
Когда время — ваш враг: детальный анализ time-based атак и cпособов защиты
Специалист отдела обнаружения вредоносного ПО PT ESC Александр Тюков рассказывает о том, как реализовали защиту от time-based атак в песочнице.

Киберпреступники постоянно совершенствуют методы атак, используя среди прочего знания о принципах работы систем защиты. Например, появилось целое направление техник обхода песочниц: такие методы позволяют определять, что вредоносное ПО выполняется в контролируемой виртуальной среде, и, исходя из этого, менять его поведение или завершать работу. К наиболее популярным техникам из указанной категории можно отнести проверки:
- бита гипервизора в регистре ECX инструкции CPUID(1);
- имени гипервизора в результате выполнения инструкции CPUID(0x40000000);
- имени текущего пользователя или компьютера по списку;
- MAC-адресов сетевых адаптеров, присутствующих в системе;
- количества ядер процессора, общего объема оперативной памяти, размера жесткого диска, разрешения экрана;
- наличия файлов, путей реестра, сервисов, драйверов и процессов, специфичных для виртуальных сред;
- времени, прошедшего с момента последнего запуска системы.
CPUID — инструкция, позволяющая получить основную информацию о процессоре (например, его модель, поддерживаемые расширения и инструкции). Подробнее можно узнать на сайте Microsoft или в спецификации производителя конкретного процессора.
Детальнее о техниках обхода песочниц в таргетированных атаках мы говорили в другой статье. А сегодня поговорим о более продвинутых временных атаках, использующих особенности работы гипервизора для детектирования виртуального окружения. Механизм борьбы с ними реализован в PT Sandbox.
Что такое временные атаки
Главное в такой атаке ― замерить время выполнения определенных действий в виртуальной среде и сравнить его с результатами, полученными при выполнении тех же действий на реальном устройстве. Например, реализация инструкции CPUID на реальном компьютере в среднем занимает 100–200 процессорных тиков, а на виртуальной машине (VM) — более 2000 тиков в зависимости от используемого гипервизора. Чтобы понять, откуда появляется такая разница, обратимся к спецификации Intel.

Рисунок 1. Инструкции, всегда вызывающие выход в гипервизор (Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C, & 3D): System Programming Guide)
Согласно документации, CPUID является одной из инструкций, которые всегда вызывают выход в гипервизор из VM (VM exit). Гипервизор эмулирует эту инструкцию, что сильно увеличивает время ее обработки. Пример обработчика CPUID есть в проекте Xen.
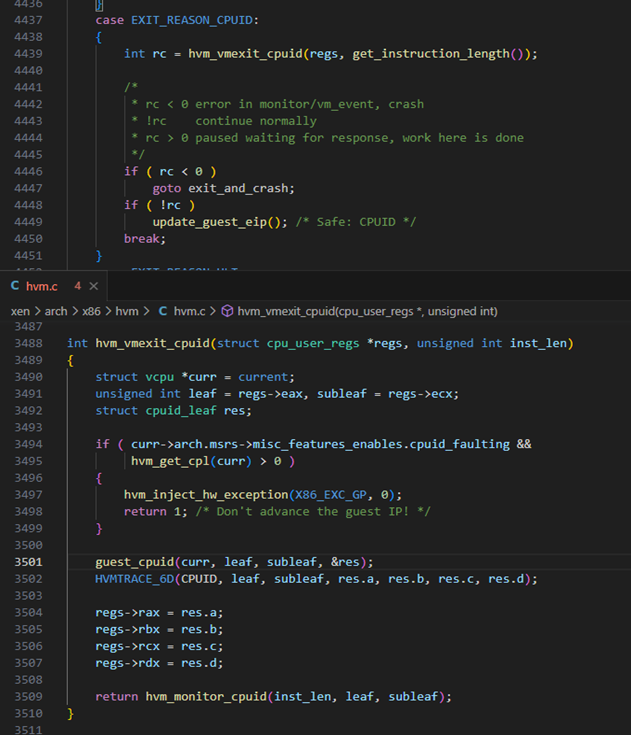
Рисунок 2. Обработчик CPUID в проекте Xen
Из описанного выше становится ясно, что вызывает такую разницу. Результат измерения представляет собой суммарное время, необходимое:
- для переключения с гостевой VM на гипервизор;
- выполнения обработчика и функций, которые он вызывает в процессе;
- возврата из гипервизора в гостевую VM.
