
Многопоточные криптографические алгоритмы
Статья посвящена многопоточному выполнению криптопреобразований с точки зрения использования параллелизма в алгоритмических конструкциях шифров.
Все криптопреобразования используемые в данной статье не более чем демонстрация возможных подходов к построению параллельных криптографических алгоритмов.
Если в результате этого получилось что-то стоящее внимания криптографа, то это исключительно случайно…
Автор: R_T_T
Статья посвящена многопоточному выполнению криптопреобразований с точки зрения использования параллелизма в алгоритмических конструкциях шифров.
Все криптопреобразования используемые в данной статье не более чем демонстрация возможных подходов к построению параллельных криптографических алгоритмов.
Если в результате этого получилось что-то стоящее внимания криптографа, то это исключительно случайно…
Публичная информация о квантовых методах криптоанализа
Уже давно не секрет, что разработаны алгоритмы криптоанализа симметричного, и ассиметричного шифрования специально для квантовых компьютеров. Алгоритмы были, не было компьютеров, теперь они появились.
http://www.securitylab.ru/news/448779.php
Независимые (академические) криптоаналитики должны иметь свой инструмент для публичных исследований, и он уже тоже появился. http://www.pcweek.ru/idea/article/detail.php?ID=185415
До недавнего времени считалось, что симметричное шифрование плохо поддается методам квантового криптоанализа, но вот новость касающаяся взлома блочных шифров новым (хорошо забытым старым) методом. http://www.securitylab.ru/news/301779.php?pagen=3&el_id=301779
На первый взгляд не понятно о чем идет речь, попробую объяснять «на пальцах»…
Во первых, это возвращение к древнему аналоговому решателю.
Были такие раньше вычислительные установки, тогда они были «электрическими», а вот теперь стали «квантовыми». Но суть от этого не меняется.
Во вторых, в описываемой установке используется новая техника квантового криптоанализа требующая пояснения.
Возьмем простейший случай генерации гаммы, вырабатываемой к примеру, на основе алгоритма ГОСТ 28147-89. Оцифруем получившуюся последовательность гаммы как волну, с помощью преобразования Фурье, разложив на гармонические составляющие.
В результате получим классическую и очень стабильную картину псевдослучайного «розового» шума, там будет стабильный и ограниченный набор частот модулированных по амплитуде и фазе.
Теперь наложим на гамму шифруемый текст, у нас получится зашифрованный текст, его тоже можно представить в виде оцифрованной волновой функции. Фактически шифрование, это процесс тождественный радиопередаче, когда модулируется высокочастотное излучение низкочастотным сигналом. Гамма это высокочастотный сигнал, а шифруемый текст, это низкочастотный модулятор.
Взлом с помощью квантовой криптографии по сути тождественен работе детекторного приемника, отсекается исходная волновая функция и выделяется низкочастотная модулирующая составляющая.
Если шифруемый текст полностью лишен внутренних закономерностей (в простейшем случае содержит случайные числа) то мы получим уже не «розовый», а классический «белый» шум. Такой шифротекст квантовой криптографии сложно расколоть, нужно иметь для криптоанализа исходный и зашифрованный текст, тогда вычислить ключи реально.
Но обычно шифруются тексты с внутренними взаимосвязями (повторами в простейшем случае), там где есть повторяемость (даже не явная), картина изменится, в спектре появятся специфические низкочастотные составляющие (пучности).
В этом случае, даже исходный текст взломщикам становится не нужен.
Вывод из выше изложенного очевиден, кроме алгоритмической сложности алгоритм шифрования должен еще и обеспечивать статистические параметры шифротекста максимально приближенные к случайному распределению.
Как с этим бороться?
АНБ ввела в публичный обиход понятие «ПостКвантовая криптография», воспользуемся им и мы. Появление этого термина символично и означает, что старые методы шифрования уже не пригодны.
Для начала АНБ предлагает увеличивать длину ключа, это не решение проблемы, но существенное затруднение процесса взлома. В последующем вообще предлагается переходить на более стойкие алгоритмы.
