
Управление инцидентами в ИБ: формальность или необходимость?
В нашей недавней серии статей про SIEM системы упоминалась, среди прочего, встроенная в некоторые продукты возможность управления инцидентами (incident management). Сегодня мы расскажем о некоторых аспектах этого процесса.
Автор: Олеся Шелестова, исследовательский центр Positive Research.
Сотрудники служб ИБ и технические специалисты занимаются решением самых разных задач. При этом не всегда их инициатором является руководство: в случае обнаружения симптомов угрозы, инцидента безопасности или ошибки конфигурации сотрудник вполне может и сам проявить инициативу. Если задачу ставит руководитель, то он, как правило, устанавливает сроки и контролирует ход решения задачи. Однако далеко не во всех компаниях используется специализированное ПО для контроля и учета задач наподобие Microsoft Project. Зачастую применяются «самописные» или адаптированные системы Service Desk. Задачи оформляются в подобном ПО, и далеко не всегда это делается должным образом.
Если сотрудник самостоятельно находит инцидент и сам же занимается его решением, то позиция руководителя здесь: «лишь бы все работало». Редко бывает, что процесс решения задач регламентирован, задокументирован, что выстроена схема согласования. И чем больше компания, тем ситуация хуже.
Вот лишь некоторые недостатки этих двух схем:
- Внесение несогласованных изменений. Информация о причине тех или иных изменений в системе нигде не хранится, в лучшем случае все согласования происходят устно. Неудивительно, что спустя какое-то время мало кто в состоянии вспомнить последовательность произведенных действий.
- Отсутствие контроля изменений. В результате неизвестно, кто и когда изменил тот или иной параметр.
- Не производится оценка изменений. Никто не задается вопросом о том, как внесенные изменения повлияли на инфраструктуру и стабильность информационных систем, не породили ли они других инцидентов и проблем безопасности.
- Некорректно определяются приоритеты. Если сотрудник определяет порядок решения задач самостоятельно, то более важную задачу он может оставить «на потом» и сфокусироваться на менее сложной. Для бизнеса такой подход неприемлем.
- Отсутствует прозрачность работы подразделения. Руководству необходимо знать, какие задачи, для чего, почему, кто и когда решает.
- Отсутствуют метрики. Не ведется учет количества задач и сроков их исполнения для каждого сотрудника. Как следствие, возникают проблемы при обосновании штатного расписания и трудности при организации service level agreement (SLA).
- Проблемы не выявляются. Не ясны причины роста числа инцидентов, трудно планировать меры предупреждения проблем.
- Затруднения при оптимизации процессов. Решение простых задач может занимать достаточно много времени. Разобраться, что стало тому причиной (загруженность сотрудника, долгий процесс согласования), очень трудно.
- Отсутствие контроля. Зачастую сотрудник приступает к решению задачи не сразу после ее постановки, а лишь спустя значительное время.
- Безответственное отношение к процессу документирования. Доказательства по инцидентам хранятся в разных местах, и соответственно, узнать подробности о них (на основании чего возникали, как решались, вносились ли в процессе работы над ними изменения) — не представляется возможным. Кроме того, при подобной схеме можно вообще не узнать, что инцидент имел место. Невозможно вручную сравнить несколько состояний системы или конфигураций, чтобы выяснить, какие были внесены изменения.
- Отсутствие базы знаний. При постоянном решении типовых инцидентов сотрудник набивает руку и справляется с ними все легче. Однако иногда возникают совсем не типовые проблемы, после решения которых даже опытный профессионал зачастую не вспомнит, какие строки в конфигурационном файле были изменены. Кроме того, в любой компании время от времени появляются новые сотрудники, у которых поначалу и типовые инциденты могут вызывать сложности.
- Проблемы взаимодействия между подразделениями. Несмотря на то что далеко не всегда для решения инцидентов информационной безопасности требуется помощь сотрудников отдела ИТ, налаженное взаимодействие между ИБ- и ИТ-департаментами жизненно необходимо. Если общего для всех процесса работы с инцидентами нет, то время их решения увеличивается в разы. Даже наличие плана реагирования на инциденты в данной ситуации не сильно поможет, ведь одно только назначение ответственных сотрудников может занять массу времени. При подобной организации управления инцидентами уменьшить временные затраты можно с помощью автоматических шаблонов.
Все вышеперечисленное существенно влияет на оперативность решения задач и инцидентов (mean time to remediate, MTTR), на риски их возникновения, простои и даже на размер штата подразделения. При этом невозможно утверждать (и подтвердить это), что в информационных системах компании нет уязвимостей, а те, что есть, своевременно обнаруживаются и устраняются.
