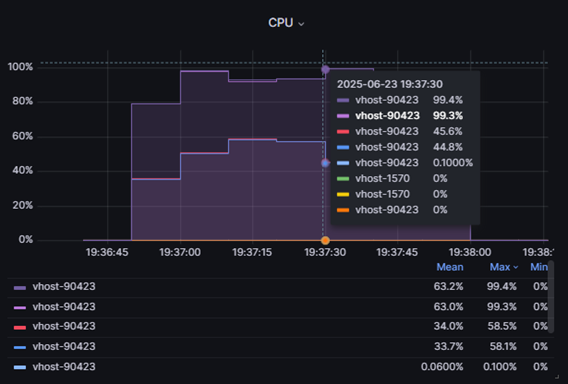
При этом уровень нагрузки на CPU ВМ PT NGFW составляет порядка ~8%.
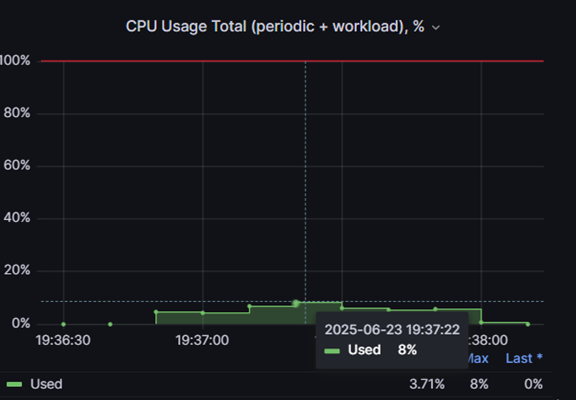
Чтобы убедиться, что ограничение не связано с PT NGFW, проведём нагрузочный тест на Linux-хосте, используя стандартный TCP/IP стек.
По результатам тестирования видно, что мы также достигаем предела производительности виртуального коммутатора, и полностью утилизируем процессор гипервизора.
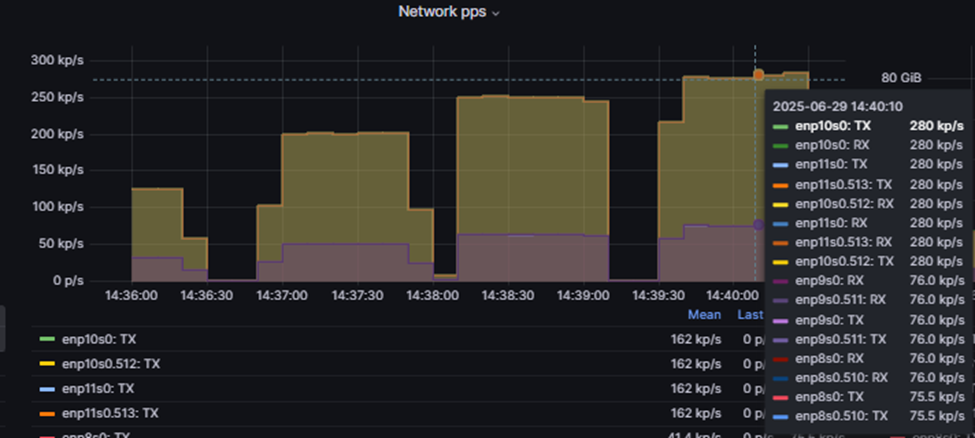
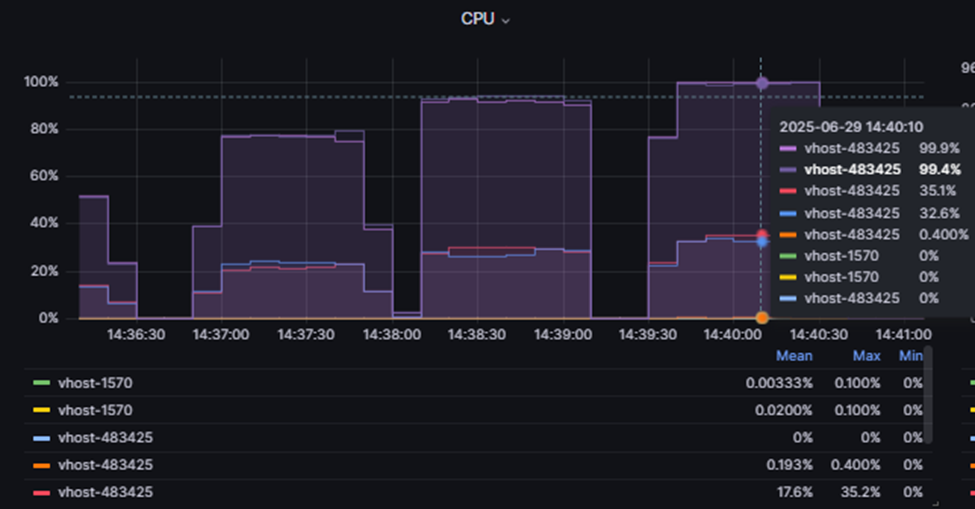
Таким образом, виртуальный коммутатор на базе KVM также имеет ограничения, схожие с vSwitch VMware.
