Поиск и эксплуатация уязвимости пользовательского словаря в Android (CVE-2018-9375)
Всегда старайтесь выйти за рамки шаблонного мышления и помните, что время – один из наиболее ценных ресурсов.
Автор: Daniel Kachakil
Некоторое время я проводил аудит смартфон на базе Android и, в частности, все установленные приложения. Обычно, если позволяет время, я стараюсь вручную исследовать код. Именно подобным образом мне удалось найти уязвимость, позволяющую получить доступ к содержимому, которое, как предполагается, должно быть защищенным, а конкретно – к пользовательскому словарю, где хранятся сохраненные нестандартные слова.
Теоретически, доступ к пользовательскому словарю разрешен только привилегированным аккаунтам, авторизированным Редакторам Методов Ввода (IME) и корректорам орфографии. Однако существовал метод обхода этих ограничений, позволяя вредоносному приложению обновлять, удалять и даже извлекать содержимое словаря без необходимости в получении прав доступа или взаимодействия с пользователем.
Эта уязвимость среднего уровня опасности была отнесена к категории, связанной с расширением привилегий, и исправлена в июне 2018 года. Данная проблема была в следующих версиях Android: 6.0, 6.0.1, 7.0, 7.1.1, 7.1.2, 8.0 и 8.1.
Персональный словарь
В Android есть специальный словарь, который можно пополнять вручную или автоматически на базе тех слов, которые вводит пользователь. Доступ к этому словарю можно получить через меню «Настройки -> Язык и ввод -> Пользовательский словарь» (Settings -> Language & keyboard -> Personal dictionary). В некоторых случаях соответствующий пункт меню находится в другом месте. В словаре может содержаться в том числе конфиденциальная информация: имена, адреса, телефонные номера, электронная почта, пароли, коммерческие бренды, нестандартные слова (наименования заболеваний, лекарств, технический жаргон и т. д.) и даже номера кредитных карт.
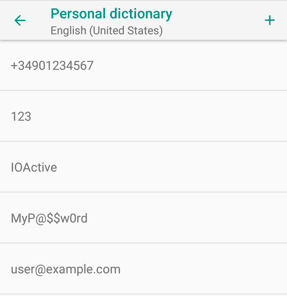
Рисунок 1: Пример содержимого пользовательского словаря
Пользователь также может назначить короткую последовательность для ускоренного ввода длинной фразы или предложения как, например, полного домашнего адреса.
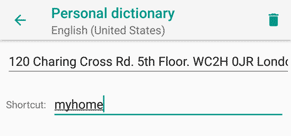
Рисунок 2: Пример привязки короткого слова к более длинной фразе
Содержимое персонального словаря хранится в базе данных SQLite в таблице «words» (независимо от «android_metadata»), которая состоит из шести колонок:
- _id (INTEGER, PRIMARY KEY)
- word (TEXT)
- frequency (INTEGER)
- locale (TEXT)
- appid (INTEGER)
- shortcut (TEXT)
Основное наше внимание будет приковано на колонке «word» поскольку, исходя из названия, там как раз хранятся слова. Хотя остальные колонки и другие таблицы в той же базе также будут доступны.
Технические детали уязвимости
В старых версиях Android доступ к пользовательскому словарю управляется следующими константами:
- android.permission.READ_USER_DICTIONARY (права на чтение).
- android.permission.WRITE_USER_DICTIONARY (права на запись).
В новых версиях эта тема уже не работает. Согласно официальной документации [1] (см. раздел Ссылки): «Начиная с API 23, пользовательский словарь доступен только через IME и корректор орфографии». Вышеупомянутые константы были заменены внутренними проверками, и теоретически доступ к пользовательскому словарю (content://user_dictionary/words) стал разрешен только привилегированным учетным записям (например, root и system), подключенным IME и корректорам орфографии.
Если посмотреть код репозитория AOSP (Android Open Source Project) на предмет изменений [2], то можно обнаружить новую функцию canCallerAccessUserDictionary, которая стала вызываться внутри стандартных методов query, insert, update и delete класса UserDictionary, предназначенного для работы со пользовательским словарем, и не допускает неавторизованный вызов этих методов.
В методах query и insert нововведение работает эффективно, однако в случае с функциями update и delete та же самая проверка выполняется слишком поздно. Тем самым у нас возникает уязвимость, позволяющая любому приложению успешно обойти проверку авторизации и запустить соответствующие функции через доступный провайдер контента.
