
Советы и трюки по анализу данных в Microsoft Excel в сфере информационной безопасности
В этой статье мы рассмотрим разные трюки в Экселе, используемые для совместного анализа разнородных типов данных.
Авторы: Jake Nicastro, David Pany
Во время расследования инцидентов зачастую приходится сталкиваться с нестандартными типами данных, доступными на хосте, когда нельзя обойтись исключительно готовыми инструментами для парсинга и анализа. Мы в компании постоянно встречаемся с инцидентами, в которые вовлечены разные системы и решения, использующие нестандартные логи и информационные артефакты. Расследование инцидентов обычно требует глубокого погружения и изучения типов данных, а также разработки эффективных методик выявления и анализа наиболее важных фактов и свидетельств.
Один из наиболее эффективных инструментов для выполнения подобного анализа - Microsoft Excel, доступный практически всегда и полезный при решении широкого спектра задач. В этой статье мы рассмотрим разные трюки в Экселе, используемые для совместного анализа разнородных типов данных.
Объединение разных типов данных в одну таблицу
Утилиты наподобие FireEye Redline включают в себя функции для объединения разных типов событий в единой временной шкале. При использовании индивидуальных парсеров или артефактов в нестандартном формате бывает сложно объединить разнородной информации общую картину. Нормализация данных при помощи Excel в один набор с простыми и понятными столбцами позволяет состыковать разные типы.
В качестве примера рассмотрим файловую систему, журнал событий и данные из реестра для анализа в общем контексте на основе следующих таблиц.
|
$SI Created |
$SI Modified |
File Name |
File Path |
File Size |
File MD5 |
File Attributes |
File Deleted |
|
2019-10-14 23:13:04 |
2019-10-14 23:33:45 |
Default.rdp |
C:\Users\ |
485 |
c482e563df19a40 |
Archive |
FALSE |
|
Event Gen Time |
Event ID |
Event Message |
Event Category |
Event User |
Event System |
|
2019-10-14 23:13:06 |
4648 |
A logon was attempted using explicit credentials. |
Logon |
Administrator |
SourceSystem |
|
KeyModified |
Key Path |
KeyName |
ValueName |
ValueText |
Type |
|
2019-10-14 23:33:46 |
HKEY_USER\Software\Microsoft\Terminal Server Client\Servers\ |
DestinationServer |
UsernameHInt |
VictimUser |
REG_SZ |
Поскольку вышеуказанные необработанные наборы данных имеют разные колонки и типы, довольно трудно проводить анализ в общем контексте. Если мы отформатируем данные при помощи конкатенации строк в Экселе, то сможем легко скомбинировать информацию в единую систему. Для форматирования можно использовать оператор «&» вместе с функцией присоединения, которая может пригодиться в поле с итогами.
Пример команды для объединения данных, имеющих отношение к файловой системе и разделенных амперсантами, может выглядеть так: “=D2 & " | " & C2 & " | " & E2 & " | " & F2 & " | " & G2 & " | " & H2”. Комбинируя эту функцию форматирования в сочетании с колонками «Timestamp» и «Timestamp Type» мы можем получить все информацию для первичного анализа.
|
Timestamp |
Timestamp Type |
Event |
|
2019-10-14 23:13:04 |
$SI Created |
C:\Users\attacker\Documents\ | Default.rdp | 485 | c482e563df19a401941c99888ac2f525 | Archive | FALSE |
|
2019-10-14 23:13:06 |
Event Gen Time |
4648 | A logon was attempted using explicit credentials. |
|
2019-10-14 23:33:45 |
$SI Modified |
C:\Users\attacker\Documents\ | Default.rdp | 485 | c482e563df19a401941c99888ac2f525 | Archive | FALSE |
|
2019-10-14 23:33:46 |
KeyModified |
HKEY_USER\Software\Microsoft\Terminal Server Client\Servers\ | DestinationServer | UsernameHInt | VictimUser |
После объединения трех разных таблиц и сортировки полученной информации по полю timestamp обнаруживается, что с аккаунта «DomainCorp\Administrator» из системы «SourceSystem» было подключение к серверу «DestinationServer» при помощи учетной записи «DomainCorp\VictimUser» через RDP.