Если вернуться к даташиту PT NGFW VM, можно заметить, что начиная с модели VM-1050 указано количество PPS, превышающее те значения, которые удалось получить при нагрузочных тестах.
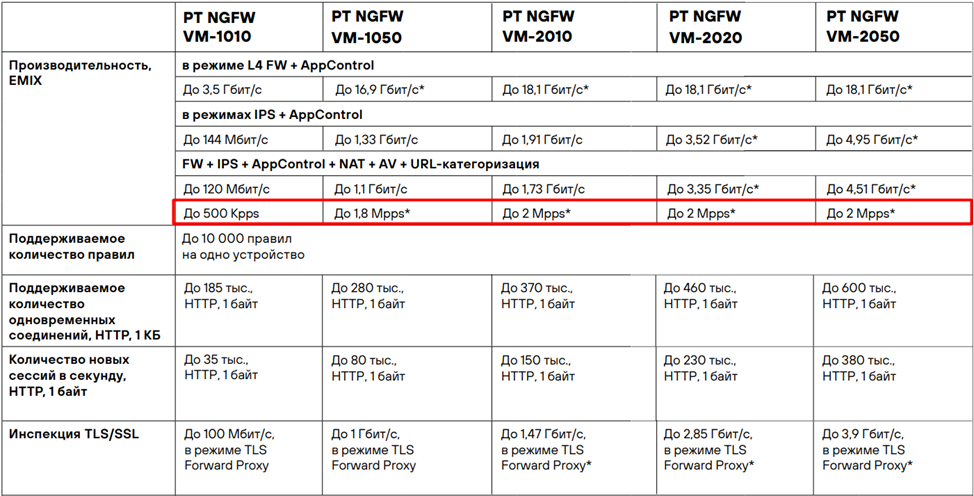
Одним из эффективных способов извлечь максимальную производительность PT NGFW в виртуальной среде является использование функции PCI passthrough. Эта технология позволяет напрямую передавать физические PCI-устройства виртуальной машине, обеспечивая ей прямой доступ к аппаратным ресурсам. Благодаря этому существенно снижаются задержки и накладные расходы, связанные с виртуализацией, что значительно повышает скорость обработки трафика и общую производительность PT NGFW.
Далее разберем, как настроить PCI passthrough в средах виртуализации и подготовить PT NGFW VM к запуску.
2. Настройка гипервизора
2.1 KVM настройка PCI passthrough
Чтобы настроить PCI passthrough в KVM, необходимо предварительно определить на гипервизоре PCI адреса сетевых карт, которые будут подключаться к ВМ NGFW.
Для этого можно воспользоваться командой:
lspci | grep -i eth
либо
shw -c network -businfo
В результате мы получим следующий вывод и в рамках него определим карты, которые будем подключать к ВМ:
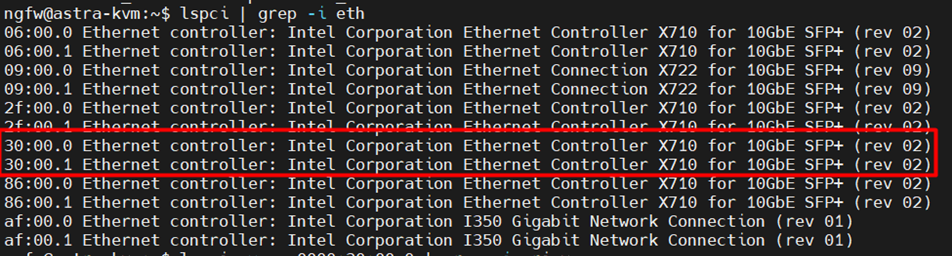
После этого можно воспользоваться virt manager для подключения PCI к PT NGFW.