Если обратить внимание на выделенные фрагменты в коде класса UserDictionaryProvider [3], то можно увидеть, что проверки авторизации выполняются после того, как запрос к базе данных уже выполнен:
@Override
public int delete(Uri uri, String where, String[] whereArgs) {
SQLiteDatabase db = mOpenHelper.getWritableDatabase();
int count;
switch (sUriMatcher.match(uri)) {
case WORDS:
count = db.delete(USERDICT_TABLE_NAME, where, whereArgs);
break;
case WORD_ID:
String wordId = uri.getPathSegments().get(1);
count = db.delete(USERDICT_TABLE_NAME, Words._ID + "=" + wordId
+ (!TextUtils.isEmpty(where) ? " AND (" + where + ')' : ""), whereArgs);
break;
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
// Only the enabled IMEs and spell checkers can access this provider.
if (!canCallerAccessUserDictionary()) {
return 0;
}
getContext().getContentResolver().notifyChange(uri, null);
mBackupManager.dataChanged();
return count;
}
@Override
public int update(Uri uri, ContentValues values, String where, String[] whereArgs) {
SQLiteDatabase db = mOpenHelper.getWritableDatabase();
int count;
switch (sUriMatcher.match(uri)) {
case WORDS:
count = db.update(USERDICT_TABLE_NAME, values, where, whereArgs);
break;
case WORD_ID:
String wordId = uri.getPathSegments().get(1);
count = db.update(USERDICT_TABLE_NAME, values, Words._ID + "=" + wordId
+ (!TextUtils.isEmpty(where) ? " AND (" + where + ')' : ""), whereArgs);
break;
default:
throw new IllegalArgumentException("Unknown URI " + uri);
}
// Only the enabled IMEs and spell checkers can access this provider.
if (!canCallerAccessUserDictionary()) {
return 0;
}
getContext().getContentResolver().notifyChange(uri, null);
mBackupManager.dataChanged();
return count;
}
Также заметьте, что в файле AndroidManifest.xml не предусмотрено никаких дополнительных мер защиты (например, intent-фильтры или права доступа) для экспортируемого явным образом провайдера контента.
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.android.providers.userdictionary"
android:sharedUserId="android.uid.shared">
<application android:process="android.process.acore"
android:label="@string/app_label"
android:allowClearUserData="false"
android:backupAgent="DictionaryBackupAgent"
android:killAfterRestore="false"
android:usesCleartextTraffic="false"
>
<provider android:name="UserDictionaryProvider"
android:authorities="user_dictionary"
android:syncable="false"
android:multiprocess="false"
android:exported="true" />
</application>
</manifest>
Злоумышленнику не составит особого труда обновить содержимое пользовательского словаря через запуск следующего кода из любого приложения и без специальных прав доступа:
ContentValues values = new ContentValues();
values.put(UserDictionary.Words.WORD, "IOActive");
getContentResolver().update(UserDictionary.Words.CONTENT_URI, values,
null, null);
Схожим образом, можно удалить отдельные строки или весь пользовательский словарь:
getContentResolver().delete(UserDictionary.Words.CONTENT_URI, null, null);
Оба метода (update и delete) возвращают количество строк, участвующих в операции, однако в случае с нелегитимными вызовами, эти методы всегда возвращают 0, что немного затрудняет работу с информацией, которая выдается провайдером контента.
На первый взгляд, кажется, что вышеуказанные операции – единственное, что доступно злоумышленнику. Конечно, удаление или обновление произвольных записей может навредить пользователю, однако намного интереснее получить доступ к персональным данным.
Даже если упомянутая уязвимость отсутствует в функции query, полная выгрузка содержимого словаря все еще возможна через реализацию атак, сочетающих эксплуатацию временных характеристик и сторонних каналов. Поскольку аргументы условия where полностью контролируется злоумышленником и тот факт, что запрос на обновление выполняется дольше, если строки изменяются, чем тот же самый запрос, который никак не влияет на содержимое таблицы, мы можем реализовать вполне эффективную атаку.
