
Аномалии и предиктивная аналитика
Безопасность - главный приоритет Росатома, а сбои в работе оборудования могут привести к серьезным материальным потерям. Чтобы определять возможные поломки на старте, специалисты по анализу данных (data scientists) компании «Цифрум» (Росатом) при реализации ряда промышленных проектов для предприятий атомной отрасли внедрили ИТ-решение, детектирующее вероятные аномалии в момент их зарождения. В его основе – машинное обучение и анализ данных.
1. Введение. Обзор пула проблем
Искусственный интеллект в целом, машинное обучение и развивающиеся благодаря ему возможности прогнозирования дают уникальную возможность для улучшения и повышения качества процессов во многих отраслях, например, повышение КПД оборудования и сокращение числа аварийных ситуаций на производствах.
На самом деле технология предиктивной аналитики, о которой пойдет речь в данной статье, успешно применяется абсолютно в любой сфере или области знаний, где необходимо анализировать данные, имеющие зависимости как между сигналами, так и от прошлых значений, и вовремя фиксировать нарушения зависимостей и отклонения от паттернов нормального поведения системы. Благодаря предиктивной аналитике, развивается и инженерия – например, оборудование дорабатывается, чтобы использовать его можно было без или при минимальном контроле со стороны человека.
2. Специфика машинного обучения в атомной отрасли
Работа с данными вообще и с данными, собираемыми во время эксплуатации оборудования (промышленными данными), в частности – необходимость для атомной отрасли, но у нее есть своя специфика. Во-первых, есть существенные ограничения безопасности - алгоритм должен быть максимально простым и прозрачным, чтобы исключить риски и повысить доверие пользователей. Далее, критическим требованием к разработчикам становится импортонезависимость - особенно сегодня. При этом работу усложняют такие факторы, как различие контуров разработки и применения решения, проблема несовершенства и необходимости часто сложной предварительной обработки промышленных данных, и “трудности перевода” в коммуникации между командой аналитиков данных и технологическим персоналом, напрямую взаимодействующим с оборудованием.
АЭС накапливают огромные массивы данных, обработать которые в ручном режиме попросту невозможно. Все сигналы можно разделить на сигналы АСУ ТП, сигналы локальных систем диагностики и контроля, данные лабораторных исследований, ручные замеры и иные данные. Поэтому также востребованной задачей является их систематизация, агрегация и снижение размерности (задача уменьшения количества сигналов) для снижения нагрузки на персонал, но вернемся к основной теме.
Благодаря технологии предиктивной аналитики удается не только прогнозировать и избегать многие поломки и задержки в работе, но и приблизиться к тому, чтобы оборудование могло работать в режиме «обслуживания по состоянию» (без иногда ненужных плановых остановок и ремонтов), что существенно снижает издержки на ремонт и оптимизирует расходы по поддержанию оборудования и инфраструктуры в требуемом состоянии.
3. Технология предиктивной аналитики в работе оборудования
Ключевым типом данных, которые используются в предиктивной аналитике, является временной ряд – упорядоченная последовательность точек, признак, измеряемый через одинаковые и постоянные временные интервалы, характеризующий происходящий физический процесс. Временной ряд предполагает зависимость наблюдений, что дает возможность опираться на предыдущие показания для оценки и прогнозирования будущих состояний, и это главное отличие такого типа данных от классических табличных данных. Временной ряд сводит процесс к ключевым измеримым характеристикам, что позволяет ставить и решать задачи с применением методов машинного обучения.
Следующим важным понятием является поиск аномалий во временном ряду - это задача обнаружить необычное поведение временного ряда, какое-то несвойственное для процесса поведение.