В virt manager переходим в свойства ВМ и нажимаем «Add Hardware», далее в списке выбираем PCI-устройство.
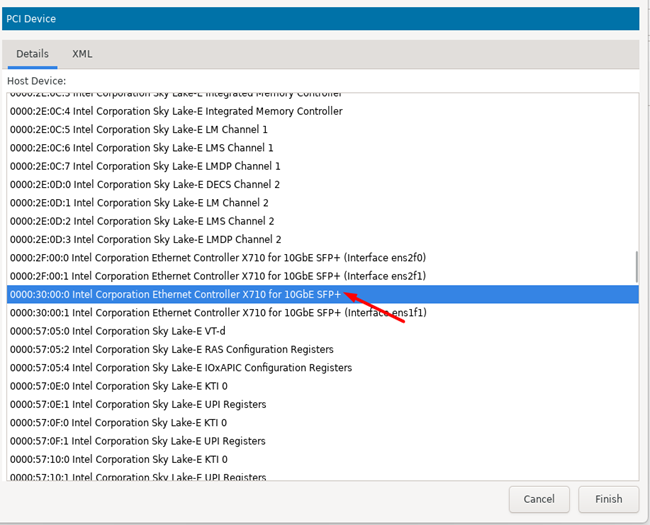
Далее необходимо убедиться, что PCI устройство подключилось к ВМ, для этого необходимо внутри ВМ воспользоваться командой:
lspci | grep -i eth
В полученном выводе мы должны увидеть подключенные PCI:

После необходимо скорректировать конфиг NGFW, прописав корректные PCI-адреса для интерфейсов в параметре «addr»:
sudo nano /opt/pt-ngfw/ngfw-core/etc/config/pt-ngfw.conf
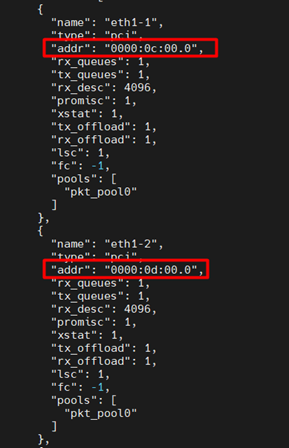
Далее перезапускаем службу NGFW:
sudo systemctl restart pt-ngfw-core
После чего мы можем проследить за процессом запуска PT NGFW посредствам вывода лога:
sudo tail -f /opt/pt-ngfw/ngfw-core/logs/ngfw.log
В результате запуска мы получим следующие сообщения, уведомляющие нас, что NGFW успешно запустился и увидел физические линки.

2.2 Резервирование ресурсов KVM
Для стабильной работы PT NGFW VM необходимо гарантировать выделение и резервирование ресурсов, чтобы виртуальная машина всегда получала назначенные мощности без конкуренции с другими VM или процессами гипервизора.
Для этого необходимо скорректировать XML виртуальной машины следующим образом:
sudo virsh edit «имя ВМ»
Прописываем в блок domain секции <cputune> и <memtune>:

Секция <memtune> используется для настройки управления памятью виртуальной машины.
Параметр <min_guarantee> устанавливает минимальный объём памяти, который будет гарантированно выделен ВМ.
Секция <cputune> используется для управления распределением процессорных ресурсов.
<vcpu> указывает количество виртуальных процессоров (VCPU), выделенных для ВМ. <vcpupin> – этот параметры привязывают каждый виртуальный процессор (VCPU) к конкретному физическому ядру (CPU).
Далее необходимо выключить ВМ и запустить ее:
sudo virsh shutdown «имя ВМ»
sudo virsh start «имя ВМ»
Таким образом ВМ будет гарантировано получать необходимые ресурсы.
Если ресурсы не закреплены за виртуальной машиной, это может привести к потерям трафика при высокой нагрузке, когда гипервизор и другие ВМ активно используют общие вычислительные ресурсы. Рассмотрим результаты нагрузочного тестирования PT NGFW в условиях, когда ресурсов недостаточно.
