
Технологии успешного SOC
Что первым приходит в голову при построении какого-либо процесса информационной безопасности? Конечно же, стандарты. В перечне NIST (National Institute of Standards and Technology — американский национальный институт стандартизации, аналог Госстандарта) есть методологии на любой вкус. Взять, например, NIST 800-61 по управлению ИБ-инцидентами, который содержит отличную методологию. Но что делать техническим специалистам, желающим наладить этапы подготовки, детектирования, обогащения и устранения.
О том, чем руководствоваться при выборе тех или иных источников данных, на какие поля обращать внимание, откуда черпать вдохновение при написании правил, рассказывают руководитель отдела развития продукта Security Vision Данила Луцив и генеральный директор компании Руслан Рахметов.
Часть 1. Тактика и стратегия сбора событий
Долгое время информационная безопасность больше напоминала гадание, нежели научное знание. На чем основываются гипотезы аналитиков Центра мониторинга и реагирования на киберугрозы (Security Operation Center, SOC)? В основном на личных предположениях. Иногда они были точным попаданием, но чаще всего создавали большое количество ложных срабатываний и не детектировали реальных вторжений.
Одной из самых знаковых статей в информационной безопасности за последние годы стал материал Гитхабификация Информационной Безопасности Джона Ламберта. Можно по-разному относиться к информационной базе данных Mitre ATT&CK, говоря о ее неполноте и других недостатках. Но хотим мы того или нет, ATT&CK стала общим языком, на котором могут общаться все специалисты информационной безопасности, когда речь идет о процессе управления инцидентами. В результате важен даже не ATT&CK-фреймворк как таковой, а машиночитаемые описания на хостинге Mitre GitHub, включая модели данных и другие свободно распространяемые проекты вроде Caldera, которые строятся на единой методологии.
Сообщество быстро подхватило такой подход, и сейчас уже сложно представить проекты в цифровой криминалистике и реагирования на инциденты (Digital Forensics and Incident Response, DFIR), в которых не упоминалась бы атрибуция. Отчеты о проникновении, правила корреляции, дата-сеты событий, воспроизводящие записи действий атакующего, скрипты, эмулирующие вредоносную активность и ноутбуки хантов для поиска сложных атак — все это уже имеет соответствующие тэги и позволяет сформировать комплексное представление о том, как именно происходит атака, а также какие источники и правила нужны для ее детектирования. Наконец в сферу ИБ приходит истинно научный подход, обладающий свойством воспроизводимости экспериментов.
Что же могут вынести рядовые специалисты по информационной безопасности из подобных проектов? Давайте попробуем за несколько статей разобраться в том, что интересного происходит в сообществе в области DFIR.
Каждая компания, которая сталкивается с необходимостью мониторинга событий безопасности, решает одни и те же задачи: каким источникам данных уделить внимание в первую очередь, какие политики логирования выбрать, какие инструменты сбора логов использовать. Немало SIEM-внедрений потерпели неудачу уже на этом этапе, утилизировав всю доступную лицензию дорогостоящего инструмента на малозначительные для поставленных целей данные. Попробуем найти ответ на эти вопросы на просторах интернет.
Twitter был и остается одной из самых главных соцсетей для обмена знаниями cyber-комьюнити. С него мы и начнем. Эксперт по кибербезопасности Флориан Рот (Florian Roth), автор IoC-сканера Loki и множества других DFIR-проектов, предлагает такую методологию приоритизации источников:
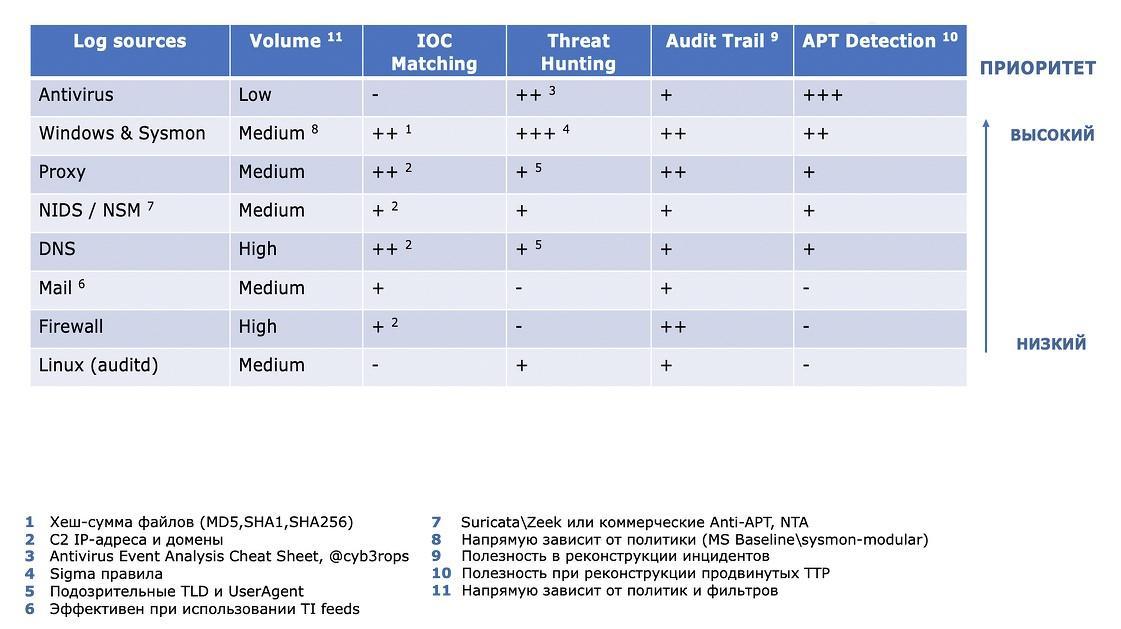
Источник: Twitter эксперта по кибербезопасности Флориана Рота (Florian Roth), перевод — Данила Луцив, Security Vision
Безусловно, таблица имеет потенциал для критики. Однако многие практики ИБ подтверждают, что компании часто пренебрегают должной обработкой первой тройки, уделяя излишнее внимание таким тяжеловесным источникам, как логи межсетевых экранов. Мы же не будем повторять этих ошибок и отдадим приоритет в рассмотрении «лидерам» таблицы.

Главная миссия DevOps: сначала вытащи логи, а потом... просто вытащи логи
Логи подключений прокси-сервера несут множество полезной информации для расследования инцидентов, данный источник прост в подключении и не требует фильтрации. Стоит разве что отметить важность такого поля, как User Agent — по нему можно идентифицировать обращения в интернет целого ряда вредоносного ПО. Аналитика по антивирусам от уже известного нам Флориана Рота приведена на сайте Nextron Systems, и разобраться в ней не составит труда. А вот журналы событий Microsoft Windows все еще представляют сложность для многих специалистов по кибербезопасности. Попробуем разобраться, что именно и как стоит мониторить.
Для того, чтобы получить события Windows, первым делом необходимо активировать их запись через групповую политику. Для систематизации подхода к логированию подойдет ATC, к которому мы будем еще не раз возвращаться в нашем цикле, а точнее его разделы Logging Policies и Data Needed. На этих ресурсах, а также на репозитории проекта, собраны различные политики логирования, способы их активации, id событий и те их свойства, которые понадобятся аналитику. Проект позволяет полностью выстроить логическую цепочку из политик логирования, данных из событий безопасности, Sigma-правил детектирования атак и скриптов эмуляции атомарных действий атакующих.
Говоря о журналах безопасности Windows, нельзя не сказать об одном из самых известных проектов в этой области — Windows Security Log Encyclopedia. На ресурсе содержится, пожалуй, самое подробное описание практически всех возможных событий безопасности, снабженное примерами, описаниями значений полей и расшифровками ряда внутренних идентификаторов.
На вопросы «Что?» и «Как?» в сфере сбора событий безопасности отвечает в своих материалах Джессика Пейн (Jessica Payne). Ее статья Monitoring what matters, несмотря на то, что была написана в 2015 году, не теряет своей актуальности. Многие компании пренебрегают механизмомом Windows Event Forwarding (WEF), хотя он позволяет штатными средствами решить проблему централизованного сбора событий безопасности, имеет механизм фильтрации, легко масштабируется и обладает множеством других полезных функций.
Продолжает тему централизованного сбора событий через WEF проект Windows Event Forwarding Guidance специалистов по информационной безопасности американской компании Palantir. В нем содержатся не только групповые политики, позволяющие настроить централизованный сбор событий, но и программная библиотека, значительно расширяющая возможности данного механизма. Стоит также обратить внимание на Event Forwarding Guidance, взявший за основу рекомендации по мониторингу от Агентства национальной безопасности США (АНБ).
Вполне резонный вопрос, почему в такой чувствительной материи, как информационная безопасность, стоит доверять АНБ и Palantir — организациям не самым открытым и дружелюбным. Понять применимость тех или иных политик мониторинга помогают датасеты (сохраненные события безопасности, записанные в процессе реальных действий атакующего).
Наиболее интересными с точки зрения объема датасета и атрибуции являются Evtx Attack Samples и Security Datasets (ex. Mordor). Датасеты могут быть с легкостью загружены в SIEM систему для проверки существующих правил корреляции, использоваться для написания новых правил или быть частью базы знаний SOC подразделения.
Вендеро-специфичным, но не менее любопытными для исследования являются датасеты, созданные компанией Splunk.