Вектор направления в разработках новых блочных шифров очевиден, это приближение шифрованного текста к параметрам случайной последовательности, зашифрованный текст должен быть максимально статистически схож с данными получаемыми на генераторах случайных чисел.
В России на данный момент официально существует два блочных шифра, новый «Кузнечик» не пригоден для скоростного шифрования, его удел специальные ускорители типа встроенного в Интел спец/вычислителя AES шифра.
Старый ГОСТ 28147-89 (Магма) идеально ложится на систему команд х86-84 в части параллельных вычислений (AVX расширения). Взяв новое имя, он, к сожалению не прошел «рестайлинга», который ему уже давно необходим.
Поэтому, фантазировать и изобретать новые стойкие алгоритмы, не будем. Вместо этого займемся поиском «красоты» в параллельной реализации ГОСТ 28147-89, а красота страшная сила, она побеждает все, в том числе и квантовые методы взлома…
Что сделать конкретно?
Во первых, нужно статистические параметры «Магмы» максимально приблизить к характеристикам случайной последовательности (белому шуму). Это сделается «честным» подбором блоков замен.
Во вторых, «Магма» нуждается в увеличение разрядности ключей и блоков данных. Нужно уходить от схемы четырех повторов 8 ключей и переходить к схеме без повторов. При этом нужно увеличивать размерность блоков данных.
В третьих, с учетом специфики квантовых методов взлома, простого увеличения длины ключа и размерности блоков мало, нужен глубокий «тюнинг».
Перечислю главное:
- Шифруемый текст предварительно пропускать через процедуру удаления избыточности, проще говоря, компрессировать с максимальной тщательностью.
- Не использовать алгоритмы обладающие обратимостью, соответственно работать в режиме гаммирования, либо, что еще лучше в режиме прямой замены+гаммирование.
- Ввести в алгоритм операции по «запутыванию» состояния.
- Ввести операции по формированию «неопределенности» состояния накопителей.
- Не использовать линейных «зацеплений» между смежными блоками, т.е. отказаться от линейных преобразований при формировании первоначальных заполнений.
Техника параллельных раундов
С моей легкой руки сейчас все перешли на параллельную реализацию ГОСТ 28147-89, пока параллелизм используется только для увеличения скорости, за счет одновременного расчета до 16 блоков. Раньше аппаратура позволяла эффективно вести расчеты только на 8 блоках (на ХММ регистрах), сейчас можно уже использовать регистры удвоенной длины (YMM регистры).
Единственно возможным (с точки зрения оптимизации) размещением накопителей N1 и N2 по регистрам длинной 256 бит является такая схема, для счета в 16 потоков:
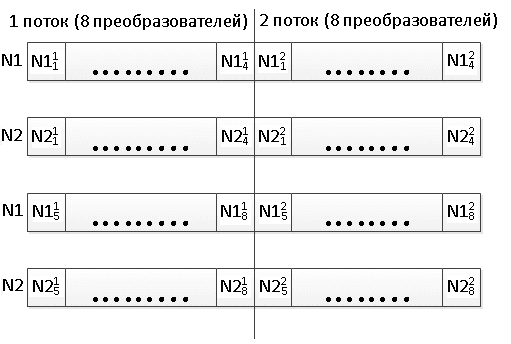
Как видно, эта схема предполагает раздельное хранение накопителей N1 и N2 (так было и раньше, на регистрах длиной 128бит
Использование YMM регистров делает старшие и младшие половинки регистров независимыми для блоков подстановок. Это позволяет создать два независимых потока расчетов на различных блоках замен и различных ключах. Раньше так делать было нельзя.
Возможности параллельного счета увеличением скорости не ограничиваются, перечислю основное, что можно использовать в чисто алгоритмических целях:
- Во первых, пока параллельный счет идет на одних и тех же ключах и блоках замен, но это не обязательное ограничение, можно шифровать на уникальных ключах и блоках замен для каждого блока.
- Во вторых, у нас появляется за один раунд одновременно 16 независимых результатов, это эквивалентно проведению 16 раундов над одним блоком.
- В третьих, алгоритм ГОСТ 28147-89 не использует в преобразовании накопитель N2, его можно тоже модифицировать, но не проводя над ним математические преобразования, а «запутывая» его состояние в зависимости от состояния смежных параллельно работающих преобразований.