Во время теста на PT NGFW VM была подана нагрузка в 8 Гб, профиль emix. Анализ графиков CPU Usage и Handlers pools usage показал, что вычислительные ресурсы CPU использованы на ~40-60%, при этом оперативная память была полностью исчерпана.
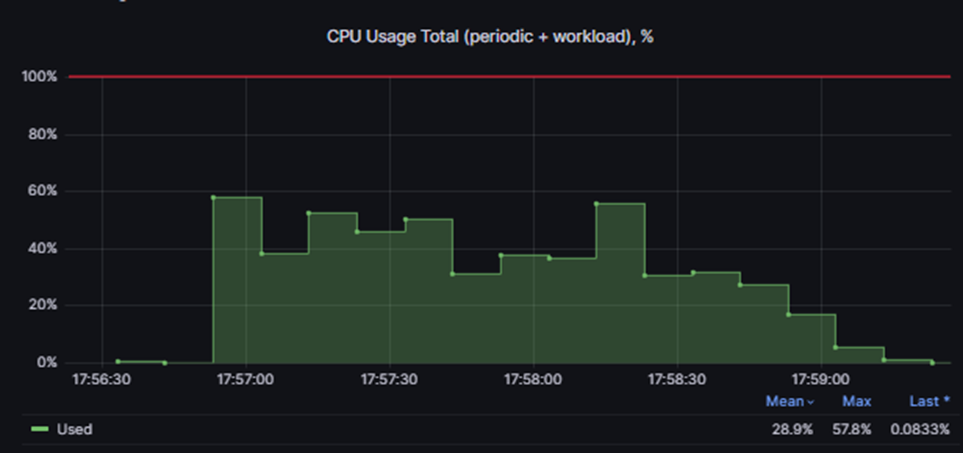
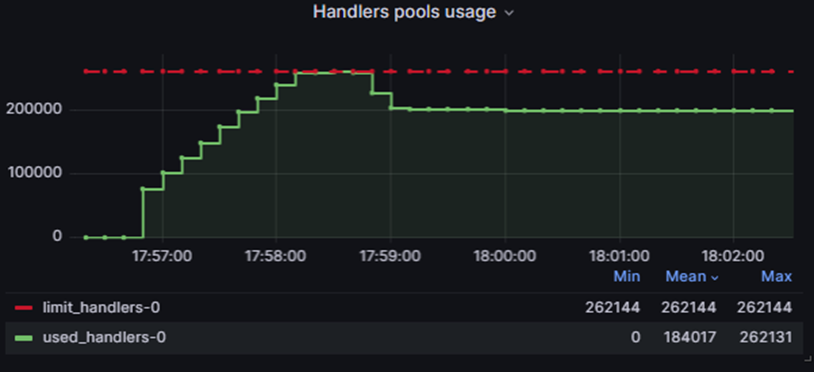
В итоге из подаваемых 8 Гб трафика ВМ смогла обработать лишь около 2 Гб, что свидетельствует о значительных потерях из-за нехватки ресурсов. Это подчёркивает важность правильного закрепления и выделения ресурсов за ВМ для обеспечения стабильной и эффективной работы.
2.3 ESXI настройка PCI passthrough
Для настройки PCI passthrough в ESXI необходимо выполнить следующее:
1. Включить поддержку passthrough в настройках EXSI.
На вкладке «Hardware» -> «PCI Devices» выбрать сетевую карту, которую мы будем подключать к ВМ, и нажать «Toggle passthrough».
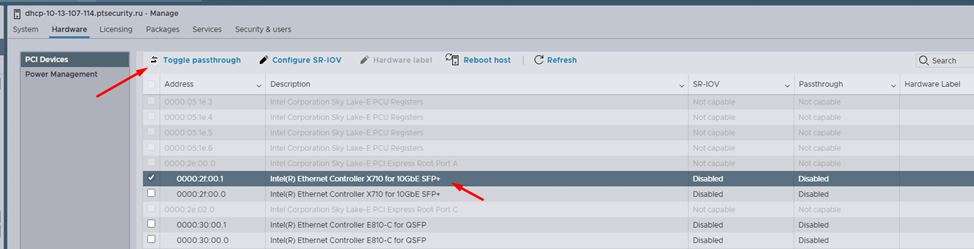
После этого в поле «Passthrough» отобразится состояние «Active».

