
Второй раз повторяю: я человек!
К сетевой общественности присоединяются уже домохозяйки в поисках рецептов, курортов и новых течений в моде, дети, скачивающие компьютерные игры, и многие другие слои населения. Но люди не единственные его обитатели и все чаще можно услышать о, так называемых, интернет-роботах…
Мысла Владислав // DgtlScrm // digitalscream@real.xakep.ru
С каждым днем растет активность пользователей Интернет. К сетевой общественности присоединяются уже домохозяйки в поисках рецептов, курортов и новых течений в моде, дети, скачивающие компьютерные игры, и многие другие слои населения. Но люди не единственные его обитатели и все чаще можно услышать о, так называемых, интернет-роботах…
1. Краткий обзор
Интернет-роботы или как их чаще называют боты, это программы созданные для автоматизированного выполнения некоторых функций в сети. В зависимости от их предназначения, цель работы таких программ тоже разная. Но объединяет роботов одно – избавить человека от выполнения однообразной рутинной работы. Казалось бы, в этом нет ничего зазорного. Бизнесмен, получающий на электронную почту самые свежие новости с огромного количества сайтов или роботы-поисковики, не должны приносить вред мировому сообществу. Но часто цель функционирования таких систем совершенно иная, кроме этого даже выше описанные задачи могут расцениваться негативно. Ведь если человек получает последние сводки новостей с помощью бота, он так и не увидит рекламного баннера, за показ которого владельцы сайта, возможно, получают деньги. Робот-поисковик, при определенных условиях может наткнуться на информацию, публичный доступ к которой крайне нежелателен (вспомнить хотя бы “Google Hacking”). Но это все крайности. Чаще всего, автоматизация – удел людей преследующих далеко не самые благие цели.
За примерами далеко ходить не стоит. Активно растущий уровень спама, очень сильно зависит от работы таких программ как сборщики почты (для пополнения базы адресов), автоматических регистраций почтовых ящиков (которые потом используются для рассылки). Роботы могут использоваться для «замусоривания» форумов, чатов, живых журналов; они могут заниматься рассылкой SMS через Web-интерфейсы, писать письма, участвовать в голосованиях, подбирать пароли и т.д. Все это приводит или к затруднительности получения искомой информации пользователем, или к более эффективной работе злоумышленников. Такое положение дел заставило людей, занимающихся компьютерной безопасностью, вплотную задуматься о способах решения этой проблемы, а хакеров, в свою очередь, о способах их обхода.
Изображение, содержащее цифры или слова, и просьба ввести их с клавиатуры…. Большое количество пользователей не понимают предназначения этой процедуры, многие создатели ботов не задерживаются долго на таких сайтах, но некоторых это не останавливает. Данная статья написана для того, чтобы разобраться с положением дел на этом фронте. И понять, действительно ли защищают нас от такого рода систем.
2. Компьютер или человек
Для определения действительно ли посетитель сайта является человеком или это программа, ему предстоит решить задачу, простую для человека, но не решаемую (а точнее тяжело решаемую) для компьютера. Такого рода задачи называются CAPTCHA.
CAPTCHA – это акроним, от выражения “Computer Aided Public Turing test to tell Computers and Humans Apart”. Собственно говоря, это Тест Тьюринга для различения человека от программы. Иногда CAPTCHA называют обратным тестом Тьюринга (Боле подробную формулировку этого понятия можно найти на Wikipedia).
Понятие Теста Тьюринга было введено Аланом М. Тьюрингом (1912-1954 гг.) в его работе “игра имитации”. Задача такого теста определить обладает компьютерная программа интеллектом, или точнее может ли она выдавать себя за человека. Критерий Тьюринга описан в виде игры “Имитация”. Суть игры заключается в том, что берется один мужчина, одна женщина и программа. Последняя, в свою очередь, не имея информации, о поле двух остальных участников, задает им вопросы. Цель программы – определить пол людей. Несмотря на критику этой теории, она внесла большой вклад в развитие систем искусственного интеллекта и философии, а в наше время еще нашла применение в борьбе с автоматизированным программным обеспечением.
