
Flush+Reload: Атака по сторонним каналам на кэш L3
Flush+Reload – атака по сторонним каналам на кэш, когда отслеживается доступ к данным в совместно используемых страницах памяти. В этой статье мы продемонстрируем, как при помощи этой атаки можно извлечь секретные ключи шифрования из GnuPG. Высокая разрешающая способность и низкий процент ошибок при реализации атаки типа Flush+Reload позволяет программе-шпиону извлекать более 98% битов секретного ключа при одиночном дешифровании или подписи.
Факультет Информатики Университета Аделаиды
Аннотация
Flush+Reload – атака по сторонним каналам на кэш, когда отслеживается доступ к данным в совместно используемых страницах памяти. В этой статье мы продемонстрируем, как при помощи этой атаки можно извлечь секретные ключи шифрования из GnuPG. Высокая разрешающая способность и низкий процент ошибок при реализации атаки типа Flush+Reload позволяет программе-шпиону извлекать более 98% битов секретного ключа при одиночном дешифровании или подписи. В отличие от других подобных атак, здесь целью является кэш L3 (самого низкого уровня). Следовательно, программе-шпиону и жертве нет нужды использовать ядро исполнения команд (execution core) совместно с жертвой. Подобную атаку можно осуществлять не только в традиционных операционных системах, но и в виртуальной среде, где атаке могут подвергаться программы, запущенные на различных виртуальных машинах.
1 Введение
Атаки по сторонним каналам направлены на рабочие криптосистемы, а не теоретические уязвимости криптоанализа. Атака по сторонним каналам на кэш – разновидность атак по сторонним каналам, которая основана на временном различии при доступе к кэшированным и некэшированным данным.
Ранее атаки по сторонним каналам на кэш уже использовались при взломе RSA [1, 13], Elgamal [21], DSA [2] и AES [9, 16, 20]. Однако в вышеупомянутых случаях было одно исключение: все эти атаки монополизировали кэш, при этом вытесняя данные жертвы.
Так как большинство операций с памятью происходит в кэше L1 и поскольку монополизация кэша L1 намного проще, чем монополизация более низких уровней [13], то целью всех этих атак был кэш L1 и, соответственно, происходило совместное использование ядра вместе с жертвой.
Гуллаш (Gullasch) с сотоварищами [9] описывает атаку по сторонним каналам на кэш, в которой используются общие страницы памяти у программы-шпиона и жертвы. При этой атаке, именуемой также Flush+Reload, удаляются определенные участки памяти без монополизации самого кэша. Во время атаки Flush+Reload удаляются выбранные участки памяти из всех уровней кэша, включая кэш L3. Такой подход, который был использован Гуллашем с сотоварищами, позволяет осуществлять атаку среди процессов, запущенных на разных ядрах одного и того же процессора. Более того, поскольку гипервизоры, очевидно, разделяют страницы памяти между виртуальными машинами [5, 19], подобная атака применима внутри изоляционного уровня, разделяющего виртуальные машины.
В этой статье мы расскажем об атаке Flush+Reload и продемонстрируем ее применение против реализации RSA в GnuPG [7]. Мы будем исследовать GnuPG при разрешении в 1.5 МГц. Такое высокое разрешение в сочетании с низким процентом ошибок атаки позволяет нам доставать более 98% битов секретного ключа во время перехвата операции одиночного дешифрования или подписи.
В разделах 2 и 3 рассказывается об архитектуре кэша и алгоритме RSA. О самой атаке Flush+Reload будет рассказано в разделе 4, а ее применении в отношении GnuPG в разделе 5.
2 Архитектура кэша и атаки по сторонним каналам
Кэши процессора восполняют разницу между скоростью обработки в современных процессорах и скоростью извлечения данных из памяти. Кэш представляет собой небольшой объем быстрой памяти, где процессор хранит значения ячеек памяти, к которым недавно осуществлялся доступ. Благодаря локальности ссылок недавно используемые значения часто используются снова. Получение этих значений из кэша экономит время и уменьшает нагрузку на основную память.
В современных микропроцессорах используется многоуровневый кэш. К примеру, структура кэша процессора Core i5-3470, показанная на Рисунке 1, состоит из трех уровней: L1, L2 и L3.