Преобразование часовых поясов
Один из наиболее важных элементов при своевременной реакции на инциденты и криминалистическом анализе – хронометраж событий. Временной анализ позволяет выявить новые свидетельства, когда становится понятно, что происходило до или после интересующего нас события. Не менее важен точный хронометраж в отчетах. Однако стыковка времени может стать проблемой, если анализируемые системы находятся в разных часовых поясах. Мы в компании Mandiant преобразуем все временные метки в формат UTC (Coordinated Universal Time; Всемирное скоординированное время), чтобы исключить путаницу между часовыми поясами и учесть специфические настройки, как, например, переход на летнее время и региональные летние сезоны.
Конечно, в разных системах фиксируемое время событий не всегда находится в одном формате. Иногда мы можем иметь дело с местным временем, иногда в формате UTC, и, как упоминалось ранее, разные географические локации сильно усложняют жизнь. При объединении данных в единой временной шкале вначале важно разобраться, какой формат используется в логах источника: локальное время или UTC. Если в логах используется локальное время, нужно уточнить, в каком часовом поясе находится источник, а затем воспользоваться функцией TIME() (в Экселе) для преобразования временных меток в формат UTC.
Сценарий, описанный ниже – пример реального расследования, когда компания оказалась скомпрометирована через фишинговые письма, и информация о выплатах сотрудникам в безналичной форме была изменена через внутреннее приложение по учету кадров. В этой ситуации у нас есть информация из трех источников: логи электронной почты, логи авторизаций и веб-логи приложения.
Логи электронной почты хранят время в формате UTC и содержат следующую информацию:

Рисунок 1: Логи электронной почты
Логи авторизаций хранят время в формате EDT (Eastern Daylight Time; Восточное Дневное Время) и содержат следующую информацию:

Рисунок 2: Логи авторизаций
Веб-логи приложения также хранят время в формате EDT и содержат следующую информацию:

Рисунок 3: Веб-логи приложений
Чтобы объединить три вышеуказанные таблицы, мы можем воспользоваться функцией CONCAT (которая является альтернативой оператору &) и объединить ячейки в одну для каждой строки лога. Пример формулы для логов электронной почты может выглядеть так:
![]()
Рисунок 4: Пример формулы для объединения ячеек
И здесь проверка часовых поясов для каждого источника данных начинает играть решающую роль. Если мы возьмем информацию в том виде, как есть в логах, не учтем часовые пояса и объединим в единую временную шкалу, то получим примерно следующее:
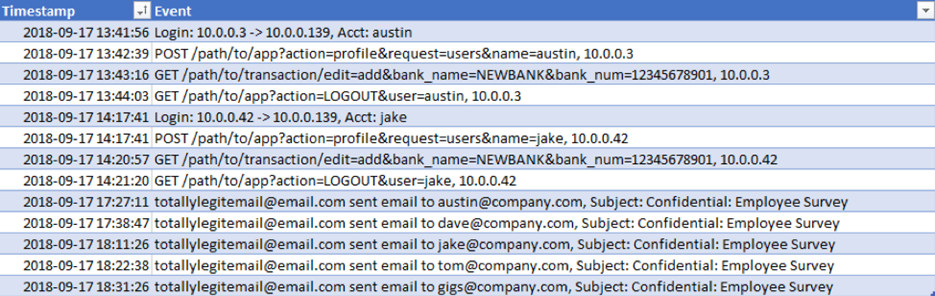
Рисунок 5: Объединение всех логов в единую таблицу
Как показано на предыдущем скриншоте, у нас есть несколько авторизаций в приложении по учету кадров, которые могут выглядеть как обычная активность сотрудников. Затем в течение дня было получено несколько подозрительных писем. Если бы у нас было сотни строк логов, мы могли бы пропустить события авторизаций и события на веб-сервере, поскольку время активности на несколько часов предшествует подозрительному изначальному вектору компрометирования. В случае отчетности эта временная шкала также была бы некорректной.
