
Борьба за корневые DNS сервера. Хорошие парни побеждают?
Однозначно никто не может сказать, способна ли данная схема с существующим числом корневых DNS серверов противостоять распределенным DoS атакам в случае использования бот сетей с миллионами хостов.
Введение
ICCAN объявил, что с 2009 года можно будет зарегистрировать домены верхнего уровня, а это означает, что нагрузка на корневые DNS сервера дополнительно возрастет. Корневые DNS сервера Интернет периодически атакуют, используя бот сети. Бот сети разрастаются до огромных размеров. Практически ни одна из коммерческих организаций не способа противостоять DoS атакам с использованием бот-сетей.
Давайте разберемся, что «хорошие парни», ответственные за работоспособность корневых DNS серверов противопоставляют «плохим парням», которые, возможно, будут атаковать эти сервера.
Основы работы DNS.
Не секрет, что функционирование всего Интернет очень сильно завязано на систему DNS. Когда вы открываете страницу вашим Интернет обозревателем, ваш почтовый сервер начинает передавать письмо, ваш SIP IP телефон вызывает другого абонента, и в тысячах других случаев, задействуется процесс определения местоположения того либо иного сервиса с помощью DNS. Если по каким - либо причинам DNS перестанет работать, это повлечет за собой неизбежные простои. Не будем разбираться в мотивации тех, кто пытается вывести из строя глобальную систему DNS, оставим это дядюшке Фрейду. Лучше выясним, почему атаке подвергаются именно корневые DNS и что это вообще такое.
Чтобы разобраться, почему атакуются именно корневые сервера DNS необходимо понимать, как работает эта система. Графически, структуру DNS корректней всего представить в виде дерева.
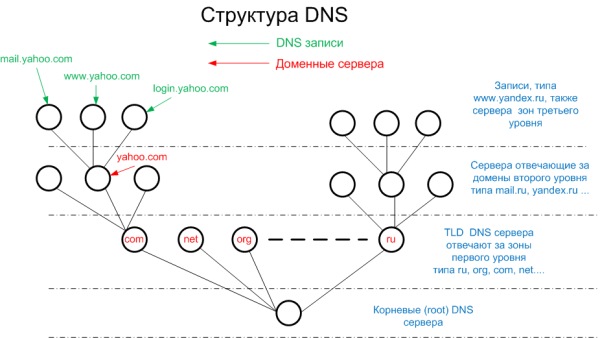
В корне дерева расположены так называемые корневые сервера. Их всего 13 штук. Корневые сервера знают о месте положения (IP адреса) так называемых TLD (Top Level Domain) серверов. TLD сервера обслуживают большие зоны первого уровня, такие как com, net, ru, kz, ua, gov…. Группа TLD серверов знает о месте положения серверов обслуживающих домены второго уровня в пределах их зоны ответственности. Например, ответственные за домен com знают IP адреса серверов второго уровня для зоны первого уровня com, ответственные за зону ru знают о серверах зоны ru, ну и так далее. Сервера ответственные за зоны второго уровня уже, как правило, знают конкретные адреса серверов, предоставляющих сервисы интернета, таких как www, mail и т.д. Также сервера второго уровня могут быть ответственными за домены третьего уровня, ну и так далее.
Для того, чтобы понять как вся структура функционирует, рассмотрим как это работает на примере определения IP адреса сервера www.securityab.ru. Для упрощения, рассмотрим пример работы рекурсивного DNS без учета механизмов кэширования.
Все, что первоначально известно серверу, который предоставляет услуги DNS это 13 IP адресов корневых серверов. В моей любимой ОС FreeBSD они жестко прописаны в файле named.root, в вашей любимой ОС, они, возможно, хранятся в других местах, но, эти IP адреса однозначно одна из самых постоянных вещей Интернета.
Допустим, клиент запрашивает IP адрес сервера www.securitylab.ru сервер DNS, который его обслуживает. Тот, в свою очередь, спрашивает об этом корневые сервера, при этом IP адрес корневого сервера выбирается произвольно. Один из корневых серверов ему отвечает, что ничего не знает о www.securitylab.ru, но, спросить об этом можно у одного из 6-ти (на данный момент) TLD серверов, ответственных за зону ru. Сервер DNS запрашивает один из серверов TLD, который отвечает, что надо бы запросить об этом один из трех серверов ответственных за зону второго уровня securitylab.ru. Сервер DNS дает третий запрос к одному из серверов второго уровня, и, наконец, узнает что www.securitylab.ru живет на IP адресе 217.16.31.134.