На сегодняшний момент CAPTCHA можно встретить практически везде: при регистрации, авторизации, отправке сообщений, запросе какой-либо информации и т.д. Везде где может быть выгодной автоматизация, в том числе и нанесение ущерба владельцам Интернет сервисов или их клиентам.
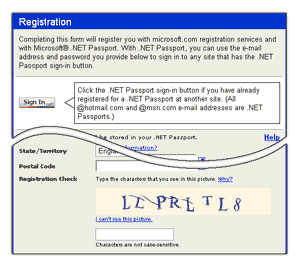
Рис. 1. Для получения паспорта Microsoft .NET,
также требуется пройти CAPTCHA тест.
CAPTCHA может быть реализована различными способами. Иногда требуется ввести не одно слово, а несколько. Встречаются также задания, где надо найти общий элемент, присутствующий на 4-х изображениях или сказать о содержимом искаженного рисунка. Для людей с плохим зрением существуют звуковые тесты или задачи, требующие логического мышления.

Рис. 2. CAPTCHA тесты бывают разными и носят разные названия
их объединяет только общая цель.
3. Вопрос безопасности
Интересно, что “CAPTCHA Project”, будучи пионером, в данной области, дали название течению, первоначальная цель которого остановить спам. Так и фирма “Spam”, первой начала практику массовой рассылки и тоже со временем определила название для “не желаемой корреспонденции рекламного характера” (хотя вообще то, тест получил название в 2000 году благодаря университету Carnegie Mellon и компании IBM, но именно этот проект был самым первым). На данный момент уже существует большой выбор среди производителей CAPTCHA. Этим занимаются, как и гиганты на рынке программного обеспечения, так и отдельные программисты. Соответственно, от квалификации производителя напрямую зависит, насколько легко можно обойти тест. В дополнение, CAPTCHA требует правильного внедрения. Часто очень хорошего качества тест, оказывается, легко обойти из-за того, что он используется без соблюдения политики безопасности.
Способов обойти или пройти тест достаточно много. Более того, на моей практике больше случаев, когда он оказывается бессилен против автоматизированных программ. Но обо всем по порядку. Начнем наш обзор с наименее вероятных техник и закончим самыми эффективными из них. В тоже время, от простых в реализации, до сложных.
3.1. Уязвимости программного обеспечения
Так всегда, если есть приложение, наверняка найдется пара-тройка уязвимостей. Нет, о переполнении буфера при прохождении теста мы говорить не будем. Хотя возможно и такие случаи встречаются. Начнем, пожалуй, с подбора контрольной информации.
3.1.1. Перебор вариантов и предугадывание результатов
Предугадывание результатов предполагает, что нам известно, какая информация напрямую влияет на генерацию CAPTCHA. Получить ее можно в двух случаях: уязвимый проект предоставляется в открытом исходном коде или она была получена с помощью эвристического анализа (определенное количество тестов, со всеми вытекающими). Такой информацией может быть наш IP адрес, время и знания об используемом генераторе случайных чисел. Последнее, не должно особо вас смущать, ибо для предсказывания псевдослучайных чисел существует огромное количество программ (Боле детально про эту тему вы можете прочитать в работе “Старый взгляд на новые вещи”). Ваша задача, в конце концов, сводится к поискам формулы, по которой создается тест. Но оставим этот способ для людей, должным образом владеющих математическим анализом, и перейдем к перебору.
Перебор возможных вариантов ответа, в принципе, работоспособный прием. Полным перебором можно воспользоваться, если ПО на сервере, неграмотно работает с сессией. Примером может служить движок vBulletin. Но о нем мы поговорим немножко позже, а пока только определим какие условия, являются необходимыми для подбора. Их всего два, более того это скорее зависимость коэффициентов:
- Чем больше время существования сессии
- Чем меньше набор символов CAPTCHA или их количество
Если сессия существует “от сабмита до сабмита”, перебор невозможен. В тоже время, когда тест требует ввести 10 символов, среди которых буквы, цифры и разные другие символы, вероятность успеха резко стремится к нулю. Практически всегда, использование перебора, требует манипуляции сессионной информацией. Поскольку, написание переборщика выходит за рамки этой статьи, а манипулирование сессий чаще всего дает и другие результаты, можно не рассматривать перебор более детально. Стоит упомянуть, что для некоторых тестов подходит перебор по словарю, а это более эффективно по сравнению с полным перебором.
