Спускаем MAYHEM на двоичный код(часть 1)
В данном документе мы представляем MAYHEM, новую систему для автоматического поиска эксплуатируемых багов в двоичных файлах программ.
Краткий обзор. В данном документе мы представляем MAYHEM, новую систему для автоматического поиска эксплуатируемых багов1 в двоичных (т. е., исполняемых) файлах программ. Каждый баг, о котором сообщает MAYHEM, сопровождается рабочим, порождающим шелл эксплоитом. Рабочие эксплоиты гарантируют обоснованность выдаваемой информации и то, что каждое сообщение о баге критично для безопасности и применимо на практике. MAYHEM работает с сырым двоичным кодом без отладочной информации. Чтобы сделать генерацию эксплоитов возможной на двоичном уровне, MAYHEM решает две основных технических задачи: активно управляет путями выполнения без истощения памяти и делает заключения об индексах символической памяти, когда адрес чтения или записи зависит от пользовательских данных. Для решения данных задач мы предлагаем две новых технологии: 1) гибридное символическое выполнение для сочетания онлайнового и оффлайнового (консимволического) выполнения и максимизации сильных сторон обеих техник и 2) индексное моделирование памяти: метод, позволяющий MAYHEM эффективно строить заключения о символической памяти на двоичном уровне. Мы использовали MAYHEM для поиска и демонстрации 29 эксплуатируемых уязвимостей в Linux- и Windows-программах, две из которых не были ранее задокументированы.
I Введение
Багов великое множество. Например, база данных контроля багов Ubuntu Linux насчитывает более 90,000 открытых багов [17]. Однако, баги, которые могут быть эксплуатированы атакующими, обычно являются наиболее серьезными и должны быть исправлены в первую очередь. Таким образом, основной вопрос не в том, имеет ли программа баги, а в том, какие ее баги можно эксплуатировать.
В данном документе мы представляем MAYHEM, надежную систему для автоматического поиска эксплуатируемых багов в двоичных (исполняемых) файлах. MAYHEM создает рабочий, перехватывающий управление эксплоит для каждого заявленного им бага, гарантируя таким образом, что каждый отчет об ошибке применим на практике и критичен для безопасности. Работая с двоичным кодом, MAYHEM позволяет проверять (не)безопасность программ даже при отсутствии доступа к их исходным кодам.
MAYHEM обнаруживает и генерирует эксплоиты на основании базовых принципов, представленных в нашей предыдущей работе, касающейся AEG [2]. На высоком уровне MAYHEM находит эксплуатируемые пути, дополняя символическое выполнение [16] добавочными ограничениями в потенциально уязвимых точках программы. Эти ограничения включают такую информацию, как возможность перенаправления указателя инструкции, возможность размещения атакующего кода в памяти и, в конечном счете, возможность его выполнения. Если результирующая формула выполнима, значит эксплоит возможен.
Главная проблема в генерации эксплоита – изучение достаточного пространства состояний программы для нахождения эксплуатируемых путей. Для решения этой проблемы MAYHEM строится на четырех основных принципах:
- система должна быть способна выполняться произвольно долгое время (в идеале бесконечное) без превышения заданного лимита ресурсов (особенно памяти),
- чтобы максимизировать производительность, система не должна повторять сделанную работу,
- система не должна отбрасывать работу – нужно, чтобы результаты предыдущего анализа системы могли быть использованы в последующих запусках,
- Система должна иметь возможность строить заключения о символической памяти, когда адрес чтения или записи зависит от введенных пользователем данных.
Обработка адресов памяти существенна для эксплуатации реальных багов. Принцип 1 необходим для исследования сложных приложений, поскольку большинство нетривиальных программ будут содержать потенциально бесконечное число путей выполнения.
Текущие подходы к симолическому выполнению, например, CUTE [26], BitBlaze [5], KLEE [9], SAGE [13], McVeto [27], AEG [2], S2E [28] и прочие [3], [21], не удовлетворяют всем вышеперечисленным требованиям. Концептуально существующие выполнители можно разделить на две основные категории: оффлайновые выполнители, которые непосредственно (или конкретно) запускают определенный путь выполнения (оффлайновые выполнители также называются основанными на трассировке или консимволическими, пример — SAGE) и онлайновые выполнители, которые пытаются запустить все возможные пути за один прогон системы (например, S2E). Ни онлайновые, ни оффлайновые выполнители не удовлетворяют принципам 1-3. Кроме того, большинство движков символического выполнения не делают логических заключений о символической памяти, а, значит, не удовлетворяют принципу 4.