Все это справедливо, если вы не используете при работе с DNS кэширование (запоминаете результаты предыдущих запросов). Кэширование подразумевает, что после первого запроса сервер уже знает адреса серверов, которые хранят информацию о зоне ru и securitylab.ru и, собственно, где расположен www.securitylab.ru.
Кэширование выгодно всем. Меньше запросов к корневым и TLD серверам, меньше трафика тратит сервер DNS провайдера, меньше времени клиент ждет ответа от DNS сервера провайдера.
С глобальной точки зрения, самый сильный положительный эффект от кэширования получают именно корневые сервера. И еще, благодаря кэшированию, самая сильная нагрузка в DNS приходится, не на корневые сервера, ибо они предоставляют информацию только о серверах TLD, а на TLD сервера, так как они вынуждены давать ответы на запросы не о сотнях, как корневые севера, а о миллионах доменов. TLD севера обычно мощнее корневых, как с точки зрения пропускной способности сети, обеспечивающей их функционирование, так и с точки зрения вычислительных ресурсов этих серверов.
Технически, проще завалить TLD сервера. Однако, не смотря на это, атакуют чаще всего, именно корневые сервера, так как, срубив ветвь, даже очень большую, такую как com, net или org,, вы всего лишь, срубите часть дерева, но не весь DNS. Убив же корень, вы добьетесь максимального эффекта.
Исходя из знаний о кэшировании, можно сделать еще один интересный вывод. Если единовременно отключить все корневые сервера, то Интернет умрет отнюдь не сразу. Однако проблемы у многих конечных пользователей начнутся практически сразу. На текущий момент все корневые DNS сервера в целом обрабатывают, десятки, а то и сотни тысяч запросов в секунду.
Вообще, проблема при распределенных DoS атаках на корневые DNS сервера вовсе не в том, что они не успевают обрабатывать запросы. Основная проблема в том, что они становятся недоступными по сети. Фактически, чтобы вызвать отказ в обслуживании всей системы DNS, атакующим достаточно одновременно вывести из строя 13 географически распределенных точек сети. Конечно, можно прописать еще несколько десятков серверов в качестве корневых. Однако это сложно с точки зрения того, что необходимо будет менять настройки программного обеспечения на всех клиентах. Кроме того, такая система не гарантирует рационального распределения трафика между корневыми серверами.
В качестве другого решения противостояния распределенным DoS атакам на текущий момент внедрена крайне масштабируемая система с использованием anycast. Рассмотрим, что это такое.
Что такое anycast.
Не смотря на то, что технология anycast была описана еще в ноябре 1993 года в RFC 1546, очень мало сетевых профессионалов знают, что это такое. Дело тут не в сложности технологии, а скорее в том, что ее использование ограничено узкой областью применения.
Слово anycast образуется от двух английских слов any – любой, cast – бросать, или, в терминах сети, вещать. Вообще в сети различают 4 метода вещания - broadcast, multicast, unicast и anycast.
Если вы откроете Википедию по cast-ам то увидите там 4 красивых рисунка иллюстрирующих их. Позволю себе их использовать.
 broadcast-ы передаются от вещающего одновременно всем. По аналогии с реальным миром у вещающего есть мегафон, с помощью которого он разговаривает с толпой людей. Его слышат все, но радиус действия мегафона ограничен. Примером использования broadcast-а является процесс выдачи IP адреса хосту по протоколу DHCP. В сетях broadcast-ы обычно не распространяются дальше локальной сети.
broadcast-ы передаются от вещающего одновременно всем. По аналогии с реальным миром у вещающего есть мегафон, с помощью которого он разговаривает с толпой людей. Его слышат все, но радиус действия мегафона ограничен. Примером использования broadcast-а является процесс выдачи IP адреса хосту по протоколу DHCP. В сетях broadcast-ы обычно не распространяются дальше локальной сети.
 multicast больше похож на радио. Радиус действия у него может быть большой, однако вы его не услышите, пока не включите радио, в терминах сети не подпишется на услугу. Пример использования multicast-а – IPTV, когда вы переключаете каналы на своей IPTV приставке, вы подписываетесь на определенный канал multicast вещания, и только после этого вам доставляется картинка со звуком. При этом на один и тот же канал могут подписаться одновременно многие пользователи.