В качестве одного из методов замера времени может использоваться инструкция RDTSC.
Инструкция RDTSC считывает состояние внутреннего счетчика временных меток TSC, который содержит количество тиков процессора с последнего получения сигнала RESET. Результат возвращается в регистрах EDX:EAX в виде 64-битного значения. Подробнее о счетчике TSC можно узнать из Википедии.
Примеры временных проверок In The Wild
Примеры временных проверок можно найти в открытых инструментах Pafish и Al-Khaser. В обоих присутствует проверка с замером времени выполнения CPUID с той лишь разницей, что Pafish вызывает Sleep после каждого этапа. Это повышает надежность проверки: пока текущий поток приостановлен, планировщик ресурсов ОС может выделить квант времени на выполнение других потоков. Таким образом снижается вероятность переключения на другой поток или процесс в ходе замера.
bool rdtsc_diff_vmexit()
{
uint64_t tsc1 = 0;
uint64_t tsc2 = 0;
uint64_t avg = 0;
int cpuInfo[4] = {};
// Try this 10 times in case of small fluctuations
for (int i = 0; i < 10; i++)
{
tsc1 = __rdtsc();
__cpuid(cpuInfo, 0);
tsc2 = __rdtsc();
// Get the delta of the two RDTSC
avg += (tsc2 - tsc1);
Sleep(500); // Not present in Al-Khaser
}
// Process repeated 10 times to make it more reliable
avg = avg / 10;
return (avg < 1000 && avg > 0) ? FALSE : TRUE;
}
В Pafish можно также найти другой вариант проверки, в котором не используется CPUID. Она рассчитана на гипервизоры, эмулирующие счетчик TSC.
bool rdtsc_diff()
{
uint64_t avg = 0;
for (int i = 0; i < 10; i++) {
tsc1 = __rdtsc();
avg += __rdtsc() - tsc1;
Sleep(500);
}
avg = avg / 10;
return (avg < 750 && avg > 0) ? FALSE : TRUE;
}
Если CPUID всегда вызывает VM exit, то для RDTSC такое поведение опционально. Согласно спецификации Intel, RDTSC тоже может вызывать выход в гипервизор при условии, что включен флаг RDTSC_EXITING. Этот факт пригодится нам позднее.

Рисунок 3. Инструкции, вызывающие VM exit (Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C, & 3D): System Programming Guide)
Временные проверки в ВПО
FatalRat единоразово проверяет разницу между двумя последовательными считываниями счетчика TSC на превышение 255 тиков.
