Скоростное поточное шифрование.
Информационная безопасность полна парадоксов, один из них это однобокая эволюция методов и приемов противостояния нападающей и обороняющейся стороны.
Информационная безопасность полна парадоксов, один из них это однобокая эволюция методов и приемов противостояния нападающей и обороняющейся стороны. Развиваются только технологии нападения, а вот защита застыла на технологиях прошлого века, а точнее прошлого тысячелетия. Причин много, но главная, мозги защитников ИБ прикормленные «халявными» деньгами перестали думать.
Пора встряхнуться, для начала о основе информационной безопасности,- методах защиты информации. Защищают информацию с древних времен криптографическими преобразованиями (шифрацией), о шифрации больших объемов информации и надежности процесса шифрования пойдет речь в данной статье.
Традиционная реализация ГОСТ 28147-89
Криптографическое преобразование по ГОСТ 28147-89 используется для поточного шифрования информации в каналах связи и на накопителях информации (дисках).
В настоящее время повсеместно применяется программная реализация данного ГОСТ на РОН центрального процессора. В известных методах реализации ГОСТ вся секретная информация (ключи шифрования, блоки замен) размещаются в оперативной памяти.
Это снижает надежность шифрования, поскольку, имея дамп оперативной памяти, можно полностью выявить все секретные элементы криптопреобразования.
Кроме этого, метод имеет ограничения по быстродействию, обусловленные расположением основных объектов криптопреобразования в ОП и неполной загрузкой исполнительных устройств ALU. Современные процессоры, реализуя криптопроцедуру по известному методу могут обеспечить реальную скорость шифрования на уровне 10-30 мегабайт в секунду.
Основной причиной низкого быстродействия и слабой защищенности криптопреобразования является программная реализация блока подстановок. Вот как он описан в официальном документе ГОСТ 28147-89 :

По п. 1.2. ГОСТ этот блок реализует тетрадные (по четыре бита) перестановки в 32битном слове, но архитектура процессора х86/64 и его система команд не способна эффективно манипулировать тетрадами.
Для программной реализации блока подстановок используют специальные таблицы в оперативной памяти подготавливаемые на этапе инициализации криптофункции. Эти таблицы объединяют узлы замен смежных тетрад в байтовые таблицы размером 8х8 бит, таким образом в оперативной памяти размещается четыре 256 байтных таблицы.
В более продвинутых реализациях эти таблицы имеют размер 1024 байта (256 слов по четыре байта). Это сделано для того, чтобы реализовать в этих таблицах дополнительно циклический сдвиг на 11 позиций полученного в результате подстановки 32 битного слова (следующая операция алгоритма преобразования по ГОСТ).
Информация блока подстановок является секретным компонентом криптофункции, вот как это сформулировано в официальном документе ГОСТ 28147-89:

Размещение этих таблиц с ключами блока подстановок в ОП противоречит требованиям ГОСТ 28147-89 п.1.7., поскольку секретная информация становится доступной для сторонних программ, работающих на вычислительной установке. ФСБ, сертифицирующая в том числе и программные реализации шифрования по ГОСТ 28147-89 на данное нарушение смотрит мягко говоря снисходительно. Если для размещения ключей в ОП ФСБ еще требует наличия «фигового листочка», в виде маскирования ключей операцией XOR, то для блоков замен в ОП ничего не требуется, они хранятся в открытом виде.
ФСБ пропускает такие программные реализации криптопроцедуры, несмотря на явное снижение стойкости такого решения и прямое нарушение собственных требований по ГОСТ 28147-89 п.1.7..
И это не смотря на общеизвестные методы взлома шифров через съём дампа памяти….
Использование SSE регистров и AVX команд современных процессоров для реализации ГОСТ 28147-89
Современные процессоры архитектуры х86/64 имеют в своем составе набор регистров SSE размером 16 байт и специализированные FPU (как минимум два) для выполнения различных операций над этими регистрами. Возможна реализация ГОСТ 28147-89 на этом оборудовании, причем в этом случае узлы замены можно размещать не в виде таблиц в оперативной памяти, а непосредственно на выделенных SSE регистрах.