multicast больше похож на радио. Радиус действия у него может быть большой, однако вы его не услышите, пока не включите радио, в терминах сети не подпишется на услугу. Пример использования multicast-а – IPTV, когда вы переключаете каналы на своей IPTV приставке, вы подписываетесь на определенный канал multicast вещания, и только после этого вам доставляется картинка со звуком. При этом на один и тот же канал могут подписаться одновременно многие пользователи.
 unicast можно сравнить с телефоном. Набрав определенный номер, вы разговариваете с определенным человеком. В сети, указав IP адрес, протокол и порт, вы общаетесь с определенным сервером. Большинство общений между хостами в Интернет происходит по технологии unicast. Примеров использования unicast-ов множество - от закачки файлов по ftp до передачи электронной почты.
unicast можно сравнить с телефоном. Набрав определенный номер, вы разговариваете с определенным человеком. В сети, указав IP адрес, протокол и порт, вы общаетесь с определенным сервером. Большинство общений между хостами в Интернет происходит по технологии unicast. Примеров использования unicast-ов множество - от закачки файлов по ftp до передачи электронной почты.
 anycast больше всего похож на unicast, его можно сравнить с обычным телефонным разговором, за тем исключением, что вы дозваниваетесь не на конкретного человека, а на справочную службу. Все операторы справочной службы равноценны и вам вовсе не важно с кем из них вы говорите. Задача телефонной станции в этом случае, при дозвоне пользователей на один и тот же номер - выбор произвольного оператора. Задача сети в случае работы с anycast-ом – выбор, по некоторым критериям, одного из равноценных серверов, с которым будет общаться хост. С точки зрения двух хостов, участвующих в anycast общении нет никакой разницы в работе по сравнению с unicast-ом.
anycast больше всего похож на unicast, его можно сравнить с обычным телефонным разговором, за тем исключением, что вы дозваниваетесь не на конкретного человека, а на справочную службу. Все операторы справочной службы равноценны и вам вовсе не важно с кем из них вы говорите. Задача телефонной станции в этом случае, при дозвоне пользователей на один и тот же номер - выбор произвольного оператора. Задача сети в случае работы с anycast-ом – выбор, по некоторым критериям, одного из равноценных серверов, с которым будет общаться хост. С точки зрения двух хостов, участвующих в anycast общении нет никакой разницы в работе по сравнению с unicast-ом.
Чтобы понять, как работает anycast необходимо иметь представления о том, как работает маршрутизация в сетях использующих протокол IP.
Основы маршрутизации.
Если два хоста, участвующих в обмене данными друг с другом находятся в разных подсетях, то пакеты между ними доставляются посредством выполняющих специальные функции устройств сети, называемых маршрутизаторами.
Часто, два удаленных хоста в Интернете связаны между собой избыточными связями. Порой, пакет данных отосланный от хоста A теоретически может достичь хоста Б десятками различных путей. Совсем не факт, что если пакет от хоста А прошел через 3 определенных маршрутизатора, то обратный пакет от хоста Б придет через те же 3 маршрутизатора. Наличие избыточных связей дает 2 основных преимущества, первое – выход из строя одного из каналов связи не будет означать недоступности для группы хостов, второе – нагрузка при передаче данных может распределяться между различными каналами, в результате общая пропускная способность сети возрастает.
В процессе принятия решения, через какой из возможных путей переслать пакет маршрутизатор руководствуется, прежде всего, адресом назначения пакета и логикой маршрутизации. Обычно, маршрутизатор не руководствуется информацией об источнике (кто послал пакет), протоколе, портах и прочей информацией заголовков пакета данных. Но, например, у маршрутизаторов cisco есть особая фича, так называемый PBR (Policy-Based Routing) http://www.cisco.com/en/US/docs/ios/12_2/qos/configuration/guide/qcfclass.html#wpxref35843
, однако, это скорее исключение, чем правило.
Забавно, но даже сетевики со стажем не всегда четко представляют, что служит критерием принятия решения о направлении пакетов по тому либо иному маршруту. Простейшая задача, на картинке ниже вводит их в ступор.