Теперь попытаемся эти новые возможности предоставляемые параллельным шифрованием 16 блоков на 16 независимых преобразователях реализовать в модифицированном алгоритме ГОСТ 28147-89.
Первоначальные заполнения
Наиболее предпочтительным среди режимов шифрования является режим гаммирования. С точки зрения параллельного счета он крайне неудобно реализован в стандартах (новом и старом), поэтому начнем с него.
Из 16 параллельно работающих преобразователей сформируем две абсолютно независимых группы (потока) по 8 преобразователей. Независимость достигается использованием в них различных ключей и блоков подстановки.
Соответственно у нас появляется два различных блока замен по 64 байта и шестнадцать четырехбайтных ключей.
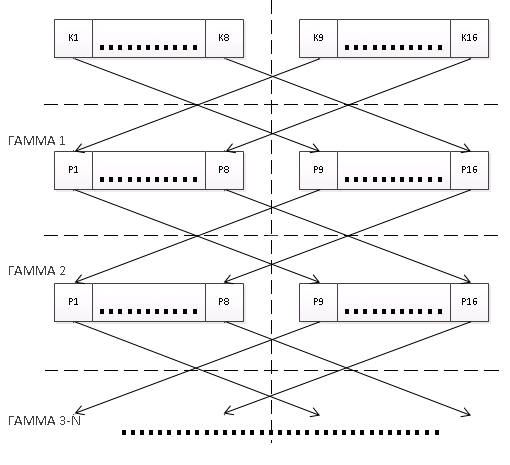
На основе этих групп будем формировать независимые первоначальные заполнения перекрестным методом, когда выходное состояние одной группы становится входным состоянием для другой группы в следующем цикле формирования гаммы.
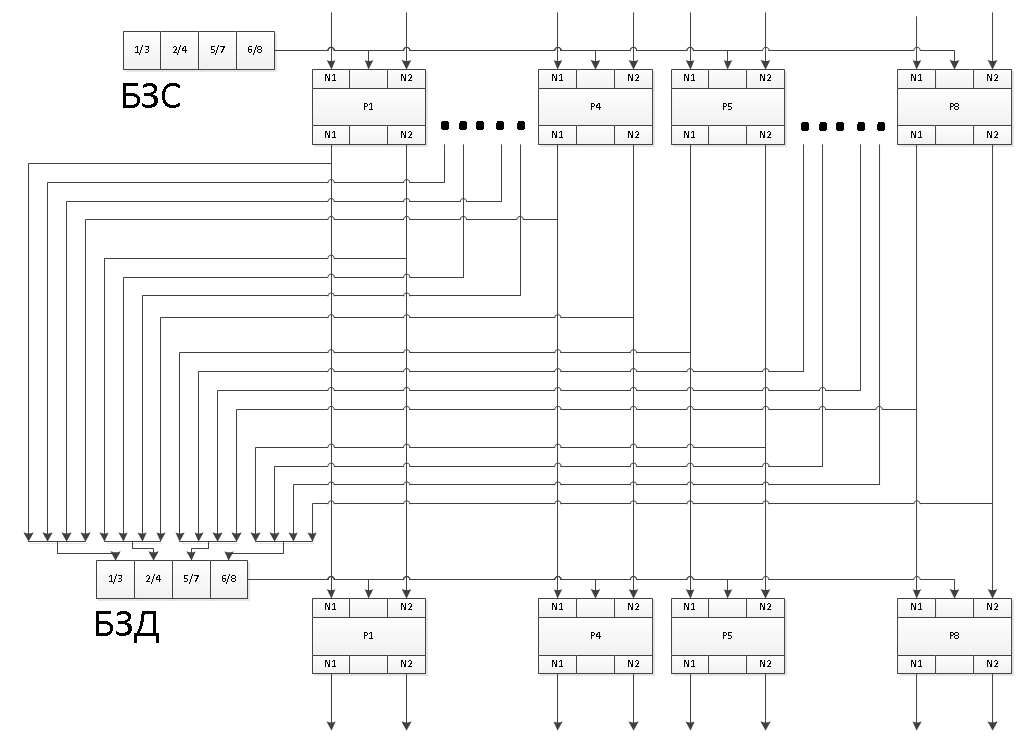
Самое первое заполнение для групп преобразователей, чтобы не плодить новых «сущностей», будем формировать из значений 8 ключей шифрования разных групп, отказавшись от концепции «синхропосылки». Будем их просто подставлять, каждому из 8 преобразователей по ключу из другой группы. Так чтобы номер (n=1…8) преобразователя соответствовал ключу с номером 9-n. Этими значениями заполнятся накопители N1, в каждом из 16 преобразователей.
