
Бесплатный вебинар
КАК СТАТЬ CISO:
КАРТА РОСТА
КАРТА РОСТА
Бесплатный вебинар 9 июля в 11:00 для тех, кто хочет развиваться в ИБ.
Термин AIOps был введен Gartner несколько лет назад. Именно такие решения помогают обеспечить стабильность ИТ в условиях растущей нагрузки, снижают информационный шум, выявляют аномалии из большого количества данных, не перегружают системы и могут интегрироваться с большим количеством систем мониторинга — и при этом учитывают вопросы ИБ.
План:
1. Что такое AIOps
2. Потери от цифровых сбоев и действие злоумышленников для крупных компаний
3. Результаты исследования по ИТ-болям в Азии и в России
4. Подходы к ИТ-управлению
5. Описание кейса по "пожаротушению" в ИТ
6. Описание кейса по взаимодействию ИТ и ИБ
Связанные статьи:
1. https://www.securitylab.ru/analytics/512063.php
2. https://www.securitylab.ru/news/511577.php
Автор: Николай Ганюшкин, CEO MONQ Digital Lab
Пандемия сделала бизнес еще более зависимым от стабильной работы ИТ. Это означает, что нагрузка на ИТ и ИБ юниты выросла в разы — именно поэтому компаниям нужны решения, которые позволят не только найти и быстро решить проблемы, но и предугадать их. Такими решениями являются AIOps.
Термин AIOps (Artificial Intelligence for IT Operations) — умное управление ИТ-операциями — был введен Gartner несколько лет назад. Именно такие решения помогают обеспечить стабильность ИТ в условиях растущей нагрузки, снижают информационный шум, выявляют аномалии из большого количества данных, не перегружают системы и могут интегрироваться с большим количеством систем мониторинга — и при этом учитывают вопросы ИБ.
Давайте посмотрим на возможности таких платформ через MONQ — AIOps-решение, которое собирает данные из всех источников, представляет данные в виде доступных дашбордов, карт цифрового здоровья сервисов и прочей аналитики, помогает быстрее выявлять причины сбоев и автоматизирует рутинные функции.
Потери от сбоев и атак
В России бизнес пока еще учится оценивать в деньгах, репутации и рисках потери от нестабильной работы ИТ-инфраструктуры и цифровых сервисов, а в мире цифры говорят сами за себя:
1. 12 трлн $ — такие суммарные потери несут ежегодно компании и государство от цифровых сбоев и действий злоумышленников
2. 1-2,5 $ млрд в год — потери от сбоев в работе корпоративных приложений для мировых компаний из ТОП-1000 (IDC)
3. 66 240 $ — стоимость 1 минуты простоя для Amazon (Ponemon)
4. 11 000 $ — средняя стоимость 1 минуты простоя в IT (Ponemon)
Тем временем, основные сбои носят повторяющийся характер, а по данным МcKinsey, до 25% ИТ-бюджета можно сэкономить на умной автоматизации процессов. А начать надо с решения основных ИТ-болей.
Что "болит" у ИТ?
Летом этого года MONQ Digital Lab провела крупное исследование в российских и азиатских компаниях. B исследовании приняли участие CIO, ИТ-директоры, руководители отделов ИТ-мониторинга, руководители ситуационных центров, руководители отделов ИТ-инфраструктуры, Product Owner, руководители отделов IT-for-IT.
