
Введение в перехват API для системы команд x86
В данном посте представлены способы перехвата API для системы команд x86.
Краткий обзор
В данном посте представлено несколько способов перехвата API для системы команд x86.В последующих параграфах мы введем читателя в перехват API: то, что мы можем сделать с его помощью, то, почему он полезен, и в его основные формы. После представления простых методов перехвата API мы охватим некоторые менее известные и используемые (если вообще используемые) методы, которые однажды могут пригодиться, а также некоторые техники, которые стоит иметь ввиду при использовании любых методов перехвата.
В завершение мы познакомим читателя с кодом, который ежедневно используется для анализа тысяч образцов вредоносного ПО.
Введение
Следующий фрагмент текста – краткое объяснение перехвата, взятое из Википедии [1].В программировании термин перехват (hooking) охватывает ряд методов, используемых для изменения или дополнения поведения операционной системы, приложений или других программных компонентов путем перехвата вызовов функций, сообщений или событий, передаваемых между программными компонентами. Код, который обрабатывает подобные перехваченные вызовы функций, события или сообщения, называется перехватчиком (hook).
Итак, мы установили, что перехват позволяет нам изменять поведение существующих программ. Перед тем, как двинуться дальше, мы представим краткий список примеров использования перехвата.
- Профилирование: Насколько быстро выполняются определенные вызовы функций?
- Мониторинг: Послали ли мы корректные параметры функции X?
- ..?
Более полный список примеров использования перехвата функций можно найти здесь [1] [2].
Данный список должен свидетельствовать о полезности перехвата функций. Теперь настало время перейти к перехвату функций как таковому.
Просим читателя заметить, что данный пост не охватывает точки останова, перехват IAT и т. д., так как эти темы заслуживают отдельного поста.
Базовый перехват API
Наиболее простой способ перехвата – вставка инструкции перехода (jump). Как вы уже знаете (а может и не знаете), инструкции системы команд x86 имеют переменную длину (т.е., инструкция может иметь длину в байтах от 1 до 16). Инструкция безусловного перехода имеет длину 5 байтов. Один байт представляет опкод, оставшиеся четыре представляют относительное 32-битное смещение. (Отметим, что существует также инструкция безусловного перехода, которая содержит лишь восьмибитное относительное смещение, но в данном примере использовать ее мы не будем).Итак, если у нас есть две функции – A и B, как мы перенаправим выполнение с функции A в функцию B? Очевидно, что мы используем инструкцию перехода, поэтому осталось лишь вычислить правильное относительное смещение.
Предположим, что функция A расположена по адресу 0×401000, а функция B – по адресу 0×401800. Далее мы определим требуемое относительное смещение. Разница между адресами данных функций составляет 0×800 байт, и мы хотим перейти из функции A в функцию B, так что нам пока не нужно беспокоиться об отрицательных смещениях.
Дальше следует хитрый момент. Предположим, что мы уже записали нашу инструкцию перехода по адресу 0×401000 (функции A), и что данная инструкция выполняется. CPU при этом сделает следующее: сначала он добавит длину инструкции к Указателю на Инструкцию [3] (или Программному Счетчику). Длина инструкции перехода равна пяти байтам, как мы установили ранее. После этого к Указателю на Инструкцию добавляется относительное смещение. Другими словами, CPU вычисляет новое значение Указателя на Инструкцию следующим образом:
instruction_pointer = instruction_pointer + 5 + relative_offset;
Поэтому для вычисления относительного смещения нам нужно переписать формулу в следующем виде:
relative_offset = function_B - function_A - 5;
Мы вычитаем 5, поскольку это длина инструкции перехода, которую CPU добавляет при запуске данной инструкции, а function_A is вычитается из function_B, так как это относительный переход. Разница между адресами функций равна, как мы помним, 0×800 байтам. (Например, если мы забудем вычесть function_A, то CPU перейдет по адресу 0×401800 + 0×401000 + 5, что, очевидно, нежелательно).
На языке ассемблера перенаправление из функции A в функцию B будет выглядеть примерно так.