Второй накопитель N2 можно заполнять номером блока гаммы, соответственно он будет для всех преобразователей связан линейной функцией. Номер блока гаммы необходим для того, чтобы на одних и тех же ключах получать разные гаммы, что важно для каналов передачи данных и шифрования дисков.
В этой схеме блоков данных может быть не более 232, но размерность самого блока не ограничена, так что размерность гаммы без повторов тоже не ограничена.
Вот как это выглядит на блок схеме:
Защита от дифференциального криптоанализа
С целью защиты от дифференциальных методов криптоанализа «запутаем» гамму. Для этого, перед тем как состояние накопителей выводить в гамму, выполним операции «перетасовки» байт накопителей. Чтобы результат такой перетасовки не был известен заранее, будем ее выполнять в зависимости от значений соответствующих байт в накопителях. Проще всего выполнить операции сборки минимальных и максимальных значений соответствующих байт в первом и втором потоке.
Вот как это выглядит на блок схеме:
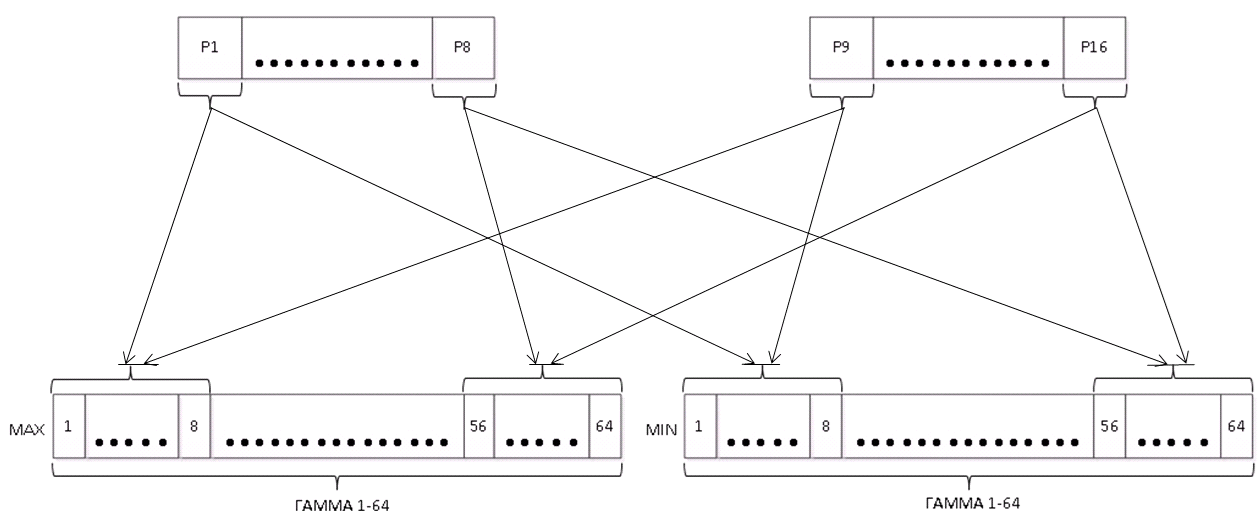
Вроде громоздко на схемах, но в коде все просто, вот как формируются начальные заполнения и запутывается гамма коде:
;/////////////первоначальные заполнения и запись результата в буфер гаммы
vperm2i128 ymm6,ymm6,ymm6,001h; обменять верхние и нижние блоки N1
vperm2i128 ymm7,ymm7,ymm7,001h; обменять верхние и нижние блоки N2
vpminsb ymm8,ymm6,ymm7; собрать минимальные значения
vpmaxsb ymm9,ymm6,ymm7; собрать максимальные значения
vmovupd [rsp+040h],ymm8; в гамму
vmovupd [rsp+060h],ymm9; в гамму
В этом коде сначала меняются местами значения в группах накопителей из верхней и нижней части 256битных регистров. Затем выполняется запутывание на командах выделения минимальных и максимальных байт в эквивалентных позициях гаммы обоих потоков. В конце получившиеся значения записываются в буфер гаммы.
