
Предсказание заражения рабочих станций как практический пример использования технологий Big Data и машинного обучения
В настоящее время никого не удивить программами, блокирующими вредоносное ПО при обнаружении малейших признаков его присутствия.
Автор: Екатерина Купчихина, инженер отдела средств защиты информации InnoSTage
В настоящее время никого не удивить программами, блокирующими вредоносное ПО при обнаружении малейших признаков его присутствия. Но в начале этого года на Kaggle (крупнейшая платформа для специалистов по машинному обучению и анализу данных) прошло соревнование Microsoft Malware Prediction https://www.kaggle.com/c/microsoft-malware-predict..., поставившее цель не просто обнаружить вредонос, но и предсказать его появление на машине еще до ее заражения.
Денежный приз этого соревнования составлял $25,000. Любое мероприятие, на которое Microsoft выделяет такие суммы, заслуживает внимания, даже если конечной целью было всего лишь продвижение своего продукта. Также в числе спонсоров соревнования Windows Defender ATP Research и университеты Northeastern University College of Computer and Information Science и Georgia Tech Institute for Information Security & Privacy. Компания Microsoft предоставила около 10 Гб обезличенной информации с 17 миллионов девайсов. В нее входят категориальные признаки машин, такие как тип устройства, версия и тип операционной системы, количество установленного антивируса и т.д. То есть вся та информация, что доступна службе Windows Defender ATP. Таким образом, идея вполне оправдана: опасный паттерн из данных параметров будет сигнализировать защитнику Windows о том, что его хозяин вскоре будет атакован вредоносом, и необходимо обновиться до более поздней версии, чтобы это предотвратить.
В теории от того, насколько хорошо участники соревнования справились с этой задачей, зависит число зараженных машин в будущем. Но только в теории: если считать, что появление уязвимостей нулевого дня коррелирует с теми же признаками, что и уже известные. На практике же появление зловредов – проблема более комплексная, зависящая и от таких параметров, как, например, поведение пользователя, которые не могут быть доступны службе Windows Defender ATP. Поэтому надеяться на то, что участники соревнования покажут 99 % точность, было бы глупо. Забегая вперед, заметим, что лучший результат показал участник с 67% точностью. То, что было предоставлено организаторами – это всего лишь косвенные признаки зараженных и незараженных машин, но никак не напрямую влияющие на заражение. Таким образом, мы ограничиваем свое видение прямых причин появления зловредов. Но машинное обучение – это не универсальное решение для любой задачи. Прежде всего нужно понимать постановку задачи и продумать датасет (набор данных, на котором обучаются и тестируются модели) для обучения – те данные, которые помогут модели.
Это уже не первое соревнование Microsoft и Kaggle на тему вредоносов. В 2015 году проводилось соревнование: https://www.kaggle.com/c/ malware-classification, где необходимо было классифицировать вредоносный файл как один из девяти классов: Ramnit, Lollipop, Kelihos_ver3, Vundo, Simda, Tracur, Kelihos_ ver1, Obfuscator.ACY или Gatak. Всего в датасете было порядка 0,5 Тб данных, содержащих код на Ассемблере.
Победитель соревнования, команда «say NOOOOO to overfittttting», показавшая 99% точность, использовала ансамбль из трех Xgboost-моделей, обученных с частичным привлечением учителя. В числе методов, которые они использовали, алгоритм Apriori, который предназначен для поиска наиболее часто встречающихся элементов – команда использовала его, чтобы найти циклы в программном коде.
Несмотря на объемный датасет того соревнования, в обучающей выборке было чуть более 10 тысяч вредоносов. В новом же соревновании количество элементов в обучающей выборке значительно больше – почти 9 млн. Однако не все так безоблачно, как может показаться, глядя на такую цифру. Некоторые признаки пусты у 99% элементов выборки. 26 признаков принимают одно и то же значение у 90% элементов. Это значит, что с точки зрения машинного обучения данные признаки бесполезны. Итого остается около пяти десятков характеристик, на основании которых должна обучиться модель. В то время как Joshua Saxe и Hillary Sanders в своей книге «Malware Data Science» говорят о том, что современные обнаружители вредоносных файлов используют тысячи, а то и миллионы характеристик.
Участниками соревнований была выявлена следующая статистика на основании предоставленного датасета.
