Обнаружение Bluetooth UAP
Во время одного из интервью меня спросили, как, используя Ubertooth, определяется верхняя часть адреса в Bluetooth (UAP, Upper Address Part). Через несколько минут после окончания разговора я понял, что допустил ошибку: вместо того, чтобы упоминать о разбавлении шифротекста белым шумом (whitening), следовало бы сказать о HEC и CRC.
Автор: Майкл Осман (Michael Ossmann)
Во время одного из интервью меня спросили, как, используя Ubertooth, определяется верхняя часть адреса в Bluetooth (UAP, Upper Address Part). Через несколько минут после окончания разговора я понял, что допустил ошибку: вместо того, чтобы упоминать о разбавлении шифротекста белым шумом (whitening), следовало бы сказать о HEC и CRC. Понимая тот факт, что глубокие знания нашего метода имеются лишь у единиц, было решено рассказать о нем более подробно. Для начала следует отметить, что описываемый способ весьма непрост, и вряд ли мы где-либо опишем его во всех подробностях, кроме как в исходном коде библиотеки libbtbb.
В данной статье будет рассматриваться классический протокол Bluetooth, а не Bluetooth Low Energy (LE или Bluetooth Smart). В целом, в случае с LE, все будет намного проще, и не потребуется столь громоздких объяснений.
Верхняя часть адреса (Upper Address Part, UAP) представляет собой 8-ми битную секцию, принадлежащую Bluetooth Device Address (BD_ADDR). Для того чтобы полностью декодировать пакеты, определить последовательность псевдослучайной перестройки частоты (hopping sequence) и вообще сделать хоть что-то интересное с Bluetooth, нам необходима верхняя (UAP) и нижняя (LAP) части адресов главного устройства пикосети.
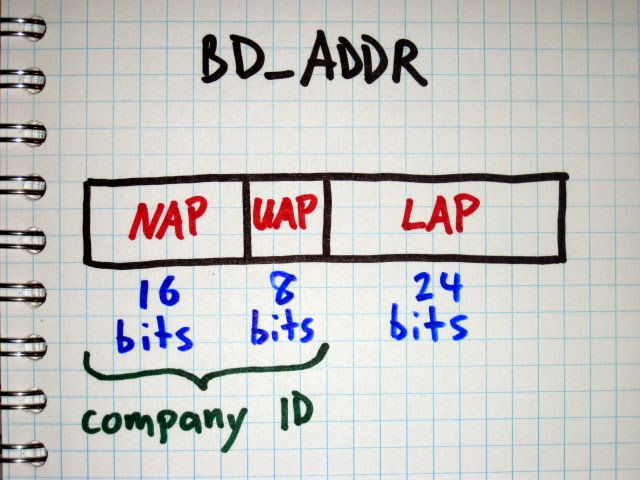
Рисунок 1: Структура адреса
Нижнюю часть адреса главного устройства легко определяется, например, при помощи утилиты Ubertooth и ей подобных, которые могут демодулировать пакеты Bluetooth. Нижняя часть адреса входит в состав синхрослова (sync word), находящегося в составе каждого пакета и передающегося в чистом виде. Следовательно, чтобы обнаружить LAP, необходимо перехватить и демодулировать хотя бы один пакет.
Верхнюю часть адреса (UAP) обнаружить сложнее. Для решения этой задачи есть несколько методов. Самый простой – перебор в лоб, описанный Джошуа Райт (Joshua Wright) в книге Hacking Exposed Wireless, Second Edition. Суть метода заключается в непрерывном подключении к целевому BD_ADDR каждый раз с разным UAP. Поскольку несущественная часть адреса (Non-significant Address Part, NAP) при первоначальном подключении может быть любой, и нам только нужны корректные значения LAP и UAP. Размер UAP равен 8 битам, а полный набор вариантов содержит 256 различных значений (то есть после 256 подключений UAP гарантированно будет подобран). Сократить количество подключений можно путем использования наиболее распространенных значений, поскольку UAP является частью Organizationally Unique Identifier (UOI), который в свою очередь привязан к производителю (а большую часть Bluetooth-устройств делает всего несколько производителей). Самые распространенные UOI можно узнать на сайте проекта BNAP BNAP.
Однако у прямого перебора есть несколько недостатков. Во-первых, метод является активным, а следовательно может повлиять на целевые устройства и попасть в поле зрения системы мониторинга. Во-вторых, метод работает только в том случае, когда устройство находится в состоянии подключения. Многие устройства не переходят в этой состояние, когда у них уже есть активное подключение. Кроме того, многие устройства находятся в состоянии подключения кратковременно (например, одну секунду через каждые пять секунд), что значительно замедляет процесс прямого перебора.
Цель проекта Ubertooth – пассивный мониторинг Bluetooth-систем, и мы реализовали метод обнаружения UAP без необходимости активного подключения.
Изначально у нас есть пространство для поиска, состоящее из 256 кандидатов. Вместо прямого поиска, мы изобрели серию техник для уменьшения поискового пространства путем исключения неподходящих вариантов до тех пор, пока не останется один нужный нам UAP.
