
Одна из базовых для DLP-систем задач - это обнаружение в потоке передаваемых данных различных государственных документов, удостоверяющих личность (паспорта, свидетельства о рождении, водительские удостоверения и т.п.), и предотвращение их несанкционированного распространения.

Если документы представлены в виде текстовых данных в электронных таблицах, базах данных и т.п., то обычно это не вызывает никаких проблем при условии, что DLP-система поддерживает контентную фильтрацию в принципе.
Однако, что делать, если речь идет о сканах документов?
Хочу на примере комплекса DeviceLock DLP показать, как можно создать DLP-политику, запрещающую печать на принтерах, отправку по электронной почте (SMTP) и заливку в облачные файловые хранилища сканов паспортов.
Особенность DeviceLock DLP состоит в том, что оптическое распознавание символов (OCR) производится непосредственно на компьютере пользователя резидентным OCR-модулем в составе DLP-агента, т.е. встроенный OCR позволяет извлекать текст из графических файлов и затем проверять его правилами, построенными на анализе содержимого передаваемых файлов и данных, непосредственно в момент совершения пользователем действий с этими файлами, без их передачи на сторонний OCR-сервер. Такая архитектура позволяет DeviceLock DLP быстро принимать решение о запрещении или разрешении пользовательской операции.
Отдельно хочу отметить, что агентская реализация DLP-системы принципиально исключает необходимость передачи пользовательских данных за пределы защищаемого компьютера для любого типа анализа, в том числе OCR, что позволяет успешно эксплуатировать DeviceLock DLP в странах с очень жестким законодательством в сфере охраны прав работников, например, в Германии и Франции.
В качестве тестового образца будем использовать этот скан российского паспорта в формате JPG.

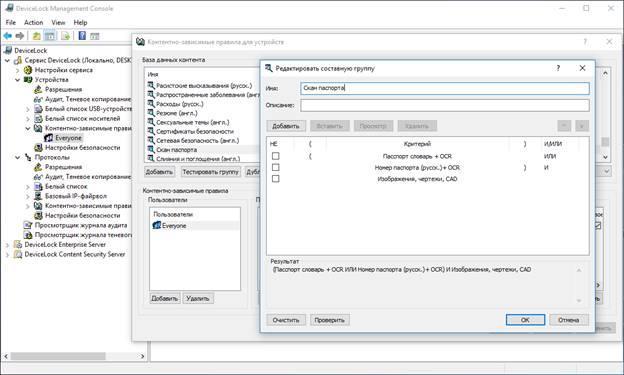
Для начала создадим составное правило контентной фильтрации. «Ловить» сканы паспортов мы будем по характерным для российского паспорта словам из встроенного в DeviceLock DLP словаря и по номерам, причем интерес для нас представляют только графические файлы (всего поддерживается более 30 графических форматов).
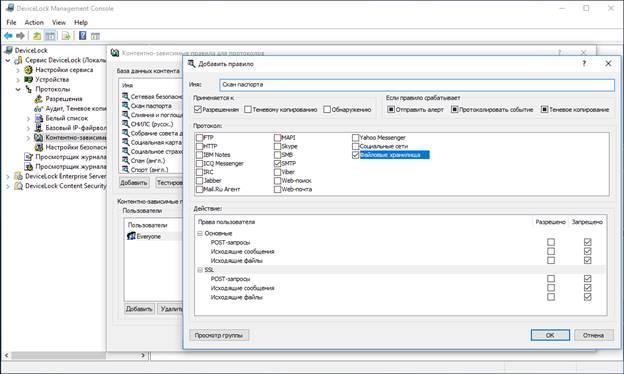
Затем применим правило контентной фильтрации к SMTP-протоколу, облачным хранилищам и принтерам. Согласно поставленной выше задаче – выставим запреты на отправку по сети и печать попавших под правило файлов.
ополнительно включим протоколирование действий пользователей, чтобы видеть в логах попытки передачи и печати сканов паспортов.
Теперь попробуем залить скан паспорта на Яндекс.Диск.