3.1.2. Использование несуществующих сессий
Сессии – корень зла. Это утверждение, чаще других оказывается истинным. Поскольку цель статьи показать простоту решений, я буду стараться везде, где это только возможно, приводить примеры. На этот раз под прицел попал сайт www.umc.ua. Это страничка Украинского мобильного оператора UMC.
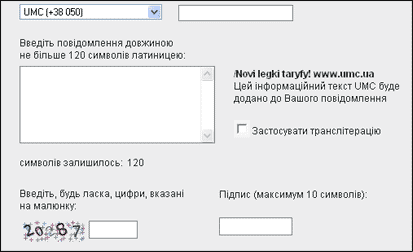
Рис. 3. Для отправки SMS сообщения из Интернет, пользователю
придется доказать что он человек а не программа
На этом сайте есть интерфейс для отправки SMS сообщений. Как и большинство операций такого рода, она требует пройти тест “вопрос-ответ” (CAPTCHA). Чтобы начать анализ и эксплуатирование данного сервиса, сперва, следует убрать все не нужное из HTML кода.
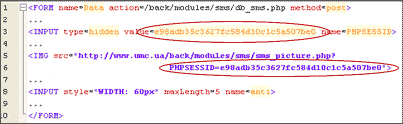
Рис. 4. Убрав все не нужное, видно, что работа CAPTCHA
основана на PHP сессии.
Взгляните на строки 3 и 6. Легко увидеть, что форма содержит скрытое поле с идентификатором сессии (строка 3) и изображение, сгенерированное специально для этой сессии (строка 6). В принципе, сама по себе, такая конструкция, не представляет никакой опасности. Но это только на первый взгляд, ее интересные особенности могут проявиться после определенных тестов. В данном случае, если в качестве идентификатора сессии (PHPSESSID) указать все нули, а поле для ответа на CAPTCHA оставить пустым, сообщение все равно посылается успешно. В чем дело? Такое могло произойти только тогда, когда при выборке данных из SQL, не проверяется количество полученных результатов (функция mysql_num_rows). Поэтому, фрагмент программы отправки сообщений может выглядеть как на рис.5.
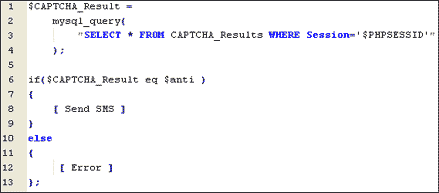
Рис. 5. Псевдокод для проверки CAPTCHA
Логика эксплуатирования достаточно проста. Все значения PHPSESSID в HTML форме - зануляются. После чего, сгенерированное сервером изображение, окажется пустым! Не долго думая, поле возле рисунка (туда, по идее, следует ввести цифры), оставляем пустым. И вот что происходит после отправки формы:
- Для несуществующего изображения в базе данных нет правильного ответа.
- Отсутствие правильно ответа в базе приводит к тому, что он равен пустой строке.
- Поле формы – “anti”, отвечающее за наш ответ, тоже пустое.
- Сравнивается правильный ответ с нашим (оба ответа - пустые строки).
- Проверка пройдена успешно, сообщение отослано.
Нехватка одной строки в программе, сводит на нет все остальные меры безопасности. Если бы программист проверил полученный результат из базы или хотя бы отвергал формы с пустым значением CAPTCHA-ответа, такая атака оказалась бы невозможной. Кстати, даже многие из Web-движков среднего уровня, содержат похожие недоработки.
3.1.3. Повторное использование сессий
Вы еще не забыли, что большинство ошибок возникают именно при обработке сессий. Я буду повторять это снова и снова, чтобы надолго закрепить в вашем сознании. Вот еще один довод: сессии существуют на определенном интервале времени. Вернемся к разбору vBulletin. На него я наткнулся, когда автоматизировал голосование сайта www.DogsOnAcid.com, посвященного D’n’B направлению в музыке.