Схему формирования первоначального заполнения и выдачи данных в гамму можно конечно усложнять и модифицировать. Данная схема описана исключительно для демонстрации самого принципа использования параллельности в криптоалгоритме.
Ключевая схема.
Можно усложнить ключевую схему в рамках уже существующей архитектуры преобразования. Сейчас в каждом раунде подаются на преобразователи (их 8 штук в каждом из двух потоков) одинаковые ключи.
Для усложнения можно:
- В каждом потоке иметь собственный набор из 8ключей.
- Подавать в преобразователи ключи в соответствии с номером преобразователя и перебирать их затем циклически.
Вот как это выглядит на схеме:
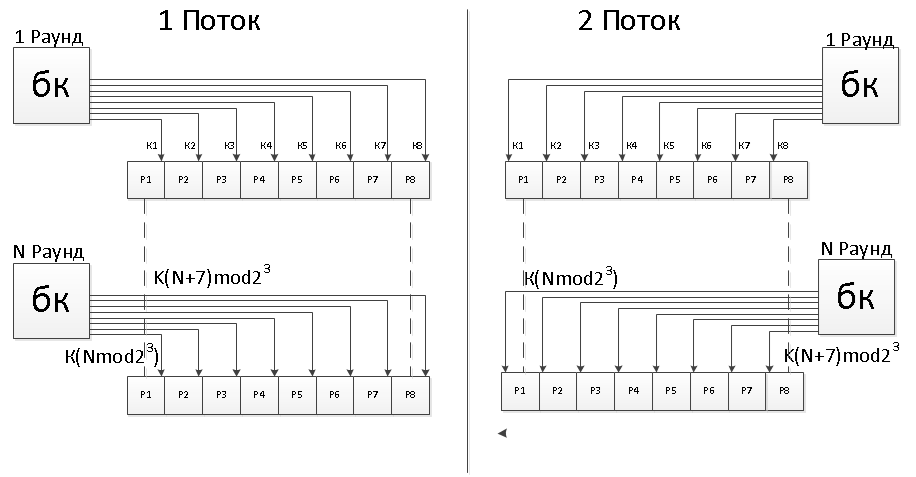
Эта схема превращает каждый из 16 преобразователей в полностью автономный функциональный блок, выдающий свой уникальный результат даже на одинаковых первоначальных заполнениях и одинаковых ключах.
Для этой операции никаких новых процессорных команд при реализации вводить не надо, просто переупорядочиваются структуры блоков ключей в оперативной памяти.
Введение операции «неопределенности» состояния накопителей
И так, для усиления схемы формирования первоначальных заполнений, из 16 параллельно работающих преобразователей сделаны два независимых потока по 8 параллельно работающих преобразователей.
Далее будем рассматривать работу только одной из этих групп по 8 преобразователей, имея ввиду, что обе группы работают одинаково, только используют разные ключи, блоки замен и первоначальные заполнения.