Несмотря на некоторую специфику разных отраслей — например, в банках вопросы безопасности стоят острее, чем в телекоме, где, в свою очередь, актуален вопрос контроля подрядчиков, поддерживающих ИТ-инфраструктуру и цифровые сервисы, — ТОП общих ИТ-болей в крупных компаниях выглядит следующим образом:
1. Непонятно, что послужило причиной сбоя
2. Клиенты быстрее IT узнают о сбоях и жалуются бизнесу
3. Нет способов быстрого и объективного контроля подчиненных и подрядчиков
4. Слишком много шума от систем мониторинга
5. "Упал" продукт, непонятно, кто чем занимается и решается ли проблема
6. Растет число задач, а штат не увеличивается
7. Много делается вручную, много ошибок
8. Нет инструмента быстрой отчетности бизнесу
9. Постоянно растут расходы на мониторинг при развитии
10. Сбои не прогнозируются, а устраняются по факту, перманентная борьба с ними стала нормой
Отдельное место занимают кросс-функциональные проблемы — когда, например, у ИБ WAF "режет" нормальный трафик и при этом страдают реальные клиенты. Выяснение, что же произошло на самом деле, занимает много времени — часто единого инструмента для отслеживания состояния ИТ с учетом влияния ИБ нету. Такое непонятное состояние — частый признак того, что в компании "тушение пожаров" стало нормой.
Подходы к ИТ-управлению
В ИТ есть несколько основных подходов к управлению ИТ-инфраструктурой и цифровыми сервисами:
1. ИТ входит в локальные команды или продукты: за разработку и поддержку цифровых продуктов отвечают команды, в которых есть и аналитики, и разработчики, и поддержка, и ИБ, при этом данные подразделения "покупают" инфраструктуру у другого продукта, также некоторые функции ИТ могут заказываться у сотрудников службы безопасности. В таких архитектурах команды работают отдельно друг от друга, многие проблемы решаются очень быстро внутри, но, когда случается сбой, затрагивающий несколько продуктов, выясняется, что непонятно, кто что делает и за что отвечает. Что-то сломалось, а почему это произошло, кто виновен и кто должен чинить — выясняется или слишком долго, или подключается некая кросс-продуктовая рабочая группа (если сбой серьезно влияет на бизнес).
2. ИТ централизованно: продакты занимаются только разработкой, а после запуска продукта отдают его на поддержку в ИТ-блок. Информация о состоянии ИТ сосредоточена в руках ИТ-юнита, а при наступлении инцидента продакты могут часами ожидать ответа от коллег. ИТ в таких случаях борется с информационным шумом от сотен тысяч уведомлений от систем мониторинга и часто не знает, на какие алерты реагировать в первую очередь, потому что не понимает, как тот или иной сбой может повлиять на бизнес.
Бизнес в таких случаях играет роль стороннего наблюдателя — о том, что происходит в ИТ, начинает интересоваться в случае масштабного сбоя или жалоб от клиентов. Независимо от подхода к управлению, AIOps может сделать состояние ИТ прозрачным и понятным для всех.
Кейс #1. Как избавиться от вечных пожаров и перейти от реактивного мониторинга к проактивным действиям
Один из самых частых кейсов в ИТ — состояние постоянного пожаротушения. По словам одного из участника исследования, "борьба со сбоями стала новой нормой".
AIOps позволяет избавиться от пожаротушения в ИТ и ИБ в пять простых шагов:
1. Подключение систем мониторинга и других источники данных. Это можно сделать за несколько минут — например, достаточно указать логин и пароль, а также домен Zabbix-мониторинга, и внутрь системы сразу же полетят данные для анализа. MONQ, например, поддерживает большое число уже готовых коннекторов.