Буквально за несколько минут воспроизвести на своем компьютере инфраструктуру, настроенную SIEM-систему, инструменты эмуляции атак и загрузить датасеты позволяет проект Detection Lab. Лабораторный стенд использует свободное и открытое ПО Vargant, что позволяет ему работать практически с любой средой виртуализации, либо развернуть среду в облачной инфраструктуре.
Как обойтись без утилиты Sysmon компании Microsoft в статье про события безопасности? Является ли данный инструмент панацеей для детектирования любых атак — безусловно нет. Однако он довольно сильно расширяет возможности штатного детектирования. Внедрять его первым делом, еще до того, как вы начали собирать ID 4688 с логированием командной строки, конечно же не стоит. Но те хосты, которые подвержены серьезному риску компрометации, стоит добавить в группу дополнительного мониторинга, в том числе с использованием sysmon. Например, компьютеры HR отдела, обрабатывающие большое количество файлов, поступающих извне.
Помочь разобраться с файлами конфигураций и применить атрибуцию Mitre ATT&CK сразу на этапе детектирования позволяет проект Olafhartong/sysmon-modular. Если это ваше первое знакомство с sysmon, то стоит начать с цикла статей Olaf Hartong о Sysmon. В нем автор подробно рассказывает о типах собираемых данных, способах массового развертывания, атрибуции и многом другом.
И последним, но далеко не по значению, упомянем сам репозиторий MITRE ATT&CK. В нем собраны не только сам Attack-navigator и Python скрипты для работы с контентом mitreattack-python, но и Cyber Analytics Repository - база аналитики, позволяющая выстроить правила детектирования на основе ATT&CK (правила, правда, в основном написаны на Splunk-ориентированном языке SPL). Также стоит отметить, что сама Mitre в дорожной карте развития своего фреймворка решила уделить больше внимания именно источникам данных. Так на свет появился Attack Datasources. Не просто техники и тактики, но и источники, модели данных и взаимосвязи между объектами - все это создает полный жизненный цикл аналитики событий информационной безопасности.
Встроить любые модели и средства обогащения, включая созданные в рамках ATT&CK-сообщества, в процесс обработки инцидентов информационной безопасности поможет платформа Security Vision IRP/SOAR. Обширная база знаний, снабженная датасетами событий атак, механизм атрибуции инцидентов, а также инструментарий оценки зрелости детектирования и возможности запуска атомарных скриптов генерации атрибутированных событий. Они уже доступны в Security Vision.
Часть 2. Детектирование атак. Проектирование жизненного цикла правил корреляции
Итак, выше мы рассмотрели рад проектов, которые призваны создать основу для успешного Detection Engendering – сформировать приоритеты для источников событий информационной безопасности; наладить их сбор, а также проанализировать, что именно могли бы содержать эти события в случае детектирована тех или иных тактик на примере датасетов симуляций атак. Теперь с достаточно большой вероятностью, хотя-бы при port-mortem анализе, у нас будет достаточно информации для формирования цепочки событий.
Однако назвать эффективным Security Operations Center (SOC), который не способен на ранних этапах детектировать вредоносную активность, язык не поворачивается. По этой причине следующим после обеспечения достаточности данных можно уверенно назвать этап формирования правил корреляции. Практически все компании, приобретавшие себе коммерческие SIEM-продукты, проходили все стадии жизненного цикла встроенного контента правил корреляции: «восторг», «отрицание», «гнев», «торг», «депрессия», «принятие», и, наконец, «отключение» встроенных правил и написание собственного контента.
Какие же концепты, существующие сегодня, дают специалистам SOC источники вдохновения на написание собственных правил детектирования? Мы уже говорили о том, что без Mitre ATT&CK сложно было бы представить всю существующую сегодня экосистему взаимосвязанных проектов в области практической информационной безопасности. И снова, важны не сами теги техник и тактик, а подход единого вендоро-независимого языка, описывающего технические принципы, которые лежат в основе как самих атак, так и методов их детектирования. Под общим языком мы понимаем те знания и структуры, которые можно выложить на GitHub или другой ресурс для совместной работы. Тут стоит вспомнить статью Антона Чувакина, которая для многих открыла термин Detection-as-Code. В статье говорится о необходимости внедрения подхода к написанию и тестированию правил детектирования, аналогичного тому, что используется в современной разработке программного кода.
Скептики могут сказать, что эйфория от Everything-as-Code проникла уже даже в консервативные головы безопасников. Однако сложно не увидеть явные плюсы такого подхода: версионность, обеспечение качества (Quality Assurance, QA) созданных правил детектирования, модулярность и повторное использование уже написанных блоков, кросс-вендорность и прочие преимущества внедрения автоматизированного цикла CI\CD — непрерывной интеграции или поставки (Continuous Integration or Continuous Delivery). Долгие годы во многих SIEM-системах создавать правила физически можно было только в графическом интерфейсе, без возможности копирования и редактирования блоков. По этой причине подобный подход вызывал разрыв шаблона и непонимание у многих участников отрасли, однако и существующие решения уже не могут соответствовать современным вызовам ландшафта киберугроз.
Созданные сообществом правила детектирования появились еще до ATT&CK фреймворка. Далеко не первым, однако одним из самых известных и до сих пор активно развивающихся проектов является Yara Rules. Его инструментарий представляет собой набор правил детектирования вредоносного программного обеспечения на основании совокупности строк и логических выражений, поиск которых производится в анализируемых файлах. Не удивительно, что этот язык появился в стенах широко известной компании VirusTotal. Yara-правила фактически стали стандартом для TI-обмена подобного рода информацией и широко используются в атрибуции, а также при Threat Hunting (циклическом поиске следов заражения или взлома, которые нельзя обнаружить стандартными средствами защиты).
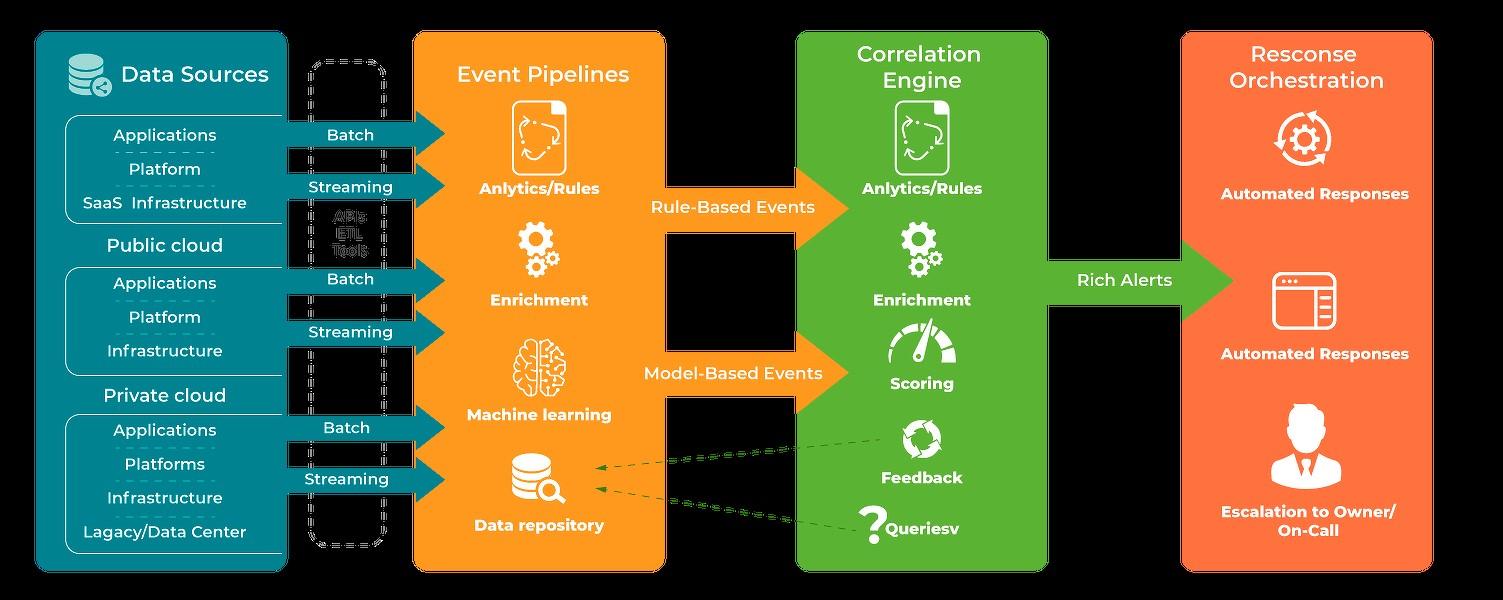
Пайплайн данных: генерация событий, агрегация информации, аналитика данных, сбор бизнес-пайплайна на базе ответов после отработки алгоритмов
Однако сфера форензики и анализа вредоносного ПО все же далека от массового профессионала ИБ. Большинство специалистов по кибербезопасности привыкли доверять антивирусам хотя бы при поиске в строчках бинарных файлов паттернов вредоносного ПО. По этой причине проект Yara, хоть и довольно хорошо известен, не претендует на звание всеобщего языка сотрудников SOC. Не менее полезными, однако столь же нишевыми можно назвать проекты, связанные с правилами детектирования сетевых атак на основе таких свободно распространяемых NIPS, как Snort и Suricata.
