
SQL команды, которые могут быть полезны во время пентестов
Не спорю, что на поиск уязвимостей уходит значительная часть времени, но реальную ценность для клиентов представляет демонстрация последствий, которые могут наступить после успешного проникновения.
Автор: Joshua Wright
Задача пентестера заключается не только в том, чтобы искать бреши и получать шеллы. Не спорю, что на поиск уязвимостей уходит значительная часть времени, но реальную ценность для клиентов представляет демонстрация последствий, которые могут наступить после успешного проникновения. Чтобы ответить на второй вопрос, лично я пытаюсь найти доступную информацию на скомпрометированной системе и оцениваю важность раскрытых сведений для клиента.
Зачастую информация извлекается из баз данных. Тут возможно два варианта. Либо SQL-база используется клиентом (MSSQL, SQLite3, MySQL, Oracle и т. д.), либо, бывает и такое, база создается мной, куда импортируются сведения из CSV-файлов, JSON-данных и других форматов. Как бывшему администратору баз данных мне очень нравится использовать SQL-запросы, и в этой статье я дам некоторые советы, которые помогут могут пригодиться во время пентестов.
В качестве примера будет использоваться база Pokémon Pokedex SQLite3, которая была собрана энтузиастами в рамках проекта veekun. Отдельное спасибо Eevee за проделанную работу.
Структуры данных
Чтобы выяснить структуру таблиц, индексов и других объектов, воспользуемся командой .schema:
sqlite> .schema
CREATE TABLE item_pockets (
id INTEGER NOT NULL,
identifier VARCHAR(79) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE pokeathlon_stats (
id INTEGER NOT NULL,
identifier VARCHAR(79) NOT NULL,
PRIMARY KEY (id)
);
...
Эта база данных имеет несколько таблиц. Если вы хотите выяснить структуру конкретной таблицы, укажите имя:
sqlite> .schema pokemon
CREATE TABLE pokemon (
id INTEGER NOT NULL,
identifier VARCHAR(79) NOT NULL,
species_id INTEGER,
height INTEGER NOT NULL,
weight INTEGER NOT NULL,
base_experience INTEGER NOT NULL,
"order" INTEGER NOT NULL,
is_default BOOLEAN NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(species_id) REFERENCES pokemon_species (id),
CHECK (is_default IN (0, 1))
);
CREATE INDEX ix_pokemon_order ON pokemon ("order");
CREATE INDEX ix_pokemon_is_default ON pokemon (is_default);
Обратите внимание, что команда .schema используется только в SQLite. В других базах данных используются схожие команды: SHOW TABLES и DESC tablename. Большинство остальных команд, о которых будет рассказано в этой статье, можно использовать во всех базах данных.
Извлечение данных
Мы будем извлекать информацию из базы данных при помощи инструкции SELECT (предварительно я ввел команду .headers, которая используется в SQLite3 для отображения наименования колонок):
sqlite> select * from pokemon;
id|identifier|species_id|height|weight|base_experience|order|is_default
1|bulbasaur|1|7|69|64|1|1
2|ivysaur|2|10|130|142|2|1
3|venusaur|3|20|1000|236|3|1
4|charmander|4|6|85|62|5|1
5|charmeleon|5|11|190|142|6|1
6|charizard|6|17|905|240|7|1
7|squirtle|7|5|90|63|10|1
8|wartortle|8|10|225|142|11|1
9|blastoise|9|16|855|239|12|1
10|caterpie|10|3|29|39|14|1
...
Если указать *, то в результатах запроса будут отображаться все колонки таблицы. Если хочется вывести отдельные колонки, нужно указать соответствующие имена в том порядке, в котором должны отображаться столбцы:
sqlite> select id, identifier, weight, height from pokemon;
id|identifier|weight|height
1|bulbasaur|69|7
2|ivysaur|130|10
3|venusaur|1000|20
4|charmander|85|6
5|charmeleon|190|11
6|charizard|905|17
7|squirtle|90|5
8|wartortle|225|10
9|blastoise|855|16
10|caterpie|29|3
...