Когда мы знаем, в каком часовом поясе находится источники логов, то можем преобразовать соответствующие временные метки в формат UTC. В этом случае посредством тестирования мы выяснили, что логи авторизаций и веб-логи записаны в формате EDT, который на 4 часа предшествует времени в формате UTC (или «UTC-4»). Соответственно, для преобразования этих временных меток в формат UTC нужно добавить 4 часа. Например, при помощи функции TIME. Можно просто добавить еще одну колонку к уже существующим таблицам и в первую ячейку занести формулу «=A2+TIME(4,0,0)», смысл которой заключается в следующем:
- =A2
- Ссылка на ячейку A2 (в нашем случае – временная метка в формате EDT). Обратите внимание, что ссылка не абсолютная, и мы можем использовать эту формулу в остальных строках.
- +TIME
- Эта функция говорит Экселю, что нужно взять значение из ячейки A2 в формате «time» и добавить нужное количество времени.
- (4,0,0)
- В нашем примере для функции TIME нужно три аргумента: часы, минуты, и секунды. Мы добавляем 4 часа, 0 минут и 0 секунд.
Теперь у нас есть формула для преобразования времени из EDT в формат UTC посредством добавления четырех часов. Затем переносим эту формулу на остальные ячейки таблица и в результате получаем следующее:
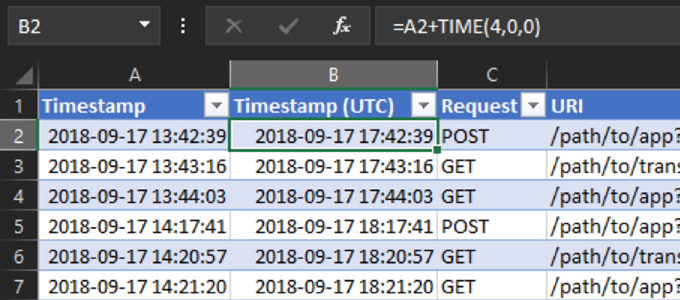
Рисунок 6: Время веб-логов, преобразованное в формат UTC
После преобразования времени мы можем объединить логи в единой временной шкале:
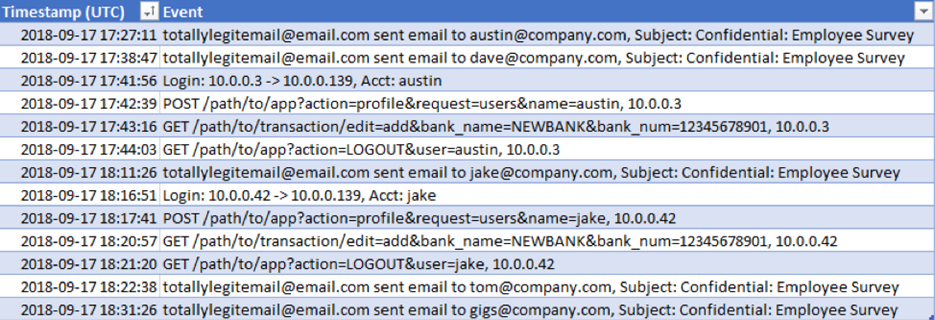
Рисунок 7: Преобразованные логи в единой временной шкале
Теперь мы четко видим подозрительные письма отосланные (фиктивным) сотрудникам Остину и Дэйву. Через несколько минут с аккаунта Остина произошла авторизация в приложении по учету кадров и добавлен новый банковский счет. Затем мы видим то же самое письмо, отосланной Джэйку и последующую авторизацию в приложении с добавлением того же самого банковского счета, как и в случае с Остином. Таким образом, конвертирование времени в единый формат при помощи Экселя позволило нам быстро связать события воедино и понять, что сделал злоумышленник. Кроме того, мы обнаружили новые индикаторы, как, например, номер банковского счета для поиска в других логах.
