
Схема DDoS атак на уровне приложений и архитектур микрослужб
В этой статье речь пойдет о DDoS-атаках на уровне приложений, как об одном из наиболее разрушительных способов, при помощи которого можно вывести из строя современные архитектуры микро-служб.
Авторы: Scott Behrens и Bryan Payne
Введение
В этой статье речь пойдет о DDoS-атаках на уровне приложений, как об одном из наиболее разрушительных способов, при помощи которого можно вывести из строя современные архитектуры микро-служб. Специально созданная DDoS атака уровня приложений позволяет каскадно вывести из строя системы, используя намного меньший объем ресурсов по сравнению с теми ресурсами, которые необходимы для проведения традиционных DDoS атак. Подобный расклад возможен из-за сложных взаимосвязей, существующих между приложениями. Традиционные DDoS атаки нацелены на истощение ресурсов системы на сетевом уровне. На уровне приложений внимание сосредоточено на ресурсозатратных API-вызовах и взаимосвязях, чтобы спровоцировать атаку системы на саму себя, и иногда с лавинообразным эффектом. В современной архитектуре микро-служб подобных подход может оказаться особенно разрушительным.
Злоумышленник может создать изощренные вредоносные запросы, имитирующие легитимный трафик, который будет проходить через все защитные системы, в том числе и WAF (web application firewall; фаервол для веб-приложений).
В этой заметке мы поговорим о методах компании Netflix, используемых для идентификации, тестирования и защиты от DDoS-атак на уровне приложений. Начнем с базовых сведений, касающихся этой проблемы. Далее поговорим об инструментах и методах для тестирования наших систем. В конце рассмотрим шаги для создания систем, которые более устойчивы к DDoS атакам подобного рода.
Предыстория вопроса
Согласно отчету компании Akamai, DDoS атаки на уровне приложений занимают менее 1% среди всех DDoS атак. Однако эта метрика не отражает степень влияния подобных атак. Когда злоумышленник тратит время на подготовку плана DDoS-атаки, эффективность этого сценария возрастает в разы. Учитывая сей факт, при защите от подобного типа атак в первую очередь необходимо убедиться, что не произойдет выхода из строя систем лавинообразным образом.
Традиционные DDoS атаки на уровне приложений были основаны на предварительной подготовке входных параметров с учетом возможностей системы по генерации выходных данных. Подобные сценарии основаны на использовании ресурсозатратных вызовов (например, запросов к базам данных или операции с дисковыми системами) с целью чрезмерного использования приложения до тех пор, пока не прекратится обслуживание легитимных пользователей. А поскольку архитектура приложения является частью более сложных и распределенных систем, у нас появляется дополнительная задача по проверке служб и сложных зависимостей микрослужб, которые могут пострадать, если один ключевой сервис становится нестабильным.
Микрослужбы и DDoS
В современной архитектуре микрослужб DDoS атака на уровне приложений может стать особенно эффективной, если ставится задача по выводу из строя этой службы. Чтобы понять почему, рассмотрим пример микрослужбы, использующей шлюз для взаимодействия с несколькими микрослужбами на среднем уровне и бэкэнде, как показано на рисунке ниже.
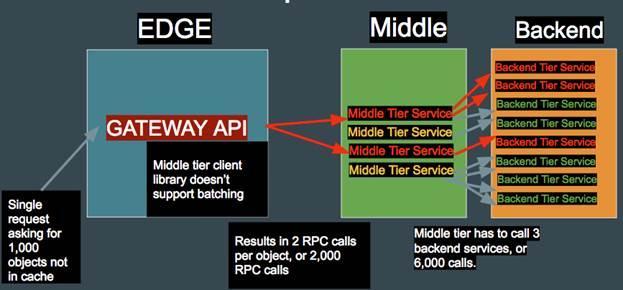
Рисунок 1: Схема взаимодействия микрослужб на различных уровнях
На диаграмме выше показано, как один запрос в шлюзе может превратиться в тысячи запросов на среднем уровне и бэкэнде. Если злоумышленник сможет найти API-вызовы, которые приводят к подобному эффекту, то далее возможно использовать эту фишку против всей системы. Если результирующие вычисления будут потреблять слишком много ресурсов, некоторые службы на среднем уровне могут остановиться. В итоге, в зависимости от уровня критичности этих служб, вся система подвергнется угрозе в той или иной степени.
Подобная схема возможна благодаря архитектуре микрослужб, которая позволяет злоумышленнику серьезно усилить атаку против внутренних систем. То есть один запрос к микрослужбе может сгенерировать десятки тысяч сложных вызовов к службам на серединном уровне и бэкэнде.