2. Подключить PCI Devices к ВМ.
Перейти в параметры ВМ и нажать «Add other device», в выпадающем списке выбрать «PCI Devices».
Далее выбрать необходимую карту.
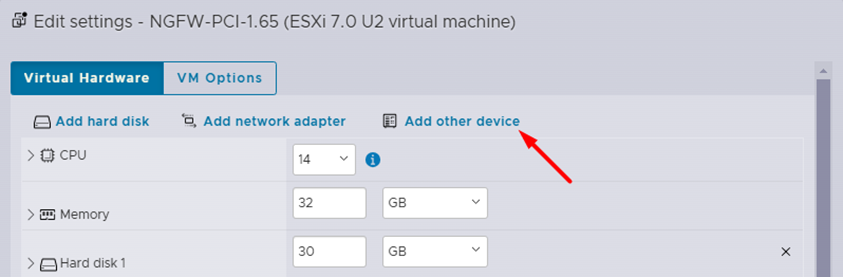
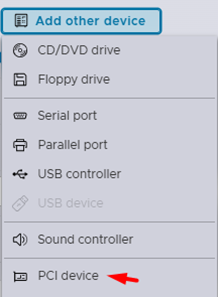

Затем нужно подготовить PT NGFW к запуску, выполнив следующие шаги:
1. На ВМ убедиться, что PCI-устройства успешно подключены командой:
lspci | grep -i eth
либо
lshw -c network -businfo

2. Скорректировать файл конфигурации загрузчика GRUB, отключив поддержку Intel IOMMU:
sudo nano /etc/default/grub
GRUB_CMDLINE_LINUX="quiet splash intel_iommu=off“
sudo update-grub

3. Отредактировать pt-ngfw.conf:
sudo nano /opt/pt-ngfw/ngfw-core/etc/config/pt-ngfw.conf
Прописываем PCI-адреса для интерфейсов:
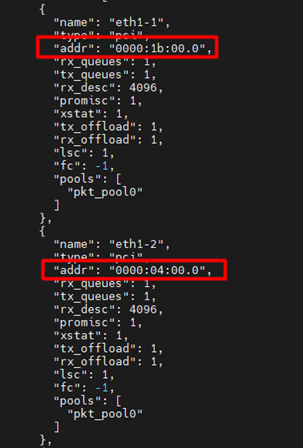
После этого в pt-ngfw.conf необходимо скорректировать «uio_driver», прописав «igb_uio».
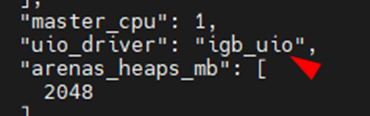
4.Скачиваем пакет, содержащий модули ядра (kernel modules) для DPDK, и загружаем его в ядро Linux:
sudo apt install dpdk-kmods-dkms/oldstable
sudo insmod /usr/lib/modules/5.10.0-34-amd64/updates/dkms/igb_uio.ko
5. Перезагружаем ВМ:
sudo reboot
6. Запускаем команду для отслеживания процесса запуска NGFW:
sudo tail -f /opt/pt-ngfw/ngfw-core/logs/ngfw.log
7. В результате запуска мы увидим, что NGFW подтянул интерфейсы и успешно запустился:

2.4 Резервирование ресурсов ESXI
При работе с PT NGFW на платформе VMware, по аналогии с KVM, важно обеспечить гарантированное и приоритетное выделение ресурсов виртуальной машине. Для этого в свойствах VM необходимо настроить параметры CPU и RAM – Reservation, Limit и Shares.
Reservation устанавливает минимальное количество ресурсов, которые гарантированно будут выделены для виртуальной машины.
Limit устанавливает максимальное количество ресурсов, которое ВМ может использовать.
Shares определяет относительный приоритет доступа к ресурсам между ВМ.