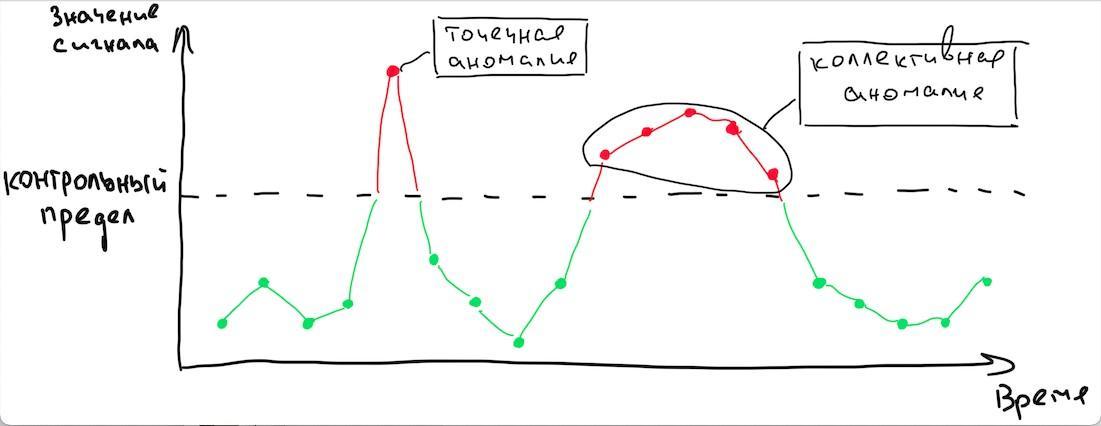
Рис.1. Пример временного ряда с детектированными аномалиями
Временные ряды – не уникальное для промышленности понятие, этот тип данных используют и в экономике, и в ритейле, и в кибербезопасности (и не только), поэтому некоторые методы и алгоритмы работы с такими данными легко тиражируются на различные отрасли.
При работе с временными рядами выделяются различные задачи, вот несколько из них, о которых мы поговорим подробнее: прогнозирование, классификация, кластеризация, агрегация (сведение временного ряда к набору признаков и описание процесса с их помощью) и поиск тех самых аномалий. Результатом их решения становятся модели или алгоритмы, которые в дальнейшем можно использовать в предиктивной аналитике.
В задаче прогнозирования от исследователя требуется найти функцию, которая бы на горизонте прогнозирования предсказывала значения, приближенные к реальным. Визуализация результатов работы алгоритма для такой задачи выглядит следующим образом.
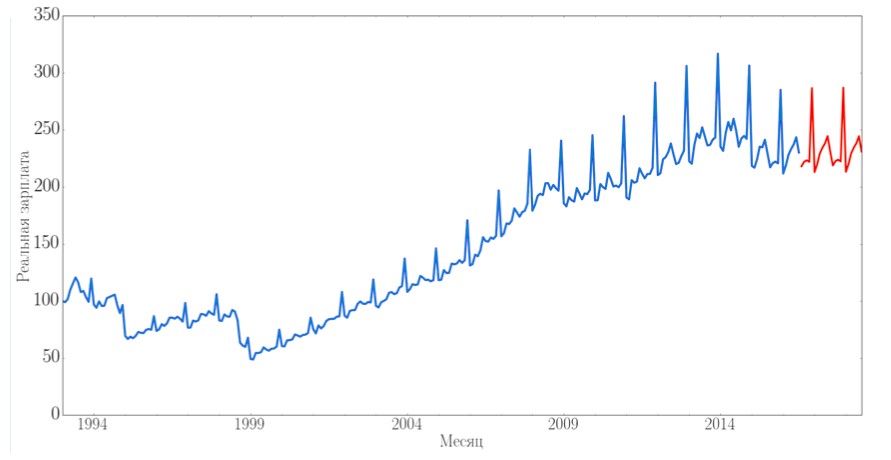
Рис. 2. Результаты работы модели прогнозирования (красным - прогноз, синим, исторические данные для обучения и тестирования модели)
Благодаря наличию данных о работе оборудования в различных режимах можно создавать достоверные модели с широкой областью применения и прогнозировать показатели работы для различных режимов в том числе для случаев отклонения режимов работы от нормального. Это важно и полезно при решении задачи определения остаточного ресурса оборудования, когда режим уже не является нормальным, но оборудование все равно может проработать, например, до следующей плановой остановки.
Еще одна задача - задача классификации временных рядов. Это не классическая задача классификации, когда нам нужно для каждой временной точки или каждого момента времени определить его класс, в данном случае нам нужно определить класс целого временного ряда!