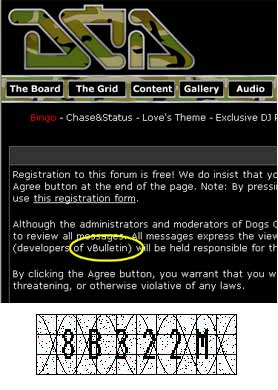
Рис. 6. DogsOnAcid один из множества сайтов, которые используют vBulletin
Популярность системы не всегда является признаком ее надежности. vBulletin – тому доказательство. Для регистрации в системе вам опять-таки придется пройти тест “вопрос-ответ”. Взглянем, что на этот раз нам предстоит обойти.

Рис. 7. Так в чистом виде выглядит CAPTCHA от vBulletin
Ситуация должна немного усложниться, поскольку кроме сессии пользователя (поле s, строка 7), введена еще сессия для изображения (поле imagehash, строка 25). Кроме всего этого, изображение выдается сервером по обоим входным параметрам (сессия и хеш). Скажу вам, честно, в исходный код я не смотрел. Но заметил, кое-что именно в HTML странице и Cookie. С начала о Cookie, их надо игнорировать вообще. Если бот работает в Internet Explorer или каком то другом браузере, выключите их. Если это приложение, то отсылая запрос к серверу, оставьте их значение пустым. Такое требование необходимо, поскольку после регистрации в них будет содержаться информация о том, что вы успешно зарегистрированы, кроме того, несоответствие сессии в Cookie и HTML форме, может настораживать атакуемые сервисы.
Теперь самое интересное, после успешной или неуспешной регистрации, вам создается новая сессия. Но, тем не менее, старая некоторое время еще лежит в базе и может быть повторно использована. Сессия пользователя, не должна вызывать у вас особого интереса, поскольку можно воспользоваться и новой. Другое дело хеш изображения. Ответив один раз правильно на CAPTCHA, используя старый хеш, вы можете дать тот же самый ответ, и он будет засчитан. Поэтому, представим себе ситуацию, когда вы один раз говорите боту правильный ответ, а он в свою очередь, за предоставленное ему время регистрирует пару сотен пользователей. Или в других системах, имеющих такую же ошибку, пишет комментарии, подбирает пароли, делает покупки и т.д.
Хорошо, если вы всегда рядом и можете ему подсказать ответ, в то время, когда старая сессия уже непригодна. Что же делать в случае, если от него требуется полностью автономная работа. Тут уже дело за вами, вы можете написать его так, чтобы он самостоятельно, с помощью полного перебора, получал правильный ответ, и дальше повторно им пользовался. Если вы не далеки от программирования, у вас есть все шансы написать относительно простенький распознаватель образов. Пускай он будет работать не самым быстрым образом, зато от него требуется распознать текст в течении нескольких минут, а поэтому скорость работы не критична. Дальше результат распознавания ставится на конвейер. Но о распознавании мы поговорим попозже.
Бывают и другие случаи, когда в HTML коде вы не встретите какого-либо упоминания о сессии. Не расстраивайтесь, она обязательно должна быть. Советую тогда взглянуть в содержимое Cookie. К повторному использованию сессий не равнодушны такие системы как Gotcha, Code Project Captcha, humanVerify, и другие. В них информация о сессии хранится именно в Cookie. Кстати в этих системах подменять надо именно сессию пользователя (в данном случае это PHPSESSID), поскольку хеш изображения там напрочь отсутствует.
Причина успешной атаки, как и в прошлый раз банальна, сессия (после отправки формы) не удаляется на сервере в течение достаточно большого промежутка времени. Одна строчка, не хватает всего одной строки.
3.1.3. Манипулирование значением VEWSTATE
Будьте бдительны, имея дело с сессиями. Особенно когда кто-то их создал за вас, и вы даже не задумываетесь о принципах их работы. Речь идет о приложениях написанных на ASP.NET. Элегантность и простота программирования на этом языке, проявляют побочные эффекты при их более детальном изучении. Для примера, возьмем сайт, требующий прохождения теста, при каждом входе пользователя в систему.