Сей факт добавляет головной боли специалисту по безопасности. Если в вашей среде используется WAF, настроенный стандартным образом (например, как API-шлюз), то в таком режиме могут пропускаться запросы, специально направленные для выхода из строя служб на серединном уровне и бэкэнде. Фаервол может «не догадываться» о последствиях одного запроса, направленного к вышеупомянутым службам, и как итог не сработает фильтр по черному списку, что может привести к плачевным последствиям.
Нам, специалистам по безопасности, важно понимать, как найти вызовы, которые потенциально могут использоваться в DDoS атаках на уровне приложений.
Фреймворк для поиска и проверки на предмет DDoS атаки на уровне приложений
Мы должны найти запросы, которые требуют много ресурсов от служб на серединном уровне и бэкэнде. Один способов обнаружения – измерение времени выполнения API-вызовов. Самый простой и не очень надежный способ – идентификация API-вызовов через браузер. Открываем консоль Chrome Developer, выбираем вкладку Network, выставляем флажок Preserve log и далее начинаем просматривать сайт. Через некоторое время сортируем запросы по колонке Time и смотрим вызовы с наибольшим временем выполнения. Вы получите таблицу, схожу с той, которая показана на рисунке ниже.
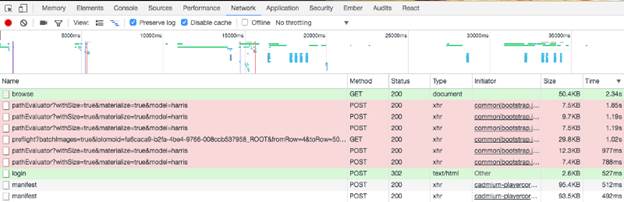
Рисунок 2: Запросы сайта, отсортированные в порядке убывания по времени выполнения
Эта техника может привести к ложным срабатываниям, включая запросы, которые нельзя модифицировать для увеличения времени выполнения. Либо можно пропустить вызовы, которые можно изменить для увеличения времени выполнения. Более точная техника связана с мониторингом периодичности запросов к службам серединного уровня. Как только на серединном уровне обнаружена служба, использующая вызовы с большим временем выполнения, нужно реконструировать запрос, который может пройти через API-шлюз для повторного выполнения запроса к найденной службе.
После нахождение нескольких интересных API-вызовов следующий шаг – инспекция содержимого этих функций. Наша задача – сделать так, чтобы эти вызовы стали потреблять больше ресурсов. Одна из техник – увеличение диапазона запрашиваемых объектов. Например, на картинке ниже можно модифицировать параметры from и to для увеличения нагрузки на службы серединного уровня.

Рисунок 3: Содержимое одного из запросов, который потенциально может нагрузить службу
Если копнуть еще глубже, то зачастую можно найти много других элементов запроса для увеличения потребления ресурсов. На рисунке ниже показан пример модификации поля запрашиваемого объекта, диапазона и даже размера картинки.
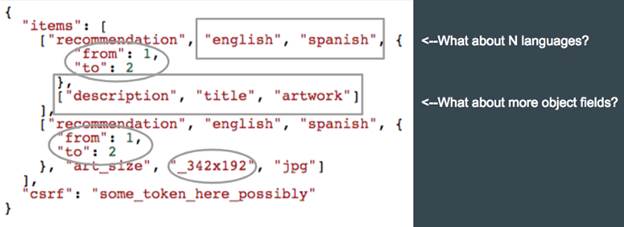
Рисунок 4: Потенциальные места запрашиваемого объекта, которые можно изменить
Кроме того, вы можете сформировать список индикаторов, отражающих успешность тестирования, и которые информируют вас о том, что тестирование находится в процессе выполнения и места увеличения/уменьшения масштабирования. Обычно индикаторы включают в себя статусные HTTP-коды и время выполнение отдельных запросов во время тестирования, но могут использоваться и другие показатели: заголовки, текст ответа, содержимое стека и т. д. На рисунке ниже показан пример перечня индикаторов:
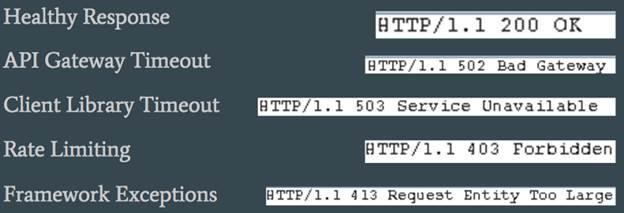
Рисунок 5: Перечень показателей, используемых во время тестирования
Еще один полезный индикатор успешности теста – увеличенное время выполнение (например, HTTP-код 200 и время ответа 10 секунд). Вы можете измерить время выполнения во время тестирования или когда другие пользователи используют приложение. Как только вы нашли типы запросов, которые приводят к увеличению неактивности и сформировали индикаторы успешности тестирования, необходимо перенастроить тесты с учетом WAF, если таковой используется в среде.