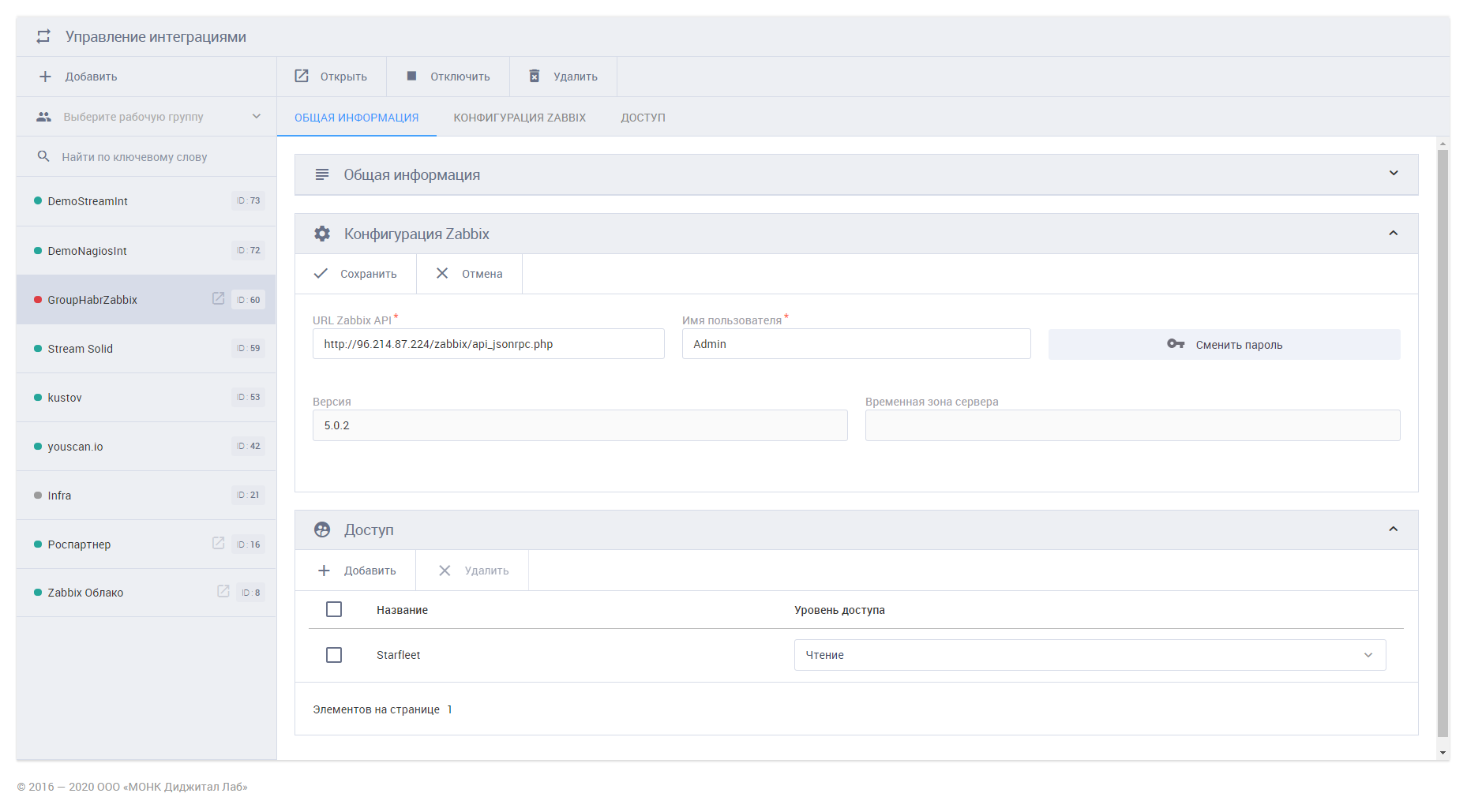
Экран MONQ: подключение систем ИТ-мониторинга
2. Подключение средств ИБ. Там, где нет коннекторов, или если нужно забрать логи с устройств и средств безопасности, можно подключить стримы неструктурированных данных. Этот функционал чем-то схож со возможностями Splunk и Elastic.