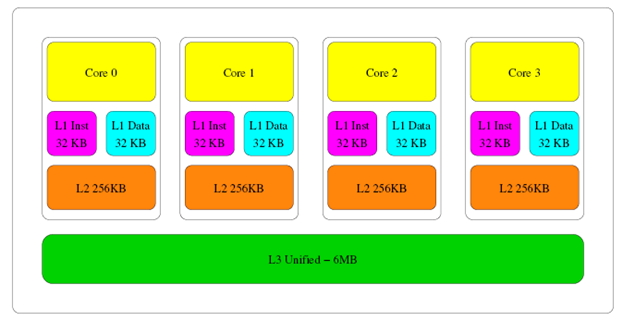
Рисунок 1: Архитектура кэша Intel Ivy Bridge
У процессора Core i5-3470 четыре блока обработки, называемых ядрами. У каждого ядра имеется кэш L1 размером 64Кб, который состоит из кэша данных и кэша инструкций (размер каждого 32Кб). Также у ядра есть кэш L2 размером 256Кб. Все ядра совместно используют кэш L3 размером 6МБ.
Единица памяти внутри кэша представляет собой участок, состоящий из фиксированного числа байтов. Кэш состоит из множества наборов, каждый из которых хранит фиксированное количество участков. Количество участков в наборе называется ассоциативностью кэша. Каждая очередь памяти может быть закэширована в любой участок кэша одиночного набора. В процессоре Core i5-3470 размер каждого участка кэша составляет 64 байта. Кэши L1 и L2 – 8-канальные ассоциативные, а кэш L3 – 12-канальный ассоциативный.
Получение данных из памяти и кэшей низких уровней занимает больше времени, чем получение данных из кэшей более высоких уровней. Как раз это временное различие и используется при осуществлении атак по сторонним каналам. Тромер (Tromer) с сотоварищами [16] описывает два вида атак по сторонним каналам: атаку Evict+Time и атаку Prime+Probe.
Во время атаки Evict+Time кэш устанавливается в известное состояние, обычно путем выполнения цикла вычислений, выделения выбранных наборов из кэша и замера времени, необходимого для выполнения цикла вычислений. Время, которое требуется на выполнение вычисления, зависит от значений, находящихся в кэше на момент начала вычисления. Следовательно, время выполнения вычисления позволяет выявить участки памяти, которые были использованы во время выполнения операции.
Во время атаки Prime+Probe кэш заполняется известными участками памяти. Затем через некоторое время эти участки памяти проверяются на предмет того, какие из этих участков были удалены из кэша, если вообще были удалены. Повторимся еще раз, информация о том, к каким наборам осуществлялся доступ, позволяет выявить участки памяти, использованные во время вычисления и, соответственно, данные, которые подверглись обработки.
Вышеупомянутые техники больше применимы для реализации атак по сторонним каналам на кэш L1, а не на кэши более низких уровней. Одна из причин: кэширование базируется на адресах физической памяти, в то время как процессы используют виртуальные адреса. В случае с кэшами L1 смещение байтов в странице всегда увязывается (map) с тем же самым набором кэша. Следовательно, для выделения набора или заполнения кэша злоумышленнику необходимо лишь число страниц, соответствующее ассоциативности кэша, и для этого подойдут любые страницы.
В случае с более объемными кэшами виртуальная память маскирует мапирование между страницами памяти и наборами кэша. Более того, такое мапирование не всегда стабильно и может меняться во время выполнения программы. Обзор техник по восстановлению мапирования представлен в соответствующей статье [10]. Однако эти техники реализуют мапирование только для памяти, используемой злоумышленником, в то время как схема мапирования на стороне жертвы все еще остается неизвестной.
Второе ограничение для осуществления вышеупомянутых атак – размер кэша L3. Размер кэша существенно влияет на схему реализации атаки Prime+Probe, увеличивая время заполнения и проверок кэша и уменьшая потенциальную разрешающую способность атаки. Для атак Evict+Time увеличивается пространство для поиска, что делает их более сложными.