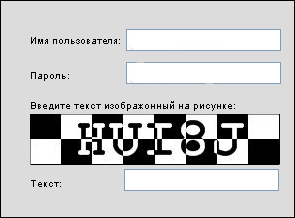
Рис. 8. Форма авторизации пользователя созданная на ASP.NET
Все должно быть правильно. Как только пользователь вводит свои логин и пароль, а ко всему и верно отвечает на вопрос, он успешно получает свою сессию. Программа входа в систему выглядит следующим образом:
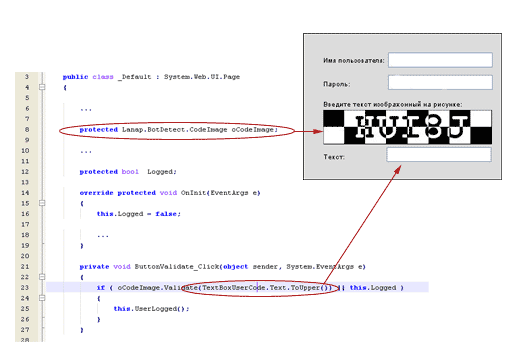
Рис. 9. Частичный исходный код авторизации пользователя на ASP.NET
На этой странице используется CATPCHA от фирмы Lanap. Соблюдая старую последовательность действий, заглядываем в исходный код страницы:

Рис. 10. Частичный исходный код авторизации пользователя в HTML
Попытки манипуляции с идентификатором изображения не увенчались успехом. Но, поскольку это приложение написано на ASP.NET, у нас есть возможность заняться экспериментами, манипулируя VEWSTATE.
Вообще VEWSTATE это тема отдельной статьи. Для тех, кто не знаком с его предназначением я коротко поясню некоторые нюансы. Это поле скрытое, и сделано оно для обеспечения удобно-программируемой системы клиент-сервер. VEWSTATE, своего рода сессия, но она берет на себя намного больше обязанностей. К ним относиться также и хранение переменных. Откровенно говоря, VEWSTATE может быть мощным орудием для атак SQL Injection, XSS и т.д. Но сейчас поговорим только об ее возможности хранить значения переменных.
Значит, когда вы ввели свой логин и пароль, они с большой вероятностью могут попасть в VEWSTATE. В нашем случае, успешный вход пользователя в систему, дополнительно контролируется переменной Logged. Как вы уже наверно догадались, она тоже хранится в VEWSTATE. Нет, следующий этап это не дешифрация VEWSTATE, в данном случае это лишнее. Вводим правильно логин, пароль и ответ на тест. В результате мы пройдем авторизацию. Дальше, в HTML коде страницы находим значение VEWSTATE и копируем его. Создаем HTML страницу, с формой авторизации. Из оригинальной формы, можно удалить все кроме VEWSTATE и SUBMIT. Интересно, что не требуются даже поля логин и пароль. Как вы думаете, почему? Все очень просто, их значения хранит VEWSTATE. Вы успешно авторизируетесь.
Проблема данной программы заключается в строке 23, там кроме ответа на CAPTCHA также проверяется ваш статус. Если вы уже вошли в систему, то данные не проверяются. А вы вошли, об этом свидетельствует значение VEWSTATE, пришедшее на сервер. Я не забыл напомнить, что это проблема сессии?
3.2. Распознавание образов
В широких кругах распознавание образов по праву считается самым эффективным способом для решения задач интерпретации. Это действительно так, ведь все остальные способы очень специфичны, и для их реализации требуются дополнительные затраты времени. С другой стороны, вероятность обнаружить уязвимость в атакуемом интерфейсе зависит от квалификации создателей ПО и злоумышленника. Часто может быть так, что попытки найти уязвимость заканчиваются неудачей. Поэтому в таких случаях, распознавание образов может оказаться очень привлекательным решением. Но не стоит думать, что речь идет исключительно о системах искусственного интеллекта, хотя они имеют место быть. Существует еще два способа, которые вошли в этот раздел.