Безусловно вдохновляясь описанными выше инициативами, создатели проекта Sigma задумывали свою идею как «Yara для логов», и такой подход лег на крайне благодатную почву зародившегося ATT&CK Community. Если вкратце, то подобно другим Everything-as-Code-решениям, Sigma представляет собой данные, сериализованные в формате YAML. Такой подход позволяет как непосредственно импортировать данные правила в SIEM-системы (напрямую или через конверторы), так и работать с ними как с базой знаний. Все правила снабжены референсами на исследования специалистов по кибербезопасности, а также тэгами, которые позволяют понять, к каким именно техникам, тактикам и процедурам относятся данные детектируемые атаки. Часто Sigma-правила в своих тегах ссылаются на собственный Mitre-репозиторий правил детектирования, называемый Mitre CAR. Однако 541 существующая ATT&CK техника покрывается 3 781 правилом детектирования, 2 094 из которых реализованы в Sigma и еще примерно по 700 в Splunk и Elastic SIEM, а собственным CAR-идентификатором обладают лишь 178 техник.
Стоит отметить, что во встроенной поддержке на стороне SIEM-систем для интеграции Sigma-правил нет необходимости. Репозиторий Sigma содержит штатную утилиту Sigmac, которая позволяет конвертировать правила в запросы множества SIEM-систем, таких как Arcsight, Qradar, Splunk и многих других. Также ресурс Uncoder от компании SOC Prime позволяет не только конвертировать созданные сообществом правила, но и преобразовывать одни проприетарные правила в другие, что будет крайне полезно, например, при смене SIEM-вендора.
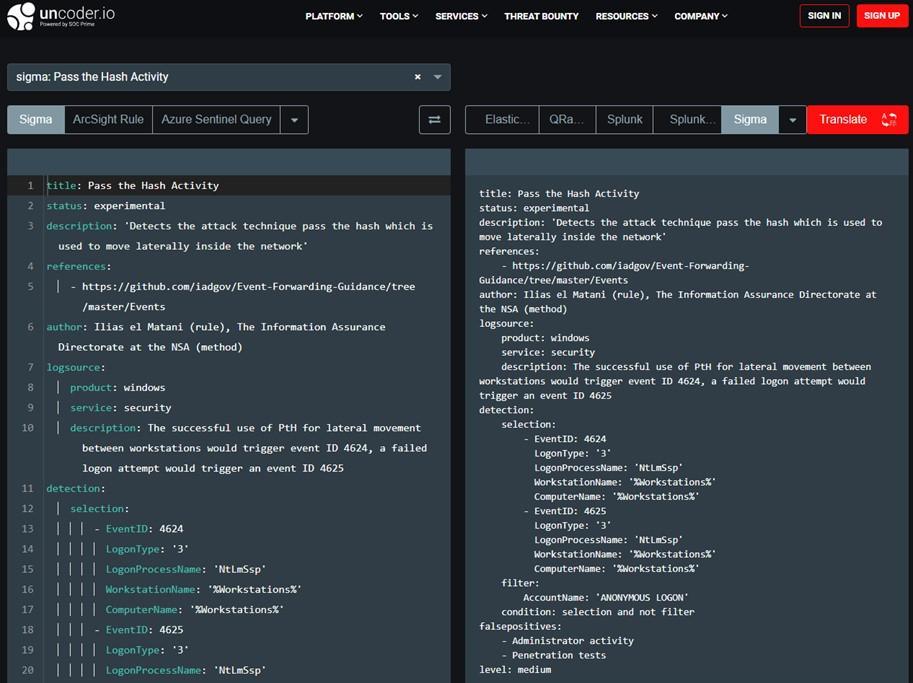
Uncoder.io — бесплатный и уже готовый UI от компании SOC Prime для конвертации
Развивая функционал Sigmac в направлении Detection-as-Code, компания 3CORESec создала проект SIEGMA, использование которого позволяет реализовать автоматические pipeline-внедрения правил детектирования непосредственно в SIEM. К сожалению, на текущий момент поддерживаются только Elastic SIEM и Azure Sentinel.
Те же энтузиасты из компании 3CORESec стали авторами инструмента Automata, который уже максимально приближается к званию управления полным жизненным циклом правил детектирования. Описанный выше SIEGMA-конвертор, получающий Sigma-правила из внешних репозиториев и конвертирующий их в запросы Elastic SIEM, работает в данном проекте в связке с Mitre Caldera, воспроизводящим атомарные действия атакующих. Задачей Automata является обнаружение соответствий внедренных правил и фактических детектирований после прохождения автоматических тестов. Ложноположительные и ложноотрицательные классификации аллертируют в системе для формирования адаптации правил перед внедрением их в промышленную эксплуатацию.
Однако подобную связку не так часто можно увидеть в реальной инфраструктуре. Наиболее часто для тестирования правил корреляции применяется созданная компанией Red Canary библиотека скриптов эмуляции техник атакующего Atomic Red Team. Библиотека содержит более 800 атомарных тестов, структурированных на основании Mitre ATT&CK-техник и снабженных референсами на соответствующие исследования.
Не все компании пока готовы к столь кардинальному шагу как внедрение автоматизированных Adversary Simulation в своих инфраструктурах. Для подобного проекта должна быть создана соответствующая, релевантная продуктиву, тестовая среда, а нужные процессы согласованы со всеми подразделениями. На первоначальных этапах построения жизненного цикла правил детектирования можно обойтись и более простыми инструментами.
Например, приложения Zircolite и Сhainsaw предоставляют возможность протестировать имеющиеся SIGMA-правила непосредственно на evtx-логах, даже без участия SIEM-системы. Это позволяет оценить наличие в инфраструктуре потенциальных источников ложноположительных срабатываний еще до внедрения правила. Немаловажно также отметить, что инструменты отлично работают и с Security Datasets, коллекциями событий информационной безопасности. Zircolite поддерживает поиск не только в evtx, но и в json (формате, который используется в Security Datasets). Это дает возможность проверить собственные или созданные энтузиастами правила на реальных атаках даже без необходимости воспроизведения их вживую.
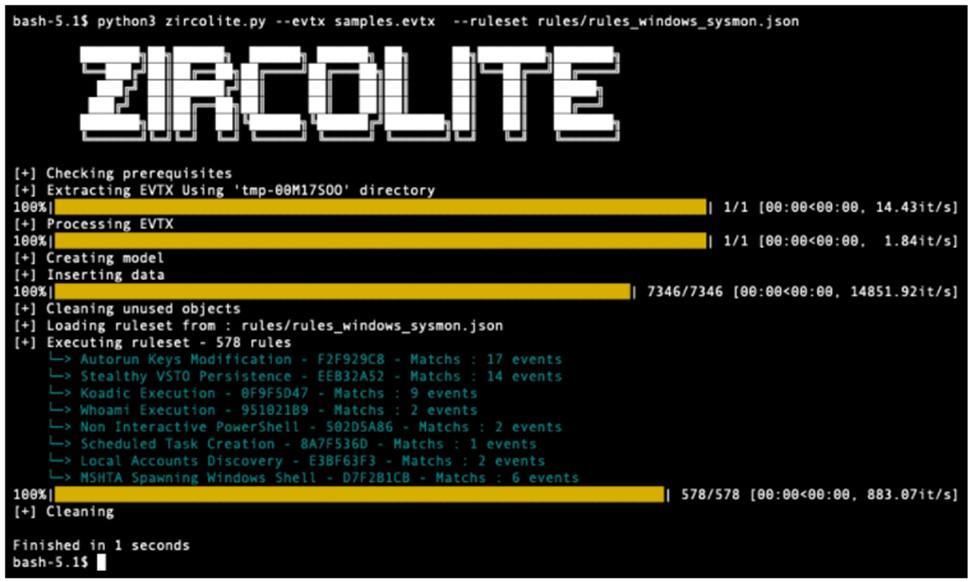
Zircolite — автономный инструмент, который позволяет протестировать имеющиеся SIGMA-правила непосредственно на evtx-логах, даже без участия SIEM-системы
Последний проект, о котором мы уже упоминали в предыдущей статье, это Atomic-Threat-Coverage. Помимо уже описанных ранее разделов данного проекта, посвященных logging policies и data needed, сотрудники SOC могут найти здесь собственно правила детектирования Detection Rules в Sigma и других форматах. Кроме того, тут размещены референсы, известные условия ложно-положительных срабатываний и скрипты эмуляции атомарных действий атакующего, которые покрываются данным детектированием. В общем смысле это является прообразом карточки инцидента, а точнее тем, что в зарубежной литературе называется Alerting and Detection Strategies (ADS).
От аналитического отчета до правила детектирования, от необходимой политики логирования до скриптов эмуляции — проекты ATT&CK-сообщества сегодня раскрывают практически полностью тему Detection Engineering. Конечно, они далеки от совершенства и часто больше похожи на Proof-of-Concept, нежели на реально работающие инструменты. Те же Sigma-правила пока что лишены столь важных функций, как join-операторы и агрегации событий. Однако можно с уверенностью сказать, что подобный индустриальный подход к созданию и тестированию правил детектирования событий информационной безопасности переводит Security Operations Center на качественно новый уровень.
В заключение ответим на вопрос многих SOC-специалистов, имеющих сейчас в арсенале лишь несколько десятков правил детектирования и уже сталкивающихся с проблемой ложноположительных срабатываний: «Для чего нужно такое избыточное количество правил, количество которых уже перевалило за тысячу, если существующая команда SOC не справляется и с существующей загрузкой?».