Оффлайновые выполнители [5], [13] за один раз делают заключение о единственном пути выполнения. Принцип 1 удовлетворяется путем итеративного выбора очередного исследуемого пути. Каждый запуск системы независим от остальных и, таким образом, результаты предыдущих запусков могут быть немедленно использованы, что соответствует принципу 3. Однако, оффлайновые выполнители не соответствуют принципу 2. Каждый запуск системы требует перезапуска программы с самого начала. Одни и те же инструкции необходимо раз от раза запускать для каждой трассировки выполнения. Наши экспериментальные результаты показывают, что данное повторное выполнение может быть очень затратным (см. §VIII).
Онлайновое символическое выполнение [9], [28] разветвляется (создает новый поток выполнения) в каждой точке ветвления программы. Предыдущие инструкции никогда не выполняются снова, но постоянное разветвление нагружает память, замедляя движок выполнения по мере увеличения количества ветвей. В результате отсутствует продвижение вперед, и потому принципы 1 и 3 не выполняются. Некоторые выполнители вроде KLEE перестают ветвиться для избежания замедления из-за загрузки памяти. Данные выполнители удовлетворяют принципу 1, но не принципу 3 (интересующие пути могут быть отброшены).
MAYHEM соединяет оба этих метода в гибридном символическом выполнении, в ходе которого происходит переключение между онлайновым и оффлайновым выполнением. Гибридное выполнение действует как менеджер памяти в ОС, за исключением того, что оно спроектировано для эффективной выгрузки символических выполнителей. Когда память достаточно загружается, движок гибридного выполнения выбирает активный поток выполнения и сохраняет его текущее состояние выполнения и формулу пути. Поток позже восстанавливается путем восстановления формулы и непосредственного выполнения программы до сохраненного состояния выполнения, после чего он продолжает выполнение. Кэширование формул путей предотвращает повторное символическое выполнение инструкций ( недостаток оффлайнового выполнения), в то время как память управляется более эффективно, чем при онлайновом выполнении.
MAYHEM также предлагает методы для эффективного составления заключений о символической памяти. Обращение к символической памяти происходит, когда адрес чтения или записи зависит от введенных данных. Символические указатели очень распространены на двоичном уровне, и для генерирования перехватывающих управление эксплоитов необходимо делать выводы о них. На самом деле наши эксперименты показали, что 40% сгенерированных эксплоитов были бы не возможны из-за ограничений конкретизации (§VIII). Для преодоления этой проблемы MAYHEM использует индексную модель памяти (§V), чтобы избежать ограничения индекса, где это возможно.
Полученные результаты обнадеживают. Хотя остается большое пространство для новых исследований по данной теме, MAYHEM уже генерирует эксплоиты для нескольких уязвимостей: переполнения буфера, перезаписи указателя функции и уязвимостей строк формата для 29 различных программ. MAYHEM также демонстрирует ускорение в 2-10 раз по сравнению с оффлайновым символическим выполнением, не имея ограничений памяти онлайнового выполнения.
В целом MAYHEM вносит следующий вклад:
- Гибридное выполнение. Мы вводим новую схему для символического выполнения, которую мы назвали гибридным символическим выполнением. Она позволяет нам найти лучший баланс между требованиями скорости и использования памяти. Гибридное выполнение позволяет MAYHEM исследовать множество путей быстрее, чем существующие методы (см. §IV).
- Индексное моделирование памяти. Мы предлагаем индексную модель памяти как практический подход к операциям с символическими индексами на двоичном уровне (см. §V).
- Исключительно двоичная генерация эксплоитов. Мы представляем первую полностью двоичную систему поиска эксплуатируемых багов, которая демонстрирует эксплуатируемость путем генерации рабочих перехватывающих управление эксплоитов.
II. Обзор MAYHEM
В данном разделе мы опишем общую архитектуру MAYHEM, сценарий использования и проблемы поиска эксплуатируемых багов. Мы используем HTTP-сервер, orzHttpd [1] (показанный на рисунке 1a), чтобы выделить основные проблемы и показать, как работает MAYHEM. Заметьте, что мы показываем исходные коды для простоты и ясности, MAYHEM работает с двоичными кодами.


(a) Фрагмент кода.