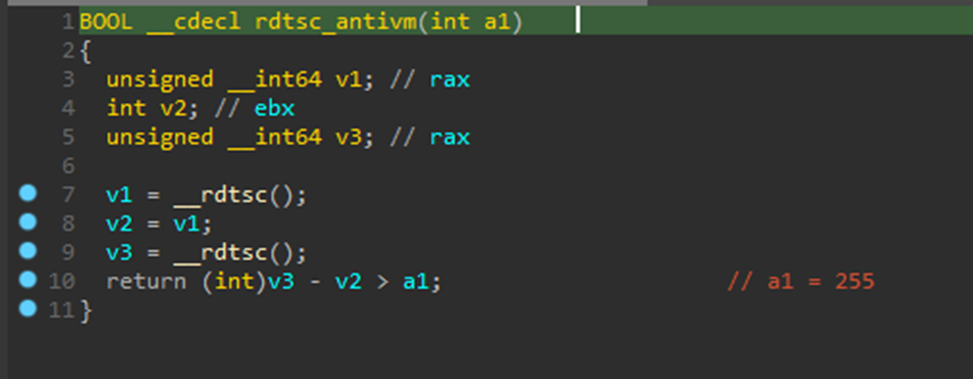
Рисунок 4. Временная проверка в FatalRat (SHA-256 — 17075832426b085743c2ba811690b525cf8d486da127edc030f28bb3e10e0734)
IcedID использует слегка другой подход. В цикле измеряется и аккумулируется время на выполнение последовательностей RDTSC → CPUID → RDTSC и RDTSC → RDTSC, после чего вычисляется их отношение. При этом для повышения надежности проверки применяется вызов SwitchToThread() (аналогичный Sleep в Pafish).
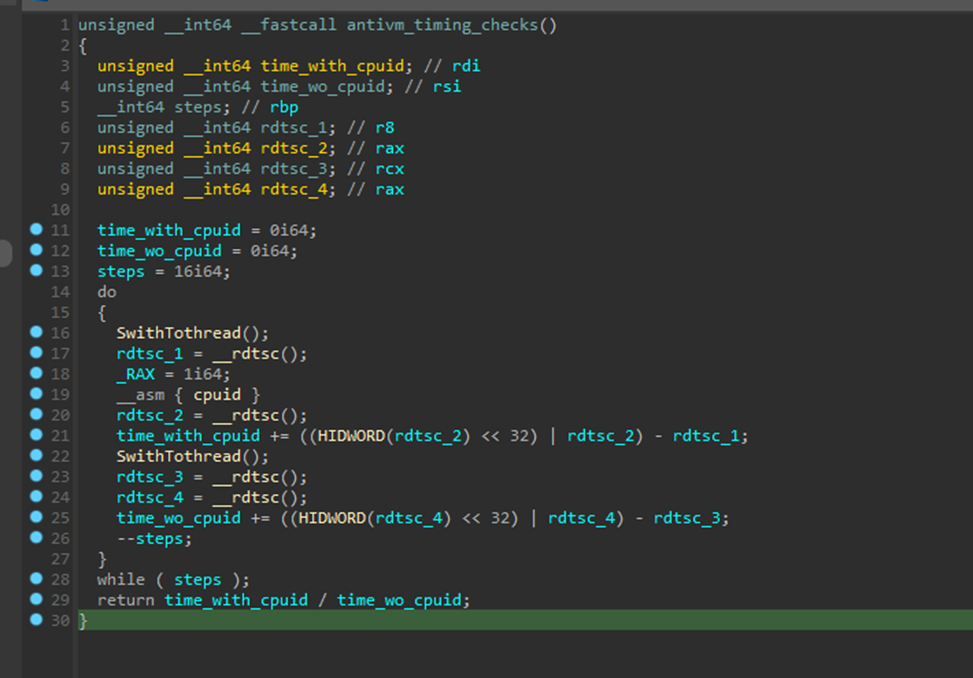
Рисунок 5. Временная проверка в IcedID (SHA-256 — a9fc2b58e0e714a5135bff2d7c5c3a1d46359363696bdfa3feaabeb6f6bdc3af)
GuLoader использует две временных проверки. Первая заключается в замере времени выполнения все того же CPUID, однако в качестве источника используется не счетчик TSC, а поле SystemTime из структуры KUSER_SHARED_DATA (см. документацию Microsoft). Это возможно, потому что такая структура всегда расположена по фиксированному адресу.