Совет от профессионалов: обязательно учитывайте данные логов, которые смещены относительно времени в формате UTC (из-за перехода на летнее время или летних периодов). Например, алгоритм конвертации часового пояса должен быть изменен для логов, хранящих время в формате восточного времени США в Вирджинии, с +TIME(5,0,0) на +TIME(4,0,0) в первый уикэнд марта каждый год и обратно с +TIME(4,0,0) на +TIME(5,0,0) в ноябре для учета перехода на летнее время и стандартных сдвигов.
Функция CountIf для компоновки логов
При анализе логов, фиксирующих события, связанные с аутентификацией в формате аккаунт-временная метка, то можем воспользоваться функцией COUNTIF для получения простых показателей для идентификации учетных записей с подозрительной активностью.
В качестве примера воспользуемся формулой «=COUNTIF($B$2:$B$25,B2)» для выявления исторической линии. Рассмотрим эту формулу, находящуюся в ячейке C2, более подробно:
- COUNTIF
- Экселевская функция COUNTIF позволяет посчитать, как много раз значение встречается в диапазоне ячеек.
- $B$2:$B$25
- Полный диапазон всех ячеек от B2 до B25, который мы хотим использовать для поиска определенного значения. Символ «$» в начальной и конечной ячейке диапазона говорит об использовании абсолютных ссылок, которые не обновляются при копировании формулы в другие ячейки.
- B2
- Эта ячейка содержит значение, которые мы ищем и считаем вхождения в диапазоне $B$2:$B$25. Обратите внимание, что в этом параметре не используется абсолютная ссылка с символом «$». Таким образом, при копировании формулы в остальные строки будет учитываться соответствующее имя пользователя.
В итоге эта формула позволяет найти имя пользователя во всех событиях, связанных с авторизацией, и посчитать, сколько раз логинился каждый пользователь.
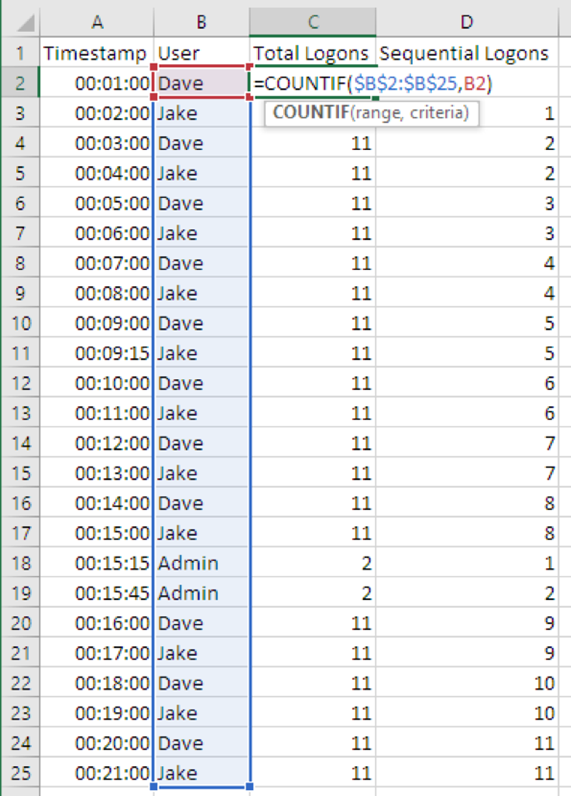
Рисунок 8: Подсчет количества авторизаций для каждого пользователя
Сравнение общего количества авторизаций может помочь в выявлении скомпрометированных учетных записей, используемых впервые. Если мы берем определенный промежуток времени, то может оказаться полезным узнать, какие аккаунты проходили авторизацию в этот период впервые.
Формула COUNTIF помогает отследить учетные записи в течение определенного периода времени для идентификации первой авторизации, что в свою очередь может помочь в выявлении редко используемых аккаунтов, которые были скомпрометированы в течение ограниченного временного отрезка.