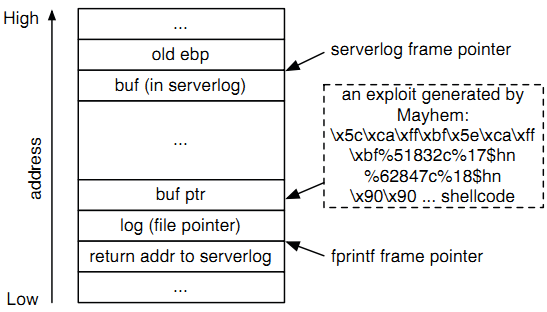

(b) Диаграмма стека уязвимой программы.
Рисунок 1: уязвимость orzHttpd
В orzHttpd каждое HTTP-соединение передается в функцию http_read_request. Данная функция, в свою очередь, вызывает static_buffer_read как часть цикла на строке 29, чтобы получить строку запроса пользователя. Пользовательские данные помещаются в 4096-байтный буфер conn->read_buf.buf на строке 30. Каждое считывание увеличивает переменную conn->read_buf.used на число считанных до текущего момента байтов, чтобы предотвратить переполнение буфера. Цикл считывания продолжается, пока не будет встречена последовательность \r\n\r\n, что проверяется на строке 34. Если пользователь передает более 4096 байтов без символа завершения строки HTTP, цикл считывания прерывается и сервер возвращает код ошибки 400 (строка 41). Каждый запрос, выполненный без ошибки, логируется с помоью функции serverlog.
Уязвимость сама по себе находится в функции serverlog, которая вызывает fprintf с определяемой пользователем строкой формата (то есть, HTTP-запросом). Функции с переменным числом аргументов вроде fprintf используют строку формата для определения того, как перемещаться между аргументами, расположеными в стеке. Эксплоит для данной уязвимости работает путем подачи строк формата, которые заставляют fprintf идти по стеку к данным, контролируемым пользователем. Эксплоит затем использует дополнительные спецификаторы формата, чтобы записать информацию по желаемому адресу [22]. Рисунок 1b показывает разметку стека orzHttpd в момент обнаружения уязвимости строки формата. Здесь происходит вызов fprintf с аргументом, являющимся контролируемой пользователем строкой.
Мы выделим несколько ключевых моментов для нахождения эксплуатируемых багов:
Имеют значение низкоуровневые детали: Определение эксплуатируемости требует составления выводов о низкоуровневых деталях вроде адресов возврата и указателей стека. Это мотивировало нас сконцентрироваться на методах, работающих на двоичном уровне.
Существует огромное количество ветвей выполнения: В рассмотренном примере каждая встреча с оператором if порождает новую ветвь, что может привести к экспоненциальному росту количества ветвей. Кроме того, количество ветвей во многих фрагментах кода связано с размером входных данных. Например, memcpy разворачивает цикл, создавая новую ветвь для символического выполнения на каждой его итерации. Больший объем данных означает большее количество условий, ветвей и усложнение масштабирования. К сожалению, большинство эксплоитов не являются короткими строками, например, типичные эксплоиты для переполнения буфера имеют длину порядка сотен или тысяч байтов.
Чем больше ветвей проверено, тем лучше: Чтобы получить в рассмотренном примере эксплуатируемый баг в fprintf, MAYHEM нужно мысленно пройти цикл, прочитать входные данные, создать ветвь интерпретатора для каждой возможной ветви выоплнения и проверить ошибки. Без грамотного управления ресурсами движок может завязнуть в слишком большом количестве потоков символического выполнения из-за огромного количества возможных ветвей.
Запускать так много, как это вовзможно: Символическое выполнение медленнее по сравнению с обычным выполнением, поскольку семантика инструкций симулируется программно. В orzHttpd миллионы инструкций производят настройку базового сервера прежде чем атакующий сможет хотя бы подключиться к сокету. Мы хотим выполнить эти инструкции непосредственно и лишь затем переключиться на символическое выполнение.