В таблице pokemon много записей. Если, например, нужно вывести только 5 строк, в конце запроса доставьте LIMIT
5.
sqlite> select id, identifier, weight, height, "order" from pokemon limit 5;
id|identifier|weight|height|order
1|bulbasaur|69|7|1
2|ivysaur|130|10|2
3|venusaur|1000|20|3
4|charmander|85|6|5
5|charmeleon|190|11|6
Извлечение уникальных строк
Строки в таблице часто содержат одинаковые значения. Чтобы получить перечень уникальных строк, воспользуемся модификатором DISTINCT. Предположим, что у таблицы contest_type_names следующая структура:
sqlite> .schema contest_type_names
CREATE TABLE contest_type_names (
contest_type_id INTEGER NOT NULL,
local_language_id INTEGER NOT NULL,
name VARCHAR(79),
flavor TEXT,
color TEXT,
PRIMARY KEY (contest_type_id, local_language_id),
FOREIGN KEY(contest_type_id) REFERENCES contest_types (id),
FOREIGN KEY(local_language_id) REFERENCES languages (id)
);
CREATE INDEX ix_contest_type_names_name ON contest_type_names (name);
sqlite> select * from contest_type_names;
contest_type_id|local_language_id|name|flavor|color
1|5|Sang-froid|Épicé|Rouge
1|9|Cool|Spicy|Red
2|5|Beauté|Sec|Bleu
2|9|Beauty|Dry|Blue
3|5|Gr'ce|Sucré|Rose
3|9|Cute|Sweet|Pink
4|5|Intelligence|Amère|Vert
4|9|Smart|Bitter|Green
5|5|Robustesse|Acide|Jaune
5|9|Tough|Sour|Yellow
1|10||Ostrá|
5|10|Síla||
2|10|Krása|Suchá|
Для получения списка уникальных цветов используем следующий запрос:
sqlite> select distinct(color) from contest_type_names;
Rouge
Red
Bleu
Blue
Rose
Pink
Vert
Green
Jaune
Yellow
Условные выражения
Часто требуется получить отфильтрованный список строк. Ключевое слово WHERE позволяет указать условия для одной или нескольких колонок. Например, нам нужно получить только строки с идентификатором pikachu из таблицы pokemon.
sqlite> .schema pokemon
CREATE TABLE pokemon (
id INTEGER NOT NULL,
identifier VARCHAR(79) NOT NULL,
species_id INTEGER,
height INTEGER NOT NULL,
weight INTEGER NOT NULL,
base_experience INTEGER NOT NULL,
"order" INTEGER NOT NULL,
is_default BOOLEAN NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(species_id) REFERENCES pokemon_species (id),
CHECK (is_default IN (0, 1))
);
CREATE INDEX ix_pokemon_order ON pokemon ("order");
CREATE INDEX ix_pokemon_is_default ON pokemon (is_default);
sqlite> select * from pokemon where identifier = "pikachu";
id|identifier|species_id|height|weight|base_experience|order|is_default
25|pikachu|25|4|60|112|32|1
В дополнении к условию на точное совпадение в SQLite3 поддерживают и другие операторы сравнения:
|
Оператор |
Значение |
|
= |
Равно |
|
!= |
Не равно |
|
< |
Меньше, чем |
|
> |
Больше, чем |
|
<= |
Меньше или равно |
|
>= |
Больше или равно |
Предположим, нужно получить перечень идентификаторов, у которых высота меньше 4:
sqlite> select identifier from pokemon where height < 4;
caterpie
weedle
pidgey
rattata
spearow
paras
...
Можно использовать комбинированные условия. Например, мы хотим получить идентификаторы, у которых высота меньше 4, а вес больше 19. Обратите внимание, что я нажал Enter для переноса запроса на новую строку.
sqlite> select identifier, height, weight from pokemon
...> where height < 4 and weight > 190;
klink|3|210
durant|3|330
Шаблоны (wildcard)
SQL позволяет указывать специальные символы и ключевые слова в условных выражения внутри конструкции WHERE. Ключевое слово LIKE в сочетании с символом _ позволяет найти совпадения по одиночному символу, а в сочетании с символом % - совпадения по группе символов. Допустим, нужно вывести все строки таблицы, у которых значения в колонке genus начинаются с символов Dr:
sqlite> .schema pokemon_species_names
CREATE TABLE pokemon_species_names (
pokemon_species_id INTEGER NOT NULL,
local_language_id INTEGER NOT NULL,
name VARCHAR(79),
genus TEXT,
PRIMARY KEY (pokemon_species_id, local_language_id),
FOREIGN KEY(pokemon_species_id) REFERENCES pokemon_species (id),
FOREIGN KEY(local_language_id) REFERENCES languages (id)
);
CREATE INDEX ix_pokemon_species_names_name ON pokemon_species_names (name);
sqlite> select name, genus from pokemon_species_names where genus like 'Dr%';
name|genus
Nidoqueen|Drill
Nidoking|Drill
Rhydon|Drill
Hypotrempe|Dragon
Seeper|Drache
Horsea|Dragón
Horsea|Drago
Horsea|Dragon
...