Зачастую ретивые менеджеры просто-напросто заставляют сотрудников оформлять инциденты и «заводить» решаемые задачи вручную, полагая, что так порядка будет больше. Очевидно, что построить адекватный процесс управления инцидентами в таких условиях невозможно по двум причинам:
- никто не любит бумажную волокиту;
- ручное документирование задач тратит время сотрудника, которое могло бы быть использовано более эффективно.
В то же время автоматизация управления инцидентами, построенная на шаблонах регистрации и проведения инцидента с расстановкой задач и контролем сроков их выполнения, — значительно упрощает внедрение, адаптацию и ведение процесса управления инцидентами.
Зачем это нужно?
Для чего нужна автоматизация и переход к управлению инцидентами? Конечно, вы можете выявлять инциденты самостоятельно и по электронной почте или по телефону назначать задачи по их устранению конкретным сотрудникам. Однако всегда есть риск не дозвониться, а письмо может попасть в спам. Специфика ИБ заключается в том, что за это время вирус на рабочей станции способен перерасти в настоящую эпидемию, злоумышленник может провести эксплуатацию уязвимости, похитить конфиденциальные данные, нанести ущерб системе. Во избежание подобных последствий как раз и требуется снижение показателя MTTR.
Представим себе ситуацию, когда инцидент не был своевременно выявлен. Причин тому может быть множество: сотрудник заболел, отвлекся, был загружен другими задачами, банально забыл или ему не хватило опыта. Если процесс управления инцидентами в компании отлажен хорошо, то ситуация «забыл зарегистрировать инцидент» не произойдет в принципе. Инцидент будет зарегистрирован, зафиксирован, а к решению проблемы будет привлечен компетентный сотрудник. Именно для автоматического выявления и регистрации инцидентов нужны механизмы корреляции SIEM-систем. Кстати сказать, подобные системы обычно оснащены и встроенным функционалом управления инцидентами.
Без особых затрат автоматизировать процесс регистрации инцидента можно с помощью автоматически создаваемого электронного письма, содержащего сценарий необходимых действий в зависимости от условий инцидента, запуск процедуры SQL для поиска симптомов инцидента, взаимодействие посредством API. Большинство программных продуктов, предназначенных для обеспечения информационной безопасности, имеют встроенную возможность работы с системами регистрации инцидентов или минимально необходимые инструменты для взаимодействия посредством электронной почты, SNMP, API.
Понятие и организация процесса управления инцидентами для IТ-департаментов наиболее полно и четко описаны в ITIL и ITSM. Для ИБ же, по большому счету, опираться можно только на стандарт NIST 800-61, хотя на практике можно успешно пользоваться и ITIL.
Процесс управления инцидентами включает в себя следующие понятия:
- Собственно, инцидент (INC, Incident) — событие (или потенциальная возможность события), которое ведет к нарушению требований информационной безопасности, конфиденциальности, целостности или доступности информационных ресурсов, либо любое нестандартное событие, которое вызывает или может вызвать снижение качества работы или прерывание доступности сервиса.
- Запрос на изменение (RFC, Request for Change) используется для согласования задач на изменение конфигураций, политик и т. п. и организации процесса изменения по задачам в рамках RFC. Это может быть изменение какого то конфигурационного файла, IP-адреса сервера, смена всего адресного пространства IP, установка каких-либо средств защиты или сетевых устройств.
- Проблема (Problem) — может возникать при многочисленном повторении однотипного инцидента. Является следствием принятия неэффективных или неверных мер по устранению причин возникновения инцидентов (или непринятия мер вообще), либо внесения изменений, повлекших нарушение работы информационных систем и возникновению рисков. Например, пользователь каждый день обращается и сообщает, что у него заблокирована учетная запись. Факт обращения – это инцидент. Но пользователь обращается каждый день, и ежедневно на решение инцидента тратятся ресурсы. Для этого заводится проблема, призванная разобраться с причинами блокировки и устранить возникающие однотипные инциденты.
Процесс управления инцидентами может и должен включать в себя часть процессов управления изменениями и управления проблемами (change management и problem management).
Чтобы определить понятия, используемые в процессе управления инцидентами, рассмотрим простые жизненные примеры.
- Задача вида «Необходимо обновить версию программного обеспечения» — это запрос на изменение (RFC).
- Задача вида «Установите патч. Уязвимость не найдена, но возможна» — это RFC.
- «Сканер нашел уязвимость. Установите патч!» — это инцидент. В зависимости от принятых в условии правил RFC может быть даже открыто из инцидента на согласование изменений и установку патча.
- «Настроить сервер» — это RFC или задача в рамках существующего RFC «Установить сервер»;
- «необходимо перенастроить прокси (squid)» — это RFC. В случае, если эти перенастройки необходимы из-за возникающих инцидентов, задача может выполняться в рамках этих инцидентов или же представлять собой запрос на изменение (RFC, связанный с инцидентом).