До внедрения перехватчика в начале функции можно видеть несколько исходных инструкций. После внедрения они перезаписываются инструкцией jmp. Первые три исходные инструкции занимают 6 байт вместе взятые (т. е. можно видеть, что инструкция push ebx расположена по адресу 0×401006). Наша инструкция перехода использует только пять байтов, что оставляет нам один дополнительный байт. Мы перезаписали этот байт инструкцией nop (инструкция, не делающая ничего).
Инструкции, которые мы перезаписали, мы называем украденными байтами, в следующем параграфе мы рассмотрим их более подробно.
Трамплины
Итак, мы перехватили функцию A и перенаправили ее на функцию B. Однако, что если мы хотим выполнить исходную функцию A, не выполняя перехватчик? Для этого нам нужно создать так называемую функцию-трамплин.Следующий фрагмент кода показывает простой пример использования трамплина для запуска исходной функции из перехваченной функции. В нем function_A_trampoline обозначает трамплин к функции A (функции, которая была перехвачена).
// this is the hooked function void function_A(int value, int value2);
// this is the Trampoline with which we can call
// function_A without executing the hook void (*function_A_trampoline)(int value, int value2);
// this is the hooking function which is executed
// when function_A is called void function_B(int value, int value2) {
// alter arguments and execute the original function function_A_trampoline(value + 1, value2 + 2); }
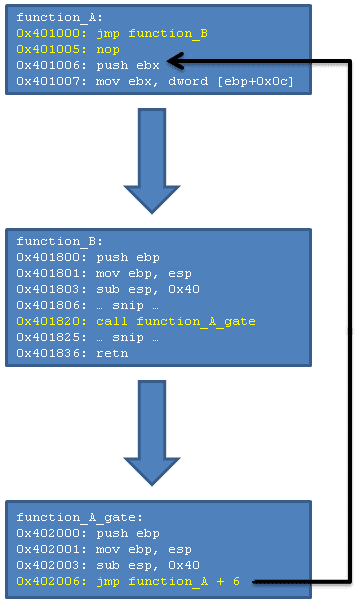
В примере перехвата, который мы только что обсудили, мы перезаписали первые пять байт функции A. Чтобы запустить исходную функцию без перехватчика, нам понадобится запустить байты, которые мы перезаписали при установке перехватчика, а затем перейти по адресу, на несколько байт большему, чем адрес функции A (чтобы пропустить код перехватчика). Это в точности то, что происходит в вышеуказанном фрагменте кода, но в коде на языке C вы этого не видите из-за относительно высокой абстракции. В любом случае, картинки говорят больше, чем тысяча слов, так что… вот изображение, которое показывает устройство трамплина.
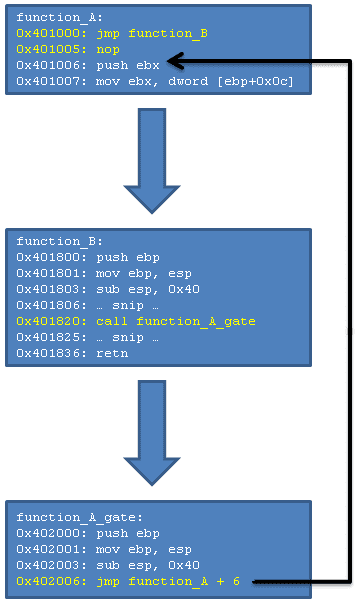
На изображении вы видите следующий поток выполнения: запускается функция A, выполняется перехватчик, передавая тем самым управление функции B. Функция B выполняет некие действия, но на адресе 0×401820 она хочет выполнить исходную версию функции A (без перехватчика), где и приходит на помощь трамплин. Про трамплин можно написать множество слов, но одно изображение объясняет его полностью. Трамплин состоит из двух частей: исходных инструкций и перехода на ту часть функции A, которая следует за перехватчиком. Если вы вернетесь к изображению из раздела Базовый перехват API, вы увидите, что перезаписанные перехватчиком инструкции теперь располагаются в трамплине. Переход в трамплине вычисляется по указанной ранее формуле, однако, в данном случае адреса и смещения немного отличаются, так что формула принимает следующий вид:
relative_offset = (function_A_trampoline + 6) - (function_A + 6) - 5;
Отметим, что мы переходим с адреса 0×402006 (function_A_trampoline + 6) на 0×401006 (function_A + 6). Данные адреса можно проверить по рассмотренному ранее изображению. Ничего особенного, кроме того факта, что у нас получилось отрицательное смещение. Но это не доставит нам проблем (CPU сделает всю грязную работу по корректному представлению отрицательного относительного смещения).