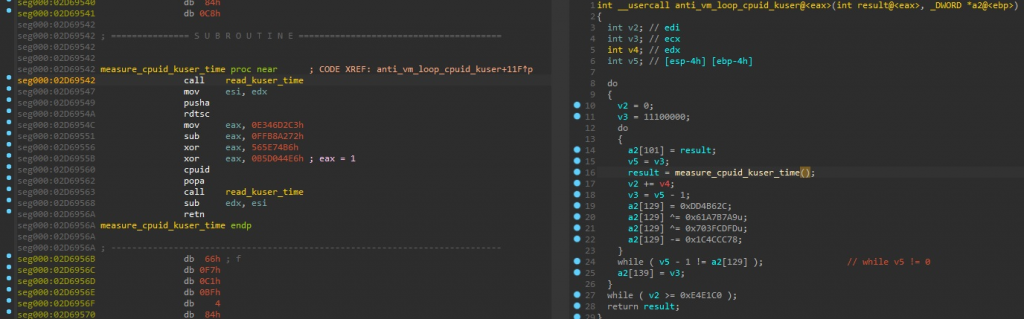
Рисунок 6. Замер времени выполнения CPUID путем чтения KUSER_SHARED_DATA.SystemTime (SHA-256 — b44b66a528c6cc9f395cf656a336edd3e763744529cbd3eab845f7ef371d6535)
Вторая проверка похожа на те, что были показаны ранее, но вызов RDTSC находится в отдельной функции. Замеры выполняются 100 000 раз, на каждом этапе результат добавляется к общему. Кроме того, отдельно проверяются случаи, когда дельта составила менее 49 тиков.
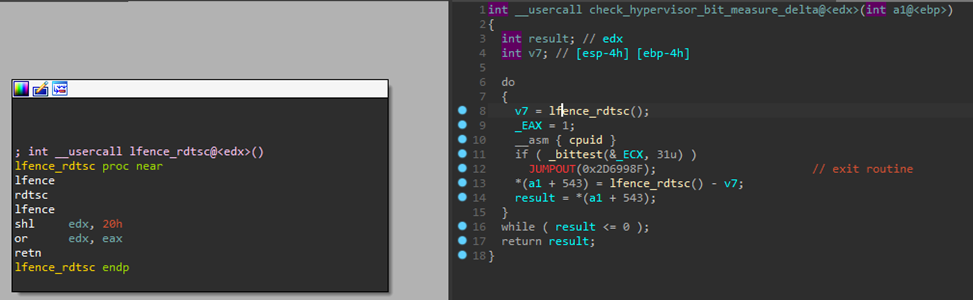
Рисунок 7. Замер времени выполнения CPUID и проверка бита гипервизора в регистре ECX (SHA-256 — b44b66a528c6cc9f395cf656a336edd3e763744529cbd3eab845f7ef371d6535)
По итогам замеров с помощью сравнения проверяется, что:
- количество раз, когда дельта была менее 49 тиков, не превышает 60 000;
- сумма результатов не превышает 110 000 000 тиков.
Интересным также является тот факт, что проверки выполняются, пока не будут успешно пройдены, то есть до получения результата, характерного для реального устройства. За счет этого в некоторых песочницах GuLoader бесконечно работает вхолостую, не доходя до развертывания полезной нагрузки.
Существуют и более продвинутые варианты атак. Прочитать о них можно, например, в докладе My Ticks Don’t Lie: New Timing Attacks for Hypervisor Detection, который был представлен на конференции Black Hat.
Если резюмировать описанное выше, можно сделать несколько выводов:
- В большинстве ВПО и инструментов для совершения атак используется совокупность вызовов RDTSC и CPUID.
- Почти всегда эти вызовы расположены в рамках одной функции, идут подряд или на небольшом расстоянии друг от друга, чтобы минимизировать шанс переключения контекста во время проверки.
- Инструкция RDTSC может вызывать VM exit при включенном флаге RDTSC_EXITING.
