
Время – один из ключевых факторов в работе пентестера. С одной стороны, недостаток времени может мешать выполнению качественного анализа, когда вы находитесь в режиме дедлайна, а с другой – помогать в аудите безопасности. Как? – спросите вы. В качестве примера возьмем технику извлечения данных из базы данных, которая основана на измерении времени ответа сервера, где используются слепые SQL-инъекции. Однако эта техника может применяться не только к базами данных, но и к файловым системам. Практически каждый пентест начинается со сбора информации о системе, где наиболее вероятно применяется поиск файлов по словарю или просто атака по словарю. Но почему же не упростить этот шаг? Чтобы конкретизировать эту мысль, в этой статье мы приведем исследование этого вопроса, которое недавно было представлено на конференции ZeroNights 2013.
Вводное слово
Термин «атака по времени» происходит из криптографии, когда речь заходит об атаке по сторонним каналам на криптосистему, реализуя которую злоумышленник пытается скомпрометировать систему посредством анализа времени, требуемого для выполнения криптографического алгоритма. Однако сам криптографический алгоритм – не единственная цель при осуществлении атаки по времени, которая также может иметь более широкую область применения. Только недавно, в июле 2013 года, Пол Стоун (Paul Stone) из компании Context IS наглядно представил, как атаку по времени можно реализовать в отношении браузеров. В работе Пола был продемонстрирован обход SOP (Same Origin Policy) в современных браузерах путем вычисления задержек во время обработки пикселов на страницах. Как правило, манипуляции с пикселами недоступны через обычные методы из-за ограничений принципа одинакового источника (Same Origin Policy) в случае с кросс-доменами.
Наше исследование атак по времени против файловых систем, начатое в конце 2012 года, основывается на накопленном опыте при проведении аудита безопасности веб-приложений и пентестов. В этой статье мы расскажем о результатах и уроках на будущее.
Исходная информация и область исследования
При анализе веб-приложения или безопасности сетевого сервиса методом черного ящика, на начальном этапе мы собирали информацию о целевой системе. Информация о доступных файлах, директориях и обработчиках приложения (в случае, если дело касается техник перезаписи URL и любых других техниках относительно user-friendly URL’ов), в основном, получается при помощи атаки по словарю, которая, например, может быть выполнена при помощи утилит наподобие OWASP DirBuster.
Наша цель – усовершенствовать метод поиска файлов веб-приложений, используя атаки по времени. В идеале, мы хотим заменить классический перебор имен директорий (по сути, метод прямой атаки по словарю) на метод, похожий на поиск файлов по части их имени. В самом простейшем случае метод касается файловых систем. В случае с серверами приложений, мы будем использовать атаки по времени против механизмов перезаписи и других методов выбора какого-то действия для конкретного URL.
На это исследование нас сподвигли практические наблюдения времени ответа TFTP-сервера (время между отсылкой и получением UDP-дейтаграммы) при запросе различных имен файлов во время аудита безопасности. Используя статистику при разрешении соответствующих ошибок, нам удалось вычислить возможные встроенные файловые префиксы (первые 3-5 байта файлового имени на сервере) посредством атаки по словарю. Затем мы продолжили атаку, пытаясь найти оставшихся частей имени файла, посредством поиска префиксов, которые создают аномальные времена ответа сервера.
Основы атаки по времени
Прежде, чем двинуться дальше, углубимся немного в теорию. Возьмем абстрактную функцию A, которая оперирует пользовательскими данными (UserData) и определенными секретными данными (PrivateData). Эта функция выполняет некоторые операции с PrivateData на основе UserData без полного отображения на выходе полных секретных данных. Для простоты предположим, что выходная информация у функции отсутствует вообще.

Рисунок 1: Суть алгоритма атаки по времени
Перевод с Рисунка 1: время выполнения функции Function зависит от UserData и PrivateData. На основе времени выполнения функции и UserData можно определить PrivateData.