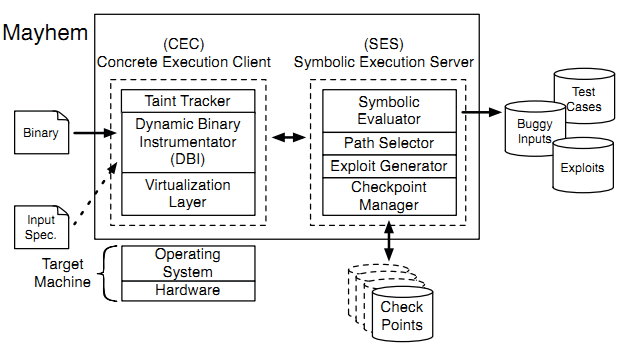

Рисунок 2: устройство MAYHEM
Устройство MAYHEM для нахождения эксплуатируемых багов показано на рисунке 2. Пользователь запускает MAYHEM следующей строкой:
mayhem -sym-net 80 400 ./orzhttpd
Данная Командная строка указывает MAYHEM символически запустить orzHttpd и открыть сокеты на порту 80 для получения символических 400-байтовых пакетов. Все остальные шаги для создания эксплоита выполняются автоматически.
MAYHEM состоит из двух одновременно действующих процессов: Concrete Executor Client (CEC, Клиент непосредственного выполнения), который запускает код нативным образом на процессоре, и Symbolic Executor Server (SES, Сервер символического выполнения). Оба компонента показаны на рисунке 2. На высоком уровне CEC выполняется на целевой системе, а SES на любой платформе, ожидая соединений от CEC. CEC принимает двоичную программу с потенциальными символическими источниками (спецификациями входных данных) в качестве входных данных и начинает обмен информацией с SES. SES символически запускает блоки, которые посылает CEC и выводит несколько типов тест-кейсов, включая нормальные тест-кейсы, аварийные завершения и эксплоиты. Вот шаги, которые делает MAYHEM для поиска уязвимого кода и генерации эксплоитов:
- Аргумент --sym-net 80 400 говорит MAYHEM производить символическое выполнение данных, полученных на порту 80. Фактически это определяет, какие источники потенциально попадают под контроль атакующего. MAYHEM может обрабатывать данные атакующего из переменных окружения, файлов и сети.
- CEC загружает уязвимую программу и соединяется с SES для инициализации всех источников символических входных данных. После инициализации MAYHEM запускает двоичный файл непосредственно на процессоре с помощью CEC. В ходе выполнения CEC инструментирует код и производит динамический taint-анализ [23]. Наш движок taint-трассировки проверяет, содержит ли блок тентированные инструкции, где блок – последовательность инструкций, заканчивающаяся условным переходом или инструкцией вызова.
- Когда CEC встречает тентированное условие ветвления или цель перехода, он приостанавливает непосредственное выполнение. Тентированный переход означает, что цель может зависеть от входных данных атакующего. CEC посылает соответствующие инструкции SES, и SES определяет, какие из ветвей выполнения являются достижимыми. CEC позднее получет от SES следующую ветвь, подлежащую исследованию.
- SES, выполняющийся параллельно с CEC, получает поток тентированных инструкций от CEC. SES представляет эти инструкции в терминах промежуточного языка (§III) и символически выполняет их. CEC предоставляет конкретные значения, когда это необходимо, например, когда инструкция производится над символическим операндом и конкретным операндом. SES поддерживает два типа формул:
Формула пути: формула пути отражает ограничивающие условия для достижения определенной строки кода. Каждый условный переход добавляет новое ограничение на входные данные. Например, строки 32-33 создают два новых пути: первый ограничен условием, что считанные данные заканчиваются на \r\n\r\n, при этом выполняется строка 35; во втором входные данные не заканчиваются на \r\n\r\n и выполняется строка 28.
Формула эксплуатируемости: формула эксплуатируемости определяет, может ли атакующий получить контроль над указателем инструкции и запустить полезную нагрузку.
- Когда MAYHEM попадает на тентированную ветвь, SES решает, нужно ли разветвить выполнение путем запроса к SMT-решателю. Если разветвление необходимо, все новые ветви посылаются селектору путей для расстановки приоритетов. После выбора пути SES уведомляет CEC об изменении и восстанавливает соответствующее состояние выполнения. Если достигнут предел системных ресурсов, тогда менеджер контрольных точек начинает генерировать контрольные точки вместо разветвления выполнителей (§IV). В конце процесса для завершенных выполнителей генерируются тест-кейсы и SES информарует CEC о том, с каких контрольных точек следует продолжить выполнение.
- В ходе выполнения SES переключает контекст между выполнителями, и CEC сохраняет/восстанавливает предоставленное состояние выполнения и продолжает выполнение. Для этого CEC поддерживает уровень виртуализации, чтобы обрабатывать взаимодействие программы с системой и запоминать/восстанавливать разные состояния выполнения программы. (§IV-C).