На одном SSE регистре можно разместить сразу две таблицы из 16 строк. Таким образом, четыре SSE регистра позволят полностью разместить все таблицы замен. Единственным условием такого размещения является требование чередования, согласно которому тетрады одного байта должны помещаться в разные SSE регистры. Кроме этого целесообразно размещать младшие и старшие тетрады входных байтов соответственно в младших и старших тетрадах байтов SSE регистров.
Эти требования обуславливаются оптимизацией под имеющийся набор AVX команд.
Таким образом, каждый байт SSE регистра будет содержать две тетрады, относящиеся к разным байтам входного регистра блока подстановок, при этом позиция байта на SSE регистре однозначно соответствует индексу в таблице замены блока подстановки.
Схема одного из возможных размещений узлов замены на SSE регистрах показана на рисунке:
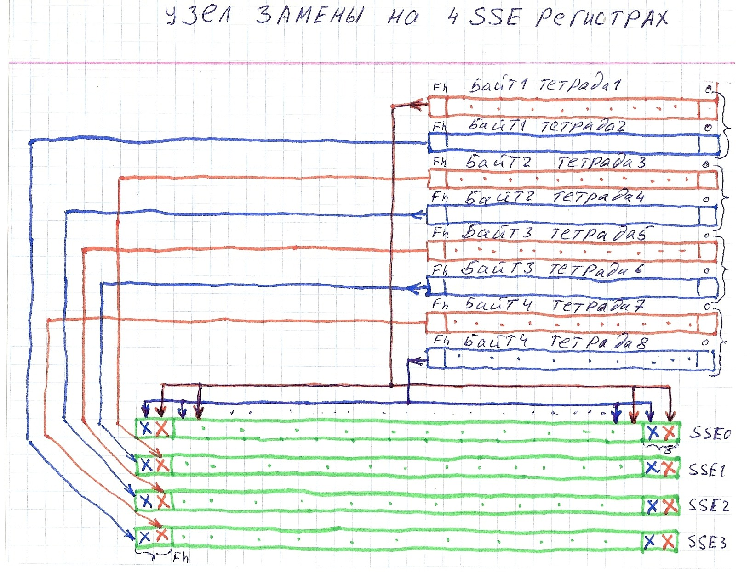
Размещение секретной информации узлов замен на SSE регистрах повышает защищенность криптопроцедуры, и скорости его работы.
Для эффективной выборки из SSE регистров тетрад используется имеющиеся в составе блоков FPU многовходовые байтовые коммутаторы. Эти коммутаторы позволяют осуществлять пересылки из любого байта источника в любой байт приемника, по индексам находящемся в специальном индексном SSE регистре. Причем параллельно выполняется пересылка для всех 16 байт SSE регистра- приемника.
Имея узлы хранения подстановок на SSE регистрах и многовходовый коммутатор в блоках FPU можно организовать следующее преобразование в блоке подстановок:
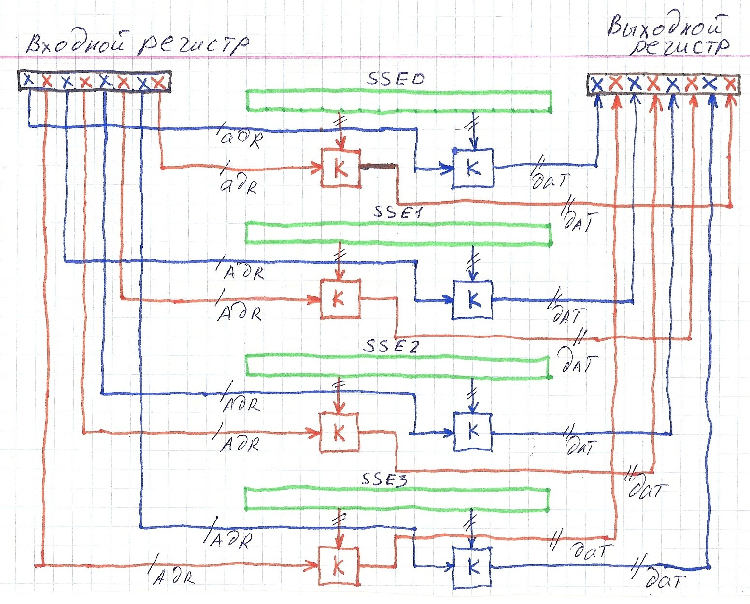
В этой схеме входной регистр в каждой тетраде задает адрес для соответствующего коммутатора, который по шине данных передает из накопителей узлов замены информацию в выходной регистр.