Утверждается, что функция A() уязвима к атаке по времени, если результат выполнения функции A() зависит от UserData так, что время выполнения функции может быть использовано для получения некоторой информации о PrivateData. Классическая атака по времени на криптосистемы представляет собой извлечение секретного ключа (PrivateData) при помощи времени, которое требуется для дешифровки соответствующих шифротекстов (UserData).
Атака по времени на файловую систему

Рисунок 2: Суть алгоритма атаки по времени на файловую систему
Перевод с Рисунка 2: Время поиска зависит от двух факторов: поисковой строки и массива данных, по которому проводится поиск. Концепция атаки заключается в нахождении данных по временам, затрачиваемым на поиск посредством различных поисковых строк.
Когда дело касается файловых систем, наиболее целесообразно выбрать такую модель, где функция, уязвимая к атаке по времени, ищет файлы по имени. Для UNIX-систем это означало бы проверку времени выполнения системного вызова STAT(). Имейте в виду: как только у нас есть права на доступ к директории, мы также можем проверить права доступа к файлу при помощи данных, полученных при вызове того же самого системного вызова STAT(). Соответственно, права на доступ к файлу не влияют на атаку по времени.
Естественно, способы реализации атаки по времени не ограничиваются лишь проверкой времени выполнения вызова STAT(). Существуют и другие варианты, однако в нашем случае подобный подход представляется наиболее общим и практически применимым к нашему исследованию.
Алгоритм поиска файлов внутри директории
Во время нашего исследования мы анализировали поисковые алгоритмы следующих файловых систем: EXT2, EXT3, EXT4, UFS2, NFS, FAT, и NTFS (эти файловые системы были выбраны на основе тенденций их использования в веб-серверах). Так как файловые системы будут непосредственно влиять на время ответа, их алгоритмы индексирования директорий можно разделить на две категории: неоптимизированные (списки) и оптимизированные (деревья и хеш-таблицы):
|
Файловая система |
Алгоритм индексирования директорий |
Тип хеш-фукнции |
Наличие кэша |
|
Ext2 |
List |
- |
+ |
|
Ext3/4 |
Htree |
Half_md4 + seed (earlier Legacy, TEA) |
+ |
|
Ufs2/NFS |
Dirhash |
FNV (FreeBSD) DJB (OpenBSD) |
+ |
|
FAT |
List (btree) |
- |
+ |
|
NTFS |
btree |
- |
+ |
Давайте посмотрим, как наличие кэша влияет на возможность реализации атаки по времени. На первый взгляд может показаться, что кэширование препятствует или даже делает невозможным реализацию подобных атак, но на самом деле все с точностью да наоборот. Кэширование (под кэшированием подразумевается сохранение результатов операций в памяти) уменьшает объем запросов к хранилищу данных устройства, таким образом, удаляя излишний шум в статистике задержек во время доступа к файлу.

Рисунок 3: Обобщенные выводы о влиянии кэша на реализацию атаки по времени
Файловая система ext2
Теперь давайте рассмотрим конкретные поисковые алгоритмы вышеупомянутых файловых систем, начиная с файловой системы ext2. Эта файловая система использует простой список, что означает сравнение каждого с каждым элементом. Однако перед сравнением строк имен файлов, происходит побайтовое сравнение длин этих строк. Если длины не совпадают, сравнение рассматривается как неудачное и автоматически прекращается.
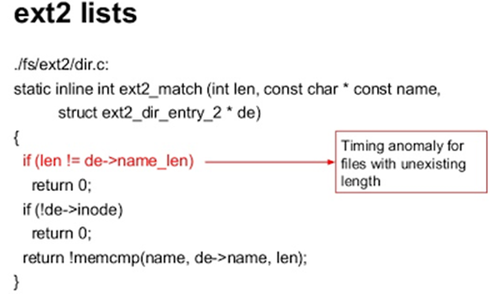
Рисунок 4: Функция сравнения в файловой системе ext2
Как вы могли догадаться, этот вид оптимизации (когда происходит побайтовое сравнение) создает аномалии для тех длин имен файлов, которые не совпадают с длинами имен файлов, находящимися в каталоге. Мониторинг временных аномалий, относящихся к сравнению длин имен файлов, - довольно полезен при атаке на директории, в которых содержатся файлы определенного формата, например, log-20131113-1122-c4daa58ccb8ee718.dat. Позже мы рассмотрим, как на практике реализовать атаку на файловую систему ext2.