Первая техника рассчитывает UAP путем реверсии поля контроля ошибок (Header Error Check, HEC), находящегося в конце заголовка каждого пакета (у которого есть заголовок). HEC – 8-битное значение рассчитанное на основе UAP и других байтов заголовка. Приемник использует HEC для подтверждения корректности получения заголовка пакета. Мы делаем допущение, что пакет получен без каких-либо ошибок (что верно в подавляющем количестве случаев). После декодирования HEC и байтов заголовка становится возможным найти недостающий элемент – UAP. Это не так сложно, поскольку алгоритм формирования HEC – двусторонний. Мы можем использовать этот алгоритм в одну сторону для расчета HEC на основе UAP и байтов заголовка и в обратную сторону для нахождения UAP и байтов заголовка на основе HEC.
Помимо идентификатора типа пакета, который обычно передается во время запросов на поиск устройства и соединения, каждый Bluetooth-пакет содержит заголовок с HEC, что позволяет нам выполнить эту технику для загруженной пикосети даже когда мы мониторим только 1 из 79 каналов.
Казалось бы, мы на коне и все в ажуре, но есть одна серьезная проблема: шифротекст разбавляется белым шумом. Все дело в том, что каждый пакет перед отправкой рандомизируется псевдослучайной последовательностью, и прежде, чем применять вышеупомянутую технику, мы должны очистить заголовок пакета.
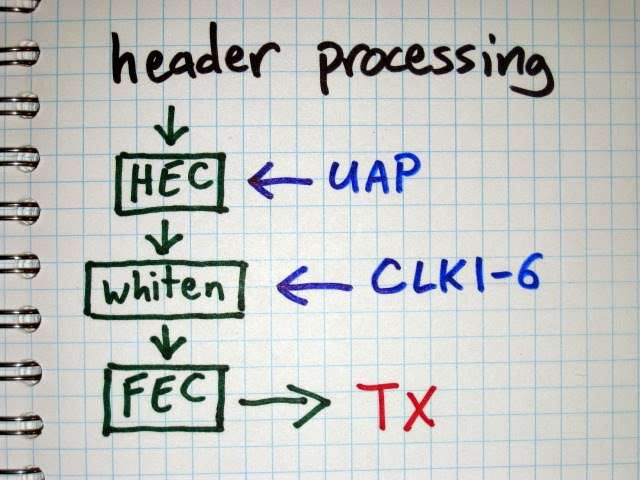
Рисунок 2: Перед отправкой пакет разбавляется псевдослучайной последовательностью
Существует 64 возможных вариантов псевдослучайных последовательностей. В процессе «разбавления» пакета определенная последовательность выбирается таймером (CLK1-6), который, к тому же, используется для синхронизации перестройки частоты.
Мы получаем пакет и пытаемся использовать одно из 64 возможных значений CLK1-6. Для каждого такого значения мы рассчитываем псевдослучайную последовательность, затем очищаем пакет и определяем UAP при помощи обратного HEC-алгоритма. На выходе у нас получается 64 возможных значения UAP, и, следовательно, множество кандидатов уменьшается с 8 до 6 бит. Поскольку мы можем вычислить UAP для конкретного CLK1-6, то каждый раз пытаемся определить значение CLK1-6.
Существует один простой способ определить значение CLK1-6. Если пакет содержит «полезную нагрузку», включающую в себя CRC (Cyclic Redundancy Check), мы можем использовать CRC для того, чтобы удостовериться в корректной очистке пакета. Если один из 64 возможных значений CLK1-6 совпадает с CRC, тогда задача решена.
Данный метод был описан в статье BlueSniff: Eve meets Alice and Bluetooth.
Главная проблема способа, связанного с CRC, заключается в том, что не все пакеты содержат CRC (согласно спецификации Bluetooth Core Specification), и в реальной жизни таких пакетов передается мало. Если вы попробуете отловить подобный пакет при помощи Ubertooth, то убедитесь в том, что, даже из тысячи пакетов в пикосети, нужного может не оказаться. Таким образом, нам нужен какой-то другой метод для определения корректности (или некорректности) значения CLK1-6.
Следующий метод для валидации CLK1-6 связан с проверками формата пакета. Очищенный заголовок содержит 4-х битовое поле типа пакета. Если, к примеру, код типа пакета равен 5, то это пакет HV1. У HV1-пакетов нет CRC, но есть полезная нагрузка, закодированная на 1/3 при помощи алгоритма Forward Error Correction, который реализуется путем повторения каждого бита три раза подряд. Поскольку различные типы пакетов кодируются при помощи разных FEC-методов, мы можем выполнить проверку, подтверждающую, что каждый бит повторяется три раза для предполагаемой длины пакета (с некоторым допущением на битовые ошибки). Если проверка заканчивается неудачно, значит, у нас неправильное значение CLK1-6.

Рисунок 3: Алгоритм вычисления UAP
Более подробно об этом рассказывается в заметке Building an All-Channel Bluetooth Monitor.
К сожалению, у обоих вышеупомянутых методов есть один большой недостаток: случаи, когда их можно применить, возникают достаточно редко.