- Когда MAYHEM обнаруживает тентированную инструкцию перехода, он строит формулу эксплуатируемости и запрашивает SMT-решатель, чтобы проверить, является ли она выполнимой. Подходящие для выполнения формулы входные данные будут по своей конструкции эксплоитом. Если для тентированной инструкции ветвления не было найдено эксплоита, SES продолжает изучать пути выполнения.
- Вышеприведенные шаги выполняются в каждой ветви либо до нахождения эксплуатируемого бага, либо до достижения определенного пользователем максимального времени выполнения, либо до исчерпывания всех путей.
III. Предварительные сведения
Представление двоичных файлов в нашем языке. Базовое символическое выполнение выполняется над ассемблерными инструкциями по мере их выполнения. Как ранее объяснялось, в системе в целом поток инструкций исходит от CEC. Здесь мы будем предполагать, что они просто даны нам. Мы использовали BAP [15], фреймворк с открытым исходным кодом для анализа двоичных файлов, чтобы конвертировать инструкции x86-ассемблера в промежуточный язык (ПЯ), подходящий для символического выполнения. Для каждой запускаемой инструкции символический выполнитель преобразует инструкцию в промежуточный язык BAP. SES производит символическое выполнение промежуточного языка напрямую, вводя дополнительные ограничения, связанные с полезными нагрузками определенных атак, и посылает формулу SMT-решателю для проверки выполнимости. Например, ПЯ для инструкции ret состоит из двух утверждений: того, которое загружает адрес из памяти, и того, которое переходит по этому адресу.
Символическое выполнение в ПЯ. При непосредственном выполнении программе на вход дается конкретное значение, она выполняет операторы для производства новых значений и завершается с итоговыми значениями. В символическом выполнении мы не ограничиваем выполнение одним значением, а вместо этого предоставляем символическую входную переменную, которая отражает набор всех возможных входных значений. Когда символическое выполнение натыкается на ветвление, оно рассматривает два возможных мира: того, где произошел переход по ветви, соответствующей истинному значению логического выражения, и того, где произошел переход, соответствующий ложному значению. Это делается путем разветвления интерпретатора на каждую из ветвей и добавления утверждения, которому должен удовлетворять контролер ветви. Итоговая формула инкапсулирует все условия ветвей, которые должны быть выполнены для следования по данному пути выполнения и потому называется формулой или предикатом пути.
В MAYHEM каждый тип оператора ПЯ имеет соответствующее правило символического выполнения. Утверждения ПЯ немедленно добавляются к формуле. Операторы условного перехода создают две формулы: одну, где условное выражение истинно и происходит переход по истинной ветви, и одну, где оно ложно и происходит переход по ложной ветви. Например, если у нас уже есть формула f и выполняется cjmp e1, e2, e3, где e1 – условие ветвления, а e2 и e3 – цели переходов, то мы создаем две формулы:
f ∧ e1 ∧ FSE(pathe2)
f ∧ ¬e1 ∧ FSE(pathe3)
Здесь FSE означает forward symbolic execution (прямое символическое выполнение) цели перехода. Из-за ограничений размеров статьи мы даем точную семантику в сопутствующей документации [15], [24].
Примечания
1 Здесь используется менее формальный, но более емкий термин "баг" вместо "программная ошибка"
2 Заметим, что термин "контрольная точка" отличается от "зерна" оффлайнового выполнения, которое является лишь конкретными входными данными.
Ссылки
[1] "Orzhttpd, a small and high performance http server," http://code.google.com/p/orzhttpd/.
[2] T. Avgerinos, S. K. Cha, B. L. T. Hao, and D. Brumley, "AEG: Automatic exploit generation," in Proc. of the Network and Distributed System Security Symposium, Feb. 2011.
[3] D. Babi´ c, L. Martignoni, S. McCamant, and D. Song, "Statically-Directed Dynamic Automated Test Generation," in International Symposium on Software Testing and Analysis. New York, NY, USA: ACM Press, 2011, pp. 12–22.
[4] G. Balakrishnan and T. Reps, "Analyzing memory accesses in x86 executables." in Proc. of the International Conference on Compiler Construction, 2004.
[5] "BitBlaze binary analysis project," http://bitblaze.cs.berkeley.edu, 2007.
[6] BitTurner, "BitTurner," http://www.bitturner.com.