Вот в общем-то и все, что нужно знать о базовом перехвате API, так что дальше мы обсудим некоторые более продвинутые методы. В одном из следующих разделов, Построение трамплинов, мы более подробно рассмотрим процесс создания трамплинов.
Продвинутые методы перехвата
Мы рассмотрели базовый метод перехвата API и >трамплины. Однако, поскольку базовый метод перехвата так прост (всего лишь вставка инструкции перехода), его очень легко обнаружить. Поэтому мы также обсудим несколько более продвинутых методов. Помимо этого, мы также введем читателя в перехват методов классов C++.Обнаружение перехвата для примера, рассмотренного в разделе «Базовый перехват API», можно осуществить так:
if(*function_A == 0xe9) { printf("Hook detected in function A.\n"); }
Суть в том, что 0xe9 – опкод инструкции безусловного перехода с 32-битным относительным смещением. ПО, которое мы перехватываем, может обнаружить или не обнаружить подобный перехватчик. В любом случае, далее мы обсудим разные методы, которые пытаются обойти подобные алгоритмы обнаружения. (Заметим, что программы вроде GMER [4] обнаруживают все типы методов перехвата, так как сверяют виртуальную память с физическим образом на диске).
Метод I: вставка Nop в начало
Это действительно простой обходной путь, который работает с любым из методов, которые мы рассмотрим.По сути, вместо записи по адресу функции A, например, инструкции перехода, мы сначала запишем инструкцию nop (не делающую ничего), за которой уже последует функция перехода. Применяя данную технику, имейте в виду, что инструкция перехода теперь будет располагаться по адресу 0×401001 (function_A + 1), и это изменит относительное смещение на единицу.
Вот изображение, иллюстрирующую данную технику.
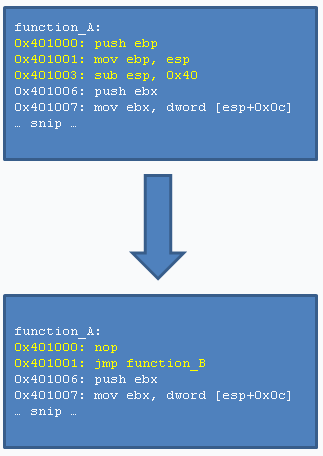
Поскольку первая инструкция функции A теперь – nop (а не jmp), чтобы обнаружить перехватчик, нам нужно переписать метод обнаружения подобным образом:
unsigned char *addr = function_A; while (*addr == 0x90) addr++; if(*addr == 0xe9) {
printf("Hook detected in function A.\n"); }
По существу, он пропускает любое количество последовательных инструкций nop, имеющих опкод 0×90, и проверяет присутствие инструкции перехода после всей цепочки nop-ов.
Метод II: Push/Retn
Инструкция push кладет 32-битное значение в стек, а retn выталкивает 32-битный адрес из стека в Указатель на Инструкцию (другими словами, она начинает выполнение инструкций, расположенных по адресу, лежащему на вершине стека).Этот метод занимает 6 байт и выглядит следующим образом. Отметим, что инструкция push принимает абсолютный адрес, а не относительный.
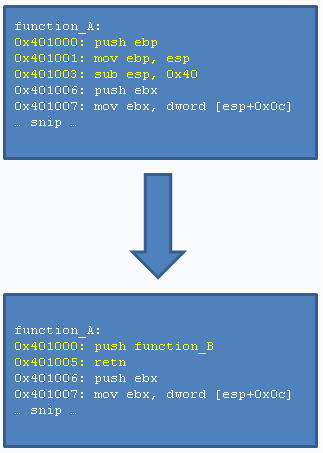
Обнаружение данного метода может выглядеть так, как показано ниже. Однако, учтите, что помещение nop-инструкций в начало или между инструкциями push и retn не позволит данному коду обнаружить перехватчик.
unsigned char *addr = function_A; if(*addr == 0x68 && addr[5] == 0xc3) {
printf("Hook detected in function A.\n"); }
Как вы наверное уже догадались, 0×68 – опкод инструкции push, а 0xc3 – опкод инструкции retn.