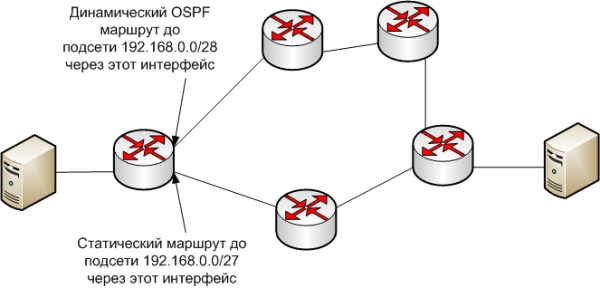
Вопрос: пакет на хост 192.168.0.2 уйдет с верхнего или нижнего интерфейса?
Правильный ответ – с верхнего. Почему? Потому, что при выборе лучшего маршрута последовательно срабатывают следующие 3 правила.
1) Если длины префиксов подсетей, в которые попадает IP адрес хоста назначения разные, то выбирается маршрут с самым длинным префиксом.
2) Если префиксы равны, то выбирается маршрут с более приоритетным протоколом маршрутизации.
3) Если и префиксы равны и протоколы одинаковые, то срабатывает внутренняя метрика протокола маршрутизации.
В данном примере сработало первое правило.
А теперь немного подробней. Что такое префикс? Префикс это метод описания подсети. Префикс состоит из двух частей, левая – идентификатор подсети, правая – длина этого идентификатора.
Самый длинный префикс имеет длину 32 при этом левая часть такого префикса, по сути, является IP адресом. Самый короткий префикс имеет длину 0, при этом левая часть префикса также равна 0, такой префикс записывается как 0/0 или 0.0.0.0/0, и в него попадают все возможные IP адреса.
В маршрутизации для описания подсетей используются префиксы, но не идентификаторы подсетей и маски. Запись 192.168.0.0/28 описывает подсеть, в префиксе которой последовательно 28 единиц (длина префикса), что эквивалентно записи 192.168.0.0 маска 255.255.255.240. Вообще, тут несколько тонкий вопрос отличия, но маски используются для того, чтобы вычислить относится ли хост к определенной подсети, префиксы служат для описания значимой для маршрутизации информации о местоположении подсетей. Есть еще некоторые не существенные, в данном контексте отличия.
Маршруты могут вноситься ручками в конфигурацию маршрутизатора, это называется статическая маршрутизация, а могут появляться там автоматически, с помощью протоколов динамической маршрутизации.
Основной принцип динамической маршрутизации прост. Каждый маршрутизатор знает о нескольких сетях доступных через него. После включения динамической маршрутизации соседние маршрутизаторы начинают обмениваться информацией о доступных через них сетях. В конце концов, после полного обмена маршрутной информацией у каждого маршрутизатора появляется полное представление обо всех подсетях в пределах автономной системы маршрутизации (например, какие есть подсети, через какие интерфейсы они доступны, как далеко они расположены). В случае, если происходят некоторые события, например пропадает линк между маршрутизаторами, или вносятся/удаляются определенные подсети, таблицы маршрутизации автоматически пересчитываются.
Несколько слов о приоритетах протоколов маршрутизации. Статическая маршрутизация имеет наивысший приоритет, различные протоколы динамической маршрутизации имеют каждый свой приоритет. В примере, приведенном выше, если бы префиксы подсетей совпадали, то пакет, согласно второму правилу, был бы передан через нижний интерфейс. Область действия приоритетов протоколов маршрутизации локальна для каждого маршрутизатора. Если маршрутизатор A получил маршрут для сети 192.168.0.0/28 через статический маршрут, а маршрутизатор B получил маршрут 192.168.0.0/28 от маршрутизаторов A и C по OSPF, то маршрутизатор B в выборе приоритетов руководствуется метриками OSPF. То есть маршрутизатору не важно, как соседи узнали о том либо ином маршруте, важно только то, как и что он о нем узнал.
Теперь стоит объяснить, что такое метрики протоколов маршрутизации. Метрики это некоторые внутренние атрибуты протокола маршрутизации, на основании которых принимаются решения направить пакет по тому, либо другому пути. Если вы используете статическую маршрутизацию, то естественно, метрики вы выставляете вручную, когда прописываете маршрут. В случае с динамической маршрутизацией метрики, как и маршрут, чаще всего вычисляются автоматически, однако, их также можно менять и руками, заставляя маршрутизатор кидать пакеты по нужному пути.
Различные протоколы динамической маршрутизации вычисляют метрики различными способами. Для примера поверхностно рассмотрим критерии выбора маршрута протоколом динамической маршрутизации OSPF.