Наглядный пример классификации или разделения временных рядов по типам работы оборудования представлен на рисунке ниже (рисунок 3).
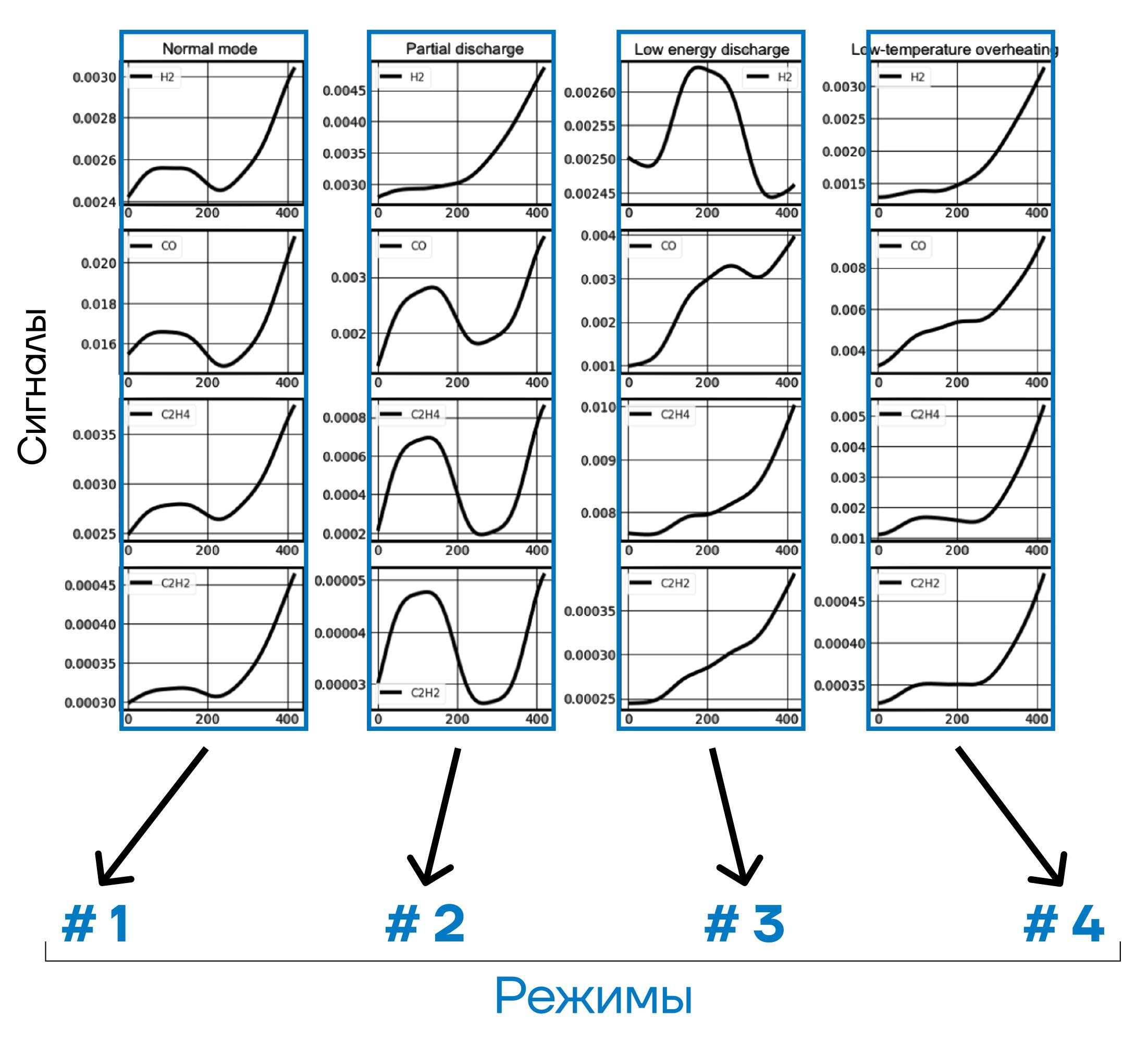
Рис. 3. Пример различных режимов (классов) в работе оборудования
Если классы, к которым необходимо отнести данные (временные ряды), не известны заранее, а все, что есть у нас это куча перемешанных временных рядов (рисунок 4), то можно решать задачу кластеризации. Она по сути не отличается от задачи классификации - нам по-прежнему надо разделить режимы/состояния или поделить временные ряды на группы, однако делается это уже с помощью совсем других методов - методов кластеризации.