Сокрытие VM от временных атак
Существуют разные методы обхода временных атак. Попробуем рассмотреть один из вариантов сокрытия VM на базе связки Xen и DRAKVUF. Однако прежде нужно найти ответы на следующие вопросы:
- как различать процессы, вызывающие VM exit на уровне гипервизора;
- как переключать флаг RDTSC_EXITING в Xen;
- как сдвигать время для конкретного ядра VM;
- когда требуется его сдвигать.
Регистр CR3
Большинство современных процессоров используют четырехуровневую адресацию при работе в 64-разрядном режиме. Вместе с тем регистр CR3 содержит физический адрес начала таблицы PML4, используемой для трансляции физического адреса в виртуальный. Подробнее об этом процессе можно узнать в статьях Exploring Virtual Memory and Page Structures и Turning the Pages: Introduction to Memory Paging on Windows 10 x64.

Рисунок 8. Описание структуры CR3 (Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C, & 3D): System Programming Guide)
Поскольку каждый процесс работает в рамках своего виртуального адресного пространства, то и адреса PML4 в CR3 будут уникальными.
Манипуляции со временем в Xen
Xen поддерживает два режима работы со счетчиком TSC: нативный и режим эмуляции. Переключение между ними осуществляется за счет установки ранее упомянутого флага RDTSC_EXITING (далее — ловушка). Включить или отключить ловушку можно так:
vmx_set_rdtsc_exiting(v, 1); // v — vCPU where flag should be enabled
Добавим обработчик, который будет заполнять регистры EDX:EAX заданным временем:
void hvm_rdtsc_intercept_fixed(struct cpu_user_regs *regs, uint64_t set_time)
{
// We already know the TSC value that we have to write
msr_split(regs, set_time);
HVMTRACE_2D(RDTSC, regs->eax, regs->edx);
}
Помимо результата в регистрах также требуется подменить и синхронизировать время на ядре, чтобы при отключении ловушки изменения сохранились на гостевой ОС. Делается это путем модификации поля TSC offset. Спецификация Intel дает четкое представление о том, как и в каких случаях оно используется.

Рисунок 9. Описание поля TSC offset (Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3 (3A, 3B, 3C, & 3D): System Programming Guide)
То есть, чтобы установить время для конкретного ядра, требуется:
- отключить флаг RDTSC_EXITING;
- рассчитать новое время на основании текущего значения TSC offset и получить дельту;
- вычесть дельту из значения TSC offset или добавить ее в зависимости от того, в какую сторону требуется сдвинуть счетчик.
В коде это выглядит следующим образом:
static void try_set_tsc_offset(struct vcpu *v)
{
if (!v->ts.override_tsc)
return;
// Turn off RDTSC trap
disable_hook(v);
// Calculate delta between current time and the time we want to set
delta_to_set = hvm_get_guest_tsc(v) - v->ts;
// Subtract delta from currently cached tsc_offset
v->arch.hvm.cache_tsc_offset -= delta_to_set;
// Write new tsc_offset to vCPU
vmx_set_tsc_offset(v, v->arch.hvm.cache_tsc_offset, 0);
// Not updating system time might cause VM to crash after a while
if (v == current)
force_update_vcpu_system_time(v);
}
Важный момент: поскольку установка счетчика и его синхронизация между гипервизором и VM также занимают некоторое время, идеально точная настройка не представляется возможной.
Логика работы сокрытия
По умолчанию в Xen инструкция RDTSC выполняется нативно. Это означает, что последовательные проверки RDTSC → RDTSC инструменту нестрашны. Соответственно, в первую очередь будет рассмотрен вариант, при котором используется CPUID.
После каждого выхода по CPUID сохраняется текущее время гостевой VM, состояние регистров (CR3, RBP, RIP) и включается ловушка RDTSC, если она не была включена ранее. CR3 используется как уникальный идентификатор процесса, RBP — как идентификатор потока или функции, RIP — для определения принадлежности инструкций к одному блоку кода. Требуется учитывать тот факт, что время, затрачиваемое на переход из гостевой VM в гипервизор, неизвестно, и корректировать сохраняемое значение.