Начнем с формулы «=COUNTIF($B$2:$B2,B2)» в ячейке D3. Обратите внимание, что символ "$" используется немного по-другому, и это важный нюанс:
- COUNTIF
- Экселевская функция COUNTIF позволяет посчитать, как много раз значение встречается в диапазоне ячеек.
- $B$2:$B2
- Это диапазон ячеек (от B2 до B2), с которым работаем. Поскольку мы хотим, чтобы диапазон увеличивался после перехода к следующей строке, перед числом второй ячейки не стоит символ «$» (соответственно, ссылка не является полностью абсолютной). По мере добавления этой формулы в последующие строки, диапазон будет автоматические увеличиваться и будет включать в себя текущую строку лога и все предыдущие строки.
- B2
- Эта ячейка содержит значение, вхождения которого мы хотим посчитать в указанном диапазоне. Обратите внимание, что параметр B2 не является абсолютной ссылкой с префиксом «$». Таким образом, мы можем добавлять эту формулу во все строки и считать вхождения соответствующего имени пользователя.
В итоге эта формула будет искать имя пользователя во всех предыдущих событиях, включая текущее, и считать количество соответствий на текущий момент.
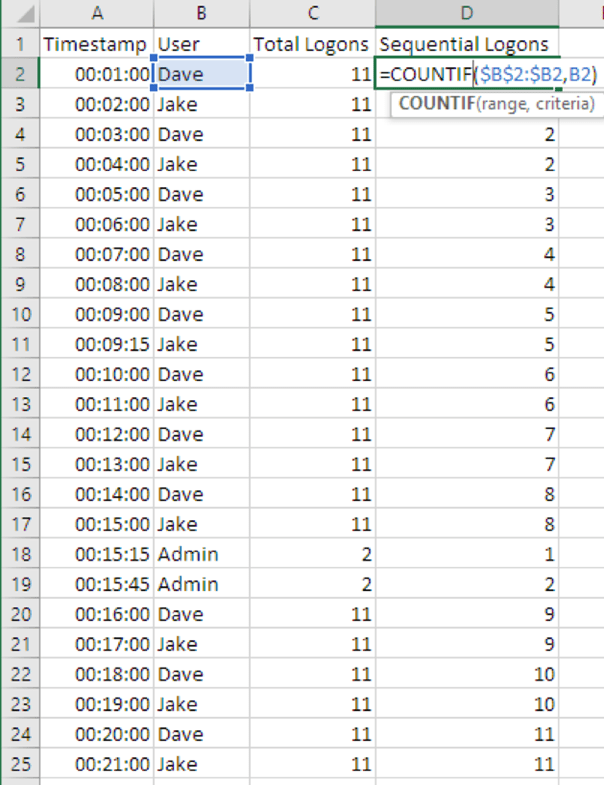
Рисунок 9: Формула для подсчета количества последовательных авторизаций
Пример ниже иллюстрирует, как Эксель автоматически обновляет диапазон в ячейке D15 при помощи обработчика заполнения.