Из-за ограничений на использование только кэша L1 вышеупомянутые техники работают только в том случае, когда злоумышленник и жертва используют одно и то же процессорное ядро.
Гуллаш с сотоварищами [9] описывает атаку по сторонним каналам на кэш, которую мы называем Flush+Reload. Схема реализации этой атаки похожа на Prime+Probe в том смысле, что происходит мониторинг кэша во время выполнения вычислений. Однако в отличие от Prime+Probe, атака Flush+Reload удаляет участки памяти из кэша и измеряет время перезагрузки этих участков для выявления их использования во время выполнения вычисления.
Более подробно об атаке Flush+Reload мы поговорим в Разделе 4.
3 RSA
RSA [14] – криптографическая система, использующая публичный ключ, которая поддерживает шифрование и подпись. Создание системы шифрования происходит так:
- Случайно выбираются два случайных простых числа p и q и вычисляется их произведение n = pq.
- Выбирается публичный порядок e. GnuPG использует e = 65537.
- Вычисляется секретный порядок числа
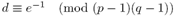 .
. - Сгенерированная шифровальная система включает в себя:
- Публичный ключ – пара значений (n, e).
- Секретный ключ – три значения (p, q, d).
- Функция шифрования -
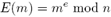 .
. - Функция дешифрования -
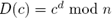 .
.
При реализации функции дешифрования часто используется следующая оптимизация:
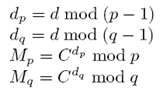
Затем на основе ![]() и
и ![]() вычисляется М при помощи формулы Гарнера [6]:
вычисляется М при помощи формулы Гарнера [6]:
![]()
Для вычисления функций шифрования и дешифрования GnuPG использует алгоритм возведения в произвольную степень путем многократного возведения в квадрат и умножения [8]. Вычисляется переменная ![]() путем обследования битов бинарного представления степени e. Учитывая бинарное представление e как
путем обследования битов бинарного представления степени e. Учитывая бинарное представление e как ![]() , алгоритм вычисляет последовательность промежуточных значений
, алгоритм вычисляет последовательность промежуточных значений ![]() , где
, где ![]() , при помощи следующей формулы:
, при помощи следующей формулы: ![]() . На Рисунке 2 показан псевдокод реализации алгоритма.
. На Рисунке 2 показан псевдокод реализации алгоритма.

Рисунок 2: алгоритм возведения в произвольную степень путем многократного возведения в квадрат и умножения
Как видно из реализации алгоритма, если злоумышленник отследит операции по этому алгоритму, то сможет вычислить значение степени. Совершенно очевидно, что если степень равна d, то злоумышленник, который вычислил степень, сможет взломать алгоритм шифрования. Хотя GnuPG использует схему оптимизации, описанную выше, и атакующий может лишь получить значения ![]() и
и ![]() . Далее мы покажем, что извлечение любого из значений (
. Далее мы покажем, что извлечение любого из значений (![]() или
или ![]() ) вполне достаточно, чтобы разложить n и, следовательно, взломать алгоритм шифрования.
) вполне достаточно, чтобы разложить n и, следовательно, взломать алгоритм шифрования.
Вначале следует заметить, что n=pq, для каждого X существует целое ![]() так, что:
так, что:
![]()
Следовательно,
![]()
Поскольку ![]() мы применяем малую теорему Ферма к выражению выше и получаем следующее:
мы применяем малую теорему Ферма к выражению выше и получаем следующее:
![]()
Поскольку существует ![]() такое, что
такое, что ![]() , получаем следующее:
, получаем следующее:
![]()
или
![]()
Таким образом, значение p можно вычислить при помощи следующего выражения:
![]()
В следующем разделе мы подробнее рассмотрим атаку Flush+Reload, при помощи которой можно извлечь степень, используемую GnuPG.
4 Атака Flush+Reload
Атака Flush+Reload является вариантом атаки Prime+Probe, которая основывается на использовании общих страниц между программами злоумышленника и жертвы. При помощи общих страниц программа-шпион может гарантировать, что определенный участок памяти удаляется из всей структуры кэша, используемой программой-шпионом для мониторинга доступа к участку памяти.