Концепция атаки
Рассмотрим следующий фрагмент кода, запускаемого локально из вредоносного приложения:
ContentValues values = new ContentValues();
values.put(UserDictionary.Words._ID, 1);
long t0 = System.nanoTime();
for (int i=0; i<200; i++) {
getContentResolver().update(UserDictionary.Words.CONTENT_URI, values,
"_id = 1 AND word LIKE 'a%'", null);
}
long t1 = System.nanoTime();
Если выполнять один и тот же запрос достаточное количество раз (например, 200 раз, хотя все зависит от устройства), временной интервал (t1-t0) между вычислением SQL-условия, результатом которого является «истина», и тем же самым условием, результатом которого является «ложь», становится заметным. В этом случае злоумышленник может извлечь всю информацию из базы данных, реализуя классическую Boolean Blind SQL-инъекцию в связке с эксплуатацией временных характеристик.
Таким образом, если первое слово в пользовательском словаре начинается с символа «a», результатом проверки условия станет «истина» и код, показанный выше, будет выполняться дольше (допустим, 5 секунд). Тот же самый запрос, у которого результатом проверки условия станет «ложь», будет выполняться быстрее (например, 2 секунды), поскольку в этом случае ни одна строка задействована не будет. Если в результате выполнения запроса мы сразу же получим «ложь», пробуем то же самое с символами «b», «c» и т. д. Если в результате мы получим «истину», значит, первый символ в слове обнаружен, и можно переходить к вычислению второго, используя ту же самую технику. Далее переходим к следующему слову и так до тех пор, пока не выгрузится весь словарь или отфильтрованное множество строк и полей.
Чтобы избежать реального изменения содержимого базы, обновляем колонку «_id» на то же самое значение. В итоге запрос будет выглядеть так:
UPDATE words SET _id=N WHERE _id=N AND (condition)
Если условие истинно, строка с идентификатором N будет обновлена таким образом, что никакие изменения не произойдут, поскольку в колонку «_id» будет занесено первоначальное значение. Этот метод извлечения данных называется неинтрузивным, когда время выполнения используется в качестве стороннего информационного канала.
Поскольку мы можем заменить условие выше на любой вложенную выборку (запрос select), в этой атаке доступны любые SQL-выражения, которые поддерживаются в SQLite, например:
· Содержится ли конкретное слово в словаре?
· Получить все 16-символьные слова (например, номера кредитных карт).
· Получить все слова, к которым привязана короткая последовательность (ярлык).
· Получить все слова с точкой.
Схема реализации атаки
Процедура, описанная выше, может быть полностью оптимизирована и автоматизирована. Я написал простейшее Android-приложение с целью доказательства своей концепции.
Приложение базируется на том обстоятельстве, что мы можем вслепую обновить произвольные строки в базе UserDictionary через вышеуказанного провайдера контента. Если запрос UPDATE затрагивает одну или более строк, время на выполнение требуется больше. По сути, у нас есть все, что нужно, чтобы узнать результат проверки SQL-условия («истина» или «ложь»).
Однако поскольку на данный момент у нас нет никакой информации относительно содержимого словаря (и даже о внутренних идентификаторах), вместо перебора всех возможных идентификаторов мы начнем со строки с наименьшим идентификатором и заменим значение колонки «frequency» на произвольное число. Эту задачу можно решить несколькими корректными способами.
Поскольку в Android будут запущены одновременно несколько разделяемых процессов общая продолжительность выполнения будет варьироваться во время разных запусков. Кроме того, время выполнения будет зависеть от производительности устройства. С другой стороны, можно вычислить среднее значение после многократных запусков. Нам лишь нужно подобрать количество итераций в зависимости от устройства и текущей конфигурации (например, если используется режим энергосбережения).
Я начал со сложного подхода, помогающего определить, соответствует ли время ответа значениям «истина» и «ложь», но в итоге реализовал более простой метод, дающий вполне точные и надежные результаты. Суть заключается в том, что нужно выполнить одинаковое количество запросов, которые всегда и истинны (например, с конструкцией «WHERE 1=1») и ложны (например, с конструкцией «WHERE 1=0»). Затем нужно вычислить среднее значение, которое будет использоваться в качестве порога. Если время выполнение больше порогового значения, значит, в результате получаем «истину», в противном случае – «ложь». Как вы понимаете, мы не использовали искусственный интеллект, биг дату, блокчейн или облачные вычисления, но часто простейшие алгоритмы могут давать вполне рабочие результаты.