Работой коммутаторов управляет специальная трехадресная команда AVX VPSHUFB. Первый операнд которой является приемником информации из коммутаторов, второй операнд является источником, к которому подключены входы коммутаторов, а третий операнд является управляющим регистром для коммутаторов, каждый байт которого ассоциирован с соответствующим коммутатором и значение в нем задает номер направления с которого коммутатор считывает информацию. Вот описание этой команды из официальной документации фирмы Интел:

А вот схема работы этой команды, - изображена только половина SSE регистров, для второй половины все аналогично:
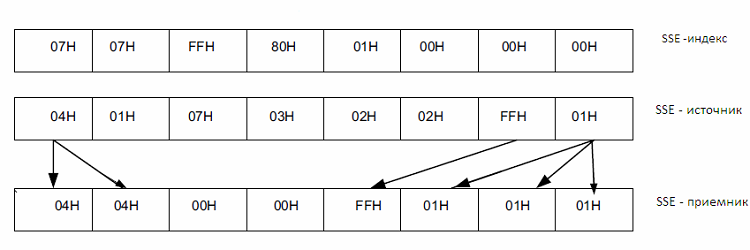
Коммутатор использует только младшие четыре бита для определения направления коммутации, последний бит в каждом байте используется для принудительного обнуления соответствующего байта приемника, но эта функция коммутатора в нашем случае пока не востребована.
Регистры SSE можно разбивать на равные части и выполнять над этими частями одинаковые преобразования одной командой. Нас интересует пакетный режим с разбивкой SSE регистра на четыре 32битных блока, это дает возможность одной процессорной командой параллельно обрабатывать сразу четыре блока по 32 бита, т.е. в параллель рассчитывать четыре блока данных.
В современных процессорах имеется как минимум два блока FPU и для их полной загрузки можно использовать два потока независимых команд. Если грамотно чередовать команды из независимых потоков, то можно загрузить работой оба блока FPU полностью и получить сразу восемь параллельно обрабатываемых потоков данных. Если кому интересно, то пример реализации алгоритма на Ассемблере есть в приложении в конце статьи.
Цена вопроса
Использование SSE регистров для хранения узлов замены дает гарантию изоляции секретной ключевой информации, а вот увеличение скорости криптофункции на FPU это неочевидно. Поэтому были проведены замеры времени выполнения стандартных процедур по методу прямой замены в соответствии с ГОСТ 28147-89 для четырех потоков и для восьми потоков.
Для четырех потоков была получена скорость выполнения 472 процессорных тактов. Таким образом, для процессора с частотой 3,6 Ггц один поток считается со скоростью 59 мегабайт в секунду, а четыре потока соответственно со скоростью 236 мегабайт в секунду.
Для восьми потоков была получена скорость выполнения 580 процессорных тактов. Таким образом, для процессора с частотой 3,6 Ггц один поток считается со скоростью 49 мегабайт в секунду, а восемь потоков соответственно со скоростью 392 мегабайт в секунду.