OSPF - Open Shortest Path first, вольно это можно перевести как лучший (маршрут) - с наименьшим доступным путем. Это значит, что в случае равнозначных (по скорости) связей между узлами сети выбирается маршрут с наименьшим количеством маршрутизаторов через которые он будет следовать. На длину пути автоматически влияет скорость, с которой работает интерфейс. Например, если интерфейс работает на скорости 100Мбит/c, то путь до соседа будет равен 1, если 10Мбит/c, то он будет равен 10 и т.д. Повлиять на дистанцию можно и ручками. Для этого надо просто прописать на нужном интерфейсе параметр bandwith (емкость), который не влияет на физическую скорость интерфейса, но влияет на процесс принятия решения маршрутизации.
В заключение, хотелось бы объяснить, почему правила маршрутизации срабатывают именно в таком, но не в другом порядке. На самом деле, все очень просто и логично.
Правило номер 1.
Задумайтесь, как описать, где расположены выходы из вашей сети, в которой крутится, допустим, тот же OSPF. Естественно, на маршрутизаторах, где они (выходы) расположены надо прописать маршрут по умолчанию (default gateway). В маршрут по умолчанию должны включаться все возможные IP адреса. Как описывается default gateway в префиксах? Вот так - 0/0. Любой IP адрес попадает в префикс 0/0, однако пакеты на default gateway должны кидаться только в том случае, если другие маршруты не срабатывают (адрес назначения не попадает ни в один другой существующий префикс маршрутизации). Default gateway – тот же маршрут, он так же передается между маршрутизаторами протоколом OSPF, следовательно, маршруты с более длинным префиксом всегда делаются более приоритетными, для того, чтобы схема с маршрутом по умолчанию работала.
Правило номер 2.
Метрики различных протоколов маршрутизации не соизмеримы. Гораздо проще дать приоритет одному протоколу маршрутизации над другим, чем, не понятно как, сопоставлять приоритеты метрик различных протоколов маршрутизации.
Правило номер 3.
Оно третье только потому, что первые 2 места уже заняты J
Для того, чтобы понять как организовывается anycast в IP сетях, понимания описанных выше принципов работы маршрутизации достаточно.
Как работает anycast.
Для описания работы anycast рассмотрим сеть, в которой работает протокол динамической маршрутизацией с максимально упрощенной логикой выбора маршрута из различных мест до хоста 192.168.0.2.
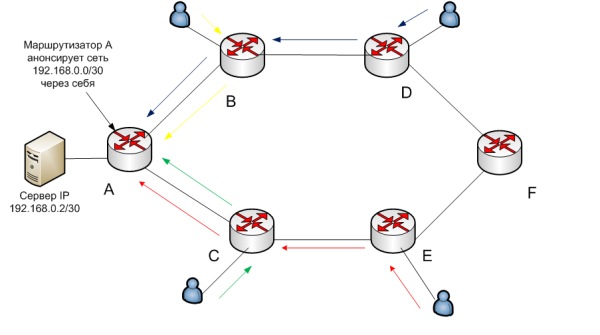
Допустим, работает тот же OSPF, при этом линки между маршрутизаторами имеют одинаковую пропускную способность и параметр bandwith нигде не сконфигурирован. Критерием выбора маршрута в данном случае, является только количество маршрутизаторов, через которые должны пройти пакеты. Стрелками разного цвета указаны пути пакетов для того, чтобы достичь сервера.
А теперь, для этой же сети включим еще один физический сервер с таким же IP в маршрутизатор F. Этот маршрутизатор, в свою очередь заставим анонсировать тот же префикс через себя.
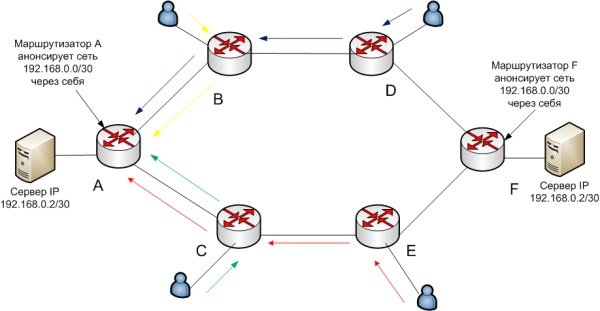
Очевидно, что в этом случае, часть трафика пойдет на один сервер, часть на другой.
Таким образом, 2 или более, разных, но равноценных сервера с одинаковым IP можно включить в различные географически удаленные места. Такая схема не только не противоречит принципам маршрутизации, но я бы сказал даже, что она органично в них вписывается.