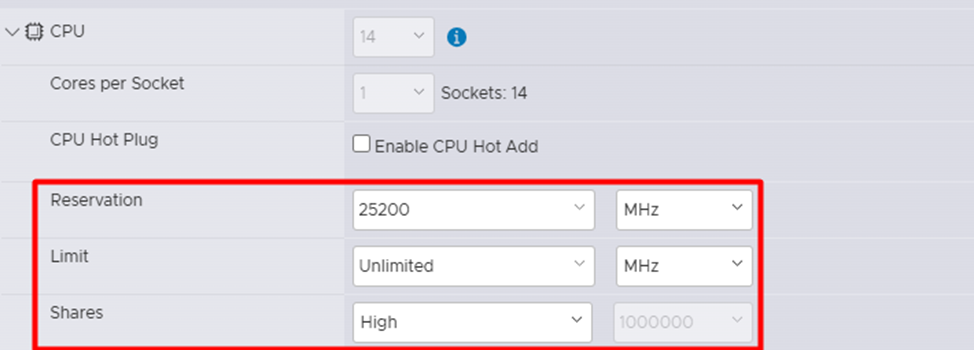
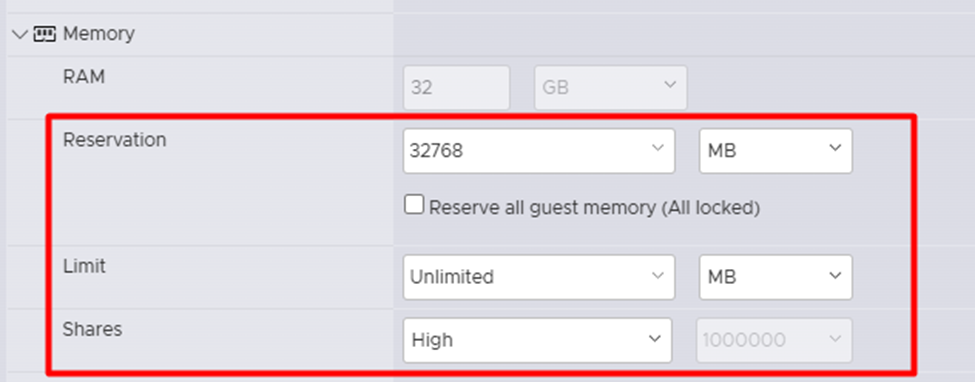
Настройка этих параметров позволяет эффективно резервировать ресурсы за PT NGFW VM, обеспечивая её стабильную работу и необходимый уровень производительности в виртуальной среде VMware.
2.5 Подача нагрузки на PT NGFW VM
После того, как мы настроили PCI passthrough, на ВМ была подана нагрузка ~18Гб/c с использованием emix профиля.
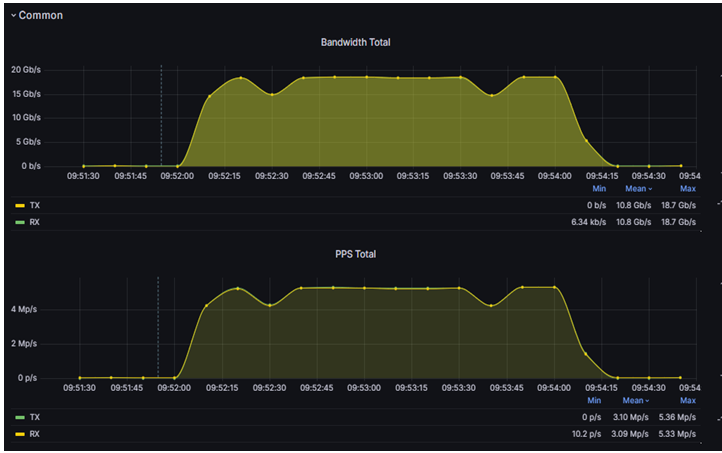
В результатах нагрузочного тестирования не наблюдается расхождение между показателями RX и TX, что свидетельствует об успешном прохождении теста. Это означает, что ограничения виртуальных коммутаторов больше не являются узким местом, что позволяет достигать значительно более высоких показателей производительности PT NGFW VM.
3 Настройка кластера PT NGFW в средах виртуализации
PT NGFW использует проприетарный протокол для работы в кластере, что позволяет на data-интерфейсах обеих нод использовать одинаковую адресацию. Это значительно упрощает архитектуру сети, устраняя необходимость в использовании протокола VRRP.