Идеальный объем трафика должен быть ниже, чем допустимый порог, когда фаервол начинает блокировку, но достаточный, чтобы набор запросов и количество потребляемых ресурсов вывели службу из строя.
Фреймворк Repulsive Grizzly

Для облегчения проведения тестирования в небольших масштабах вы можете использовать фреймворк Repulsive Grizzly, который поддерживается компанией Netflix в рамках экспериментального проекта с открытым исходным текстом. Исходники публикуются в качестве доказательства нашей концепции без гарантии последующей поддержки в течение длительного времени. Этот фреймворк написан на Python с использованием библиотеки eventlet для поддержания более высокой согласованности. Также есть поддержка циклического перебора аутентификационных объектов, что может пригодиться при обходе некоторых видов WAF’ов.
Фреймворк Repulsive Grizzly не помогает в обнаружении уязвимостей, помогающих осуществить DDoS атаку на уровне приложений. Как и в случае со всеми остальными утилитами, связанными с тестированием безопасности, важно не забывать использовать эти инструменты только там, где разрешено. Вначале вам нужно найти потенциальные проблемы, упомянутые выше. Как только у вас появился «материал» для тестирования, фреймворк Repulsive Grizzly упростит весь остальной процесс.
Более подробная информация относительно использования фреймворка Repulsive Grizzly указана в документации.
Фреймворк Cloudy Kraken
После тестирования гипотез в небольших масштабах можно переходить к масштабированию при помощи фреймворка Cloudy Kraken, который работает на базе платформы Amazon Web Services (AWS). Как и в случае с фреймворком Repulsive Grizzly, Cloudy Kraken представлен в качестве экспериментального проекта с открытым исходным кодом.
Cloudy Kraken помогает поддерживать глобальный набор экземпляров тестирования, а Repulsive Grizzly отвечает за механику внутри каждого экземпляра. Также этот фреймворк создает и распределяет тестовую конфигурацию и использует расширенные сетевые драйвера сервиса AWS EC2. Cloudy Kraken позволяет масштабировать тестирование среди нескольких регионов и поддерживает синхронизацию по времени для агентов, запущенных параллельно. На диаграмме ниже показана общая схема работы Cloudy Kraken:
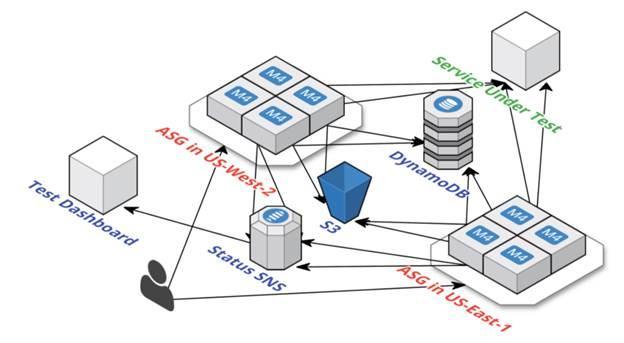
Рисунок 6: Архитектура фреймворка Cloudy Kraken
Cloudy Kraken организует ваши тесты в понятной и дружественной форме. Все начинается с конфигурационных скриптов, определяющих логику тестирования. Затем создается AWS-среда для тестирования и запуска экземпляров. Пока проводится тестирование, Cloudy Kraken собирает информацию при помощи службы AWS SNS. В конце тестирования AWS-ресурсы уничтожаются. Вся последовательность шагов показана на диаграмме ниже.