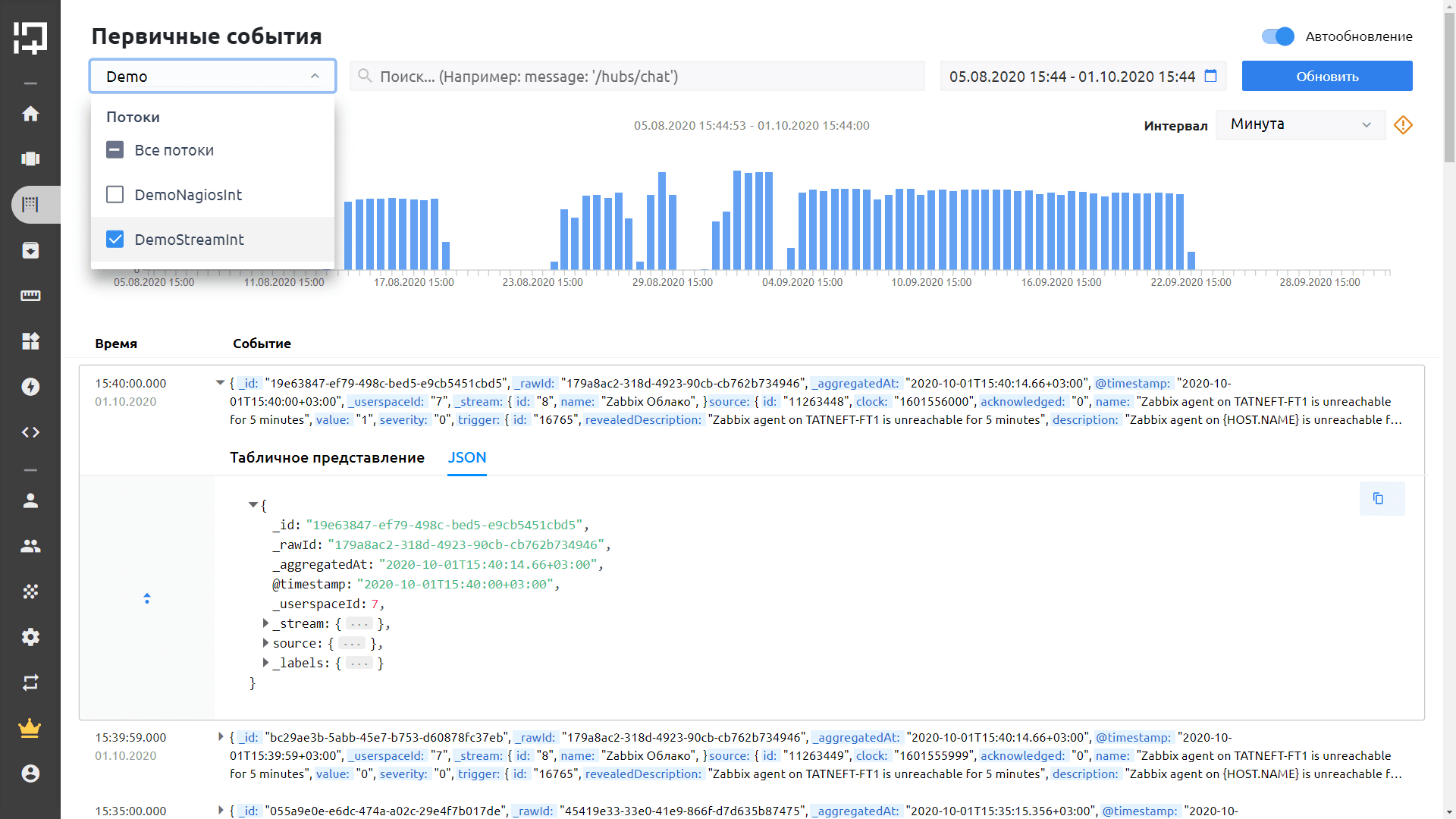
Экран MONQ: подключение логов и средств и ИБ
3. Сбор данных, настройка зависимости, правил корреляции и обработки данных. Вывод результатов в панели дашбордов. Для себя можно выводить один разрез данных, для руководства — другой, для соседних команд —делиться данными и фильтрами, и т.д. Совместное использование данных существенно сокращает расходы на их сбор и обработку. Используя технологии AIOps, инженеры смогут существенно поднять свою производительность и одновременно следить не за 5 системами, а за 20-30, так как поток бесполезных алертов от разных систем мониторинга сократится на 90% и будет преобразован лишь в полезные сообщения и наглядные виджеты.