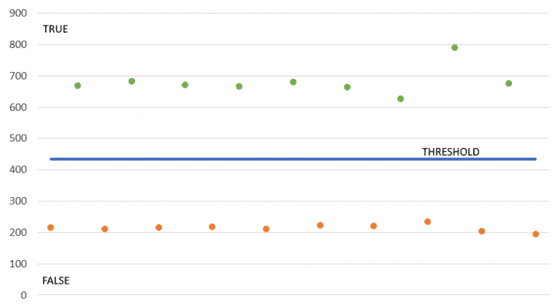
Рисунок 3: Распределение времени выполнения относительно порогового значения
Как только у нас появился метод дифференциации между истинными и ложными запросами, выгрузить всю базу не составит особого труда. В примере, рассмотренном в предыдущем разделе, легко разобраться, но в целом этот способ не самый эффективный. Вместо числовых запросов мы воспользуемся алгоритмом бинарного поиска [4]:
· Определяем количество строк в таблице (необязательная операция)
o SELECT COUNT(*) FROM words
· Определяем наименьший идентификатор
o SELECT MIN(_id) FROM words
· Определяем длину слова, к которому привязан наименьший идентификатор
o SELECT length(word) FROM words WHERE _id=N
· Извлекаем все символы найденного слова (в формате ASCII/Unicode)
o SELECT unicode(substr(word, i, 1)) FROM words WHERE _id=N
· Определяем следующий наименьший идентификатор, который больше найденного, и повторяем вышеуказанные шаги
o SELECT MIN(_id) FROM words WHERE _id > N
Помните о том, что мы не можем извлечь цифровые и буквенные значения напрямую, и нам нужно преобразовать выражения в булевые запросы, которые затем будут вычисляться как истинные или ложные на основе времени выполнения. Так работает алгоритм бинарного поиска. Вместо перебора всех символов напрямую формируется запрос: «больше ли код символа значения X». Этот запрос выполняется повторно, а значение X меняется в каждой итерации до тех пор, пока мы не найдем корректное значение, выполнив log(n) запросов. Например, если код текущего значения 97, итерации алгоритма будут следующими:
|
Номер итерации |
Условие |
Результат |
Максимальное значение |
Минимальное значение |
Среднее значение |
|
- |
- |
- |
255 |
0 |
127 |
|
1 |
N > 127? |
Нет |
127 |
0 |
63 |
|
2 |
N > 63? |
Да |
127 |
63 |
95 |
|
3 |
N > 95? |
Да |
127 |
95 |
111 |
|
4 |
N > 111? |
Нет |
111 |
95 |
103 |
|
5 |
N > 103? |
Нет |
103 |
95 |
99 |
|
6 |
N > 99? |
Нет |
99 |
95 |
97 |
|
7 |
N > 97? |
Нет |
97 |
95 |
96 |
|
8 |
N > 96? |
Да |
97 |
96 |
96 |
Реализация эксплоита
Процедура, описанная выше, была реализована в виде утилиты. Исходный код и скомпилированный APK доступен в репозитории https://github.com/IOActive/AOSP-ExploitUserDictionary.
Минималистический пользовательский интерфейс показан на рисунке ниже:
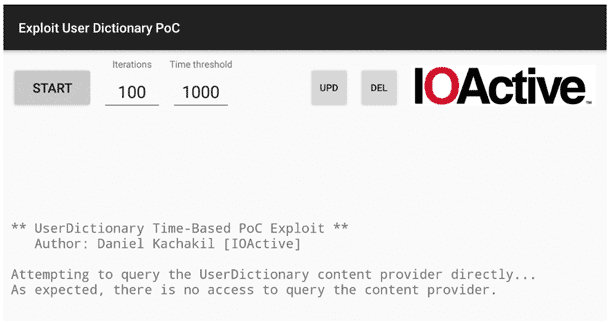
Рисунок 4: Интерфейс утилиты для эксплуатации уязвимости
Вначале приложение пытается получить доступ к контент-провайдеру пользовательского словаря, запрашивая количество записей. В обычных условиях (когда мы работаем от имени обычного пользователя и т. д.) доступ к словарю не разрешен. Если по какой-то причине у нас есть прямой доступ, никаких эксплоитов нам не потребуется. Но даже в этом случае можно потратить некоторое количество ресурсов процесса на тестирование утилиты вместо майнинга криптовалют :).
Как говорилось выше, нам нужно два параметра:
· Изначальное количество итераций: сколько раз нужно выполнять один и тот же запрос, чтобы получить существенную разницу во времени.