- Вирус или обнаруженная атака – это инцидент:
- Если в одном и том же сегменте инфраструктуры (напр. на сервере) часто обнаруживаются вирусы – это проблема.
Для правильной организации управления инцидентами необходимо обеспечить по крайней мере три линии поддержки.
- Первая линия осуществляет прием, регистрацию, перенаправление, уточнение и обработку запросов и инцидентов. Кроме того, специалисты первой линии могут заниматься решением простых инцидентов. Эти обязанности можно возложить на отдел HelpDesk или на выделенных сотрудников SOC, которые будут использовать базу знаний для помощи в решении несложных инцидентов.
- Вторая линия решает инциденты, не требующие привлечения экспертов. Как правило, этим занимаются региональные отделы ИБ или, в случае недостатка ИБ-специалистов, — сотрудники IТ-департамента.
- Третья линия — эксперты. Решают самые сложные задачи, которые выходят за рамки компетенции специалистов первой и второй линий, а также занимаются работой с критически важными для бизнеса инцидентами, которые требуют оперативной реакции.
Связь пользователь — эксперт — это не лучшая практика: тратить время высокооплачиваемого специалиста на решение простых задач невыгодно. К сожалению, на практике в некоторых случаях это необходимо, к примеру, когда у двух первых двух линий поддержки не хватает компетенции или необходимо как можно быстрее разобраться с причинами инцидентами, позвонив пользователю напрямую, а не играть в «испорченный телефон».
Введем еще один термин. Заголовок — это некое подобие задачи, которая представляет инцидент, запрос на изменение или проблему. Для того чтобы описать шаблонную автоматическую регистрацию инцидента и его назначение в качестве задачи сотруднику, каждый заголовок (инцидент, RFC, проблема) должен включать:
- тип заголовка (инцидент, запрос на изменение, проблема);
- тип подразделения (ИТ, ИБ);
- метод регистрации в системе (корреляция, пользователь, внешняя система);
- наименование заголовка; тут могут использоваться шаблоны вида %Несанкционированный доступ%, формируемые различными системами (в том числе SIEM);
- объект (офис), в котором зарегистрирован инцидент (иногда нужно знать, где именно произошел инцидент, чтобы проще было понять, кому назначить задачу по его устранению);
- класс заголовка (например, %Антивирус%; дается по классам событий);
- приоритет (информирует о степени критичности инцидента).
Присвоение приоритета позволяет в первую очередь уделить больше внимания решению действительно значимых инцидентов. В простейшем случае важность той или иной задачи определяется с помощью таблицы:
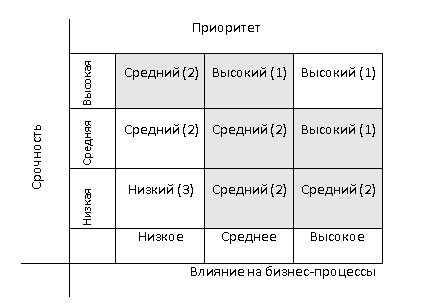
Однако в случае наличия в инфраструктуре компании систем риск-менеджмента (GRC) или SIEM-систем с возможностью указывать значения ценности актива, все немного сложнее. В общем случае каждая задача (заголовок) должна назначаться конкретному сотруднику или определенной группе специалистов. Уведомление о назначении должно подтверждаться по электронной почте. Перечислим рекомендуемые статусы заголовков для отслеживания процесса решения задач.
- Назначен. Задача назначена определенному пользователю, он проинформирован об этом, но еще не начал работать над ней.
- В работе. Сотрудник ознакомился с задачей и приступил к выполнению.
- Отложен. Решение отложено по какой-то причине (указывается отдельно).
- Решен. Ответственный сотрудник выполнил все необходимые работы по решению задачи.
- Закрыт. Решение подтверждено руководителем или задача закрыта по истечении определенного времени. Данный статус необходим для повторного открытия заголовка в том случае, если он не был решен («отрицательное решение»). К примеру, если не удалось устранить уязвимость или меры по ее устранению по какой-либо причине не были приняты.
На решение любой задачи можно потратить сколько угодно времени или вообще отложить выполнение под грузом других дел, ответственный сотрудник может уволиться/заболеть. Однако если инцидент не будет устранен своевременно, это может негативно сказаться на бизнесе. Именно поэтому, каждая задача и каждый заголовок должны иметь заданный срок решения. Он определяется на основе набора различных параметров (класс, тип подразделения, объект, приоритет, линия поддержки), а для задачи — указывается вручную сотрудником, который ее ставит.