На последующих выходах проверяется, что:
- причиной выхода является RDTSC;
- выход произошел из того же процесса;
- выход произошел из того же потока или функции;
- выход произошел не дальше, чем за N байт от сохраненных значений.
Если все условия выполнены, среднее время добавляется к сохраненному времени нативного выполнения RDTSC и устанавливается в регистры EDX:EAX, а перед возвратом исполнения кода в VM также обновляется TSC offset. Далее приведены упрощенные функции — обработчики логики для сохранения и перезаписи значений:
- Функция, отвечающая за общую логику, заполнение и сравнение используемых параметров:
// Called on each VM exit
static void timeoverride_get_params(struct vcpu *v, struct cpu_user_regs *regs, unsigned long exit_reason, unsigned long *cr3, int *override_method, bool *donotadvance)
{
unsigned long _cr3 = 0;
int _override_method = TIMEOVERRIDE_OVERRIDE_NONE;
...
get_curr_cr3(&_cr3);
// Checks are only required when RDTSC hook is enabled
if ( v->arch.hvm.vmx.exec_control & CPU_BASED_RDTSC_EXITING)
{
// Is it the same process?
if ( _cr3 == v->ts.ts_cr3 )
{
// Is it the same thread or function?
if (v->ts.ts_rbp == regs->rbp)
{
// Is it one of the interesting VM exits?
if( check_vmexit_for_override(exit_reason))
{
// Some other exits within the same process & thread occurred
// Disable hook & skip override
disable_hook(v);
}
// Is it the same chunk of code?
if (is_close(regs->rip, v->ts.ts_rip))
{
_override_method = TIMEOVERRIDE_OVERRIDE_CURRENT;
}
else
{
// It's too far, disable hook
disable_hook(v);
}
}
// It's another thread or func
else
{
...
}
}
// It's another process
else
{
...
}
}
*override_method = _override_method;
*cr3 = _cr3;
}
-
Обработчик CPUID:
static void timeoverride_cpuid_handler(struct vcpu *v, struct cpu_user_regs *regs, unsigned long cr3, unsigned long exit_reason, uint64_t time)
{
// Enable hook if it's not on
if (!rdstc_exiting(v))
vmx_set_rdtsc_exiting(v, 1);
...
v->ts.ts = time - TIMEOVERRIDE_CPUID_FIX_DELTA;
// Save regs, etc.
...
}
-
Обработчик RDTSC:
static void timeoverride_rdtsc_handler(struct vcpu *v, struct cpu_user_regs *regs, unsigned long cr3, unsigned long exit_reason, int override_method, bool donotadvance, uint64_t time)
{
if (override_method != TIMEOVERRIDE_OVERRIDE_NONE)
{
...
v->ts.ts = v->ts.ts + v->ts.ts_rdtsc_time;
// Set override flag
v->ts.override_tsc = true;
...
// Fill regs
hvm_rdtsc_intercept_fixed(regs, v->ts.ts);
...
}
else
{
// Handle RDTSC normally
...
}
}
Казалось бы, все просто, однако есть несколько подводных камней:
- Ловушка на RDTSC отключается только в случае, если сработал механизм установки времени или выход произошел далее, чем за N байт от сохраненных значений. При этом каждый такой выход сильно влияет на производительность VM.
- Программы и ОС часто легитимно вызывают CPUID, то есть ловушка будет включена почти всегда.
- При проверке может переключиться контекст (например, на какой-то другой процесс, выполнивший CPUID), тогда сохраненные данные сбросятся.
- Программа может начать временную проверку после того, как ловушка была включена.
- Проверку RDTSC + RDTSC требуется обрабатывать вручную, пока включена ловушка.