Что касается конечных пользователей, то для них такая схема прозрачна, более того, они от этого выигрывают, так как чем меньшее количество маршрутизаторов проходит пакет, тем лучше с точки зрения задержек. Что касается anycast серверов то для них это тоже прозрачно. Они работают так же как с unicast-ами.
Что до маршрутизаторов, которые анонсируют через себя префиксы, то им тоже абсолютно все равно, анонсирует ли еще кто-то через себя такой же префикс или нет. Не анонсирующие префикс маршрутизаторы просто выбирают лучший, с их точки зрения, путь до IP адреса.
В такой схеме есть только одна засада. Допустим, пользователь, работающий через маршрутизатор B качает по ftp большой файл с сервера, работающего через маршрутизатор А. В это время связь между А и B прерывается. Если бы не было anycast-а, таблицы маршрутизации перестроились бы таким образом, что пакеты пошли бы в обход, но все равно, достигли бы сервера работающего через A, и закачка бы не прервалась. В случае с anycast-ом пользователь переключится на сервер, работающий через маршрутизатор F. Так как ftp на транспортном уровне использует tcp, который ориентирован на сессию, то закачка для пользователя прервется. Я не буду детально объяснять, почему это так, так как это выходит за рамки статьи. В целом же, относительно возможности нормального использования ориентированных на сессию протоколов со схемами anycast-а, с глобальной точки зрения на функционирование Интернет, мнения специалистов разделились. Одни считают, что это не целесообразно, так как чревато частыми “обрывами” (причем, мало кто способен будет нормально объяснить, почему раньше НЕ БЫЛО НИ ЕДИННОГО ОБРЫВА, а сейчас они есть J), другие же говорят, что заметных “обрывов” не будет, и доказывают это на практике.
Если вы будете читать информацию по anycast-ам, то вам часто будет встречаться фраза, что объявляются IP адреса с определенным одинаковым префиксом. Подчеркивают это потому, что если вы объявите маршруты до одного и того же IP с различными префиксами, то работать anycast не будет, это логично, если вы понимаете логику маршрутизации, которая была описана выше, а именно, первое правило.
Действительно, допустим, вы хотите построить систему с тремя anycast серверами, живущими на одинаковых IP адресах, при этом объявили в маршрутизации 2 из них с префиксом длиной 28, а третий с префиксом длиной 29. Тогда схема не будет работать, так как все пакеты будут маршрутизироваться на третий маршрут. Если же вы прописали третий маршрут с префиксом длиной 27, то пакеты будут идти только на первые два сервера, третий выпадет из схемы.
Наличие же различных протоколов маршрутизации в сети и различных метрик внутри протоколов никак не влияет на общую работоспособность anycast-ов, этими параметрами можно влиять только на нагрузку конкретного сервера, как бы подключая к и отключая от этого сервера пользователей, имеющих доступ в сеть с через различные маршрутизаторы.
Теперь вернемся к нашим баранам, то есть корневым DNS серверам.
DNS Root сервера и anycast.
Принцип работы с anycast в глобальном масштабе такой же, как и в локальных сетях. В глобальной сети Интернет в качестве протокола динамической маршрутизации используется протокол BGP.
В целом описывать, как все устроено, и какие проблемы могут возникнуть при включении anycast-а очень сложно. Сам по себе протокол BGP не прост, а при включении anycast возникают дополнительные не совсем приятные моменты. Существует RFC http://tools.ietf.org/html/rfc4786, которые описывают лучшие практики при организации anycast в глобальных масштабах.
Чтобы определить к какому из корневых anycast серверов идут запросы, адресованные на тот либо иной anycast адрес корневого DNS сервера, можно использовать команду.
dig +norec @X.ROOT-SERVERS.NET HOSTNAME.BIND CHAOS TXT
Где X – буква от A до M для каждого из 13-ти anycast IP адресов серверов.
Если у вас есть возможность давать такие команды с различных географически удаленных серверов в сети, то, можно легко убедиться, что на запросы из различных автономных систем приходят ответы с физически разных серверов.