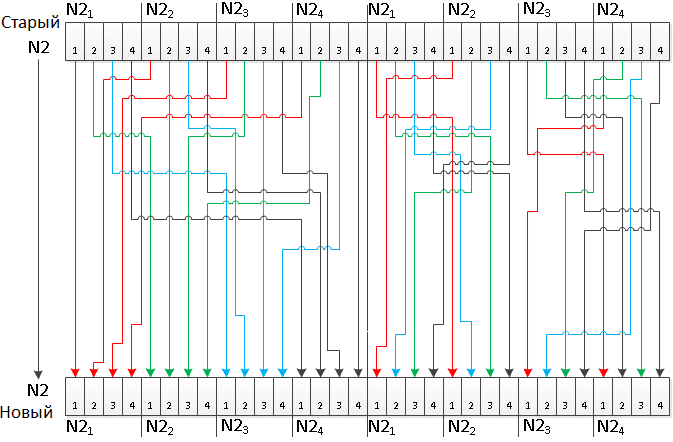
У нас в результате одного раунда в группе из 8 преобразователей вычисляются сразу 8 новых значений накопителей N1 и N2, их можно «перетасовать». Придумывать новых операций не будем, есть проверенная подстановка в блоках замен, ее и используем.
Сделаем часть подстановок не статическими, а динамическими. Другими словами, сами накопители N1 и N2 станут динамическими блоками замен. Блоки накопителей N1 и N2 при параллельном счете занимают четыре регистра по 128 бит. Именно столько же регистров используется для блоков замен в основном цикле.
Для реализации динамических блоков замен нужно подставить в преобразование вместо регистров со статическими блоками замен, регистры хранения значений накопителей N1, N2 предыдущего раунда. Будем эту операцию делать через раз, в одном раунде будем использовать штатные статические блоки замен, а в следующем будем использовать динамические блоки замен.
Таким образом у нас появляется операция которая подставляет в тетрады восьми накопителей N1 абсолютно непредсказуеме значения, эта операция необратима, таким преобразованием можно только гаммировать и вычислять Хеш функцию.
Если оставаться в рамках обратимости алгоритма, то в динамических заменах нужно использовать только накопители N2.
Эффект синергетики
Реализация динамических блоков замен кроме удовлетворения требованиям постквантовой криптографии имеет еще одно положительное свойство. Она интегрирует методом нелинейной замены 8 циклов шифрования на разных ключах.
Это эквивалентно тому, что за один раунд выполняется сразу девять независимых раундов преобразований…
Для выполнения условия эквивалентности, нужно в каждом преобразователе использовать разные ключи, у нас их 8, столько же преобразователей. Следовательно, преобразователи должны выполнять тождественные раунды на разных ключах и перебирать их последовательно.
Это требует применения ключевой схемы, о которой уже говорилось выше.
Выполнение одного раунда, на динамических блоках подстановок эквивалентно, 9 раундам исходного преобразования, поэтому можно уменьшить количество раундов в операции гаммирования. Мелочиться не будем, уменьшим их в четыре раза, до 8, это будет в эквивалентной схеме равно 40 раундам последовательного счета исходного варианта.
В результате, повышая криптостойкость мы еще в четыре раза увеличиваем скорость преобразования, на мой взгляд это и есть «красивое» решение.
Использование накопителей N2 для «запутывания» состояния статическим методом
Но даже это не предел, сделаем не просто «красиво», а «очень красиво»…
У нас простаивают во время преобразований замены и сдвига накопители N2, и есть незадействованные исполнительные устройства в составе процессора. Этот потенциальный ресурс тоже можно использовать.
Введем еще одну нелинейную операцию преобразования накопителей N2, и будем ее выполнять на фоне преобразования накопителей N1, это не приведет к увеличению времени выполнения.
Простейшим преобразованием, может быть(в качестве примера), такая статическая перестановка:
Здесь «пересобираются» байты накопителей N2 двух независимых потоков в соответствии со статической схемой перестановки. В каждом из потоков собственная схема сборки. Для этой операции требуется всего одна процессорная команда.
В первом потоке собираются байты в соответствии с номерами накопителей.
Во втором потоке смежные накопители обмениваются соответствующими байтами.
Статические замены можно использовать в обратимых алгоритмах, но в более сложном (динамическом) варианте, обратимость теряется.
Использование накопителей N2 для «запутывания» состояния динамическим методом
Усложним операцию, будем выполнять динамические перестановки, с двумя отличиями от статического преобразования:
- Использовать в качестве индекса перестановки будем тетрады из каждого байта накопителей N2.
- Индексы каждого из накопителей N2 используются для перестановок байт в другом накопителе.