Основная причина, по которой в большинстве случаев мы не можем определить вероятное значение CLK1-6, заключается в том, что в Bluetooth более 16 типов пакетов, и, следовательно, 4-х битное поле, где хранится тип, оказывается перегруженным. Рассмотрим пример.
Допустим, при декодировании поля типа пакета получено число 10. Это может означать следующее.
- Тип пакета DM3. Объем передаваемых данных от 2 до 123 байт плюс CRC.
- Тип пакета 2-DH3. Используется усовершенствованная передача данных (Enhanced Data Rate, EDR) с модулированной полезной нагрузкой, которую невозможно демодулировать при помощи Ubertooth (мы можем демодулировать только заголовок пакета, но не полезную нагрузку).
Без предварительной информации о состоянии пикосети, мы не знаем, какой из двух типов пакетов используется в данный момент. Вначале мы предполагаем, что тип пакета - DM3, а затем проверяем CRC. Если проверка прошла успешно, задача решена, но, как было сказано выше, пакеты с CRC передаются крайне редко. Скорее всего, проверка CRC завершится неудачно, что означает одно из двух: либо значение CLK1-6 ошибочно, либо тип пакета - 2-DH3. Поскольку мы не можем выяснить точную причину неудачи при проверке, то не можем и исключить значение CLK1-6 из списка кандидатов.
Подводим промежуточный итог. Некоторые проверки завершаются успешно, и вычисляется корректное значение CLK1-6. Некоторые – неуспешно. В этом случае значение CLK1-6 можно исключить. Однако в подавляющем большинстве случаев результат будет неопределенным.
К счастью, в пикосетях передается множество пакетов, и мы можем продолжить процесс исключения заведомо неподходящих значений. При получении первого пакета сразу можно сократить количество кандидатов с 64 до 50-60. С каждым новым полученным пакетом, как правило, можно продолжать исключать неподходящие кандидаты, используя одну хитрость.
Трюк связан временными интервалами между отправкой пакетов. Все дело в том, что пакеты передаются во временные промежутки, которые управляются таймером главного устройства. Мы знаем, как часто увеличивается таймер, и у нас есть предположения относительно 6 младших бит, имеющих отношение к таймеру. При получении следующего пакетам, измеряется время между соседними пакетами и вычисляется количество прошедших временных промежутков. Полученные данные говорят нам о том, насколько увеличится предполагаемое значение из 6 младших бит при получении нового пакета.
Этот метод вполне надежен, если у нас в наличии будет два согласованных между собой таймера по частоте. Кристалл платформы Ubertooth One удовлетворяет всем требованиям спецификации Bluetooth, и она, по сути, ничем не отличается от любого Bluetooth-устройства (со стабильностью по частоте не хуже, чем 20 ppm). Однако мы не знаем, насколько быстрее или медленнее таймер платформы Ubertooth по сравнению с таймером целевого устройства (различие может быть не более чем на 40 ppm). Даже если у нас будет лучший таймер, различия по частоте все равно будут до 20 ppm (предполагается, что платформа Ubertooth полностью соответствует спецификации).
Поскольку существует нестабильность по частоте, мы иногда можем исключать корректное значение CLK1-6 из-за неверного расчета количества временных промежутков между пакетами. Кроме того, из-за битовых ошибок в пакете мы можем неверно исключить кандидата (например, если из-за битовой ошибки проверка CRC прошла неудачно, когда значение типа пакета не перегружает соответствующее поле). Такое иногда происходит, и именно поэтому иногда не получается рассчитать корректный UAP. В этих случаях мы просто начинаем весь процесс заново и повторяем его до тех пор, пока не получим правильный UAP (обычно, на это уходит не слишком много времени).
Можно еще более усовершенствовать алгоритм, если использовать максимально возможное отклонение по частоте при расчете временных промежутков. Например, если мы рассматриваем три интервала вместо одного, то избежим множества ошибочных исключений корректных значений CLK1-6. Кроме того, мы можем получить дополнительные преимущества от скользящей оценки нестабильности частоты главного устройства после того, как обнаружим корректный UAP.
При работе с Ubertooth у людей иногда возникает проблема, связанная с потерей полученного ранее правильного UAP. Такое возникает из-за битовых ошибок или нестабильности частоты таймера. Поскольку при обнаружении UAP мы используем метод типа «все или ничего», подобные неточности могут привести к потере корректного значения. Еще одним усовершенствованием алгоритма, может быть сохранение «доверительного» значения для текущего UAP (или, возможно, для нескольких кандидатов). Если, к примеру, был получен корректный UAP для 1000 пакетов, то при единичных рассогласованиях это значение не следует исключать. Подобное нововведение усложнит и без того непростой алгоритм, но значительно повысит результативность.
В итоге у нас есть эффективный метод определения UAP главного устройства при пассивном мониторинге. Метод довольно сложен, но это лишь малая часть более комплексного алгоритма для определения схемы перестройки частоты пикосети.
Где кванты и ИИ становятся искусством?
На перекрестке науки и фантазии — наш канал