Файловые системы ext3/4
Эти файловые системы используют оптимизированный алгоритм HTree, который первоначально был разработан для ext2, но никогда не использовался ни в одной стабильной ветке. Во время создания файловой системы, алгоритм индексирования HTree доступен по умолчанию. Однако его можно отключить и все будет происходить в точности так же, как и в случае с файловой системой ext2.
Алгоритм HTree создает хешированные имена файлов и хранит результаты в древовидной форме. Атака по времени на подобный алгоритм позволяет нам вычислить хранимые хеши имен файлов, которые впоследствии используются для вычисления имен файлов на основе хеш-функций.
По умолчанию файловые системы ext3/4 использует хеш-фукнцию half_md4, которая использует 24 циклов (3x8). Однако, в качестве начального значения или криптографического вектора инициализации (cryptologic initialization vector, IV) используется случайное число (4 слова по 32 бита каждый), генерируемое mkfs или какой-либо другой утилитой для создания файловой системы. Атака на хеш с неизвестным вектором инициализации такой длины (128 бит) при помощи словаря в современных реалиях невозможна. Кроме того, в процессе исследования необходимо выявить криптографическую стойкость алгоритма half_md4 (24 цикла).
Обратите внимание, что использование IV вместо классического salt-значения слева предотвращает выполнение атаки типа Length-Extension (атака увеличением длины сообщения), которая обычно вполне реализуема для этого типа хеша. По этой причине злоумышленник не может создать хеш строки, содержащей подстроку с известным хешем. Кроме того, при реализации этого типа атаки, необходимо знать состояние алгоритма на момент генерации хеш-функции (или другими словами, необходимо знать значение IV), что невозможно. Если бы начальное число (seed) было классическим salt-значением, подобная атака была бы вполне осуществима.
Тем не менее, несмотря на использование вектора инициализации, файловые системы ext3/4 могут быть уязвимы к атакам по времени в случаях, когда злоумышленник знает значение IV. К примеру, когда используется общедоступная прошивка для устройства.
Файловые системы UFS2/NFS
Файловая система UFS2 – популярна среди BSD систем и имеет две хеш-функции для OpenBSD и FreeBSD. FreeBSD использует FNV-хеш, а OpenBSD – DJB-хеш. Однако с точки зрения реализации атаки по времени эти два вида хеша полностью идентичны. Ни одна функция не использует ни вектор инициализации, ни salt-значения, что позволяет реализовать атаки по времени. Поисковый алгоритм по хеш-таблице, используемый в обеих системах, - полностью оптимизирован, что позволяет добиться значительного выигрыша по времени.

Рисунок 5: Алгоритм поиска имени файла в файловой системе UFS
Файловые системы FAT/NTFS
Поисковые алгоритмы файловых систем ОС Window основываются на BTree. FAT оптимизирована для BTree начиная с Windows98. FAT, используемая в DOS или открытых UNIX-системах, заточена под использование простого списка.
BTree представляет собой структуру данных, когда узлы могут содержать несколько потомков (не путать с бинарным деревом). Файловые системы на основе BTree также уязвимы к атакам по времени, поскольку время поиска файлов напрямую зависит от структуры BTree, то есть файлов в директории.
Практическая сторона вопроса
В целях демонстрации обсуждаемых концепций мы разработали утилиту, которую каждый может скачать на нашем Github. Эта утилита также может использоваться для наглядной демонстрации временных эффектов в различных файловых системах. Суть ее работы – сравнить времена выполнения системных вызовов STAT() для различных имен файлов и различных наборов файлов в директории.
Внутри утилиты проводятся следующие базовые проверки:
- Время выполнения STAT() для длины имени файла, который не присутствует в директории.
- Время выполнения STAT() для длины имени файла той же самой длины, что и файлы, присутствующие в директории, но отличающейся первым байтом от существующих имен файлов.