Ответ кроется в статистике и в самой парадигме детектирования: false positive — не тот показатель, который нужно стремиться снижать до нуля. Данный подход проиллюстрировал в своей презентации технический директор SpecterOps Джаред Аткинсон (Jared Atkinson). Ее основная мысль заключается во фразе: «Ложноположительные — это плохо, но ложноотрицательные — хуже». Снижая количество ложноположительных срабатываний, ориентируясь лишь на правила, которые на 100% идентифицируют вредоносную активность (вроде создания неизвестного администратора домена или известные функции mimikatz в командной строке), мы отсекаем огромное количество потенциальных обнаружений широко известных техник атакующего. Мы начали данную статью со ссылки на статью Антона Чувакина, и мистер Джаред Аткинсон также ссылается на мысли этого кибер-евангелиста, однако на статью On Threat Detection Uncertainty. Господин Чувакин, как и многие другие участники кибер-сообщества, занимающиеся темой Detection Engineering, оперирует термином uncertainty (неопределенность). И для детектирования угроз в условиях неопределенности использовать подход строгих и однозначных правил крайне нецелесообразно. Вместо этого он предлагает следующие решения:
- Improve alert triage — улучшите возможности анализа событий, обеспечив получение как внутреннего, так и внешнего контекста тех объектов и индикаторов, которые вовлечены в потенциальный инцидент.
- Use multi-stage detection — старайтесь смотреть на происходящее в ретроспективе, ведь события, заслуживающие внимания, редко происходят обособленно. Вокруг них существует набор связанных событий (логов авторизации, сетевых соединений, цепочек процессов и так далее), которые в другой ситуации не представляли бы для нас интерес. Однако сейчас из них формируется сценарий развития инцидента, дающий аналитику возможность понять ту стадию, на которой он сейчас находится. А главное, те взаимосвязанные активы, которые потенциально вовлечены в инцидент и могут быть (или уже) скомпрометированы.
- Split bad from interesting — введение скорингов и приоритетов, отделяющих точно вредоносную активность от потенциально достойной внимания, аномальной активности, которая требует участия Threat Hunting-инструментов и соответствующего опыта исследователей.
Безусловно, выстроить подобную систему без внедрения средств автоматизации и оркестрации практически невозможно. Ни одна компания, даже MSSP, не сможет обрабатывать такие форсированные правила детектирования. Только SOAR-платформы, такие как Security Vison, могут на основании плейбуков обогащений производить автоматический анализ инцидентов, эскалируя на аналитика лишь те из них, которые удовлетворяют установленной критичности полученных данных и являются связанными с уже имеющимися событиями и/или индикаторами в системе. Также лишь SOAR-платформы сегодня позволяют распределять инциденты по линиям SOC в зависимости от загруженности и компетенции сотрудников.
Часть 3. Стратегии и сценарии реагирования
Источники и правила детектирования довольно неплохо описаны на текущий момент как в декларативных лучших практиках, так и в исполняемом виде Sigma и других форматов. Давайте теперь обратим внимание на весь жизненный цикл инцидента в целом, так как предыдущие темы описывали лишь процесс обнаружения.
Вне зависимости от того, о каком типе инцидентов мы говорим, будь то утечка данных, атака шифровальщика или распределенная попытка вывода системы из строя — его обработка должна иметь формализованный, процессный подход. Для этого еще до выявления реальных инцидентов должны быть подготовлены процедуры, описывающие алгоритм обработки в зависимости от типа инцидента, его критичности и других вводных. Такие алгоритмы называются сценариями реагирования на инциденты (Incident Response Playbooks) или сокращенно плейбуками.
Сценарии реагирования решают следующие задачи:
- Погружают аналитика SOC в контекст расследуемого инцидента, снабжая его всей необходимой информацией о характере инцидента, правилах анализа вовлеченных внешних и внутренних объектов, а также описанием правил корреляций, референсных исследований и возможных причин ложноположительных срабатываний;
- Классифицируют инцидент по уровню критичности в зависимости от его типа и вовлеченных объектов.
- Формируют надлежащий перечень необходимых действий для успешной обработки инцидента на всех стадиях его жизненного цикла;
- Закрепляют процедуры формирования рабочей группы и триггеров, при которых происходит эскалация;
- Создают инструментарий для накопления подобного рода экспертизы в виде, удобном для использования, последующего улучшения и распространения внутри компании и за ее пределами.
Проективный подход, наряду с расширением технологического стека, лежит в основе роста уровня зрелости процесса обработки инцидентов в компании.
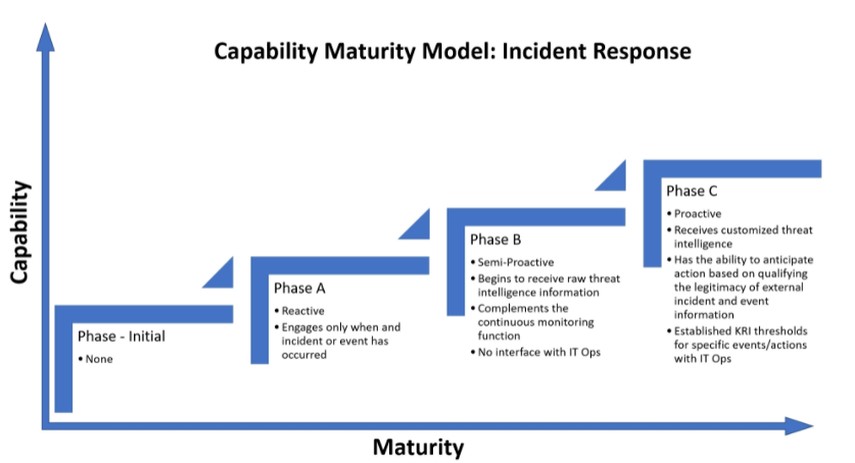
Этапы роста уровня зрелости процесса реагирования на инциденты информационной безопасности
Какую методологию формирования этих самых сценариев реагирования стоит выбрать? Опрос в социальных сетях — хоть и не самый достоверный, но весьма показательный инструмент, говорящий о том, что большинство опрошенных отдают свои предпочтения одному из стандартов: NIST Computer Security Incident Handling Guide (800-61 R2) и SANS 504-B Incident Response Cycle (PICERL).
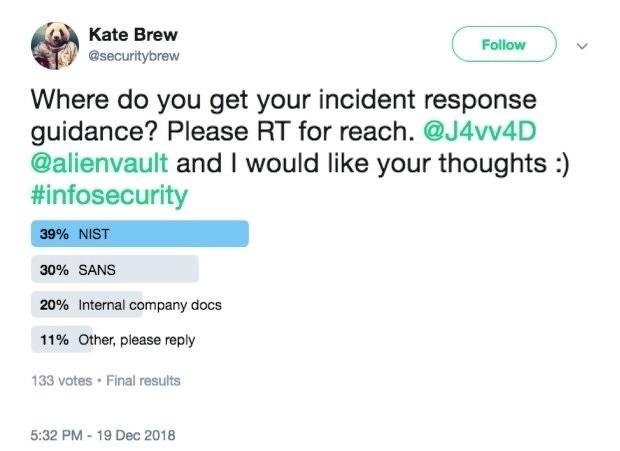
Порядка 70% специалистов ИБ в области управления рисками выбирают стандарты NIST или SANS. Источник: Kate Brew @securitybrew
Сами эти методологии чрезвычайно похожи друг на друга. Обе уделяют большое внимание процессу подготовки, инвентаризации и категорирования активов, созданию списков коммуникации по различным типам инцидентов, базовых уровней (baselinse) поведения систем для последующего сравнения с потенциально скомпрометированной и т.д. SANS и NIST на этапе анализа инцидента уделяют особое внимание поиску точки входа и охвату вовлечённых объектов. И, наконец, на финальном этапе формируется закрепление полученных результатов в виде обратной связи для постоянного улучшения процесса реагирования. Различие, и то достаточно номинальное, заключается в том, что NIST объединяет в один этап Сдерживание, Искоренение и Восстановление, в то время как SANS считает каждый из них отдельным этапом.

Сравнение NIST и SANS
Если с методологией все более-менее понятно, то с ее практическим применениями и источниками прикладных сценариев все обстоит не так радужно. В прикладном смысле сценарий (плейбук) — это набор инструкций и действий, которые должны выполняться участниками и системами на каждом этапе процесса реагирования на инцидент. Такой план действий предназначен для того, чтобы указать организациям четкий путь через весь процесс, хотя и с определенной степенью гибкости в случае, если расследуемый инцидент не укладывается в рамки.
В качестве примера рассмотрим структуру сценария распространенной угрозы фишинга с учетом описанных ранее этапов.