Атака Flush+Reload выполняется в три фазы. Во время первой фазы контролируемый участок памяти удаляется из структуры кэша. Во второй фазе программа-шпион находится в режиме ожидания, давая жертве время воспользоваться участком памяти. Во время третьей фазы программа-шпион перезагружает участок памяти и замеряет время загрузки. Если во время второй фазы жертва воспользовалась участком памяти, то этот участок будет доступен из кэша и операция перезагрузки пройдет быстро. С другой стороны, если очередь памяти осталась неиспользованной, понадобится время на загрузку участка и операции перезагрузки пройдет значительно дольше. На Рисунке 3 (A) и (B) показано время выполнения фаз атаки для обоих вышеупомянутых случаев.
Как показано на Рисунке 3 (C) интервал времени доступа жертвы к участку памяти может перекрывать интервал фазы перезагрузки. В таком случае, во время доступа жертвы к участку памяти не произойдет заполнение кэша, а будут получены уже закэшированные данные во время фазы перезагрузки. Следовательно, программа-шпион не сможет узнать о том, что жертва обращалась к участку памяти.
Похожий сценарий наблюдается и тогда, когда интервал перезагрузки частично перекрывает интервал доступа жертвы к участку памяти. На Рисунке 3 (D) показано, что фаза перезагрузки стартует в то время, когда жертва ожидает получение доступа к данным. В этом случае время перезагрузки будет с одной стороны быстрее, чем загрузка из памяти, но медленнее, чем загрузка из кэша.
Поскольку жертва и программа-шпион работают независимо друг от друга, увеличение времени ожидания уменьшает вероятность возникновение случаев перекрытия интервалов, однако с другой стороны уменьшает разрешающую способность атаки.
Один из способов увеличения разрешающей способности атаки без увеличения количества ошибок – мониторинг лишь некоторых типов доступа к памяти, которые происходят часто (например, внутри тела цикла). В этом случае нет возможности отличить один акт доступа от другого, однако, как показано на Рисунке 3 (E), вероятность пропустить доступ внутри цикла весьма мала.
Следует помнить, что некоторые механизмы оптимизации процессора могут привести к ложным срабатываниям из-за спекулятивного использования памяти, вызванного процессором жертвы [11]. Подобные оптимизации включают в себя предварительные выборки данных для локального использования или спекулятивного выполнения [17]. Во время анализа результатов после проведения атаки, злоумышленнику следует помнить о подобных оптимизациях и разработать стратегии по их фильтрации.
Наша версия кода для реализации атаки Flush+Reload показана на Рисунке 4. Код измеряет время чтения данных по адресу в памяти, а затем удаляет участок памяти из кэша. Измерение реализовано встроенным ассемблерным кодом внутри команды asm.
На входе ассемблерный код принимает один параметр (адрес), который хранится в регистре %ecx (Строка 16). На выходе получаем время чтения данных по этому адресу в регистре %eax, которое хранится в переменной time (Строка 15).
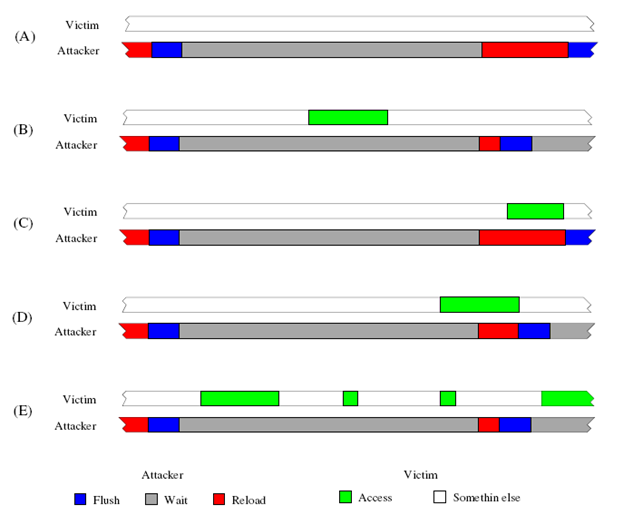
Рисунок 3: Схема взаимодействия злоумышленника и жертвы во время атаки Flush+Reload. (A) Жертва не пользовалась памятью, (B) Жертва пользовалась памятью, (C) Полное перекрытие интервала доступа к памяти и перезагрузки, (D) Частичное перекрытие интервала доступа к памяти и перезагрузки, (E) Множественный доступ к памяти
В строке 10 происходит считывание 4 байт по адресу в регистре, то есть адрес, на который указывает adrs. Для измерения времени чтения мы используем процессорный счетчик метки времени.