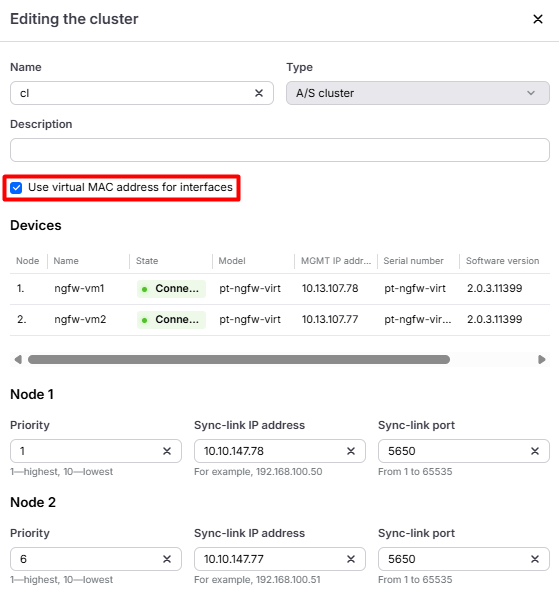
Реализация кластера в PT NGFW кроме виртуального IP-адреса опционально предлагает возможность использовать виртуальный MAC-адрес. Такой сценарий позволяет адаптировать встраивание кластера в том числе и в подсеть с приложениями, которые не адаптированы к изменению MAC-адреса шлюза по умолчанию в следствии рассылки сообщений GARP.
Стоит отметить, что для корректной работы VMAC в некоторых средах виртуализации требуется соответствующая настройка гипервизора.
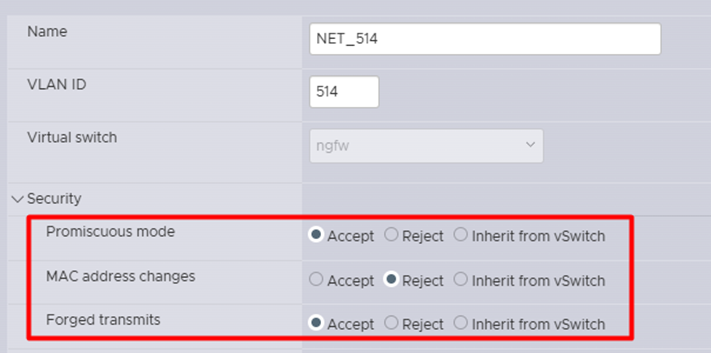
Рассмотрим ключевые шаги настройки Port Groups в VMware:
- Включить Promiscuous Mode. В этом режиме сетевой интерфейс принимает все пакеты, проходящие через сеть, независимо от их адресата. Обычно сетевой адаптер фильтрует трафик, пропуская только пакеты, адресованные собственному MAC-адресу, широковещательные или многоадресные пакеты. В режиме Promiscuous Mode устройство получает полный сетевой трафик, что необходимо для корректной работы VMAC, обеспечивая обработку пакетов, адресованных виртуальному MAC-адресу, используемому в кластере.
- Выключить «MAC Address Changes». Выключение этой опции предотвращает динамическое изменение MAC-адреса сетевого интерфейса. Это важно для стабильности сетевого взаимодействия, так как VMAC должен оставаться неизменным для корректного распознавания и маршрутизации трафика в кластере.
- Включить «Forget Transmits». Данная функция управляет кешем MAC-адресов, обеспечивая очистку информации о недавно переданных пакетах. Это помогает избежать повторной передачи или неправильной маршрутизации пакетов при переключениях или изменениях в сетевой топологии.
После настройки гипервизора необходимо активировать использование VMAC в системе управления межсетевыми экранами, указав соответствующую опцию в параметрах кластера, и применить политику.