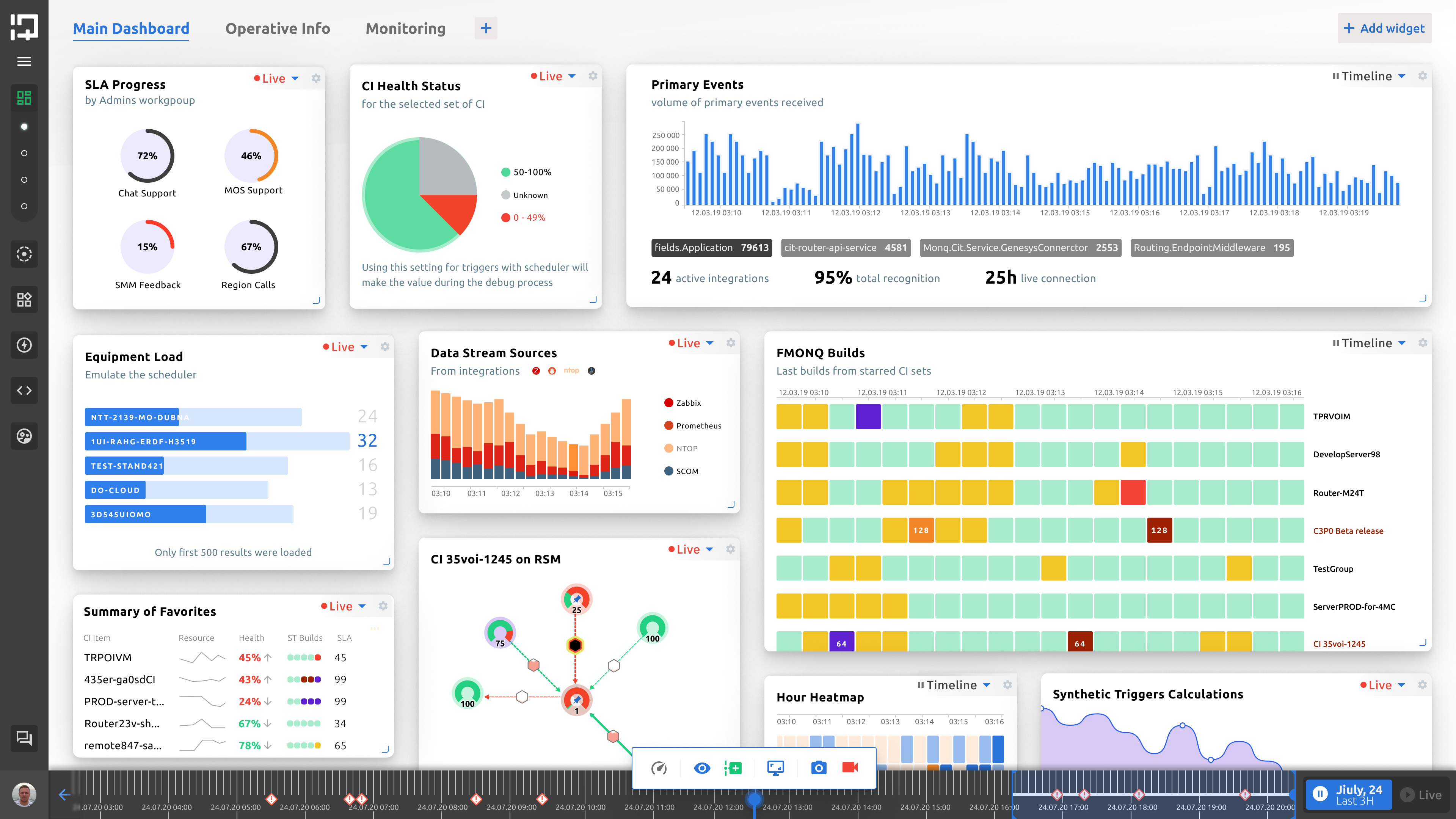
Экран MONQ: настраиваемые дашборды
4. Построение карты цифрового здоровья сервисов. Карта быстро покажет, что послужило причиной сбоя, например, это WAF или деградировавший сервер балансировки. Во время эскалации инцидент уйдет на нужную рабочую группу, а остальные ответственные получат лишь уведомление, что есть проблема, и ей занимаются коллеги из соседнего подразделения. Система учитывает и производственный календарь, сервисные режимы и пользовательские правила дедупликации. Все это существенно повышает производительность работы инженеров служб эксплуатации.