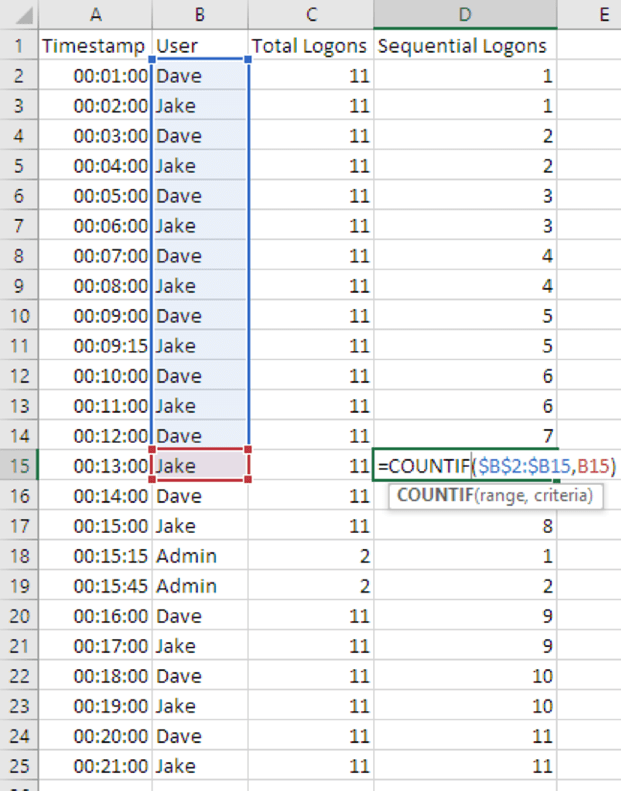
Рисунок 10: Автоматическое обновление диапазона при переходе к следующей строке
Для визуализации большого набора данных, в каждую строку добавим условное форматирование в виде цветовой шкалы:
-
Выберите ячейки, которые хотите сравнить с цветовой шкалой (например, от D2 до D25).
-
В Экселе во вкладке Home (Главная) кликните на кнопку Conditional Formatting (Условное форматирование) в разделе Styles (Стили).
-
Зайдите в раздел Color Scales (Цветовые шкалы).
-
Кликните на нужный тип цветовой шкалы.
В следующих примерах установлено, что ячейки с наименьшими значениями помечаются красным цветом, с наибольшими – зеленым. Соответственно, мы видим:
-
Отличия между пользователями с небольшим количеством аутентификаций и с высоким.
-
Ячейки, где пользователи проходили аутентификацию впервые, помечаются красным.
Какие бы цвета не использовались, будьте осторожны и не допускайте, чтобы один цвет (например, зеленый) ассоциировался с безопасностью, а другой (например, красный) – с вредоносностью.
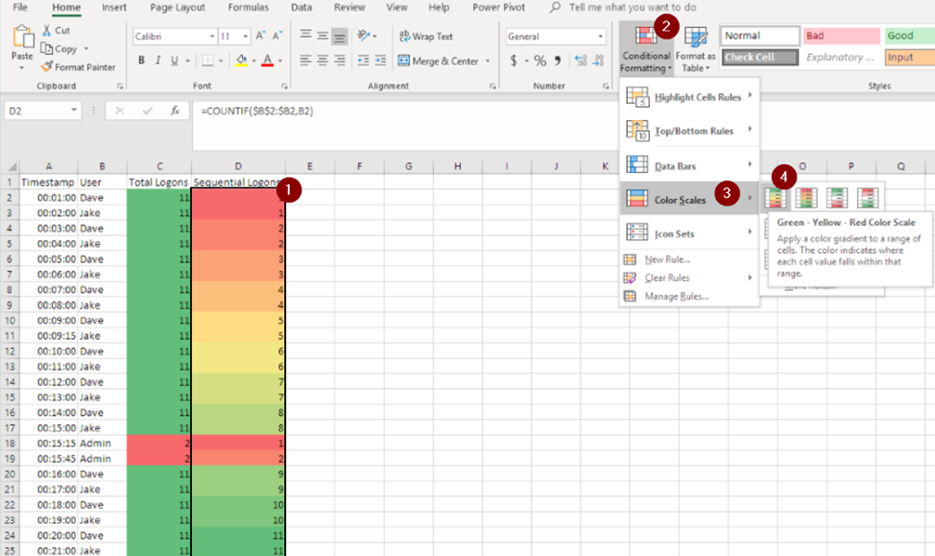
Рисунок 11: Пример цветового форматирования
Заключение
Техники, описанные в этой статье – лишь небольшая часть, которые можно использовать в Экселе для анализа произвольной информации. Хотя эти методы могут и не вовлекать более продвинутые функции Экселя, как и в любом деле, овладение основами впоследствии позволяет выйти на более высокий уровень. Используя фундаментальные методы анализа в Экселе, исследователь может работать с любым набором данных настолько эффективно, насколько возможно.