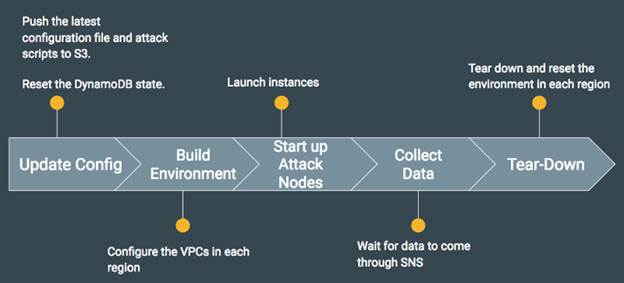
Рисунок 7: Последовательность шагов для настройки распределенного тестирования
Пример из жизни
Специалисты компании Netflix решили протестировать находки на примере определенного API-вызова, который был идентифицирован как медленный. Во время мероприятия под кодовым называнием Chaos Kong (когда Netflix эвакуировала целый AWS-регион, любезно перенаправив покупательский трафик в другие регионы), мы проводили тестирование в промышленной среде в эвакуированном регионе. Возможность протестировать сценарий DDoS атаки уровня приложений в такого рода среде предоставляется довольно редко. Наша уникальная культура сподвигает нас на героические поступки, и мы, воспользовавшись этой свободой, запустили тестирование в рабочей среде с целью понять степень влияния наших воздействий.
Тест, который мы проводили, состоял из двух атак в течение 5 минутных интервалов. По окончании теста выяснилось, что в API-шлюзе вероятность появления ошибки равна 80% в том регионе, где осуществлялась проверка. Пользователи, выполнявшие запросы к API-шлюзу, наблюдали ошибки на сайте и другие исключения, которые мешали дальнейшему использованию сайта. На графике ниже показаны два всплеска, отражающие статусные коды с номером 503 (фиолетового цвета), которые коррелируют с состоянием API-шлюза.
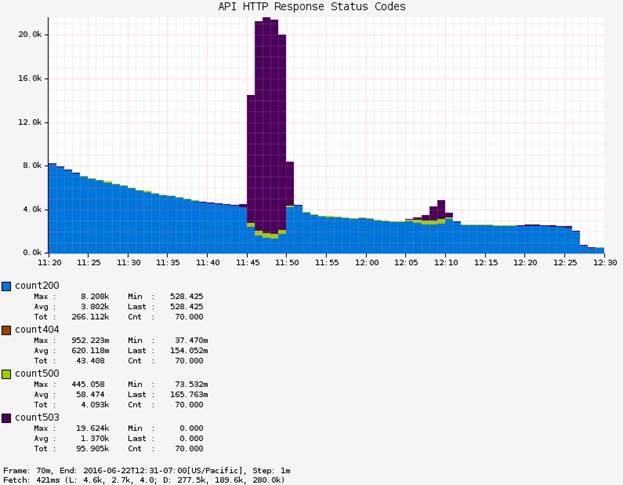
Рисунок 8: Показатели тестирования
Защита от DDoS атак уровня приложений
Первый и самый важный метод – понимание того, как работает ваша система. Вы должны понимать, какие микрослужбы влияют на каждый аспект, связанный опытом взаимодействия с покупателями / заказчиками вашей системы (в случае с последним примером, пользователями сайта). Попытайтесь сократить количество взаимозависимостей с этими службами. Если одна служба становится недоступной, остальные микрослужбы должны продолжать свою работу (возможно, в более нестабильном состоянии).
Важно иметь хорошее понимание об очередности работы служб и о механике запросов. Возможно, на серединном уровне и бэкэнде следует ограничить размер очереди или размер запрашиваемых объектов, что можно сделать как в коде клиента, так и на уровне API-шлюза. Установка ограничений на объем разрешенных запросов может значительно снизить вероятность реализации подобных атак.
Мы также рекомендуем использовать обратную связь, когда от служб серединного уровня и бэкэнда отсылаются сообщение к WAF. Эта схема поможет уведомить WAF о том, когда блокировать подобного рода атаки. Во многих случаях WAF осуществляет только мониторинг приграничной зоны и может не догадываться о влиянии одного запроса на API-шлюз. Желательно также, чтобы WAF мониторил промахи кэша (cache miss). Если API-шлюз постоянно выполняет вызов служб на серединном уровне из-за промахов кэша, значит, кэш сконфигурирован некорректно или осуществляются вредоносные действия.
API-шлюзы и другие микрослужбы должны отдавать приоритет аутентификационному трафику по сравнению с неаутентификационным, поскольку от злоумышленника требуется больше ресурсов и мастерства для использования аутентификационных сессий. Этот метод также помогает сократить влияние DDoS атак на уровне приложений на ваших покупателей.
Наконец, удостоверьтесь, что используются разумные значения тайм-аутов в клиентских библиотеках и прерыватели цепей. При использовании разумных тайм-аутов и постоянном тестировании вы сможете защитить службы среднего уровня от DDoS атак уровня приложений.
Ссылки
Repulsive Grizzly
Cloudy Kraken
Netflix Security Youtube Channel