[7] D. Brumley, P. Poosankam, D. Song, and J. Zheng, "Automatic patch-based exploit generation is possible: Techniques and implications," in Proc. of the IEEE Symposium on Security and Privacy, May 2008.
[8] J. Caballero, P. Poosankam, S. McCamant, D. Babic, and D. Song, "Input generation via decomposition and re-stitching: Finding bugs in malware," in Proc. of the ACM Conference on Computer and Communications Security, Chicago, IL, October 2010.
[9] C. Cadar, D. Dunbar, and D. Engler, "KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs," in Proc. of the USENIX Symposium on Operating System Design and Implementation, Dec. 2008.
[10] M. Costa, M. Castro, L. Zhou, L. Zhang, and M. Peinado, "Bouncer: Securing software by blocking bad input," in Symposium on Operating Systems Principles, Oct. 2007.
[11] J. R. Crandall and F. Chong, "Minos: Architectural support for software security through control data integrity," in Proc. of the International Symposium on Microarchitecture, Dec. 2004.
[12] L. M. de Moura and N. Bjørner, "Z3: An efficient smt solver," in TACAS, 2008, pp. 337–340.
[13] P. Godefroid, M. Levin, and D. Molnar, "Automated whitebox fuzz testing," in Proc. of the Network and Distributed System Security Symposium, Feb. 2008.
[14] S. Heelan, "Automatic Generation of Control Flow Hijacking Exploits for Software Vulnerabilities," Oxford University, Tech. Rep. MSc Thesis, 2002.
[15] I. Jager, T. Avgerinos, E. J. Schwartz, and D. Brumley, "BAP: A binary analysis platform," in Proc. of the Conference on Computer Aided Verification, 2011.
[16] J. King, "Symbolic execution and program testing," Commu- nications of the ACM, vol. 19, pp. 386–394, 1976.
[17] Launchpad, https://bugs.launchpad.net/ubuntu, open bugs in Ubuntu. Checked 03/04/12.
[18] C.-K. Luk, R. Cohn, R. Muth, H. Patil, A. Klauser, G. Lowney, S. Wallace, V. J. Reddi, and K. Hazelwood, "Pin: Building customized program analysis tools with dynamic instrumentation," in Proc. of the ACM Conference on Programming Language Design and Implementation, Jun. 2005.
[19] R. Majumdar and K. Sen, "Hybrid concolic testing," in Proc. of the ACM Conference on Software Engineering, 2007, pp. 416–426.
[20] L. Martignoni, S. McCamant, P. Poosankam, D. Song, and P. Maniatis, "Path-exploration lifting: Hi-fi tests for lo-fi emulators," in Proc. of the International Conference on Architectural Support for Programming Languages and Operating Systems, London, UK, Mar. 2012.
[21] A. Moser, C. Kruegel, and E. Kirda, "Exploring multiple execution paths for malware analysis," in Proc. of the IEEE Symposium on Security and Privacy, 2007.
[22] T. Newsham, "Format string attacks," Guardent, Inc., Tech. Rep., 2000.
[23] J. Newsome and D. Song, "Dynamic taint analysis for automatic detection, analysis, and signature generation of exploits on commodity software," in Proc. of the Network and Distributed System Security Symposium, Feb. 2005.
[24] E. J. Schwartz, T. Avgerinos, and D. Brumley, "All you ever wanted to know about dynamic taint analysis and forward symbolic execution (but might have been afraid to ask)," in Proc. of the IEEE Symposium on Security and Privacy, May 2010, pp. 317–331.
[25] E. J. Schwartz, T. Avgerinos, and D. Brumley, "Q: Exploit hardening made easy," in Proc. of the USENIX Security Symposium, 2011.
[26] K. Sen, D. Marinov, and G. Agha, "CUTE: A concolic unit testing engine for C," in Proc. of the ACM Symposium on the Foundations of Software Engineering, 2005.
[27] A. V. Thakur, J. Lim, A. Lal, A. Burton, E. Driscoll, M. Elder, T. Andersen, and T. W. Reps, "Directed proof generation for machine code," in CAV, 2010, pp. 288–305.
[28] G. C. Vitaly Chipounov, Volodymyr Kuznetsov, "S2E: A platform for in-vivo multi-path analysis of software systems," in Proc. of the International Conference on Architectural Support for Programming Languages and Operating Systems, 2011, pp. 265–278.
Если вам нравится играть в опасную игру, присоединитесь к нам - мы научим вас правилам!