Simipour|Drenaje
Munna|Dream Eater
Musharna|Drowsing
Muplodocus|Dragon
Viscogon|Drache
Goodra|Dragón
...
Обратите внимание, что в списке выше присутствуют значения Dragon и Dragón. Если мы хотим вывести строки только с шаблоном «Drag n», то используем модификатор _:
sqlite> select name, genus from pokemon_species_names where genus like 'Drag_n';
name|genus
Hypotrempe|Dragon
Horsea|Dragón
Horsea|Dragon
Hypocéan|Dragon
Seadra|Dragón
Seadra|Dragon
Minidraco|Dragon
Dratini|Dragón
Dratini|Dragon
Draco|Dragon
...
Если добавить % слева и справа от группы символов, то отобразятся все значения, у которых эта группа символов находится внутри. Например, выведем все строки, у которых внутри значений из колонки genus находится слово eat:
sqlite> select name, genus from pokemon_species_names
...> where genus like '%eat%';
name|genus
Castform|Weather
Munchlax|Big Eater
Munna|Dream Eater
Heatmor|Anteater
Следует отметить, что условию %eat% будут соответствовать в том числе строки, у которых слово eat находится или начале или в конце (в этом случае не обязательно, чтобы последующие и предыдущие символы удовлетворяли условию).
Сортировка данных
Для того чтобы отсортировать отображаемые данные, нужно в директиве ORDER BY указать имя колонки, по которой требуется сортировка. Можно осуществлять сортировку по нескольким столбцам. В этом случае указывается несколько имен, разделенных через запятую. По умолчанию сортировка будет в порядке возрастания. Чтобы поменять порядок, нужно добавить ключевое слово DESCENDING в конце выражения с ORDER BY.
В качестве примера рассмотрим таблицу abilities из базы данных Pokémon, где находится информация об идентификаторах. По умолчанию сортировка происходит по полю id. Чтобы поменять порядок сортировки, добавим оператор ORDER BY и колонку generation_id.
sqlite> .schema abilities
CREATE TABLE abilities (
id INTEGER NOT NULL,
identifier VARCHAR(79) NOT NULL,
generation_id INTEGER NOT NULL,
is_main_series BOOLEAN NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(generation_id) REFERENCES generations (id),
CHECK (is_main_series IN (0, 1))
);
CREATE INDEX ix_abilities_is_main_series ON abilities (is_main_series);
sqlite> select * from abilities order by generation_id;
id|identifier|generation_id|is_main_series
1|stench|3|1
2|drizzle|3|1
3|speed-boost|3|1
4|battle-armor|3|1
5|sturdy|3|1
6|damp|3|1
7|limber|3|1
...
162|victory-star|5|1
163|turboblaze|5|1
164|teravolt|5|1
10001|mountaineer|5|0
10002|wave-rider|5|0
10003|skater|5|0
10004|thrust|5|0
10005|perception|5|0
...
189|primordial-sea|6|1
190|desolate-land|6|1
191|delta-stream|6|1
Запросы с несколькими таблицами
Когда начинающие разработчики проектируют базу данных, то пытаются всю информацию хранить в одной таблице, что не очень разумно с точки зрения эффективности. Впоследствии, редко изменяющиеся данные или данные, которые должны быть изолированы, помещаются в отдельную таблицу и связываются с записями из других таблиц общими идентификаторами, чтобы можно было получать результаты из нескольких таблиц одновременно.