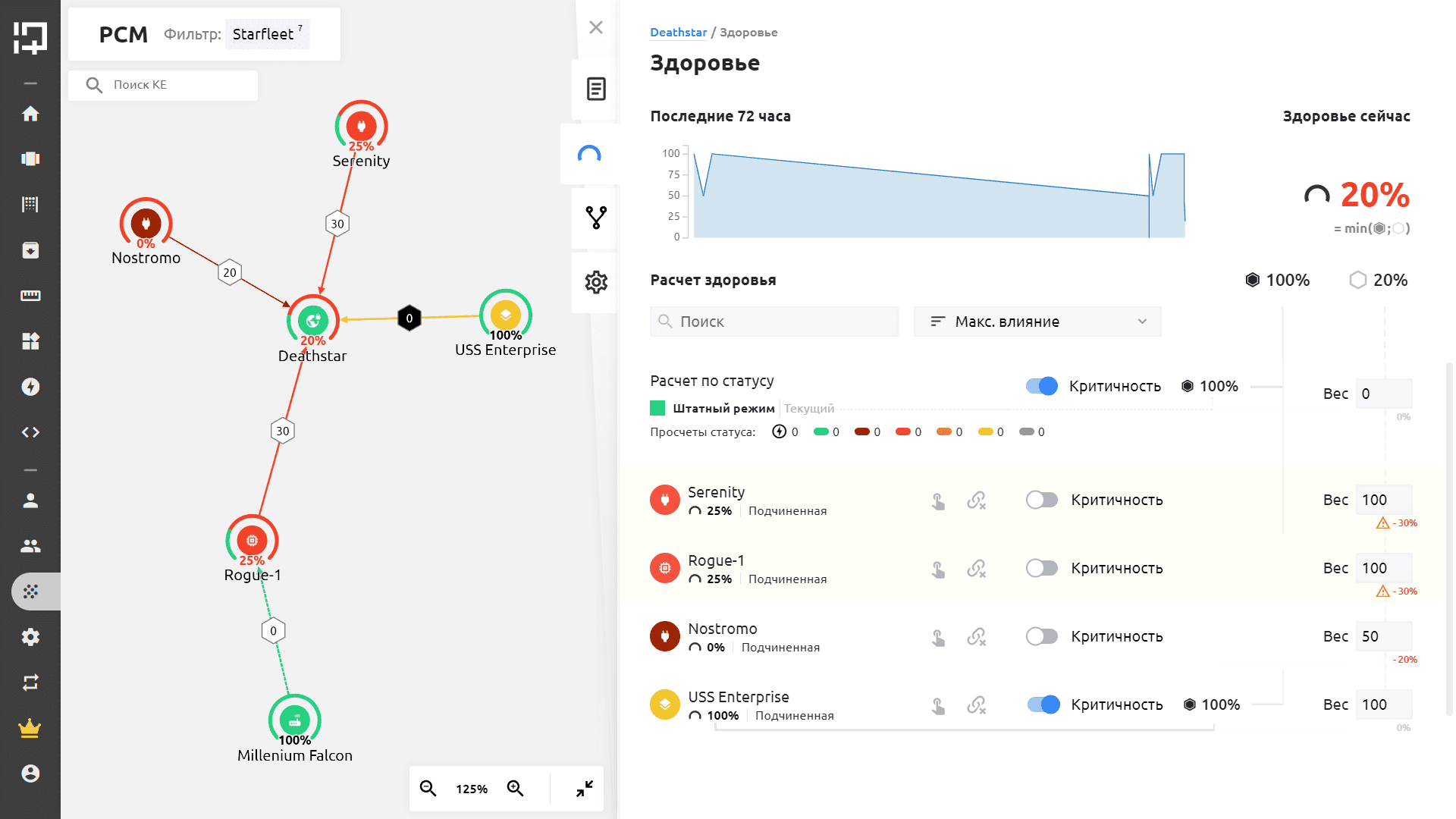
Экран MONQ: пример карты цифрового здоровья сервиса
5. Автоматизация. Все, что инженер делает удаленно, можно запрограммировать в скрипте автоматизации. Когда решение инцидента понятно, чтобы каждый раз не выполнять однотипные операции можно написать скрипт, который будет выполняться автоматически. Некоторые специалисты пишут свои скрипты и используют систему и как базу знаний, и как средство быстрого запуска скриптов. Это позволяет избавиться от ошибок. Система разграничения прав не допустит несанкционированное распространения информации, так как у инженера могут быть права на исполнения скрипта, но пароль к серверу ему будет недоступен.
Экран MONQ: запись скрипта автоматизации
Кейс #1. Как избавиться от вечных пожаров и перейти от реактивного мониторинга к проактивным действиям
Как AIOps работает на практике, можно увидеть на кейсе одного из банков. Это классическая история, где событий в ИТ было очень много: десятки инженеров круглосуточно смотрели в экраны и физически не могли отреагировать на все события. Падала доступность сервисов, клиенты и сотрудники замечали сбои раньше ИТ и жаловались. Свою роль играли и подрядчики, которые регистрировали не все инциденты, необоснованно завышая себе KPI.
Как в таком случае помог AIOps?
1. Настроили зонтичный мониторинг. Информационный шум снизился: объем бессмысленных алертов сократился на 90%. Инженеры начали реагировать на действительно важные события.
2. Запустили мониторинг пользовательского опыта, настроили мониторинг синтетических транзакций. В любой момент времени стало понятно, как чувствует себя тот или иной сервис и как он работает в глазах пользователей.