Для дальнейшей оптимизации нелишне помнить о наличие 256 битных регистров (YMM регистры), используя которые можно теоретически еще удвоить скорость вычислений. Но пока это только перспектива, на данный момент процессора очень сильно замедляются, когда выполняют 256 битные инструкции (FPU имеют ширину тракта 128 бит). Эксперименты показали, что на современных процессорах счет в 16 потоков на YMM регистрах выигрыша не даёт. Но это только пока, на новых моделях процессоров несомненно будет увеличено быстродействие 256 битных команд и тогда использование 16 параллельных потоков станет целесообразно и приведет к еще большему увеличению скорости работы криптопроцедуры.
Теоретически можно рассчитывать на скорость 600-700мегабайт в секунду при наличии в процессоре двух FPU с шириной рабочего тракта 256 бит каждый.
Как это ни странно, встроенное в процессора шифрование по AES алгоритму оказывается значительно медленнее, тесты показывают скорость на уровне 100-150 мегабайт в секунду, и это при аппаратной реализации алгоритма! Там проблема опять в однопоточном счете и блоке замен, который оперирует байтами (таблица из 256 строк). Так что ГОСТ оказывается эффективнее AES в реализации на архитектуре х86/64, кто бы мог подумать…
Описанный выше алгоритм шифрования по ГОСТ уже не теория, он внедрен в коммерческий продукт. Фирма «Код Безопасности» данный алгоритм реализации ГОСТ 28147-89 использовала в своем коммерческом продукте – Криптошлюзе «Континент», результатом внедрения стало существенное повышение пропускной способности шифрованных каналов связи. Сейчас начинается этап сертификации модернизированного изделия.
Еще быстрее.
Недавно фирма Интел анонсировала новый процессор для многопоточных вычислений «Xeon Phi». Данный процессор используется в составе ускорителя Knights Corner:

Ускоритель содержит более 60 процессорных ядер в каждом из которых находится блок вычислений с длинной операндов 512бит. Это позволяет на одном процессорном ядре вычислять сразу 16 блоков данных.
А всего на 60 ядрах можно одновременно считать более 700 блоков, скорость понятно будет меньше чем на обычном процессоре, из-за тактовой частоты в 1Ггерц (пока). Но теоретически можно рассчитывать на пропускную способность одного такого шифратора в диапазоне 10-16 Гбайт в секунду, или более 100Гбит/сек сетевого трафика, а это уже скорости магистральных каналов пакетной передачи трафика.
Сейчас начаты работы с предсерийным образцом ускорителя Knights Corner, проблем много, но все они преодолимы. Пока ПО поставляемое вместе с этим ускорителем не может обеспечить нормальной загрузки ускорителя для задачи криптопреобразования. Требуется полная переработка внутренней ОС ускорителя и написание собственных скоростных драйверов обмена информации между памятью ускорителя и ОП хостовой системы.
Если будет добрая воля фирмы Интел поделиться технической информаций, думаю к лету этот ускоритель начнет работать в качестве шифратора, причем этот шифратор будет «мечтой…ФСБ» поскольку вся ключевая информация и программы преобразований будут храниться в этом «черном ящике», внутри ускорителя (во внутренней флеш-памяти) и они не могут быть считаны/модифицированы программными средствами Хоста.
В заключении хочу обратить внимание на один аспект принципиальный проблемы поточного шифрования, - попытки протаскивания западного алгоритма AES вместо отечественного ГОСТ 28147-89. До настоящего времени это оправдывалось низкой скоростью реализации отечественного алгоритма шифрования.
Но как следует из вышеизложенного отечественный метод шифрования в предложенной реализации на SSE регистрах не только быстрее, но и надежнее западного метода. Посмотрим, как события будут развиваться далее…
Приложение
Основной цикл шифрования на SSE в восемь потоков.
SSE0, SSE1, SSE6, SSE7 содержат поочередно накопители1 и накопители2 (восемь накопителей по 4 байта каждый)
Сначала готовятся индексные регистры для работы коммутатора
Пример кода не оптимизирован по быстродействию, но максимально удобен для понимания.