Хотелось бы осветить различные топологии, используемые различными организациями, ответственными за корневые сервера. Прежде, чем описывать какие топологии используется необходимо ввести 2 понятия anycast DNS серверов. Существуют, так называемые, локальные root anycast сервера и глобальные root anycast сервера. Глобальные сервера – это сервера которые доступны в глобальных пределах, то есть теоретически всем в Интернет, хотя, благодаря регуляциям метриками BGP каждый из них доступен только из определенных мест. Локальные сервера доступны только клиентам нескольких ближайших к ним провайдеров. Регулированием того, какой это сервер глобальный или локальный занимается протокол BGP. Согласно тому, какие сервера (локальные или глобальные) и в какой пропорции используются при организации anycast, различают 3 схемы.
Единообразная (flat) – состоит только из глобальных серверов, используется для J-root серверов.
Иерархическая (hierarchical) состоит из нескольких географически близко расположенных глобальных серверов и множества локальных серверов используется для F-root серверов.
Гибридная (hybrid) состоит из географически распределенных глобальных серверов и также распределенных локальных серверов используется для K-root серверов.
Вот, например, как выглядит картина глобального местоположение для k-root серверов c IP адресом 193.0.14.129, которую администрирует RIPE www.ripe.net (гибридная схема).
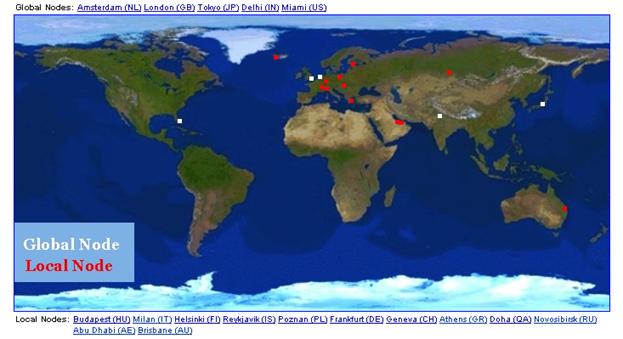
И для f-root с IP адресом 192.5.5.241, которую администрирует Internet Systems Consortium, Inc. www.isc.org (иерархическая схема).
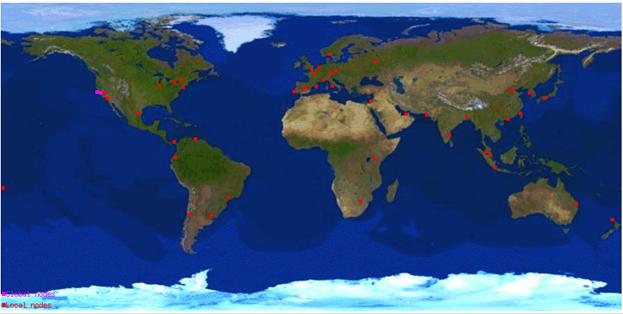
Как видите, среди различных организаций ответственных за корневые сервера различные подходы. Каждая из схем эффективна, какая из них более эффективна вопрос до конца не определенный.
Согласно всем отчетам, результаты тестирования подтверждают эффективность работы anycast для root DNS серверов в глобальном режиме, проблемы при работе DNS с использованием tcp не существенны.
Согласно исследованиям, проводимым с целью выявления эффективности распределения трафика корневых серверов в глобальных пределах, выяснено следующее: нагрузка на сервера распределяется эффективно, с точки зрения географического положения пользователей (а значит с точки зрения временных задержек ответов от серверов).
На текущий момент всего в мире 150 root DNS серверов, что более чем на порядок больше, чем первоначальное число - 13. Более подробную информацию о текущем состоянии дел по корневым серверам можно узнать тут http://www.root-servers.org/
Тот факт, что сервера географически распределены, делает DoS атаку на них более сложной. Бот сеть, которая сможет вывести из строя все корневые сервера также должна быть глобально распределенной. Ведь, если допустим, хосты атакующей бот сети будут сконцентрированы в основном в Европе, жители Южной Америки даже не будут подозревать о том, что на корневые DNS проводится атака.
В Интернете можно найти большой объем информации о технологии anycast и в частности об использовании ее для DNS. Что касается рамок данной статьи то, на этом я ограничусь.
Заключение.
Однозначно никто не может сказать, способна ли данная схема с существующим числом корневых DNS серверов противостоять распределенным DoS атакам в случае использования бот сетей с миллионами хостов. Ясно одно, схема хорошо масштабируемая, и даже если, не смотря ни на что, плохим парням удастся завалить глобальную систему DNS, то хорошие парни в ответ смогут ее многократно усилить. Похоже, хорошие парни побеждают.
Григорий Сандул, zelendoplit@yahoo.com