3. Запустили автоназначение инцидентов. Все события фиксируются, хранятся и анализируются — подрядчик получает выплаты по контракту только за действительно выполненные SLA.
Таким образом, время реагирования на сбои сократилось с 30 до 15 минут, доступность сервисов выросла с 98,5% до 99,7%, а затраты на ИТ за счет автоматического инцидент-менеджмента сократились на 30%.
Кейс #2. Как подружить ИБ и ИТ?
Разное понимание состояния инфраструктуры и сервисов в ИТ и ИБ — еще один частый кейс. Например, на одном из кейсов внедрения MONQ крупный крупном интернет-магазине мы столкнулись с ситуацией, когда периодически клиенты сталкиваются с отказом в доступе. Бизнес идет за пояснениями к ИТ, где кивали на ИБ и их WAF, который якобы трафик и режет хорошие запросы клиентов. В этот момент ИБ, который не обладает своими средствами мониторинга, обращается к поставщику сервиса и спрашивает у них логи, они вместе расследуют, что было причиной сбоя. В итоге время упущено, репутация потеряна.
Ситуацию исправили в несколько простых шагов:
1. Собрали логи о работе WAF
2. Построили метрику здоровья сервиса
3. Вывели на общий для ИТ и ИБ экран здоровья портала влияние балансировщика и низлежащего ИТ и ИБ-средств. Стало сразу понятно, где причина сбоя. Не все ddos одинаково опасные, и ИБ стало понятно, какая атака приводит к деградации сервиса для клиентов, а какая — нет.
AIOps помог не только разрешить конфликт ИБ-эксплуатации и повысить защищенность, но и дважды ускорить скорость расследования инцидентов.