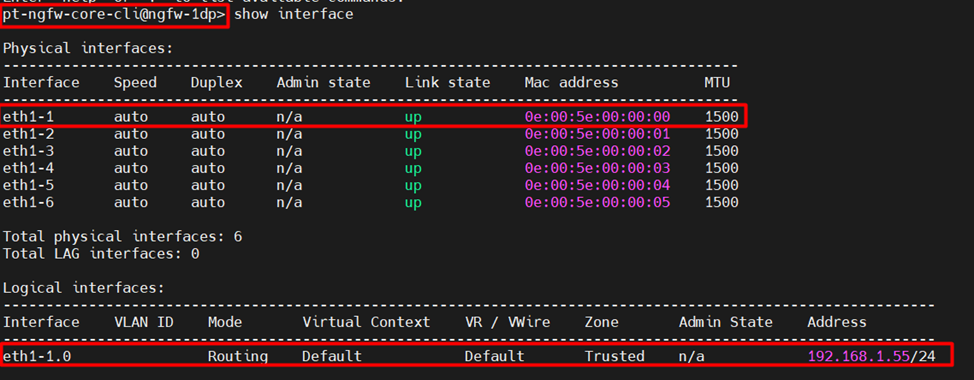
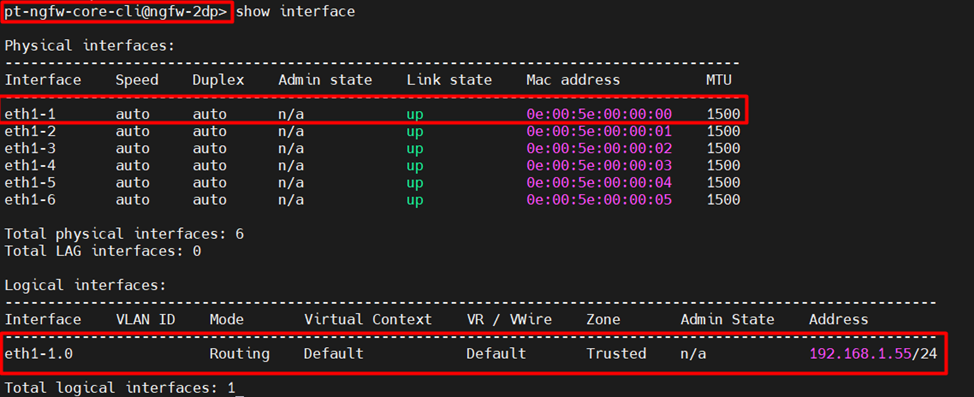
Убедиться в том, что обе ноды используют одинаковые MAC-адреса на data-интерфейсах, можно посредствам CLI с помощью команды:
show interface
Ниже приведен вывод с обеих нод.
Для подтверждения правильности настройки выполним вывод ARP-таблицы на клиентском рабочем месте. В нем будет видно, что хост распознает NGFW по виртуальному MAC-адресу, что гарантирует прозрачное и стабильное сетевое взаимодействие в кластере.

4. Заключение
При использовании PT NGFW в виртуальном исполнении необходимо учитывать следующие нюансы:
- При использовании функции PCI passthrough необходима правильная настройка драйверов в гостевой операционной системе. Например, в среде ESXi потребовалось внести изменения в драйвер uio_driver для запуска PT NGFW несмотря на то, что в KVM и ESXi использовались одинаковые сетевые карты Intel X710. Выбор драйвера зависит от среды виртуализации, типа сетевых карт и метода проброса в виртуальную машину, будь то PCI passthrough или SR-IOV.
- Выбор сетевых карт для подключения к NGFW. NGFW работает на базе DPDK, который имеет список поддерживаемых карт. С ним можно ознакомиться на официальном сайте DPDK.
- Ограничения сред виртуализации. Например, в KVM, работающей на Debian 12 с ядром 6.1.0-33-amd64, возникла проблема: виртуальная машина перестала запускаться после подключения PCI Devices. Выяснилось, что данная версия ядра содержит баг, который не позволяет использовать функцию PCI passthrough. В этом случае решение заключалось в даунгрейде до версии ядра 6.1.0-32-amd64. Делюсь ссылкой на форум, где данная проблема подсвечивалась.
- Сложности с обновлением и обслуживанием системы виртуализации. Прямой доступ к PCI Devices может ограничить использование таких функций, как vMotion в VMware, что может повлиять на гибкость и управляемость виртуальной инфраструктуры.
- Необходимость в резервировании ресурсов за ВМ. PT NGFW VM работает в общем пуле ресурсов физического хоста, который одновременно обслуживает множество ВМ. Без резервирования ресурсов NGFW может столкнуться с нехваткой CPU или памяти в моменты пиковых нагрузок других ВМ, что приведёт к снижению производительности, увеличению задержек, сетевым сбоям и другим негативным последствиям.