Инструкция rdtsc в строке 7 считывает 64-битный счетчик, который хранит младшие 32 бита в регистре %eax, а старшие биты в регистре %edx. Поскольку измеряемые интервалы времени малы, мы используем только младшие 32 бита, игнорируя старшие биты, находящиеся в регистре %edx. В строке 9 происходит копирование счетчика в регистр %esi.
После чтения данных из памяти счетчик метки времени считывается вновь (Строка 12). В строке 13 происходит вычитание значения счетчика до и после чтения данных из памяти, а затем результат сохраняется в выходном регистре %eax.
Суть техники заключается в удалении определенных участков памяти из кэша. Эту функцию выполняет инструкция clflush в строке 14. Инструкция clflush удаляет определенный участок памяти из всех кэшей, включая кэши L1 и L2 всех ядер процессора, что гарантирует загрузку данных в кэш L3, когда жертва в следующий раз обратится к памяти.
Инструкции mfence и lfence в строках 5, 6, 8 и 11 сериализуют поток инструкций. Архитектура процессоров Intel позволяет выполнять инструкции параллельно. Без сериализации, инструкции, окружающие измеряемый сегмент кода, могут быть выполнены вместе с этим сегментом. Компания Intel рекомендует использовать инструкцию сериализации cpuid для этой цели [12]. Хотя в виртуализированных средах гипервизор эмулирует инструкцию cpuid, однако такая эмуляция занимает значительное время (более 1000 циклов) и это время непостоянно, что уменьшает разрешающую способность и стабильность атаки.
Инструкция lfence выполняет частичную сериализацию. При выполнении этой инструкции гарантируется, что все предшествующие инструкции загрузки будут выполнены, и что ни одна последующая инструкция не будет выполнена перед инструкцией lfence. Инструкция mfence упорядочивает доступ к памяти, fence-инструкции и инструкцию clflush, но не упорядочивается по отношению к другим инструкциям.
В строке 18 происходит сравнение времени между выполнением двух инструкций rdtsc с предопределенной предельной величиной. Если загрузки произошли быстрее, чем предельная величина, предполагается, что другой процесс получил доступ к участку памяти с того момента, как этот участок был удален из кэша. Если же загрузки происходят медленнее, чем предельная величина, тогда предполагается, что работа ведется с памятью, сигнализируя о том, что к определенному участку памяти доступ не осуществлялся.
Размер предельной величины, используемый во время атаки, зависит от архитектуры. Для нахождения предельной величины для тестовой архитектуры мы использовали код из Рисунка 4 для измерения времени загрузки из памяти и из кэша L1 (в этого мы удалили инструкцию clflush в строке 14). Результаты 100 тысяч измерений загрузки из памяти и кэша показаны на Рисунке 5.
Практически все загрузки из кэша L1 заняли от 33 до 49 циклов. Из 100 тысяч измерений было 9 случаев, когда загрузка заняла 4000 циклов. Мы полагаем, что эти результаты корректны и для операционной системы и для гипервизора (если речь идет о виртуальной среде).

Рисунок 4: Код для реализации атаки Flush+Reload
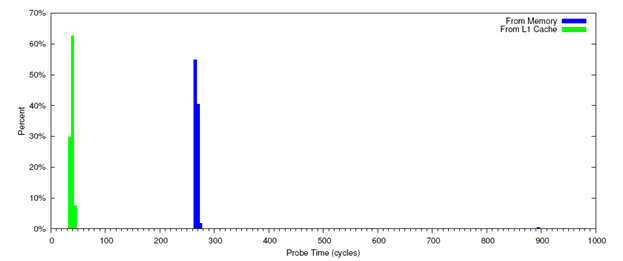
Рисунок 5: Распределение времен загрузок (зеленый цвет – из кэша L1, синий цвет – из памяти)
Распределение времен загрузки из памяти оказалось менее равномерным. В 97% случаях загрузка заняла от 200 до 300 циклов. Еще 2% случаев оказались в интервале от 300 до 400 циклов, но этот столбик очень мал, и его нельзя увидеть на графике. В 1% случаев загрузки были в интервале от 850 до 1200 циклов (на графике вы можете увидеть пик у значения 900 циклов). Как и в случае загрузки из кэша L1 было несколько случаев, выходящих далеко за рамки данного диапазона.