3.2.1. Алгоритмическая обработка изображений (тест на идентичность)
Данный способ может применяться, для распознавания изображений с низким уровнем шумов или с их полным отсутствием. Его суть заключается в том, что для идентификации символов достаточно сравнений отдельных фрагментов изображения. Для примера(он косвенно касается темы статьи, но поможет в дальнейшем ее понимании), если вы используете незарегистрированный Total Commander (утилиту можно загрузить на сайте SoftKey.Ru), при каждом его запуске от вас требуется нажать на одну из трех кнопок. Ее номер задается случайным образом и отображается в строке «Please press button Nr.? to start the program! » (см. рис. 11).
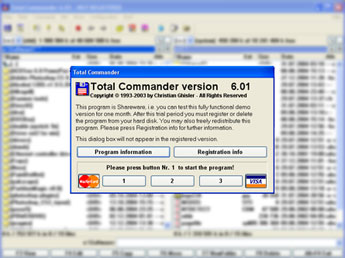
Рис. 11. Окно при запуске незарегистрированной копии Total Commander
Окно появляется в одних и тех же координатах, значит и позиция текста, гласящего о номере кнопки, тоже остается неизменной. Поэтому, сохранив изображения всех трех вариантов диалогового окна (для 1-й, 2-й и 3-й), вы получаете возможность, в любой момент времени, узнать какой номер требуется ввести. Все что для этого необходимо, это обычная проверка на идентичность, подготовленных изображений (скриншотов) с содержимым на экране. Далее, определив номер кнопки, можно программно послать на нее нажатие мышки, поскольку ее позиция тоже будет статичной.
Ситуация может быть немного усложнена, в случае когда требуется распознать текст размещенный на текстуре или состоящий из немоноширных символов. Для примера, можно взглянуть на сайт www.privatmobile.com.ua. Это сайт мобильного оператора, который предоставляет множество услуг настраиваемых через Интернет. Одна из них это смена номера телефона клиента. Когда-то, передо мной была поставлена задача автоматизации этого процесса. Для подтверждения данной операции, от пользователя требуется отослать SMS сообщение с контрольным текстом. Проблема заключается в том, что изначально он отображается в виде изображения, а не как текстовая информация (см. рис. 12).

Рис.12. Код подтверждения на сайте Privat::Mobile
отображается как рисунок
Как видно из рисунка, шум в изображении отсутствует вообще. Для успешной идентификации графической информации необходимо всего два этапа (Рис. 13):
1. избавление от фона изображения, для позиционно независимой идентификации символов.
2. трассировка контура символов, чтобы избавится от ситуации их наложения друг на друга (в данном случае это происходит с первым символом, относительно второго).
Рис. 13 Исходное изображение и результаты работы 2-х фильтров
После предварительной обработки изображения, каждая из букв будет идентифицирована в отдельности. Как и в прошлом примере, подготовив «графический словарь», сделать это можно с помощью обычного сравнения изображений. Для программиста средней квалификации, составление программы такого уровня сложности, не составит большой проблемы. Несмотря на это, сегодня в Интернете, еще очень часто можно встретить страницы, на которых генерируются рисунки такой же сложности, а то и проще.
В дополнение, на сайте www.kyivstar.net, для отправки сообщений, тоже требуется правильно ответить на CAPTCHA.
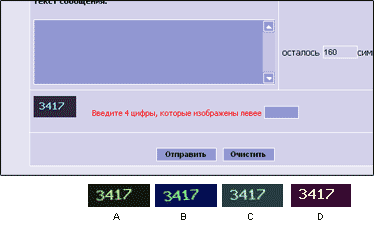
Рис. 14. Сайт мобильного оператора КиевСтар и несколько
вариантов, сгенерированных изображений.
Как вы можете заметить, в некоторых случаях тест можно легко обойти, дожидаясь, пока сгенерированное изображение будет под нулевым углом (вариант D). Но этот процесс можно значительно приблизить. Для генерации CAPTCHA используется скрипт image.php. Помните, что я говорил о сессии? Так вот, учитывая, что сессия существует несколько минут, повторное обращение к image.php, дает изображение с теми же цифрами, только под другим углом. Потребуется всего около пяти запросов, чтобы получить изображение в легко обрабатываемом виде. А идентифицировав текст, можно отправлять форму на сервер. В этом случае, проблема не только в простоте рисунка, дополнительно полагаясь на особенности сессии, вы можете легко обойти тест.