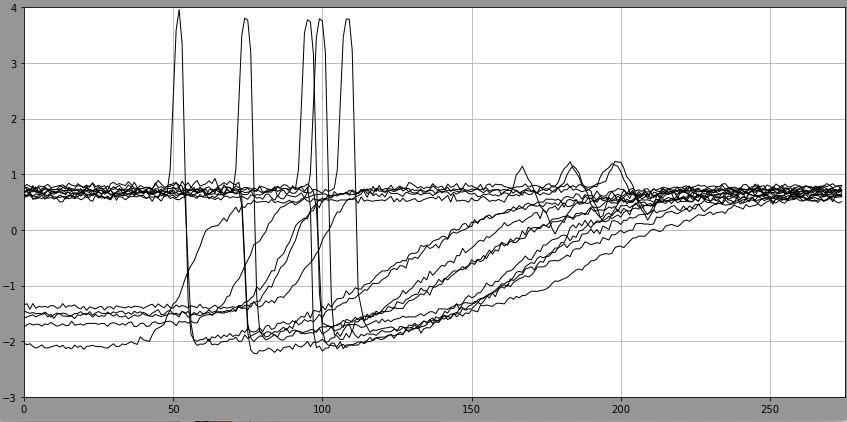
Рис. 4. Исходные данные отсюда, синтезированные для разных режимов работы АЭС
Данные после кластеризации на 3 кластера представлены на рисунках ниже.
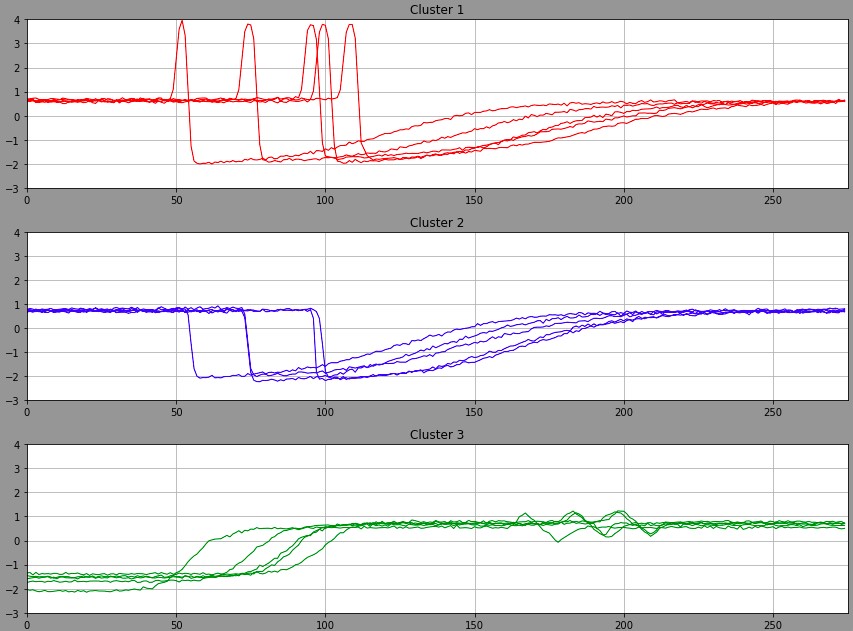
Рис. 5. Пример разделения исходных данных на кластеры
Еще одна важная, хотя и вспомогательная задача - агрегация временных рядов или выделение из временных рядов каких-то признаков, которые могут содержать наиболее ценную информацию, чтобы нам не пришлось работать со всем временным рядом, а мы могли выделять из него самые важные характеристики, например: максимальное и минимальное, медианное и среднее значения, число пиков. Подобная схема агрегации представлена на рисунке 6.