В качестве примера рассмотрим таблицы pokemon_species и pokemon_species_names (визуальное проектирование выполнялось в WWW SQL Designer).
sqlite> .schema pokemon_species
CREATE TABLE pokemon_species (
id INTEGER NOT NULL,
identifier VARCHAR(79) NOT NULL,
generation_id INTEGER,
evolves_from_species_id INTEGER,
evolution_chain_id INTEGER,
color_id INTEGER NOT NULL,
shape_id INTEGER NOT NULL,
habitat_id INTEGER,
gender_rate INTEGER NOT NULL,
capture_rate INTEGER NOT NULL,
base_happiness INTEGER NOT NULL,
is_baby BOOLEAN NOT NULL,
hatch_counter INTEGER NOT NULL,
has_gender_differences BOOLEAN NOT NULL,
growth_rate_id INTEGER NOT NULL,
forms_switchable BOOLEAN NOT NULL,
"order" INTEGER NOT NULL,
conquest_order INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(generation_id) REFERENCES generations (id),
FOREIGN KEY(evolves_from_species_id) REFERENCES pokemon_species (id),
FOREIGN KEY(evolution_chain_id) REFERENCES evolution_chains (id),
FOREIGN KEY(color_id) REFERENCES pokemon_colors (id),
FOREIGN KEY(shape_id) REFERENCES pokemon_shapes (id),
FOREIGN KEY(habitat_id) REFERENCES pokemon_habitats (id),
CHECK (is_baby IN (0, 1)),
CHECK (has_gender_differences IN (0, 1)),
FOREIGN KEY(growth_rate_id) REFERENCES growth_rates (id),
CHECK (forms_switchable IN (0, 1))
);
CREATE INDEX ix_pokemon_species_order ON pokemon_species ("order");
CREATE INDEX ix_pokemon_species_conquest_order ON pokemon_species (conquest_order);
sqlite> .schema pokemon_species_names
CREATE TABLE pokemon_species_names (
pokemon_species_id INTEGER NOT NULL,
local_language_id INTEGER NOT NULL,
name VARCHAR(79),
genus TEXT,
PRIMARY KEY (pokemon_species_id, local_language_id),
FOREIGN KEY(pokemon_species_id) REFERENCES pokemon_species (id),
FOREIGN KEY(local_language_id) REFERENCES languages (id)
);
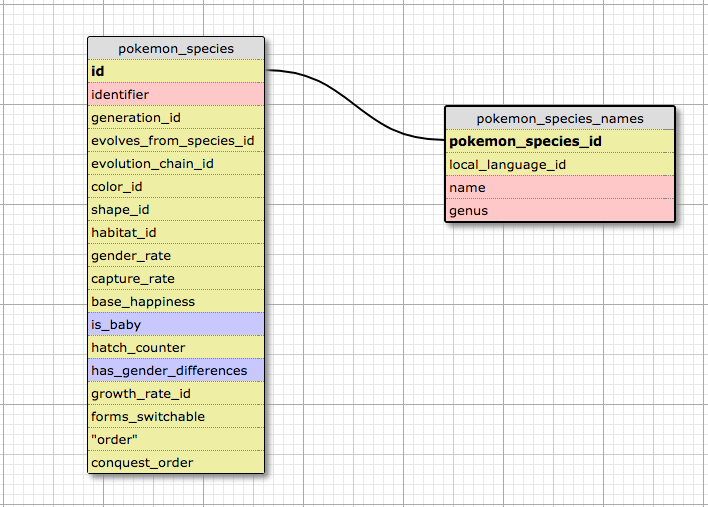
Рисунок 1: Структура и связь таблиц pokemon_species и pokemon_species_names
Как видно на рисунке выше, информация об именах и видах вынесена в отдельную таблицу. Данные в таблице pokemon_species_names, вероятно, изменяются реже, чем в таблице pokemon_species. Соответственно, такая схема таблиц вполне разумна. Чтобы создать запрос, возвращающий идентификатор и вид, на базе двух таблиц, мы будем использовать оператор join.
sqlite> select identifier, genus from pokemon_species, pokemon_species_names where
...> pokemon_species.id = pokemon_species_names.pokemon_species_id and
...> local_language_id = 9;
bulbasaur|Seed
ivysaur|Seed
venusaur|Seed
charmander|Lizard
charmeleon|Flame
charizard|Flame
squirtle|Tiny Turtle
wartortle|Turtle
blastoise|Shellfish
caterpie|Worm
...