Чтобы устранить проблемы, для первых двух пунктов вводятся дополнительные условия на отключение ловушки:
- счетчик «пропущенных» тиков, который при определенных условиях увеличивается на среднее время нативного выполнения RDTSC. При превышении заданного лимита ловушка отключается;
- выполнение двух последовательных инструкций CPUID в рамках одной функции;
- выполнение процессом прочих VM exit (за исключением частных случаев);
- выполнение RDTSC или CPUID в рамках одной функции на расстоянии больше заданного.
Для решения третьей задачи можно хранить две копии параметров: для текущего и предыдущего процессов. Если контекст переключится на несколько других процессов подряд, сокрытие не сработает (данные об исходном процессе будут перезаписаны), однако можно считать, что на реальном устройстве проверка также бы провалилась. Для четвертого и пятого пунктов используется эвристика, отслеживающая потенциальное начало проверки и позволяющая устанавливать правильное время.
Полный вариант обработчиков и их более подробное описание можно найти в приложении «Полный алгоритм сокрытия».
Повышение приоритета процессов с помощью DRAKVUF
Рассмотренный выше алгоритм стабилен только для одноядерной VM. Если же ядер несколько, есть вероятность, что при проверке исполнение будет перенесено на другое ядро, где ловушка отключена. Чтобы снизить вероятность подобной ситуации, можно поправить приоритет заданного процесса и всех его потоков при старте с помощью фреймворка DRAKVUF. Подробнее о приоритетах и их значениях — в документации Microsoft.
Не будем сильно углубляться в детали. Поля BasePriority (базовый приоритет) и Priority (текущий приоритет) потока расположены в структуре KTHREAD. Они заполняются при вызове KeStartThread. Соответственно, наиболее удобным этапом для перезаписи будет момент возврата исполнения из функции KeStartThread. Следует установить перехваты не только на KeStartThread, но и на функции PspInsertProcess и NtTerminateProcess. Они нужны, чтобы поддерживать список новых процессов на VM и, например, не повышать приоритет недавно появившихся системных потоков и прочих «неинтересных» процессов.
std::vector<addr_t> new_procs;
setpriority::setpriority(drakvuf_t drakvuf,
const setpriority_config* config
, output_format_t output): pluginex(drakvuf, output)
, offsets(new size_t[__OFFSET_MAX])
)
{
// Load required offsets from profile
if (!drakvuf_get_kernel_struct_members_array_rva(drakvuf, offset_names, __OFFSET_MAX, offsets))
{
PRINT_DEBUG("[SETPRIORITY] Failed to get kernel struct member offsets\n");
throw -1;
}
...
// Set hooks to monitor new processes & save them to new_procs
hooks.push_back(createSyscallHook("PspInsertProcess", &setpriority::hook_insertprocess_cb));
// Hook to remove terminated process from new_procs
hooks.push_back(createSyscallHook("NtTerminateProcess", &setpriority::hook_terminate_process_cb));
hooks.push_back(createSyscallHook("KeStartThread", &setpriority::hook_threadstart_cb));
}
Установка ловушки на возврат из вызова KeStartThread и сохранение адреса KTHREAD в параметрах перехвата:
event_response_t setpriority::hook_threadstart_cb(drakvuf_t drakvuf, drakvuf_trap_info_t* info)
{
// Get KTHREAD parameter from function arguments
auto kthread = drakvuf_get_function_argument(drakvuf, info, 1);
addr_t process;
// Find EPROCESS parameter from KTHREAD
if (!drakvuf_get_process_from_thread(drakvuf, kthread, &process))
{
PRINT_DEBUG("[SETPRIORITY] Failed to get KTHREAD_PROCESS\n");
return VMI_EVENT_RESPONSE_NONE;
}
// We only want to monitor new processes
if (is_new_process(process))
{
// Create and save return hook
auto hook_id = this->make_hook_id(info);
auto hook = createReturnHook<createthread_result_t>(info, &return_hook_threadstart_cb);
auto params = libhook::GetTrapParams<createthread_result_t>(hook->trap_);
// Save KTHREAD parameters to use later
params->thread = kthread;
ret_hooks[hook_id] = std::move(hook);
}
return VMI_EVENT_RESPONSE_NONE;
}
Требуется проверить, что возврат происходит в том же контексте, где установлена ловушка. В ином случае модификации параметров потока не произойдет.