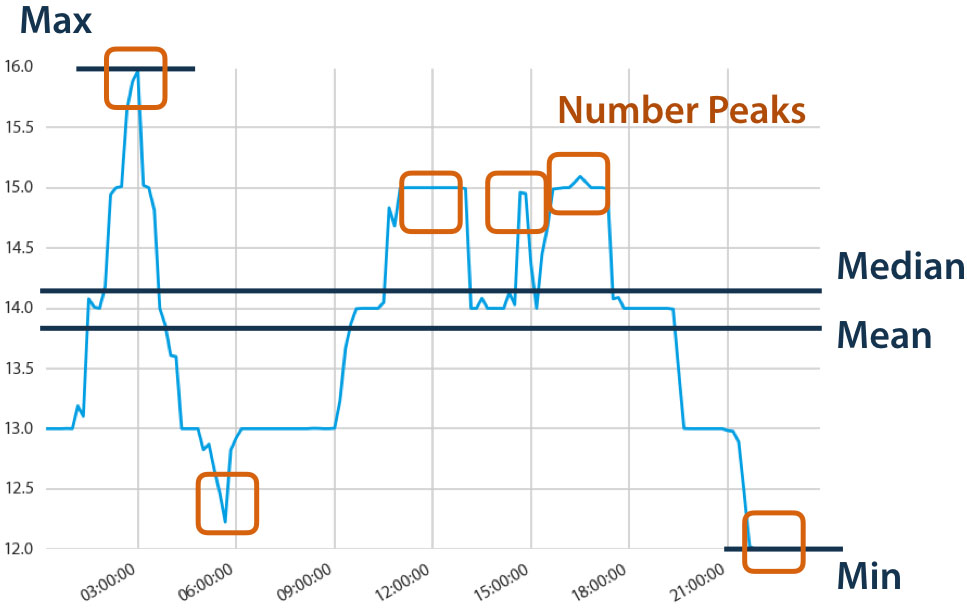
Рис. 6. Графическое описание процесса выделения признаков из временного ряда
Следующая задача, которая является достаточно сложной и популярной – поиск аномалий, то есть тех данных, которые отражают какое-либо не свойственное нормальной работе оборудования поведение, возможную поломку или сбой. Визуализировав результаты работы алгоритмов поиска аномалий, мы увидим что-то в этом роде:
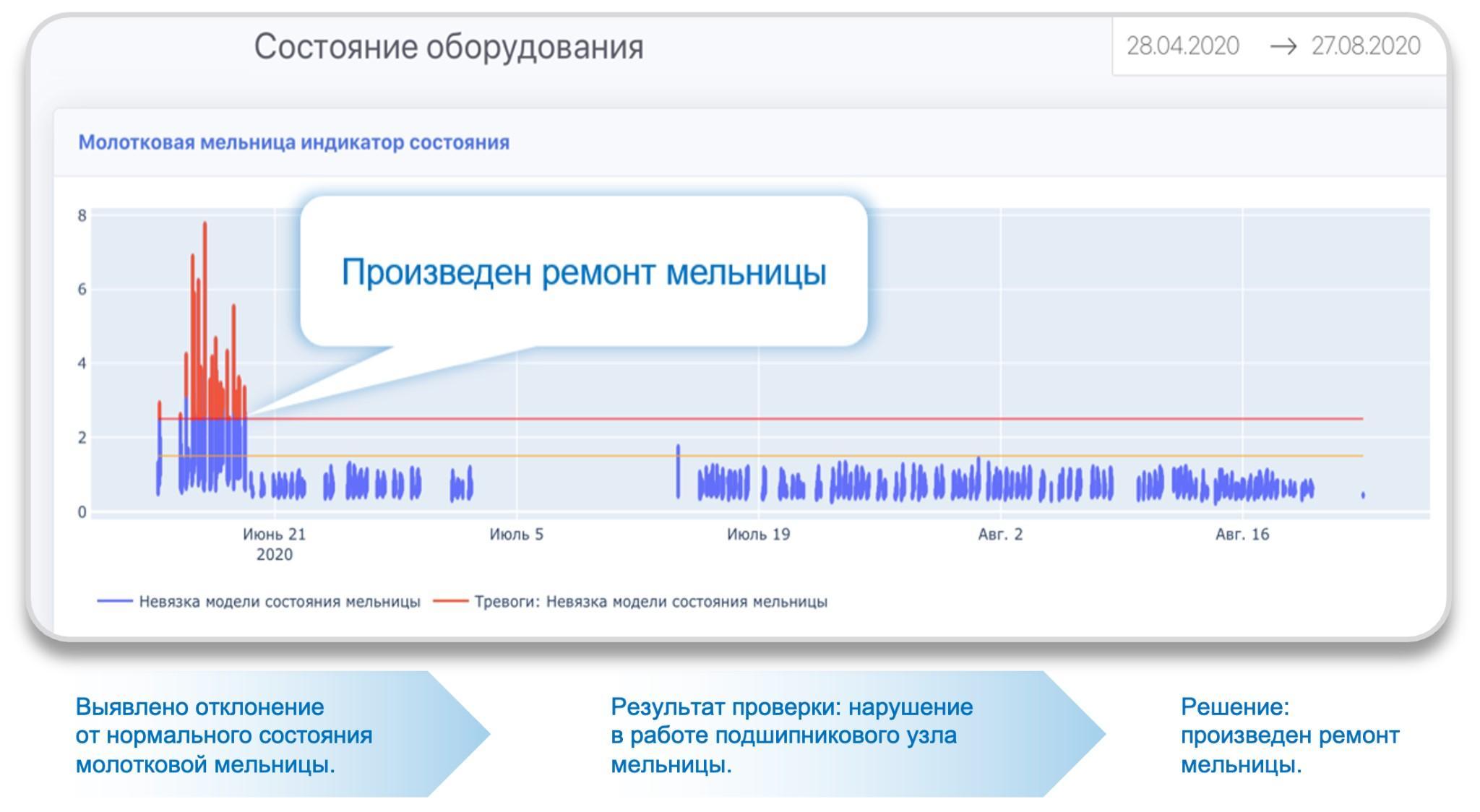
Рис. 7. Графическое представление аномалии
Как часто бывает в машинном обучении - чем больше исторических данных об аномалиях собрано, тем проще обнаруживать неполадки и принимать меры по их устранению. Логика обнаружения аномалий одного из распространенных алгоритмов состоит в выявлении участков, где прогноз - результат работы модели прогнозирования, ощутимо не совпадает с реально имеющимися данными. Прогнозные модели при этом обучаются на данных нормального режима работы, поэтому плохо работают для аномальных данных.
4. Кейс предиктивной аналитики в Росатоме
В процессе работы над одним из проектов был создан алгоритм мониторинга эксплуатации и обнаружения неисправностей электролизеров на производстве. Для этого специалисты использовали показатель среднего значения уровня электролита в коллекторах. Далее рассчитывались вероятности изменения этого уровня за разные периоды времени до текущего момента. В качестве параметров процесса мы использовали данные об уровне электролита, напряжении, давлении в коллекторах отходящих газов и другие.
Разработанное решение автоматически ищет скрытые дефекты, возникающие в ходе эксплуатации, визуализирует информацию об аномалии и оповещает оператора для принятия решений.
5. Заключение
Подведем итоги. Для работы с большими массивами данных человеческого ресурса не может и не должно хватать. Наиболее эффективным способом определять аномалии, фиксировать и давать рекомендации по устранению их на раннем этапе является машинное обучение и анализ данных, а также алгоритмы поиска аномалий на их основе. Задача аналитиков – создание таких алгоритмов, настройка пайплайнов предварительной обработки данных и постпроцессинга (настройка чувствительности алгоритмов, настройка соотношения между ложными срабатываниями алгоритмов и пропуском целей, другими словами - «отсеять» все ненужное и заставить алгоритм доносить сигналы только о принципиально важных сбоях), опираясь на практический опыт (свой и технологического персонала). Эффективная работа таких алгоритмов приводит к существенной экономии, к более долгому сроку эксплуатации оборудования и к стабильной работе оборудования атомной отрасли, так как все потенциальные неисправности устраняются еще на этапе, когда проблема не критична.
Юрий Кацер - руководитель направления предиктивной аналитики в Блоке цифровизации ГК «Росатом»
Реклама. www.rosatom.ru