- Из десяти самых популярных версий антивируса защитника Windows доля заражений машин, на которых была установлена версия защитника 1.273. была выше, чем у машин с версией 1.275. (Рис. 1)
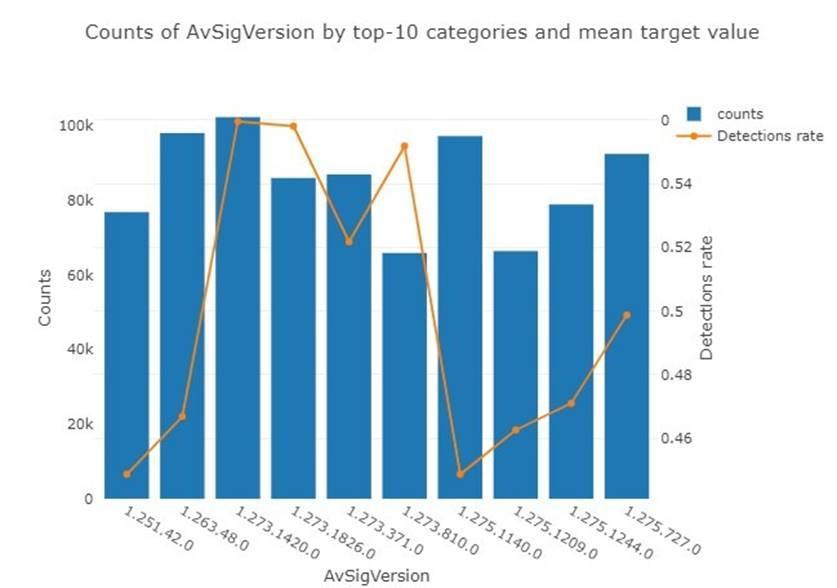
Рис. 1
-
Средняя доля заражений с версией 1.275 = 0,49, а с версией 1.273 = 0,53.
-
Среди машин, на которых установлен всего один антивирус, число зараженных было больше, чем незараженных. (Рис. 2)
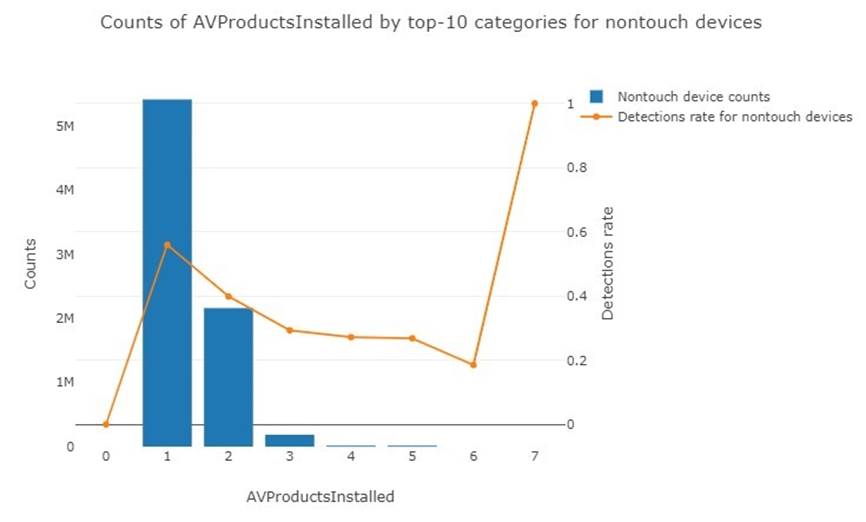
Рис. 2
- Чем больше количество ядер, тем больше доля заражений. У двухъядерных – 0,46, четырех ядерных – 0,52, восьми ядерных – 0,56. (Рис. 3)
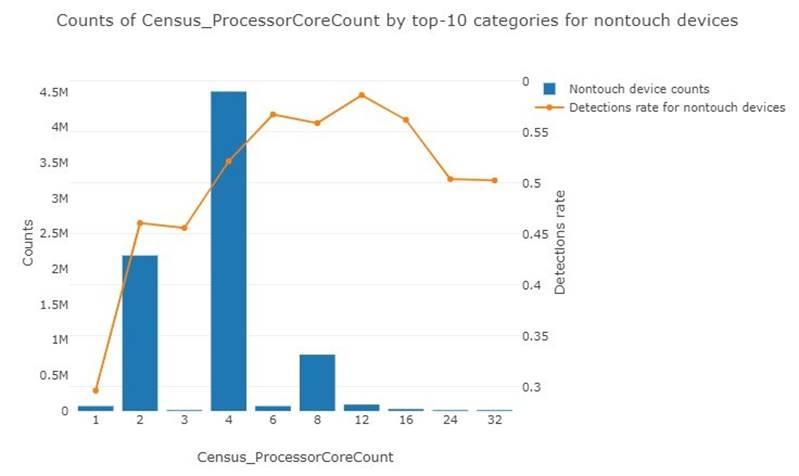
Рис. 3
- Такая же ситуация с ОЗУ: 2 Гб – 0,43, 4 Гб – 0,50, 8 Гб – 0,54, 16 Гб – 0,57. (Рис. 4)
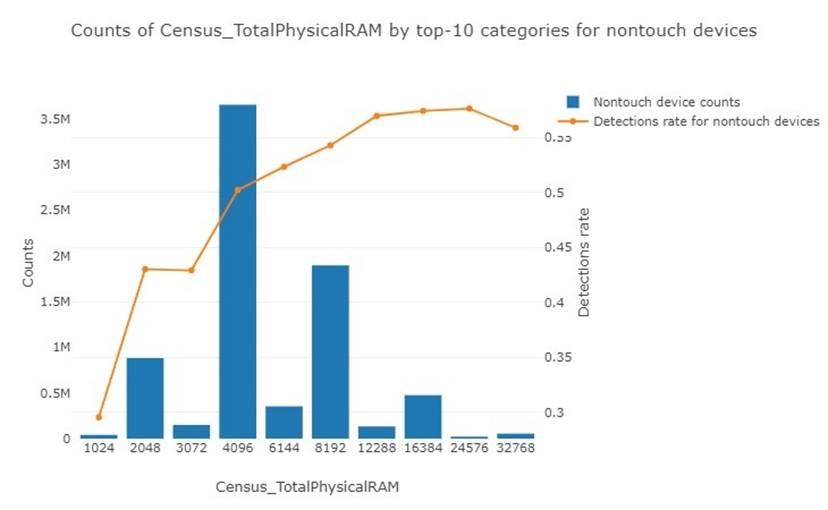
Рис. 4
На самом деле, это не значит, что больше половины компьютеров с оперативной памятью в 16 Гб, заражены. Дело в том, что классы зараженных и незараженных машин сбалансированы: в обучающей выборке 49,98% машин с вредоносом и 50,02% – без. Поэтому отклонение в несколько процентов в таком наборе данных – значительное заявление о важности того или иного параметра.
Победитель данного соревнования, команда «abuurista», к сожалению, не раскрыла свой способ решения. Только две из пяти команд, получивших денежный приз, рассказали о своих методах: они использовали дерево решений LightGBM. Если посмотреть на модели, которые участники выкладывали в обсуждения, то можно заметить, что именно это дерево решений и занимает львиную долю всех решений. По существу, участники соревновались в обработке исходных данных и подборе гиперпараметров данного дерева.
Но не стоит забывать, что модели решений на данном соревновании показывают точность в 67% на машинах с уже известными заражениями. И тот факт, что какие-то признаки коррелируют с присутствием заражения, еще не означает, что у этих признаков есть причинно-следственная связь. Таким образом, при появлении нового вируса или эксплойта, который будет использовать принципиально другие методы, данная модель окажется бессильной.
Как призывают авторы книги «Malware Data Science», в наше время безопасность в целом следует рассматривать как задачу Big Data. Применение алгоритмов машинного обучения с использованием большого количества данных – необходимое условие в борьбе с вредоносным ПО, и новое соревнование Kaggle – важный шаг в этом направлении. Поэтому если в компании есть большой собственный пул серверов или ПК, на которых огромное количество информативных данных, можно попробовать использовать их для создания собственной модели Big Data. В качестве задачи может выступить не только предсказание вредоносов, а в качестве датасета – не только категориальные признаки машин. Это может быть и анализ трафика, и обнаружение уязвимостей, и выявление аномалий. На Kaggle есть множество примеров таких решений – главное, чтобы было желание.