static event_response_t return_hook_threadstart_cb(drakvuf_t drakvuf, drakvuf_trap_info_t* info)
{
auto plugin = GetTrapPlugin<setpriority>(info);
auto params = libhook::GetTrapParams<createthread_result_t>(info);
// Ensure it's one of the processes we want to fix
if (!params->verifyResultCallParams(drakvuf, info))
return VMI_EVENT_RESPONSE_NONE;
vmi_lock_guard vmi(drakvuf);
// Get KTHREAD pointer from trap parameters
auto thread = params->thread;
// Attempt to fix its priority fields
if (!plugin->set_thread_priority_fields(drakvuf, thread))
return VMI_EVENT_RESPONSE_NONE;
auto hook_id = plugin->make_hook_id(info);
plugin->ret_hooks.erase(hook_id);
return VMI_EVENT_RESPONSE_NONE;
}
Наконец, функция перезаписи базового и текущего приоритетов для заданного потока:
bool setpriority::set_thread_priority_fields(drakvuf_t drakvuf, addr_t thread)
{
vmi_lock_guard vmi(drakvuf);
if (VMI_SUCCESS != vmi_write_8_va(vmi, thread + offsets[KTHREAD_BASE_PRIORITY], 4, &cfg_base_priority))
{
PRINT_DEBUG("[SETPRIORITY] Failed to set KTHREAD_BASE_PRIORITY\n");
return false;
}
if (VMI_SUCCESS != vmi_write_8_va(vmi, thread + offsets[KTHREAD_PRIORITY], 4, &cfg_priority))
{
PRINT_DEBUG("[SETPRIORITY] Failed to set KTHREAD_BASE_PRIORITY\n");
return false;
}
return true;
}
Проверка результатов
Результат проверки Pafish после всех вышеперечисленных манипуляций представлен на рисунке ниже.
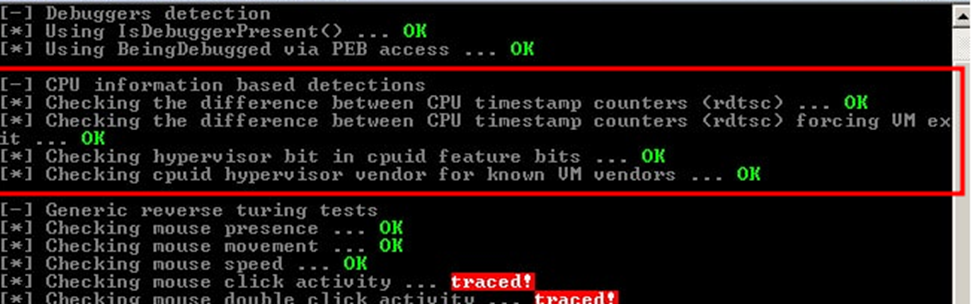
Рисунок 10. Результат запуска Pafish на VM
Ограничения подхода и возможности для доработки
Безусловно, описанный подход неидеален и не покрывает все потенциально возможные сценарии. Он представляет собой скорее proof of concept сокрытия гостевой VM от простых вариантов временных атак.
Важно иметь фиксированную частоту процессора и ограничить используемые C-состояния до C0. Иначе время переключения между гостевой VM и гипервизором может сильно варьироваться, что скажется на стабильности работы алгоритма. Кроме того, на текущий момент отсутствует синхронизация офсетов между ядрами VM, из-за чего в некоторых случаях проверки могут не проходить.
Специалист отдела обнаружения вредоносного ПО экспертного центра безопасности Positive Technologies (PT Expert Security Center)