3.2.2. Распознавание образов
Все выше описанные примеры, очень просты в использовании. А сейчас речь пойдет о немного более сложных технологиях, но в то же время и более эффективных. Мы поговорим о распознавании образов, в чистом виде. Речь идет о задачах OCR – оптического распознавания символов.
Многие считают, распознавание образов недосягаемой вершиной. Хочу вас заверить, что это утверждение далеко от истины. Вы как потребитель, наверно не раз использовали Fine Reader. Хотя можно, усомнится в качестве его работы, вспомните, что обрабатываемый им текст имеет относительно малые размеры и большой объем. А ко всему и скорость распознавания на высоком уровне. Другое дело CAPTCHA: с одной стороны нормальный размер и короткий текст, но с другой – высокий уровень шумов и деформаций.
На сегодняшний момент уже существует много проектов занимающихся исключительно распознаванием CAPTCHA. Одним из наиболее известных является “PWNtcha”.
В открытых публикациях также описывались успешные попытки распознавать тесты, сгенерированные с помощью Gimpy. Причем процент успеха составляет 92%.

Рис. 15. Примеры CAPTCHA которые были распознаны
исследователями
Работа PWNtcha, показывает тоже внушительные результаты:

Рис. 16. Фрагмент из списка CAPTCHA изображений,
распознанных программой PWNtcha
Использование искусственного интеллекта в скором времени должно свести на нет, применение визуальных тестов. Предварительно обученная нейронная сеть, может с большой точностью правильно распознать изображение. Существует один существенный нюанс, пока предложенные разработки не обладают высокой скоростью работы. В основном это связано с алгоритмами распознавания, а часто бывает так, что их используется несколько. Но для злоумышленника, использующего нейронные сети, дела стоят куда проще. Его задача сводится к обучению сети. Это не проблема, поскольку большинство предлагаемых CAPTCHA можно скачать и таким образом организовать обучение.
Ко всему перечисленному, добавьте понятия ассоциативных связей, генетического алгоритма, и возможность успешного распознавания будет расти "из поколения в поколение". Генотип алгоритмов обработки изображений, если это звучит абсурдно, то хорошенько задумайтесь над своими познаниями в областях генетики и создания искусственного интеллекта. Существующие проекты, это лишь вершина айсберга.
3.2.2. Использование человеческого ресурса
Пожалуй, самым интересным из существующих решений, это то что придумали спамеры, для регистрации бесплатных почтовых ящиков в системах Yahoo и HotMail. Они не искали уязвимостей, не писали распознавание образов. Спамеры подключили к своей борьбе приличную часть пользователей Интернета, а точнее любителей бесплатного порно (см. Рис. 17).
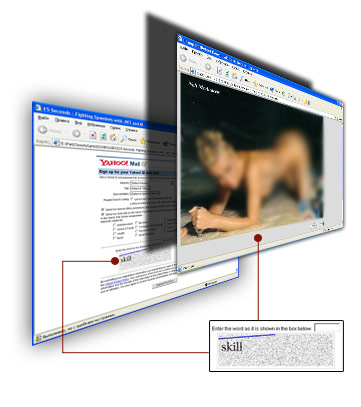
Рис. 17. Любителям бесплатного просмотра сайтов
порнографического характера необходимо проходить
CAPTCHA тест, для каждой следующей фотографии.
Спамеры создают бесплатные фото галереи порнографического характера. Единственное, что требуется от посетителя, это отвечать на CAPTCHA тест, для просмотра следующей фотографии. Сам тест, выбирается из формы регистрации почтового сервера. Ответ пользователя, соответственно вставляется в туже форму, и таким образом каждая фотография равняется новому почтовому ящику. Технически, такая система не требует высокой квалификации злоумышленника, а поэтому является очень простой в реализации. Кроме этого, любителей порно тоже не мало.