В запросе выше выбраны две колонки из двух разных таблиц. В условии WHERE указано, что нужно связать записи таблицы pokemon_species с записями таблицы pokemon_species_id, у которых совпадают значения в колонках id и pokemon_species_id. Кроме того, я ограничил количество выводимых записей, указав, что нужно выводить только записи, у которых local_language_id = 9 (только английский язык).
В этом примере, identifier и genus – уникальные имена из двух разных таблиц. Если имена колонок в двух таблицах совпадают, можно вначале указать имя таблицы, далее точку и имя колонки (например, pokemon_species.identifier, pokemon_species_id.genus).
Группировка данных
При помощи оператора GROUP BY мы можем разделить возвращаемые результаты по группам. Например, если к предыдущему запросу добавив конструкцию GROUP BY genus, результаты будут упорядочены по колонке genus.
sqlite> select identifier, genus from pokemon_species, pokemon_species_names
...> where pokemon_species.id = pokemon_species_names.pokemon_species_id and
...> local_language_id = 9 GROUP BY genus;
landorus|Abundance
seedot|Acorn
arceus|Alpha
chinchou|Angler
trapinch|Ant Pit
heatmor|Anteater
dedenne|Antenna
marill|Aqua Mouse
azumarill|Aqua Rabbit
hariyama|Arm Thrust
Вероятно, вы подумали о том, что те же самые результаты можно получить, используя оператор ORDER BY. В целом вы правы, за тем исключением, что в сочетании с оператором GROUP BY доступны агрегатные функции, одним из наиболее мощных инструментов в арсенале SQL.
Агрегатные функции
Агрегатные функции в чем-то похожи на виртуальные колонки, позволяющие выполнять простейшие операции с данными в таблицах. При помощи агрегатных функций можно выполнять следующие операции:
|
Функция |
Значение |
|
COUNT |
Подсчет общего количества записей |
|
MAX |
Найти максимальное значение |
|
MIN |
Найти минимальное значение |
|
SUM |
Подсчет суммы значение |
|
AVG |
Подсчет среднего значения |
Я буду использовать агрегатную функцию COUNT. В запросе ниже производится подсчет записей с типом mouse.
sqlite> select count(genus) from pokemon_species_names
...> where genus = "Mouse" and local_language_id = 9;
6
Оказалось, всего 6 записей.
В этом запросе функция count(genus) используется для подсчета количества записей. Другой пример – подсчет общего количества записей в таблице.
sqlite> .headers on
sqlite> select count(*) as "Total" from pokemon_species_names;
Total
6094
В запросе выше также демонстрируется именование колонки на базе агрегатной функции. Конструкция AS "Total" после агрегатной функции позволяет в дальнейшем ссылаться на эту колонку по имени.
Агрегатные функции очень полезны в комбинации с оператором GROUP BY. В одном из предыдущих примеров мы подсчитывали количество типов mouse. В запросе ниже производится подсчет количества каждого типов.
sqlite> select count(name) count, genus from pokemon_species_names
...> where local_language_id = 9 group by genus order by count desc;
count|genus
8|Dragon
6|Mouse
6|Mushroom
5|Balloon
5|Flame
5|Fox
4|Bagworm
4|Bat
4|Cocoon
4|Drill
4|Fairy
4|Poison Pin
4|Seed
4|Tadpole
3|Big Jaw
3|Bivalve
3|Cottonweed
3|EleFish
3|Electric
3|Flower
В этом примере оператор GROUP BY группирует записи по значениям в колонке genus. Кроме того, именуя колонку с агрегатной функцией, мы можем обращаться к ней в дальнейшем в операторе ORDER BY.
Оператор GROUP BY и агрегатные функции позволяют анализировать данные в различных разрезах. Например, можно посчитать общее количество скомпрометированных кредитных карт или число кредитных карт, с которых украдены деньги, в разрезе по штатам, которые должны отчитываться по подобного рода инцидентам в обязательном порядке.
Мне кажется, для одной статьи информации более чем достаточно. На мой взгляд, SQL является хорошим подспорьем во время пентестов. Если вы хотите ознакомиться с другими уроками по SQL, особенно применительно к базе данных Pokémon Pokedex, рекомендую также ознакомиться с проектом PokemonSQLTutorial.