· Минимальный порог (в миллисекундах): какой временной уровень подойдет в качестве наименьшего допустимого значения.
Хотя текущая версия утилиты подбирает эти параметры автоматически, на самой начальной стадии оба параметра выставлялись вручную, и эти два поля перекочевали с тех времен.
В теории, чем больше эти два числа, тем большую точность мы получим, но в то же время замедлится процесс извлечения данных. Если значения уменьшить, понизится точность, но повысится время извлечения. Поэтому были прописаны два минимальных значения: 10 итераций и 200 миллисекунд.
Если нажать кнопку «Start», приложение начнет подбирать параметры автоматически. Вначале будут запущены несколько запросов и отброшены первоначальные результаты как нерепрезентативные. Затем выполняется первоначально заданное количество итераций и вычисляется временной порог. Если полученный порог выше изначально заданного минимума, тестируется точность посредством запуска 20 запросов, часть которых возвращают «истину», а часть – «ложь». Если точность неудовлетворительная (допускается только одна ошибка), количество итераций увеличивается и весь процесс повторяется заданное количество раз до тех пор, пока параметры не будут правильно настроены, или процесс завершится, если условия не будут удовлетворены.
После начала процесса некоторые элементы интерфейса станут недоступны, и мы увидим подробную стенограмму в окне ниже (или при помощи команды logcat), где, помимо других сообщений, показывается текущий идентификатор строки, все SQL-подзапросы, общее время и прогнозируемую истинность. Символы по мере извлечения будут отображаться в верхней строке.
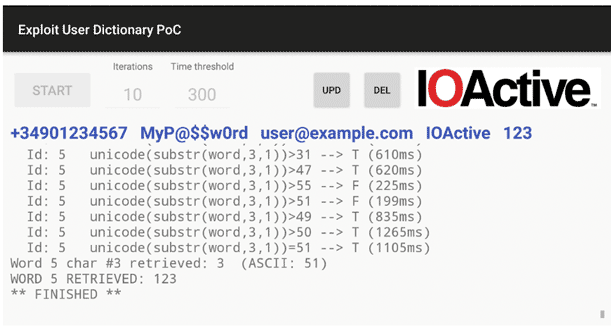
Рисунок 5: Процесс извлечения данных
Кнопки «UPD» и «DEL» с правой стороны не имеют отношения к извлечению символов, а предназначены для прямых вызовов к контент-провайдеру для выполнения запросов UPDATE и DELETE соответственно. Эти запросы ограничиваются только словами, начинающимися с числа 123, чтобы избежать случайного удаления всего содержимого словаря. Таким образом, чтобы протестировать функционал этих кнопок нужно добавить в словарь новый элемент, если значения, удовлетворяющего нужным условиям, изначально не было.
Демонстрация работы утилиты
Вероятно, самый простейший способ подытожить сказанное – наглядно увидеть весь процесс в действии. На видео ниже показан демо пример, записанный во время работы с реальным устройством.
https://www.youtube.com/watch?v=8i-oMcaJw40
https://www.youtube.com/watch?v=VQf-INNTKKU
Дополнительные соображения
Между теорией и практикой всегда есть расхождения, и я бы хотел рассказать о некоторых проблемах, которые возникли во время разработки утилиты. Во-первых, не забывайте, что этот инструмент реализован на скорую руку. Моей главной задачей было показать, что концепция рабочая. У этого эксплоита есть несколько ограничений, и код во многом не соответствует наилучшим практикам программирования. Я не задавался целью сделать продукт, который эффективен, удобен для сопровождения, имеет хороший пользовательский интерфейс и так далее.
На первоначальных стадиях я не заботился об интерактивности и просто все выгрузил в логи Android. Когда было решено, что нужно добавить графическую оболочку, я вывел запуск кода в отдельный поток, чтобы не блокировать поток пользовательского интерфейса (в противном случае приложение может перестать подавать признаки жизни и завершится средствами операционной системы). После разделения поток точность метода заметно снизилась, поскольку у потока выполнения кода был не особо высокий приоритет. Я выставил максимально возможный приоритет «-20», и все снова заработало, как полагается.
Обновление интерфейса из другого потока может привести к краху приложения, который детектируется и предотвращается через динамические исключения (runtime exception). Таким образом, чтобы вывести логи, я пользовался этими исключениями через вызов runOnUiThread. В реальном эксплоите в пользовательском интерфейсе нет необходимости.