Ключи шифрования находятся в ОП, но можно и загружать в неиспользуемые регистры процессора (MMX).
Use64
macro zxmm kl
{
;/////подготовка блока замен 1 накопитель
vpsrlq xmm3,xmm5,4;
pand xmm5,[esp+080h]; технологическая маска выделения младших тетрад
pand xmm3,[esp+080h]; технологическая маска выделения младших тетрад
;/////замена 1-2байт -м.т. 3-4байт с.т.
vpblendw xmm2,xmm3,xmm5,055h;
;/////замена 1-2байт - с.т. 3-4байт м.т.
pblendw xmm5,xmm3,0aah;
;/////////блок замен 1-2 байты - 1 накопитель
vpshufb xmm15,xmm8,xmm2;
pand xmm15,[esp];
vpshufb xmm14,xmm9,xmm2;
pand xmm14,[esp+20h];
por xmm14,xmm15;
;/////////блок замен 3-4 байты - 1 накопитель
vpshufb xmm12,xmm10,xmm5;
pand xmm12,[esp+40h];
por xmm12,xmm14;
vpshufb xmm13,xmm11,xmm5;
pand xmm13,[esp+60h];
;/////подготовка блока замен -2 накопитель
vpsrlq xmm3,xmm4,4;
pand xmm4,[esp+80h];
pand xmm3,[esp+080h];
;/////замена 1-2байт -м.т. 3-4байт с.т.
vpblendw xmm2,xmm3,xmm4,055h;
;/////замена 1-2байт - с.т. 3-4байт м.т.
pblendw xmm4,xmm3,0aah;
;/////////блок замен 1-2 байты - 2 накопитель
vpshufb xmm14,xmm8,xmm2;
pand xmm14,[esp];
vpshufb xmm15,xmm9,xmm2;
pand xmm15,[esp+20h];
por xmm14,xmm15;
;/////////блок замен 3-4 байты - 2 накопитель
vpshufb xmm3,xmm10,xmm4;
pand xmm3,[esp+40h];
por xmm14,xmm3;
vpshufb xmm15,xmm11,xmm4;
pand xmm15,[esp+60h];
}
;///////////////////////////////тестовый модуль 1 проход
macro c1 kl;
{
zxmm kl;
;/////циклический сдвиг на 11 влево - 1 накопитель
por xmm13,xmm12;
vpslld xmm12,xmm13,11;
psrld xmm13,21;
xorps xmm7,xmm12;
xorps xmm7,xmm13; суммирование заполнение1 1 накопитель
vpaddd xmm5,xmm7,[esp+100h+kl*32]; сложить заполнение с ключом
;/////циклический сдвиг на 11 влево - 2 накопитель
por xmm15,xmm14;
vpslld xmm14,xmm15,11;
psrld xmm15,21;
xorps xmm1,xmm14;
xorps xmm1,xmm15; суммирование заполнение1 2 накопитель
vpaddd xmm4,xmm1,[esp+120h+kl*32]; сложить заполнение с ключом
}
;///////////////////////////////тестовый модуль 2 проход
macro c2 kl;
{
zxmm kl;
;/////циклический сдвиг на 11 влево - 1 накопитель
por xmm13,xmm12;
vpslld xmm12,xmm13,11;
psrld xmm13,21;
xorps xmm6,xmm12;
xorps xmm6,xmm13; суммирование заполнение 0 1 накопитель
vpaddd xmm5,xmm6,[esp+100h+kl*32]; сложить заполнение с ключом
;/////циклический сдвиг на 11 влево - 2 накопитель
por xmm15,xmm14;
vpslld xmm14,xmm15,11;
psrld xmm15,21;
xorps xmm0,xmm14;
xorps xmm0,xmm15; суммирование заполнение 0 2 накопитель
vpaddd xmm4,xmm0,[esp+120h+kl*32]; сложить заполнение с ключом
}