Результаты измерения времени загрузки из кэша L1 являются заниженными в сравнении со временем, которое затрачивает жертва, поскольку во время атаки жертва считывает данные из кэша L3. Согласно документации Intel [11], разница составляет от 22 до 39 циклов. Основываясь на результатах измерений и документации Intel, мы установили предельную величину в 120 циклов.
5 Атака на GnuPG
В этом разделе мы опишем, как применять технику Flush+Reload для извлечения компонент секретного ключа из GnuPG, шифрующего по алгоритму RSA. Атаку можно реализовать как в виртуальной, так и в обычной среде.
Мы проводили тесты на HP Elite 8300 с процессором Intel Core i5-3470, оперативной памятью 8GB DDR3-1600 и операционной системой Fedora 18.
Программа-шпион делит время на фиксированные слоты по 2048 циклов каждый. Внутри каждого слота происходит исследование участка памяти кода во время каждой операции возведения в квадрат, умножения и вычисления остатка от деления. Для увеличения шансов на обнаружение доступа, мы выбрали такие участки памяти, которые часто используются во время вычисления. После исследования каждого участка памяти программа-шпион ожидает окончание временного слота.
Для облегчения местонахождения участков памяти мы использовали версию gpg, которую мы собственноручно скомпилировали вместе с отладочными символами. В реальной ситуации злоумышленнику необходимо провести реверс-инжиниринг программы для того, чтобы найти местонахождение участков памяти. Отладочная информация позволит нам сопоставить адреса памяти и строки исходного кода без утомительного реверс-инжиниринга.
Результаты измерений для первых 200 слотов времени при подписи GnuPG показаны на Рисунке 6. Результаты измерений, находящиеся ниже предельной величины, сигнализируют о том, что жертва осуществляла доступ к соответствующему участку памяти.
Операции возвещения в степень во время подписи заняли 22402 слотов или около 15 мс. В этих операция участвовало 2046 битов, 9 из которых было утеряно и 25 инвертировано. Таким образом, процент ошибок составляет 1,6%.
На Рисунке 7 показан увеличенный участок Рисунка 6. Поскольку отображенный участок ниже предельной величины, на ней показаны только те участки памяти, которые загружались из кэша. Тем самым демонстрируется активность во время шифрования GnuPG. Шаги при возведении в степень отчетливо видны на рисунке. К примеру, между временными слотами 13 и 17 жертва производила возведение в квадрат. Временные слоты 18-21 показывают выполнение операций для приведения по модулю, а временные слоты 29-33 демонстрируют операции умножения.
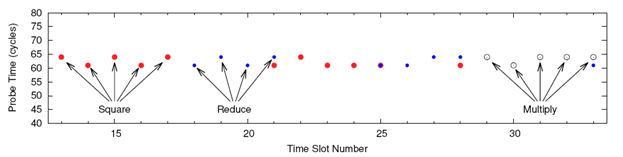
Рисунок 6: Результаты измерений во время исследования участков памяти
Последовательности операций «возведение в степень-приведение по модулю-умножение-приведение по модулю» отображены битом 1. Последовательности операций «возведение в квадрат-приведение по модулю», за которыми не следует умножение, отображены битом 0. Таким образом, последовательность битов для Рисунка 6 будет выглядеть так: 1010000110011110. В таблице 1 показаны временные слоты, соответствующие каждому биту. Операции приведения по модулю между временными слотами 0 и 3 предназначены для вычисления ![]() . Операции приведения по модулю между слотами 8 и 11 предназначены для приведения хэша сообщения по модулю p.
. Операции приведения по модулю между слотами 8 и 11 предназначены для приведения хэша сообщения по модулю p.