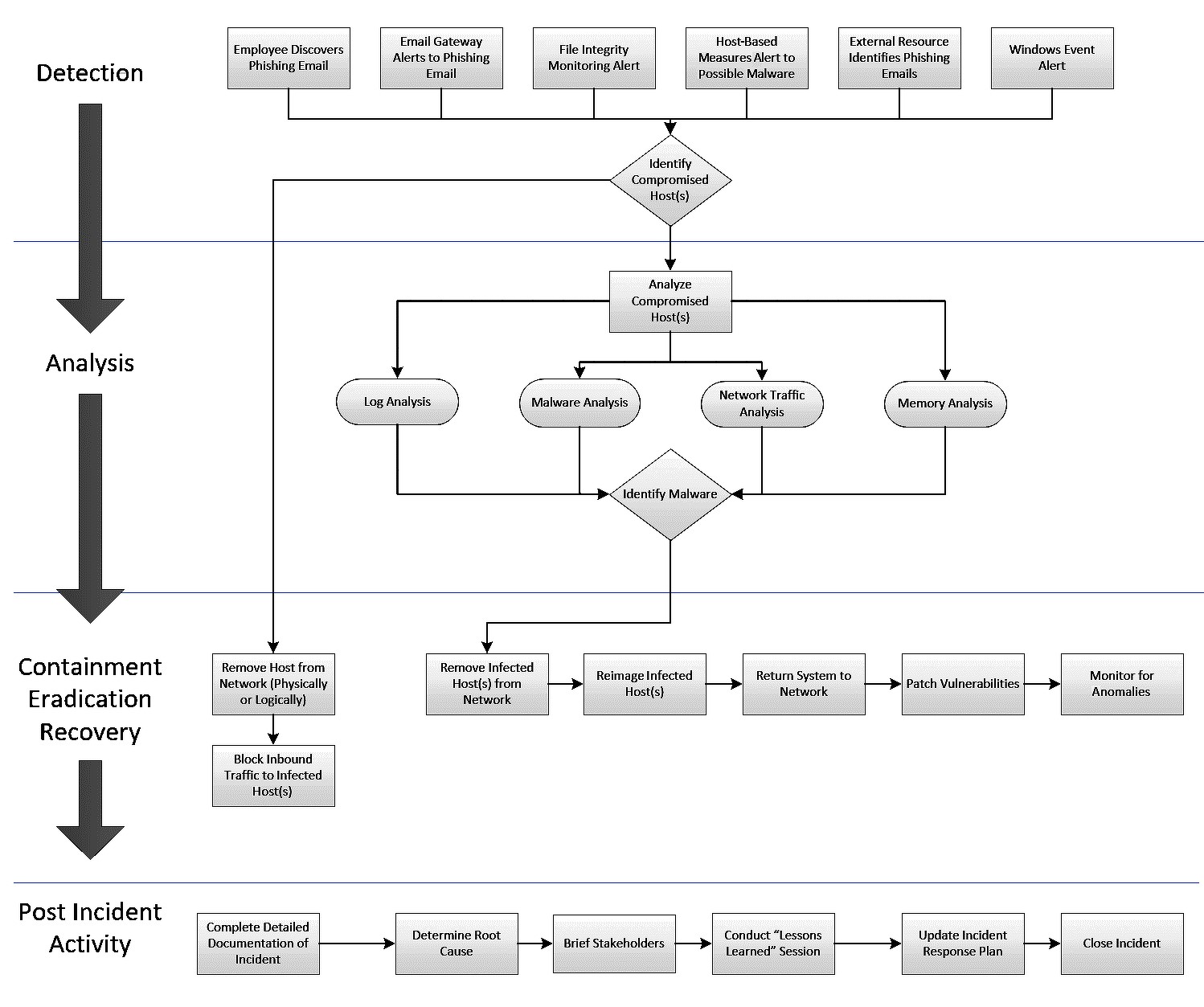
Процесс обработки инцидента «Фишинг»
- Подготовка (Preparation). В случае фишинговых атак этот этап может включать осведомленность сотрудников для выявления потенциальных фишинговых сообщений в электронной почте или использование средств защиты, которые сканируют вложения на наличие вредоносных программ и ссылок.
- Обнаружение (Detection). О фишинговых атаках организации часто получают предупреждение от ответственных сотрудников или с помощью средств контроля безопасности электронной почты. Они также должны планировать получение предупреждений с помощью средств антивирусной защиты или других систем предотвращения вторжений на конечных устройствах. Типовые вредоносные техники, такие как выполнение вредоносного кода из офисных документов, также должны быть покрыты правилами детектирования на SIEM- системах на основе анализа событий конечных устройств.
- Анализ (Analysis). Если событие обнаружено, анализ любых имеющихся вовлеченных объектов будет иметь решающее значение для классификации инцидента и надлежащего реагирования на него. В этом случае анализ может включать в себя:
- изучение индикаторов компрометации (Indicator of Compromise, IoC) и исполняемых объектов на предмет их репутации и наличия признаков вредоносности;
- изучение журналов событий на предмет подозрительных активностей;
- проверку исходящего сетевого трафика, как направленного в сеть интернет, так и внутри защищаемого периметра;
- также применяется анализ памяти устройства, служебных областей файловой системы и конфигураций, таких как реестр, WMI, сервисы и запланированные задачи на предмет наличия индикаторов атак (Indicator of Attack, IOA).
- Сдерживание (Containment). Если хост был идентифицирован как взломанный, он должен быть изолирован от сети.
- Искоренение (Eradication). В случае обнаружения вредоносного ПО его следует удалить. В противном случае в сценарии должна быть альтернатива, позволяющая выполнить развертывание системы с заведомо исправным образом.
- Восстановление (Recovery). Этап восстановления включает сканирование хоста на предмет потенциальных уязвимостей и мониторинг системы на предмет аномального трафика.
- Действия после инцидента (Post-incident activity). На данном этапе подготавливаются отчеты, используемые как для внутреннего пользования, так и направляемые в отраслевые и государственные центры мониторинга. Кроме того, производится анализ качественных и количественных метрик успешности процесса обработки и факторов, которые негативно повлияли на него и могут быть улучшены в будущем. Зафиксированные индикаторы компрометации на данном этапе также фиксируются во внутренних TI-системах.
Формирование подобного рода сценариев, безусловно, крайне полезная вещь для увеличения эффективности процесса реагирования, однако на начальных этапах — весьма трудоемкая. Без реального «боевого» опыта даже список возможных сценариев нападения — довольно нетривиальная задача, что уж говорить про поминутно расписанный сценарий противодействия. Давайте попробуем, как и в наших предыдущих статьях, сократить трудозатраты за счет опыта, который уже есть в публичном доступе по данному направлению.
IRM (Incident Response Methodologies by CERT Societe Generale) — наверное старейший и самый знаменитый публично доступный архив сценариев. Плейбуки локализованы на русском и испанском. Насчитывают 14 законченных типов, и, несмотря на свой солидный возраст, они до сих пор актуальны и вполне применимы, хотя стоит делать поправку на новые версии операционных систем.
Методологии реагирования на инциденты (IRM). Основаны на работе, проделанной CERT Societe General
GuardSIght Playbook Battle Cards. Довольно свежий проект, вдохновленный предыдущим ресурсом CERT Societe Generale, представила GuardSight, Inc. Ресурс содержит порядка пятидесяти сценариев и активно обновляется. Приятно видеть, что сценарии имеют референсы на техники Mitre ATT&CK, однако информация в самих карточках достаточно скупа на технические детали и призвана скорее направить, нежели дать исчерпывающую информацию. Соседние ветки репозитария также содержат Cybersecurity Incident Response Plan — тактический план компании по обработке инцидентов, Mission-model — шаблон отчета, который создается в процессе обработки инцидента, и ряд других интересных проектов.
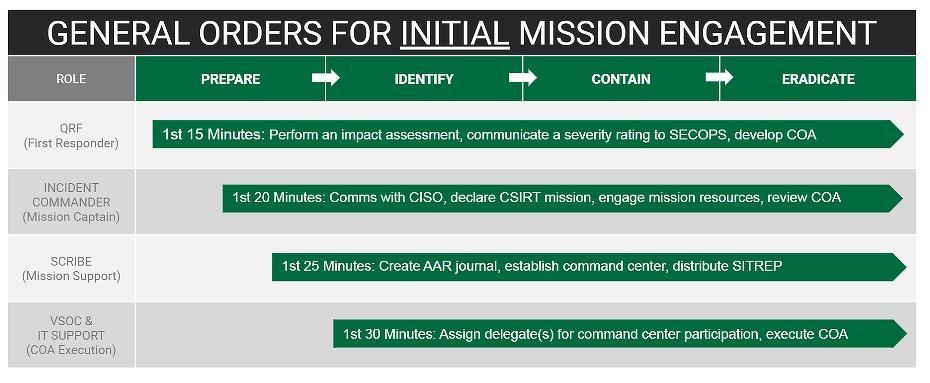
Алгоритм действий по реагированию на ИБ-инциденты
Counteractive Playbooks — проект компании CounteractiveSecurity. Он содержит пока лишь пять сценариев реагирования, многие пункты из которых пока в ToDo. Однако в отличие от предыдущего проекта, сфокусированного на концентрированном предоставлении всей информации, это достаточно технически погруженные в детали сценарии реагирования.
IR Workflow Gallery — проект, схемы из которого не стыдно показать руководству. Содержит девять сценариев, каждый этап сформирован в схему, доступную для скачивания в pdf и visio. Схемы скупы на технические детали, однако отлично подойдут в качестве ментальных карт, а открытый для изменения формат легко адаптировать под себя.