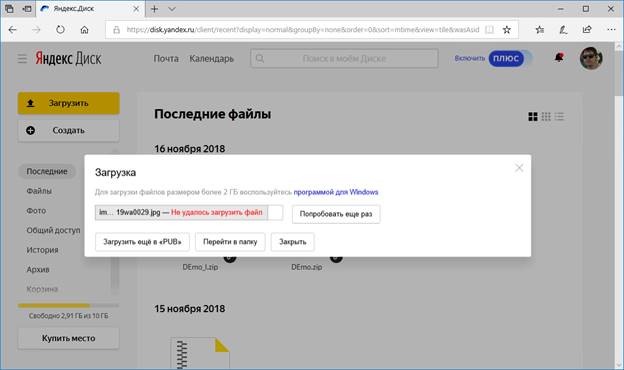
При этом в логе аудита создалась запись об этой неудачной попытке.
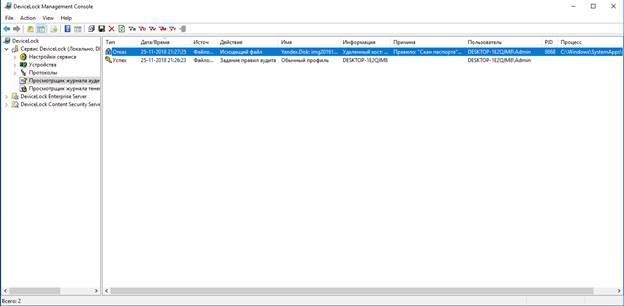
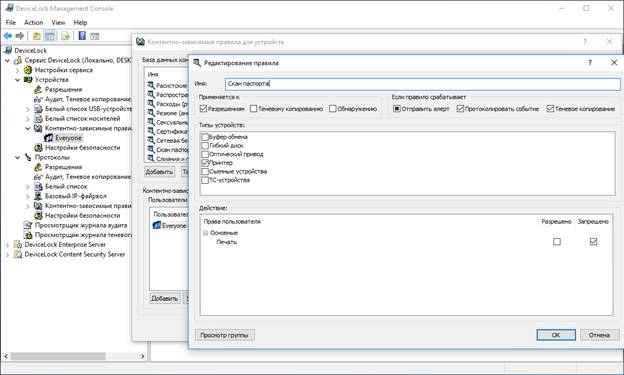
При попытке распечатать скан паспорта DeviceLock DLP остановит печать в момент отправки задачи на принтер и покажет вот такое сообщение.
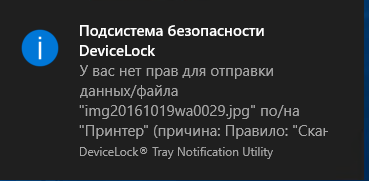
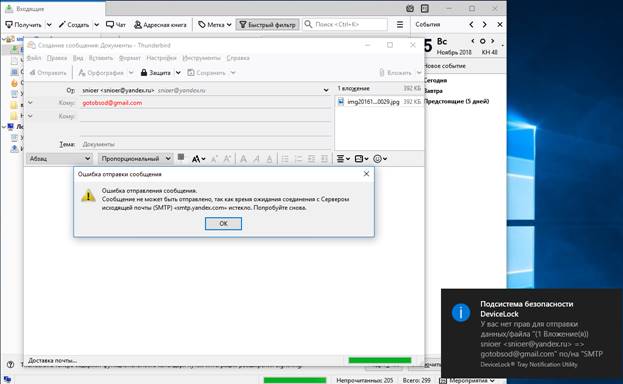
Неудача нас постигнет и в момент отправки скана по SMTP.
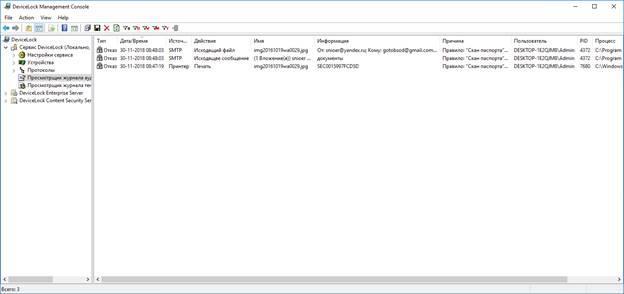
В логе аудита можно увидеть все следы.
В заключении хочу добавить, что DeviceLock DLP поддерживает оптическое распознавание символов (OCR) для всех основных языков, включая русский, английский, немецкий, китайский, японский и т.д. Текст может извлекаться из отсканированных документов, сфотографированных под углом до 90 градусов к фотографируемой поверхности документов, а также скриншотов документов.
Автор: Ашот Оганесян