Спекулятивные операции также показаны на графике. К примеру, в слоте 94 участки памяти, соответствующие всем трем операциям, загружаются из кэша. Совершенно очевидно, что в нормальной ситуации при возведении в степень операции умножения и возведения в квадрат не могут выполняться внутри одного временного слота. Процессор пытается предсказать будущее поведение программы и поэтому одновременно осуществляет доступ ко всем трем участкам памяти. В случае выполнения инструкции условного перехода процессор может стартовать одну или даже две ветки перед вычислением условия. И только когда условное выражение вычислено, процессор переходит к выполнению.
|
Последовательность |
Временной слот |
Бит |
|
1 |
13-21 |
0 |
|
2 |
21-37 |
1 |
|
3 |
38-45 |
0 |
|
4 |
45-59 |
1 |
|
5 |
59-65 |
0 |
|
6 |
66-73 |
0 |
|
7 |
73-80 |
0 |
|
8 |
80-87 |
0 |
|
9 |
87-101 |
1 |
|
10 |
102-116 |
1 |
|
11 |
116-123 |
0 |
|
12 |
123-130 |
0 |
|
13 |
130-144 |
1 |
|
14 |
145-159 |
1 |
|
15 |
159-173 |
1 |
|
16 |
173-187 |
1 |
|
17 |
188-194 |
0 |
Таблица 1: Соответствие временных слотов и последовательности битов
Во временном слоте 94 процессор как бы допускает, что значение текущего бита может быть 0. Далее пропускается тело условного выражения и загружается участок памяти операции возведения в квадрат. Когда условное выражение вычислено, процессор останавливает эту ветку и переходит к выполнению операции умножения.
6 Выводы
В этой статье мы рассказали об атаке Flush+Reload и ее использовании для извлечения секретного RSA-ключа из GnuPG. Данная техника позволяет извлекать более 98% битов секретного ключа, то есть, по сути, мы можем взломать ключ во время одиночного дешифрования или подписи. Для реализации такой схемы требуется использование совместных страниц между программой-шпионом и жертвой. Также эта схема может работать через изолированный слой виртуализированных систем.
Трудно переоценить серьезность этой уязвимости в GnuPG. GnuPG – очень популярная криптографическая программа, которая используются во многих проектах с открытым исходным кодом, а также для шифрования электронных писем, файлов или мгновенных сообщений. При помощи нашей схемы любой процесс, запущенный в системе, может достать секретные ключи. Следовательно, GnuPG и текущая реализации этого продукта небезопасна для многопользовательской системы или любой системы, которая позволяет запускать небезопасный код.
Прошлое исследование показало, что алгоритм многократного возведения в произвольную степень путем многократного возведения в квадрат и умножения может быть уязвим для атак по сторонним каналам. Самый важный урок, который могут извлечь разработчики программ из этой статьи, - иногда многократное использование уже существующей методики позволяет превратить теоретическую уязвимость в рабочий эксплоит.
Вполне вероятно, что другие существующие уязвимости могут быть использованы на практике при помощи подобной схемы. Некоторые из примеров, приходящие в голову: добавочное сокращение в алгоритме умножения по Монтгомери [3,15] и атака типа padding oracle attack, изобретенная Сержем Воденэ (Serge Vaudenay) [4, 18]. Необходимо провести дальнейшее исследование, чтобы определить масштаб использования техники Flush+Reload, и какие механизмы позволяют от этого защититься.
Также следует отметить, что техника не ограничивается применением лишь к криптографическому программному обеспечению. В любой другой программе также может произойти утечка конфиденциальных данных через кэш. Особое внимание следует уделить виртуализированным средам, где на первый взгляд кажется, что виртуальные машины полностью отделены друг от друга. Удаление дубликатов памяти (memory de-duplication) может сэкономить ресурсы, однако снижает уровень безопасности системы. Мы рекомендуем отключить эту функцию в виртуальных средах.
Благодарности
Это исследование было проведено по контракту с научно-технической организацией министерства обороны Австралии.
Ссылки
[1] O. Ac_i_cmez, "Yet another microarchitectural attack: exploiting I-Cache, ACM Workshop on Computer Security Architecture, Fairfax, Virginia, United States, November 2007, pp. 11-18.