Если персональный словарь пуст, мы не можем использовать строки для обновления, и, соответственно, все запросы будут выполняться примерно одинаковое время. В этом случае извлекать будет нечего, утилита не сможет подстроить параметры и в конечном итоге остановится. Иногда может произойти случайная калибровка даже с пустой базой, и программа будет пытаться извлечь мусор или псевдослучайные данные.
В обычном смартфоне через некоторое время ОС будет переходить в спящий режим, и производительность сильно снизится. Соответственно, время выполнения увеличится и все вызовы будут считаться истинными. Эту проблему можно было бы решить разными способами, но я выбрал наипростейший, который связан с классом android.os.PowerManager.WakeLock, чтобы предотвратить подвешивание приложения операционной системой. Я не заморачивался, чтобы вернуть все обратно, поэтому потребуется принудительно завершить приложение.
Поворот экрана также вызывает проблемы, и я принудительно переключился в ландшафтный режим, чтобы избежать автоповорота и заодно воспользоваться большей шириной для отображения сообщений в одну строку.
После нажатия кнопки «START» некоторые элементы интерфейса станут недоступны. Если нужно перенастроить параметры или запустить много раз, потребуется закрытие и повторное открытие приложения.
Некоторые внешние события и параллельные процессы (например, синхронизация почты или получение push-сообщений) могут конфликтовать с приложением и потенциально стать причиной неточных результатов. В этом случае попробуйте отключить доступ к сети или закрыть некоторые программы.
Пользовательский интерфейс не поддерживает локализацию и не предназначен для извлечения слов в кодировке Unicode (хотя реализовать этот функционал не составляет особого труда, я не ставил себе такую задачу).
В утилите намеренно реализовано ограничение на извлечение первых 5 слов, отсортированных по внутреннему идентификатору.
Устранение уязвимости
В исходном коде устранить уязвимость не составляет особого труда. Нужно лишь переместить проверочный вызов на предмет наличия у вызывающего нужных прав в начало соответствующих функций, чего вполне достаточно для исправления бреши.
Помимо описания уязвимости мы отправили заплатку разработчикам Google, при помощи которой уязвимость была устранена: https://android.googlesource.com/platform/packages/…
Поскольку проблема была исправлена в официальном репозитории, нам, пользователям, нужно убедиться, что установленные обновления содержат патч для уязвимости CVE-2018-9375. Для Google Pixel/Nexus заплатка была выпущена в июне 2018 года: https://source.android.com/security/bulletin/pixel/2018-06-01
Если по каким-то причинам вы не можете установить это обновление, проведите ревизию персонального словаря на предмет присутствия конфиденциальной информации.
Заключение
Разработка программного обеспечения не так проста, как кажется на первый взгляд. Как вы могли убедиться, неправильно расположенный вызов функции может стать причиной серьезных последствий. Изменения, целью которых было улучшение безопасности и защита пользовательского словаря, привели к противоположному результату, когда словарь стал доступен любому желающему. Эта уязвимость оставалась незамеченной почти три года.
Поиск подобных брешей не сложнее, чем чтение и понимание исходного кода. Просто нужно отследить поток выполнения. Автоматические тесты могли бы помочь в детектировании подобного рода проблем на ранних стадиях и предотвратили бы повторное появления в будущих изменения. Однако эти тесты не всегда так легко реализовать и поддерживать.
Мы также изучили методы, как выжать максимум из того, что у нас есть. Изначально у нас была возможность только удалить или испортить содержимое словаря, но в итоге мы научились извлекать информацию посредством реализации атаки с использованием стороннего канала и временных характеристик.
Всегда старайтесь выйти за рамки шаблонного мышления и помните, что время – один из наиболее ценных ресурсов. Каждая наносекунда на счету!
Ссылки
-
https://developer.android.com/reference/android/provider/UserDictionary
-
Gerrit’s Change-Id: I6c5716d4d6ea9d5f55a71b6268d34f4faa3ac043
https://android.googlesource.com/platform/packages/providers/… -
На момент раскрытия уязвимости изменения были в главной ветке AOSP:
https://android.googlesource.com/platform/packages/providers/UserDictionaryProvider/…
После исправления то же самое содержимое можно найти в следующем коммите:
https://android.googlesource.com/platform/packages/providers/UserDictionaryProvider/…