За соблюдением сроков выполнения своих задач обязаны следить все самостоятельно. Для того чтобы облегчить сотрудникам эту задачу, существуют автоматические уведомления о просрочке, рассылаемые по электронной почте или в виде новых задач в рамках заголовков. За соблюдением сроков выполнения заголовков обязаны следить первая линия поддержки и руководители. Если складывается ситуация, когда сроки выполнения заголовка не будут соблюдены, первая линия обязана выяснить причины и предпринять действия к недопущению просрочки (напомнить, оповестить, выяснить причины). Руководители должны получать оповещения о фактической просрочке заголовка (например, выше 25% отведенного на решение времени).
В процессе управления инцидентами учитывается и план реагирования, однако в терминологии SIEM подобный план — это сценарии, которые лишь выполняют регистрацию инцидента и первоначальную постановку задач. Системы Service Desk позволяют «вести» инцидент от момента открытия до подтверждения решения, а также подключать шаблонные планы реагирования — заранее заготовленные инструкции, содержащие описание шагов по устранению типового инцидента.
Функциональные возможности управления инцидентами, реализованные в различных SIEM, перечислены в таблице:
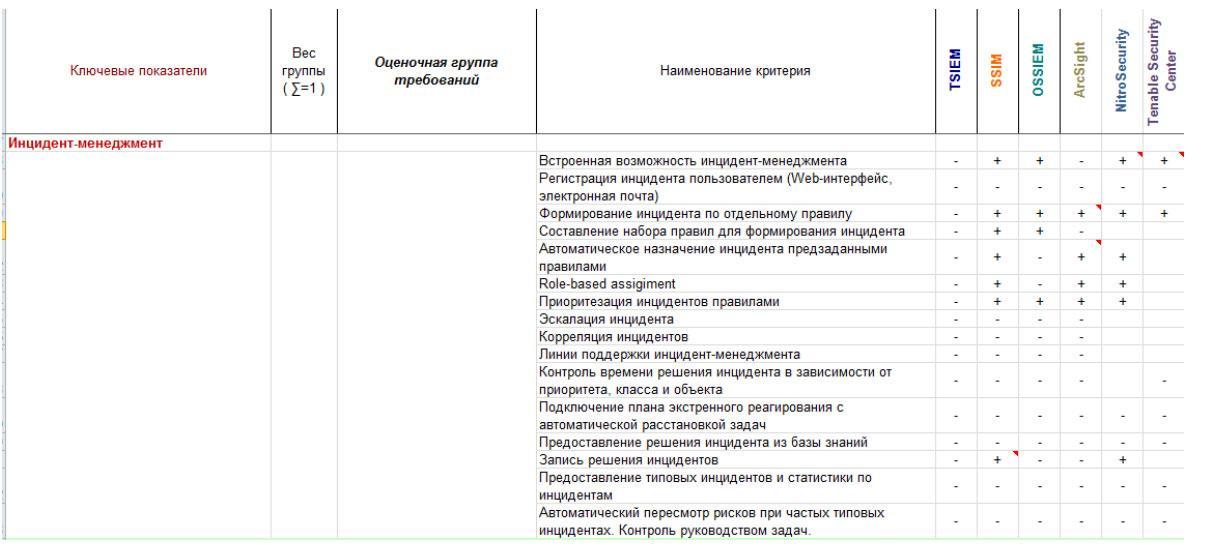
Управление инцидентами полезно и при составлении и обосновании плана минимизации рисков. С его помощью на основании возникающих инцидентов и критичности активов можно оценить слабые места в инфраструктуре. Кроме того, управление инцидентами с автоматическим формированием задач — важно для контроля конфигураций и соответствия стандартам. При ручной обработке формируемых отчетов довольно трудно обнаружить несоответствие какого-либо актива политике безопасности компании. Поэтому возникает проблема оперативного устранения несоответствий. При использовании управления инцидентами задачи на устранение несоответствия будут расставлены автоматически (например, ИТ специалисту, ответственному за этот актив, будет поставлена задача на установку обновления или исправление конфигурации в соответствии с политикой), а экспертам будет предоставлена контрольная информационная задача (чтобы уведомить о найденном несоответствии и предоставить возможность контроля устранения).
При совместном использовании различных систем обработки данных возникает важная проблема разграничения доступа и обеспечения целостности доказательной базы. Как правило, информацию об инциденте и этапах его решения должны иметь далеко не все сотрудники даже внутри одного отдела. Часто именно по этой причине служба ИБ не использует общую с IТ-департаментом систему HelpDesk. Доказательства по инциденту также должны храниться централизовано, а не где-то на файловом сервере.
Итак, все это может вам пригодиться при организации процесса управления инцидентами в ИБ. Вы сможет выстроить необходимые ИБ-процессы компании, упростить предоставление аудиторам статистики при проверках. Кроме того, вам будет легче отчитаться о проделанной работе перед руководством, проще управлять отделом ИБ и распределять нагрузку. Ну и, разумеется, самое главное: управление инцидентами позволит вам минимизировать риски безопасности.
ИНН 7709458650