[2] O. Ac_i_cmez, B. B. Brumley, and P. Grabher, \New results on instruction cache attacks," in Proceedings of the Workshop on Cryptographic Hardware and Embedded Systems, Santa Barbara, California, United States, August 2010, pp. 110-124.
[3] O. Ac_i_cmez and W. Schindler, "A vulnerability in RSA implementations due to instruction cache analysis and its demonstration on OpenSSL," in Proceedings of the Cryptographers' Track at the RSA Conference, San Francisco, California, United States, April 2008, pp. 256-273.
[4] N. J. AlFardan and K. G. Paterson, "Plaintext-recovery attacks against datagram TLS," in Proceedings of the 19th Annual Network & Distributed Systems Security Symposium, San Diego, California, United States, February 2012.
[5] A. Arcangeli, I. Eidus, and C. Wright, "Increasing memory density by using KSM," in Proceedings of the Linux Symposium, Montreal, Quebec, Canada, July 2009, pp. 19-28.
[6] H. L. Garner, "The residue number system," IRE Transactions on Electronic Computers, vol. EC-8, no. 2, pp. 140-147, June 1959.
[7] "GNU Privacy Guard," http://www.gnupg.org, 2013.
[8] D. M. Gordon, "A survey of fast exponentiation methods," Journal of Algorithms, vol. 27, no. 1, pp. 129-146, April 1998.
[9] D. Gullasch, E. Bangerter, and S. Krenn, "Cache games | bringing access-based cache attacks on AES to practice," in Proceedings of the IEEE Symposium on Security and Privacy, Oakland, California, United States, may 2011, pp. 490-595.
[10] R. Hund, C. Willems, and T. Holz, \Practical timing side channel attacks against kernel space ASLR," in Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, California, United States, May 2013, pp. 191"205.
[11] Intel 64 and IA-32 Architecture Optimization Reference Manual, Intel Corporation, April 2012.
[12] G. Paoloni, How to Benchmark Code Execution Times on Intel IA-32 and IA-64 Instruction Set Architectures, Intel Corporation, September 2010.
[13] C. Percival, "Cache missing for fun and pro_t," http://www.daemonology.net/papers/htt.pdf, 2005.
[14] R. L. Rivest, A. Shamir, and L. Adleman, "A method for obtaining digital signatures and public-key cryptosystems," Communications of the ACM, vol. 21, no. 2, pp. 120-126, February 1978.
[15] W. Schindler, "A timing attack against RSA with the Chinese remainder theorem," in Proceedings of the Workshop on Cryptographic Hardware and Embedded Systems, no. 109-124, Worcester, Massachusetts, United States, August 2000.
[16] E. Tromer, D. A. Osvik, and A. Shamir, "E_cient cache attacks in AES, and countermeasures," Journal of Cryptology, vol. 23, no. 2, pp. 37{71, January 2010.
[17] A. K. Uht and V. Sindagi, "Disjoint eager execution: An optimal form of speculative execution," in Proceedings of the 28th International Symposium on Microarchitecture, Ann Arbor, Michigan, United States, November 1995, pp. 313-325.
[18] S. Vaudenay, "Security aws induced by CBC padding. applications to SSL, IPSEC, WTLS. . . ," in EUROCRYPT 2002, Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Amsterdam, The Netherlands, April 2002, pp. 534-546.
[19] C. A. Waldspurger, "Memory resource management in VMware ESX Server," in Proceedings of the Fifth Symposium on Operating Systems Design and Implementation, Boston, Massachusetts, United States, December 2002, pp. 181-194.
[20] M. Wei_, B. Heinz, and F. Stumpf, "A cache timing attack on AES in virtualization environments," in Proceedings of the 16th International Conference on Financial Cryptography and Data Security, Bonaire, February 2012.
[21] Y. Zhang, A. Jules, M. K. Reiter, and T. Ristenpart, "Cross-VM side channels and their use to extract private keys," in Proceedings of the 19th ACM Conference on Computer and Communication Security, Raleigh, North Carolina, United States, October 2012, pp. 305-316.