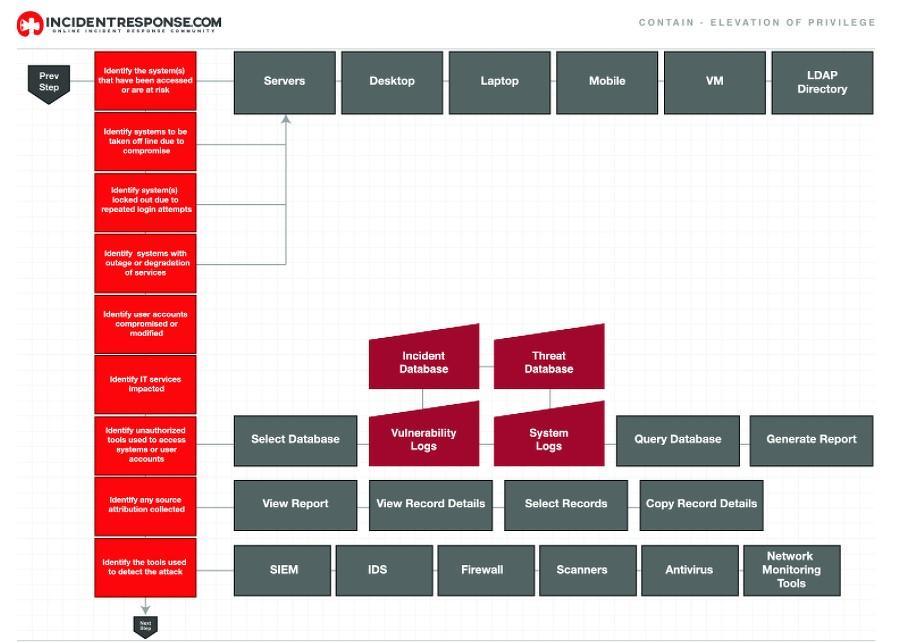
Плейбук по реагированию на инциденты c повышением привилегий содержит все семь шагов, определенных NIST. Источник: IR Workflow Gallery
Flexibleir — стартап для создания новых плейбуков и конвертирования имеющихся в формат интерактивных досок. Плейбуки постоянно обновляются, появляются специализированные, касающиеся эксплуатации трендовых уязвимостей или активности хакерских группировок.
Incident-Playbook — недавно появившийся проект, продвигаемый энтузиастами кибер-сообщества в рамках вселенной Mitre ATT&CK. Он создан для максимальной интеграции данных фреймворка в процесс обработки инцидентов. Сам концепт крайне интересный, есть отдельные ветки по настройке хардеринга систем, идентификации атак с описанием типов событий, роли, метрики эффективности и списки наблюдаемых значений. Однако проект остро нуждается в новых авторах для наполнения экспертизой.
Phantom Cyber playbooks — репозиторий публично доступных сценариев для Splunk Phantom, однако в принятой в данной статье терминологии, большинство сценариев в нем плейбуками все же не являются, так как выполняют лишь атомарную операцию по анализу или предотвращению. Аналогичные ранбуки можно найти в ветке Cortex-Analyzers проекта The Hive.
ThreatHunter-Playbook — проект, относящийся, скорее, к сфере Threat Hunting (TH), нежели классический DFIR (Digital Forensics and Incident Response), однако безусловно заслуживающий внимания. Аналогично описанным выше шагам в процессе расследования инцидентов, автор проекта Роберто Родригес (Roberto Rodriguez) поэтапно описывает работы с TH-гипотезами. Сценарии имеют Jupyter-формат и ссылаются на публичный датасет событий безопасности OTRF/Security-Datasets, что позволяет повторить анализ за автором в режиме онлайн.
Microsoft Security Best Practices. Даже Microsoft начинает публиковать свои сценарии реагирования. Пока их лишь три: Phishing, Password spray и App consent grant, и касаются они облачных сервисов в Azure.
И в заключение еще несколько шаблонов сценариев реагирования от разных компаний:
NCC Group -Cyber Incident Response Phishing Playbook
Sysnetgs Incident Response Plan template (требуется регистрация)
California Government Department of Technology incident response plan example
Playbook-Example-Mitigation of Phishing Campaigns
Сynet: 6 Incident Response Plan Templates
Подготовка подробного рода сценариев реагирования и, главное, их внедрение в продуктивную эксплуатацию требует значительных ресурсов. Для наиболее скорого возврата этих инвестиций создание таких методик реагирования лучше сразу начинать в решениях класса SOAR (Security Orchestration, Automation and Response). Он как раз и создан для конструирования сценариев, автоматизации взаимодействия людей и систем, анализа наблюдаемых объектов, формирования отчетов и подсчета метрик эффективности. Такие системы позволяют снабдить аналитика максимально возможной информацией для принятия решения, автоматизировать рутинные операции, упростить коллективную работу над инцидентом и закрепить полученные знания. Во главу угла же в системах подобного класса встает максимальная гибкость и кастомизируемость всех элементов системы. Описанные выше разнообразные подходы к формализации процесса реагирования являются тому прекрасным примером. Платформа Security Vision SOAR сочетает в себе простоту дружелюбного интерфейса и лежащий «под ее капотом» интеллектуальный механизм коннекторов, рабочих процессов, событий и объектов, который позволяет автоматизировать практически любой процесс информационной безопасности.
Часть 4. Анализ данных
Если обобщенно взглянуть на большинство процессов, связанных сегодня с Incident Response, да и в целом с Security Operations, то одним из основных узких мест является анализ большого объема данных, полученных из различных источников. А это означает, что с большой долей вероятности для решения прикладных задач информационной безопасности могут быть полезны те же инструменты, что используются для обработки данных в других сферах — все то, что сегодня называется термином Data Science. И столь популярные сейчас темы машинного и глубокого обучения как раз входят в раздел науки о данных (Data Science).
В силу высокого интереса современного рынка к темам ML/DL/AI, в совокупности с значительной сложностью в освоении и понимании используемых в этой сфере методов, многие производители, в том числе из сферы ИБ, часто спекулируют в своих рекламных проспектах данными понятиями и декларируют их как некую волшебную пулю от всех болезней информационной безопасности. Давайте же попробуем отсечь маркетинг и оценить существующий сегодня инструментарий анализа данных ИБ.
Несомненно, современные вычислительные мощности, включая распределенное и облачное вычисления, а также новые инструменты работы с большими данными, которые уже зарекомендовали себя в различных сферах бизнеса, могут предоставить для решения задач информационной безопасности множество дешевых и эффективных решений. Анализ огромного объема данных как на предмет выявления известных паттернов и закономерностей, так и на выявление слабых сигналов и аномалий, сегодня не требует ни серьезных производственных мощностей, ни профессионального математического образования. С чего же в этом случае стоит начать?
Для рядовых сотрудников SOC дорога в Data Science выглядит достаточно тернистой, а перспективы получения применимых в работе результатов — смутные. Попробуем пройти этот путь, «стоя на плечах гигантов», и снова обратимся к статье Джона Ламберта (John Lambert) «Гитхабификация Информационной Безопасности» («The Githubification of InfoSec»), в которой он применяет термин Repeatable Analysis — «Воспроизводимый/Повторяемый анализ». На практике это означает, что мы с вами обладаем не только описанием проводимого другим специалистом аналитического исследования данных и его итоговыми результатами, но и можем воспроизвести все сделанные им шаги в режиме реального времени как на его данных, так и на своих собственных, не прикладывая к этому большого труда. И в качестве инструмента обмена подобного рода воспроизводимыми аналитическими исследованиями Джон, как и многие другие специалисты сегодня, отдает предпочтение технологии с открытым исходным кодом, реализованной в Jupyter Notebooks.
Среда разработки Jupyter Notebook cчитается стандартом для большинства питонистов
Jupyter — это набор технологий, созданных сообществом специалистов по исследованию данных. Основным концептом данной технологии является блокнот (Notebook). Он содержит в себе описательную часть в виде текста, формул и изображений, которые позволяют понять суть исследования, последовательности и применимость его этапов, способы интерпретации полученных данных, а также, собственно, сам программный код, производящий вычисления, каждый из блоков которого возвращает полученный на данном этапе результат.
Итеративность и наглядность процесса анализа делает Jupyter де-факто отраслевым стандартом для аналитиков данных. В конце 2020 г. исследователи JetBrains решили подсчитать количество блокнотов Jupyter на GitHub и обнаружили более 9,72 миллиона публично доступных файлов с восьмикратным увеличением их количества по сравнению с аналогичным исследованием трехлетней давности. Специалисты как в области теоретической науки, так и из вполне прикладных сфер, таких как предсказание поведения клиентов, анализ электоральных данных или флуктуаций излучения спутников, — все они с готовностью публично делятся результатами своих исследований.