Та же самая проверка проводится для имен файлов, отличающихся от существующих файлов в директории, четвертым, восьмым и сотым байтом.
Рассмотрим простейшее применение утилиты для файловой системы ext2. Для начала создадим новый раздел внутри петлевого устройства (loop device) (локальный файл) для экспериментов:
$ dd if=/dev/zero of=ext2_example bs=1M count=128
https://github.com/wallarm/researches.git
$ mkfs.ext2 -F ext2_example
$ mount -o loop ext2_example /mnt/ext2_example
$ cd /mnt/ext2_example
$ git clone
Затем в строке 18 нашего кода установим префикс имени файла в 20 байт:
Рисунок 6: Устанавливаем префикс имени файла
Затем модифицируем код для вычисления времени поиска для целевых имен файлов, отличающихся от существующих имен файлов в каждом из 20 байтов префикса (от 0 до 19, поскольку отсчет начинается с нуля). Для этого мы заменяем строку 119 (check_diff_byte call) на следующий цикл:
int i;
for(i=0;i<20;i++){
check_diff_byte( timings, rounds, measures, i);
printf("testing timings on difference in %d byte", i);
print_timings( "", timings, measures);
}
Рисунок 7: Добавляем цикл в строку 119
Теперь перекомпилируем и запускаем код:
$ gcc fs-timing.c -lm
$ mkdir test
$ ./a.out test/
Как видно из рисунка ниже, если в директории есть имя файла той длины, что и целевое имя файла, время выполнения STAT() значительно увеличивается: от 450 мс до 660 мс (в случае различия в первом байте).
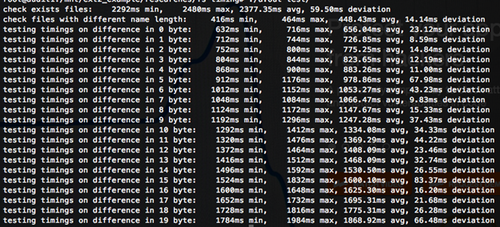
Рисунок 8: Результаты проверок длин имен файлов
Далее мы хотим проверить случай, когда целевое имя файла той же длины, что и уже существующие имена файлов, находящиеся в директории. Для этого мы измеряем время выполнения STAT() как функцию позиции байта, на которую отличается целевое имя от уже существующих файлов в директории. Было обнаружено, что результат можно прекрасно аппроксимировать линейной функцией (см. рисунок ниже), что доказывает соответствие теории и практики.
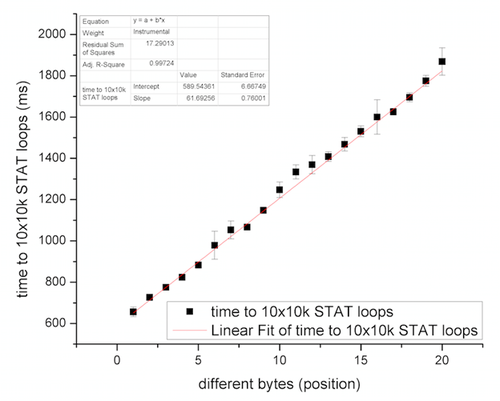
Рисунок 9: Функция времени выполнения STAT() в зависимости от позиции байта, на который отличаются имена файлов
Что дальше?
В данный момент мы работаем над фрейморком, который позволяет отслеживать временные аномалии в файловых системах. Его можно будет применять как для локальных, так и для удаленных атак. В будущем, мы бы хотели предоставить решение для нахождения файлов веб-сервера при помощи этих техник, как альтернативу классическому перебору.
Однако наши усилия в этой области направлены не только на файловые системы (об этом будет сообщено на конференции BlackHat 2014). В нашем проекте мы рассматриваем атаки по времени с точки зрения перспективы их использования в базах данных nosql и репозиториях, в которых информация организована по типу ключ-значение, принимая во внимание возможность извлечения данных из таблицы в чем-то схожую с использованием SQL-инъекций, но без использования их.