Эту операцию будем проводить во время раунда со статическими блоками замен, которые описаны ранее, чтобы не дублировать динамические подстановки в накопителях N1.
Вот как реализация этого преобразования выглядит на командах процессора:
;//////////модификация накопителей N2
vpand ymm5,ymm1,[rbx+40h]; сбросить старшие тетрады в байтах
vpand ymm8,ymm7,[rbx+40h]; сбросить старшие тетрады в байтах
vpshufb ymm7,ymm7,ymm5; перемешать байты 1блока накопителей
vpshufb ymm1,ymm1,ymm8; перемешать байты 2блока накопителей
В эквивалентной схеме введение такой операции соответствует 6 раундам исходного преобразования. Соответственно на 8 раундов в эквивалентной схеме получается 24 раундов исходного преобразования. Суммарно оба метода дают 36+24=60 раундов, это более чем достаточно для стойкости против традиционных методов криптоанализа, и достаточно для требований криптостойкости постквантовой криптографии, при этом скорость гаммирования на стенде получается 3.8Гбайт/сек для одного процессорного ядра частотой 4гГерца.
Куда больше?
Инжекция случайных байт
Больше не надо, лучше меньше, но лучше.
Сделаем так, чтобы недостаток динамических блоков подстановок (их статистическая слабость) компенсировалась инжекцией случайных байт. Это кстати частично устранит «ахиллесову пяту» Магмы, - тетрадные подстановки.
Суть операции проста, перед операцией подстановки запомним значение накопителей N1, а после подстановки и сдвига сравним полученное значение с сохраненным.
Если какие то байты совпали (из-за слабости текущей подстановки) то заменим этот байт на взятый из рандомного байтового блока случайным образом.
Рандомным блоком будет специальный стандартизированный блок размером в 256 байт, подготовленный заранее.
Случайность выборки из него организуем через смещение, величина которого зависит от предыдущего накопленного числа совпадений.
Вот как это реализуется в коде:
;/////////удаление повторов
vpcmpeqb ymm3,ymm3,ymm7; сравнить запомненное и текущее состояние
vpblendvb ymm7,ymm7,[rcx+r14],ymm3; заменить совпавшие байты
vpmovmskb r15,ymm3; маска совпадений для 32байт
popcnt r15,r15; число совпадений
add r14,r15; накопить число совпадений
and r14,0ffh; закольцевать адресацию буфера
Данный вариант операции не применим к обратимым алгоритмам, но изменив порядок выборки случайных байт можно сконструировать и обратимый алгоритм.
Понятно что эта операция увеличивает время выполнения (около 15%), но при достигнутых скоростях это уже не существенно. «Цена вопроса», - в среднем получается инжекция одного случайного байта на 128 байт гаммы, на мой взгляд это то, что надо…
В заключении
В автомобилестроение есть понятие «КонцептКар», это нечто такое, что вобрало в себя сумму инновационных решений и используется для их обкатки в тестовом режиме.
Вот и в ПостКвантовой криптографии появился такой «концепт», пока он работает в виде тестового примера, но это только пока…
Еще раз перечислю инновации этого «концепта»:
- Введены динамические блоки замен, состоящие из раундовых значений накопителей N1 и N2.
- Введена схема компенсации слабости блоков динамических замен и инжекции случайных байт.
- Введена нелинейная функция преобразования значений накопителей N2.
- Введена нелинейная функция формирования первоначального заполнения накопителей N1 и N2.
- Введена операция защиты от дифференциальных методов криптоанализа.
В результате, практически не изменив принципов самого алгоритма удалось перейти на увеличенную в два раза размерность ключей (16 четырехбайтных ключа) и увеличенную в шестнадцать раз размерность входных векторов(128 байт вместо 8).
Криптографы и криптоаналитики идеи использования параллелизма в криптопреобразованиях восприняли мягко говоря прохладно…
Причины очевидны.
Но они нам не указ, и концепт ПостКвантового шифратора не останется только на бумаге. В настоящее время разрабатывается полнофункциональная программа с его реализацией (система архивирования).
Так что пища для ума по крайней мере у «практикующих» криптоаналитиков скоро появится в принудительном порядке…