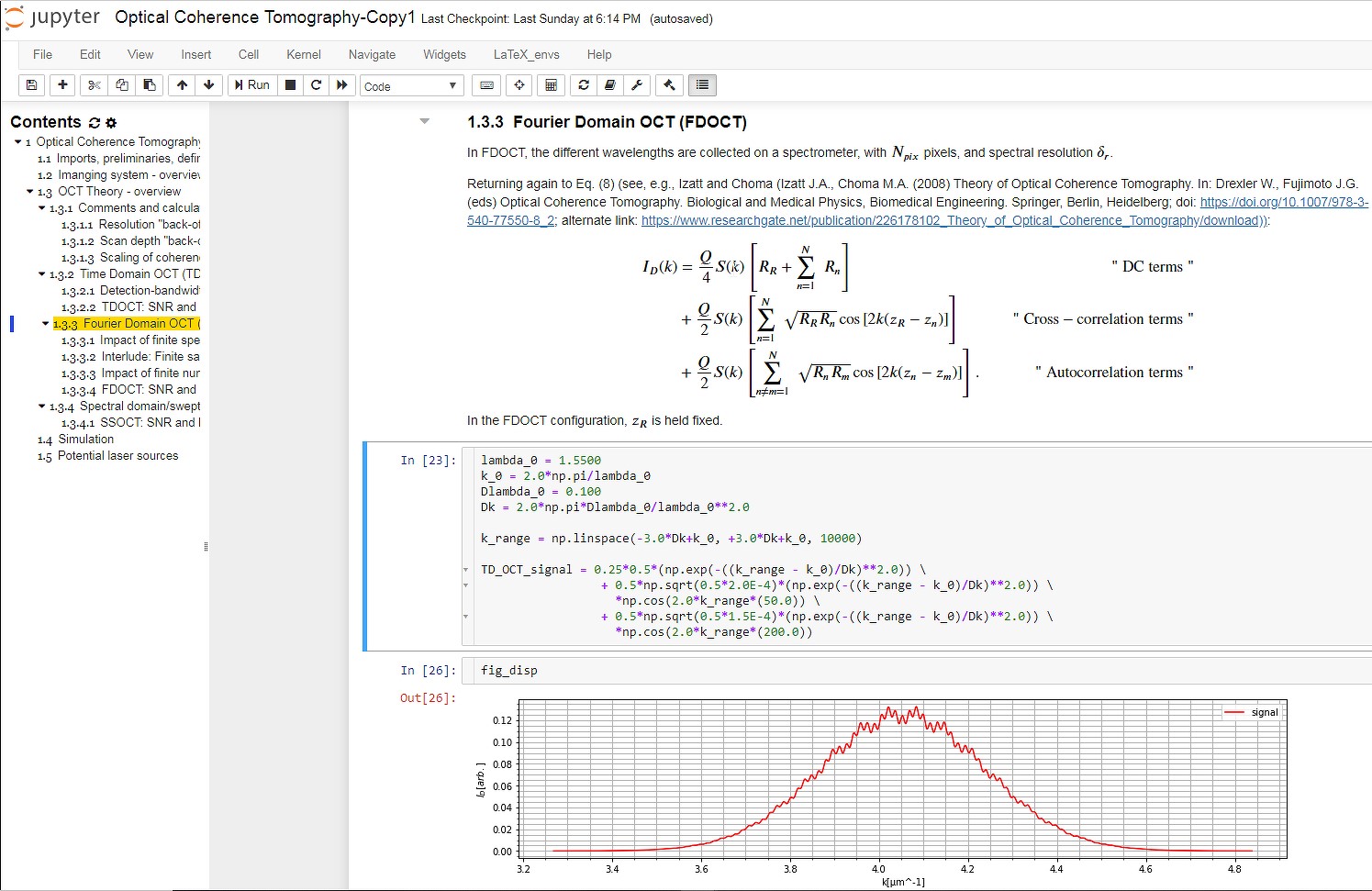
Пример исследования в Jupyter Notebook
Для запуска вычислений в Jupyter требуется «ядро», то есть процесс, который будет запускать код на Python, .NET, R или других языках программирования и возвращать результат пользователю. «Ядро» может быть запущено на любой операционной системе прямо в браузере, вне зависимости от того, Windows это, Linux, Mac или мобильное устройство. «Ядро» может быть развернуто локально, удаленно или в облачной инфраструктуре. Как ни странно, последний пункт будет особенно интересен для начинающих исследователей данных. Такие сервисы, как mybinder, предоставляют доступ к «ядрам» со всеми необходимыми установленными библиотекам, так что пользователь за считанные минуты может воспроизвести исследование, имея под рукой только браузер. Большинство GitHub, содержавших Jupiter, сегодня прямо на основной странице имеют заветную кнопку Launch Binder. Один клик, несколько секунд — и полностью рабочий аналитический аппарат для воспроизведения исследования готов к работе.
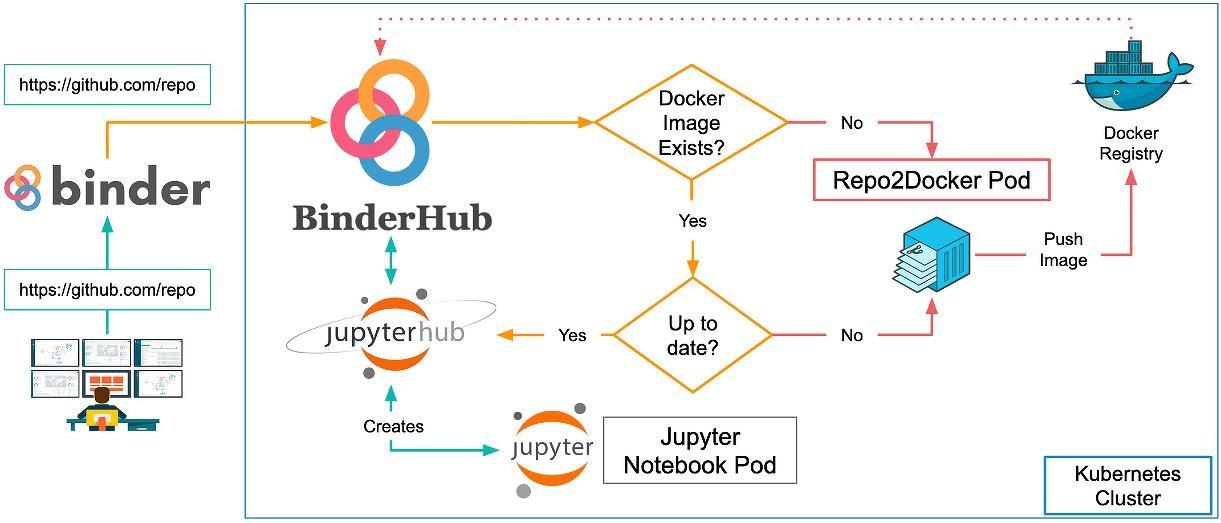
Архитектура binder
Упомянутое выше исследование (кстати, тоже присутствующее в виде сырых данных и Jupyter блокнота) говорит следующее о деталях данной технологии:
- Несмотря на большой рост популярности R и Julia в последние годы, Python остается лидирующим программным языком для Jupyter-ноутбуков.
- 60% ноутбуков содержат в списке зависимостей Numpy, 47% импортируют Pandas. Это инструменты работы с сырыми данными в виде многомерных массивов — Numpy и гетерогенные табличные структуры или датафремов (dataframes) — Pandаs.
- В качестве инструментов графического представления наибольшую популярность сегодня имеют Matplotlib и набирающий популярность Seaborn, который делает все проще и красивее, чем у конкурента.
- Инструменты машинного обучения чаще всего представлены библиотеками Scikit-learn, torch и т.д., которые дают пользователю довольно широкий набор готовых алгоритмов SVMs, Random Forests, Logistic Regression и отлично подходят для новичков в ML и серьезными низкоуровневыми инструментами вроде TensorFlow, Keras, PyTorch.
Долгое время вся эта исследовательская активность обходила стороной сферу информационной безопасности, однако ситуация изменилась в 2019 г. после выхода цикла статей Роберто Родригеса (Roberto Rodriguez) «Threat Hunting with Jupyter Notebooks». В данной серии рассказывается о применимости библиотеки Pandas для анализа событий ИБ, так как она создана как раз для работы с разнородными табличными данными, такими, например, как логи SIEM-систем.
Уже в ознакомительной статье мы можем на примере расследования по логам системы, атакованной модулем lateral_movement/invoke_wmi из состава Powershell Empire, проследить за действиями исследователя.
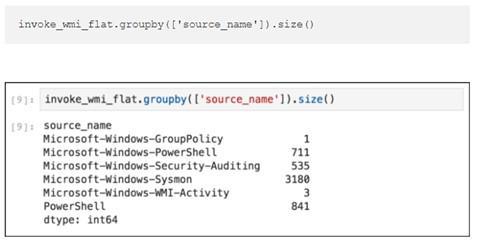
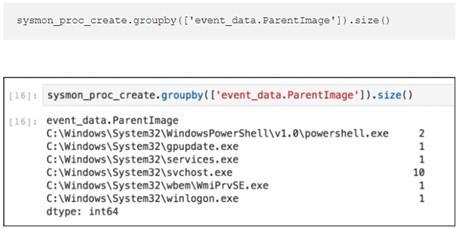
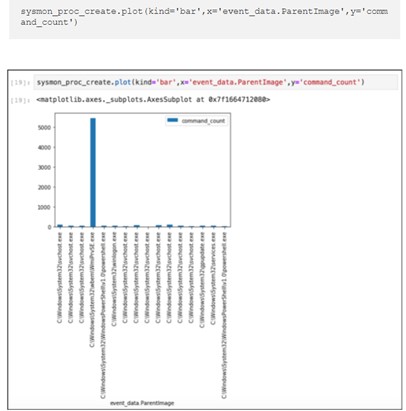
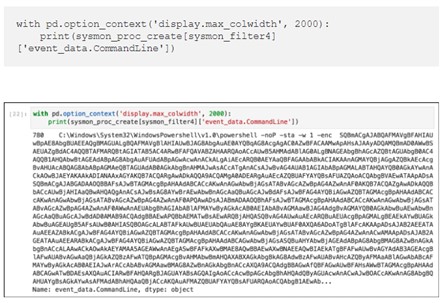
Шаг за шагом мы можем проследить и воспроизвести каждый из его шагов, ознакомиться с приводимыми Роберто референсами, изменить запросы для более глубокого ознакомления с данными или попробовать воспроизвести их на собственных выборках событий, просто изменив источник.