3.3. Рекомендации по безопасности
Как легко убедиться, что способов обойти проверку, хоть отбавляй. Поэтому этим мы и займемся. Вот некоторые рекомендации:
- Время существования сессии должно быть ограничено, пяти минут вполне хватает. Если заполняемая форма очень большая, разбейте ее на несколько частей, а сессию создавайте на последнем этапе.
- В случае получения формы, сессия должна быть немедленно удалена, чтобы избежать повторного ее использования.
- Обязательно проверяйте полученные данные на пустые значения. Это должно спасти вас от ситуации с несуществующей сессией. Это также поможет вам с проблемой VIEWSTATE, если вы программируете на ASP.NET.
- Желательно все данные о сессии хранить в Cookie и не выносить в HTML код страницы. Кстати, в HTML можно выносить фиктивные сессии, для отслеживания попыток взлома на их начальной стадии.
- Если тест находится в регистрационной форме, поставьте блокировку по IP, на повторную регистрацию. Это не панацея, но все же. В дополнение, если в генерации CAPTCHA будет принимать участие и IP адрес, то история с vBulletin с вами не повторится.
- Не генерируйте простых изображений, но и не перегибайте палку с эффектами.
На самом деле перед нами возникла достаточно большая проблема. Существующие системы не защищают своих потребителей. На этот раз речь идет не о уязвимостях, а о самой технологии. Усложняя CAPTCHA мы уже часто, сами с трудом понимаем, что за текст скрывается в этом изображении. Так не может продолжаться дальше. Область ИИ постепенно развивается, дело не в умных домах и не в чат-ботах, готовых поддержать разговор. Дело в искусственном интеллекте, нейронных сетях и ассоциативном мышлении. Что дальше? Скорее всего, это приведет к необходимости внедрения биометрических систем, со всеми из этого вытекающими. Будьте бдительны…
"Лаборатория Касперского" - международная компания-разработчик программного обеспечения для защиты от вирусов, хакеров и спама. Продукты компании предназначены для широкого круга клиентов - от домашних пользователей до крупных корпораций. В активе "Лаборатории Касперского" 16-летний опыт непрерывного противостояния вирусным угрозам, позволивший компании накопить уникальные знания и навыки и стать признанным экспертом в области создания систем антивирусной зашиты.
Компания SoftKey – это уникальный сервис для покупателей, разработчиков, дилеров и аффилиат–партнеров. Кроме того, это один из лучших Интернет-магазинов ПО в России, Украине, Казахстане, который предлагает покупателям широкий ассортимент, множество способов оплаты, оперативную (часто мгновенную) обработку заказа, отслеживание процесса выполнения заказа в персональном разделе, различные скидки от
Академия Информационных Систем (АИС) создана в 1996 году и за время работы обучила свыше 7000 специалистов различного профиля. АИС предлагает своим партнерам десятки образовательных программ, курсов, тренингов и выездных семинаров. Сегодня АИС представлена направлениями: «Информационные технологии», «Дистанционное обучение в области ИТ», «Информационная безопасность, «Управление проектами», «Бизнес-образование», «Семинары и тренинги», «Экологические промышленные системы», «Конференции», «Консалтинг» и «Конкурентная разведка на основе Интернет». АИС является организатором конференций по информационной безопасности, которые стали общепризнанными научно-практическими мероприятиями федерального значения. Ближайшая из них - четвёртая всероссийская конференция «Обеспечение информационной безопасности. Региональные аспекты» - пройдет в Сочи с 13 по 17 сентября текущего года. http://www.infosystem.ru/longconf.php?fid=1119938331389056
Интернет-магазин www.watches.ru входит в состав крупной специализированной сети часовых салонов МОСКОВСКОЕ ВРЕМЯ, которая насчитывает более 40 торговых точек по Москве и регионам России. В нашем магазине представлены более 3000 моделей часов производства Швейцарии, Германии, Франции и Кореи. Доставка по Москве - бесплатно. Для постоянных клиентов существует гибкая система скидок и выдается накопительная дисконтная карта «Московское время».
мы в MAX