Последующие статьи Родригеса рассказывают, как использовать Elasticsearch в качестве источника данных, а Apache Spark — в качестве SQL-like аналитического аппарата, что позволяет SOC-аналитику обзавестись столь необходимой функцией для расследования разрозненных событий, таких как JOIN, сцепляя на основании общего поля LogonID события аутентификации (Security EID 4624) и создания процесса (Sysmon EID 1).
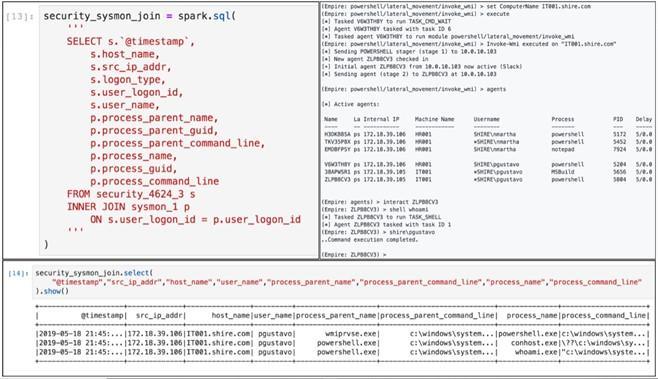
Пример функции JOIN для событий Windows
Из этого цикла статей появились GitHub репозиторий и сайт Threat Hunter Playbook. На данный момент проект содержит более трех десятков расследований и множество полезных для исследователей справочных материалов. Все расследования ссылаются на упомянутую выше библиотеку событий OTRF/Security-Datasets, также созданную братьями Родригесами
Рабочее пространство Threat Hunter Playbook
Энтузиазм двух этих уроженцев Перу сложно переоценить, и для того, чтобы заразить им как можно больше людей, в 2020 г. ребята организовали онлайн-конференцию InfoSec Jupyterthon, где, помимо них, своими воспроизводимыми исследованиями делятся специалисты из Microsoft Threat Intelligence Center (MSTIC), Awake Security, Expel, Nvidia и ряда других компаний. InfoSec Jupyterthon формата 2021 г. развернулся уже в полную силу, заняв два полных дня, за время которых выступило два десятка спикеров и было проведено семь воркшопов. Итогом стало окончательное понимание того, что Data Science и информационная безопасность вместе надолго.
Так, Мехмет Эрген (Mehmet Ergene) рассказал о методе детектирования C2 Beaconing, то есть периодических подключений вредоносного ПО к серверам управления на основании статистического анализа событий сетевых подключений пользователей. Джо Потроске (Joe Potroske) из Target's Cyber Fusion Center продемонстрировал методы обнаружения обфусцированных Powershell на основании не статических правил корреляции, которые просто невозможно описать все, а на основании поиска самой обфускации через регрессионный анализ длинны PowerShell-команд и содержащихся в них символов. И, наконец, уже второй год подряд сотрудники Microsoft Threat Intelligence Center рассказывают о msticpy. Эта созданная сотрудниками центра исследования киберугроз компании Microsoft open source библиотека позволяет:
- получать данные о событиях безопасности из SIEM-систем и других источников;
- извлекать индикаторы активности (IoA) из логов и на лету распаковывать обфусцированные события;
- проводить анализ событий на выявление аномалий и декомпозицию временных рядов;
- обогащать данные, используя внешние источники, такие как VirusTotal, XForce, OTX, GreyNoise и другие;
- визуализировать результаты с помощью интерактивных временных шкал, деревьев процессов и графов.
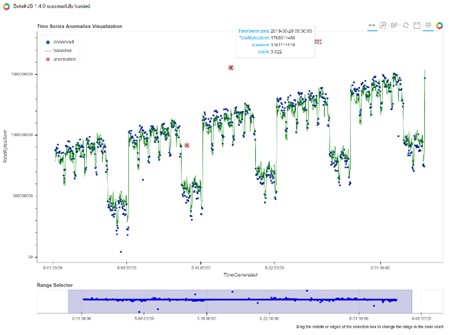
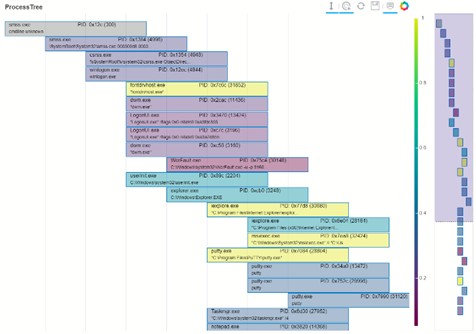
Примеры визуализации событий в misticpy
На последнем форуме Positive Hack Days для нас было очень приятным открытием, что сотрудник компании Positive Technologies Антон Кутепов создал fork данной библиотеки, снабдив ее поддержкой MaxPartol SIEM в качестве источника событий.
Есть и ряд других свободно распространяемых проектов воспроизводимых исследований. Так, широко известный специалистам по информационной безопасности портал по анализу ресурсов в интернете DomainTools опубликовал свой Jupyter блокнот, иллюстрирующий взаимосвязи исследуемых доменов на основании общей инфраструктуры, информации о регистрации и паттернов имен.
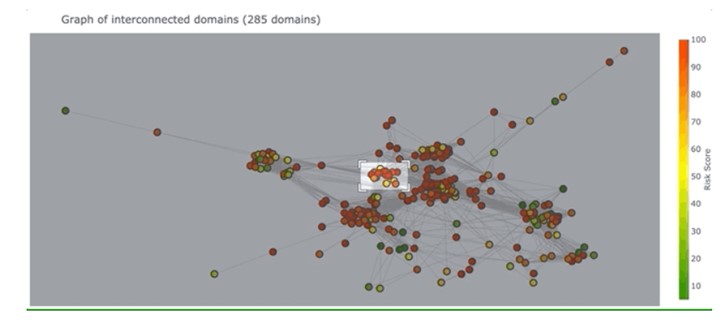
Граф взаимосвязи доменов в DomainCAT
Проект по визуализации взаимосвязей Threat Intel индукторов компрометации (IoCs), полученных в STIX-формате Stixview также обзавелся виджетом для среды интерактивных вычислений.
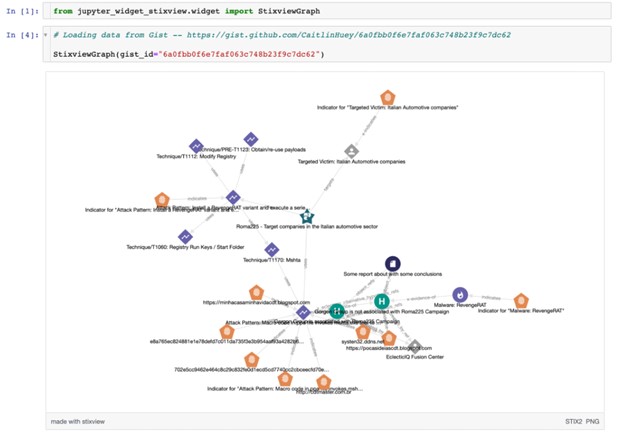
Виджет для построения графов на основании TI-данных
И это — только несколько примеров опубликованных исследований. Сегодня благодаря подобного рода технологиям обмена знаниями полностью стирается грань между фундаментальными исследователями в области Data Science, находящимися на авангарде защиты исследователями киберугроз международных SOC/CERT/CSIRT и всеми рядовыми специалистами ИБ по всему миру, только начинающими у себя в компании процесс построения Incident Response.
Наука о данных вошла во все сферы нашей жизни. ИТ-гиганты и финтех-стартапы, правительства государств и стриминговые сервисы — для всех них анализ больших данных и ML уже не есть какое-то «ноу-хау», а процесс, ежедневно находящий новые точки приложения и приносящий огромную прибыль, феноменально сокращая издержки на обработку данных. Задачи, стоящие перед сегодняшними SOC, методологически мало чем отличаются от задач в других сферах, и это означает, что сегодняшнему ИБ просто необходимо гораздо больше внимания уделить инструментам гибкой обработки данных, машиночитаемым форматам обмена экспертизой и взаимодействию всех членов кибер-сообщества для создания научного, воспроизводимого подхода к используемым нами методам и инструментам.
Рекламные проспекты решений по информационной безопасности и какой-то момент довольно сильно перегрели темы искусственного интеллекта (Artificial Intelligence) и машинного обучения (Machine Learning), сделав их фактически синонимом чего-то столь же сложного, малоприменимого и малополезного в реальной жизни. Открытые исследования на основе открытых же данных дают нам четкое понимание того, какие именно инструменты, методы и алгоритмы в каких ситуациях и при каких вредоносных активностях обеспечивают результаты выше, чем классические сигнатурные средства зашиты.
Вне зависимости от того, какие источники данных используют наши клиенты в платформе Security Vision: классические SIEM системы или инструменты работы с большими данными вроде Kafka, Spark, Hadoop, Zeppelin и т.д, продукт позволяет выстроить процесс получения, обогащения, анализа инцидента, а также выполнить действия по его обработке и устранению. Продукт может как самостоятельно оркестрировать имеющиеся у пользователя Jupyter блокноты, так и выступать источником информации и выполнять сценарии по внешнему запросу через Rest API интерфейс. Созданные нашими специалистами модели машинного обучения, интегрированные с платформой, позволяют значительно сократить нагрузку и затраты на использование SIEM-систем и детектировать аномалии, недоступные для выявления другими средствами анализа.