Метод III: Числа с плавающей запятой
В то время как рассмотренные до сих пор методы фокусировались на обычных x86-инструкциях, существуют также некоторые интересные методы, включающие операции над числами с плавающей запятой.Данный пример похож на метод push/retn: мы помещаем в стек фиктивное значение, которое затем перезаписываем настоящим адресом, после чего выполняем retn.
Примечательна же техника тем, что вместо хранения адреса перехода в виде 32-битного значения мы храним его в виде 64-битного числа с плавающей запятой. Далее мы считываем его инструкцией fld и преобразуем в 32-битное значение инструкцией fistp.
Следующее изображение демонстрирует данную технику. Перехватчик имеет размер 11 байт, что немного больше, чем для предыдущих методов, но это не так страшно. Также заметим, что floating_point – указатель на 64-битное число с плавающей запятой, которое равно адресу нашей перехватывающей функции (функции B).

Получить нужное значение с плавающей точкой довольно просто:
double floating_point_value = (double) function_B;
Функция B здесь, как и в других примерах,– наша перехватывающая функция.
Вызов исходной функции делается через трамплин, как и в других методах. (Трамплин в данном случае должен содержать как минимум инструкции, которые находятся в первых одиннадцати байтах функции).
Очевидно, что это только верхушка айсберга: существует множество операций с плавающей точкой, которые подойдут в данной ситуации. Например, вы можете вычислять адрес перехватывающей функции путем умножения значения на число π (которое можно получить с помощью инструкции fldpi).
Метод IV: MMX/SSE
Данные техники похожи на перехват с использованием чисел с плавающей запятой. Однако, вместо использования чисел с плавающей запятой, здесь мы будем использовать расширения MMX/SSE системы команд x86.Обе техники используют, как и метод с плавающей запятой, инструкции push/retn. Первый метод использует MMX-инструкции, в частности инструкцию movd. Она, как и инструкция fistp, позволяет прочитать значение из памяти и сохранить значение в стеке. Второй метод с SSE-инструкциями также использует инструкцию movd. Единственное различие между этими двумя методами в том, что MMX-инструкции оперируют 64-битными регистрами, тогда как SSE оперируют 128-битными регистрами. (Хотя в нашем случае это неважно, поскольку инструкция movd позволяет читать и записывать 32-битные значения).
Раз эти техники похожи на метод с плавающей запятой, за исключением используемых инструкций, то для них не будет отдельного рисунка (в статье и так их предостаточно).
Метод V: косвенный переход
Косвенный переход – это переход по адресу, который лежит в памяти по указанному адресу. В разделе Базовый перехват API мы рассмотрели прямой относительный переход. Косвенные переходы больше похожи на метод Push/Retn.Косвенный переход имеет длину 6 байтов, и пример перехвата выглядит так:

Заметим, что hook_func_ptr обозначает адрес, по которому находится адрес нашей перехватывающей функции (т. е. B).
Метод VI: инструкция Call
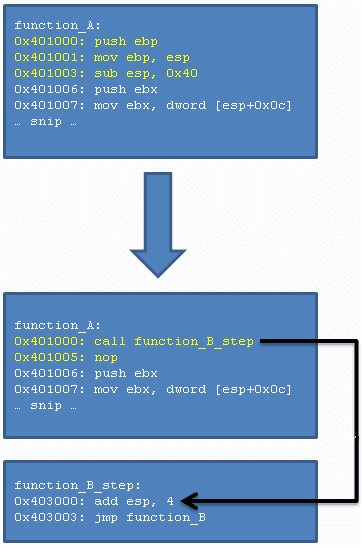
Тогда как все предыдущие методы перехвата совершали переход прямо в перехватывающую функцию (т. е. функцию B), для данного метода перехвата нужен дополнительный шаг. Это из-за того, что инструкция call переходит по заданному адресу после помещения адреса возврата в стек (адрес возврата равен текущему значению указателя на инструкцию, увеличенному на длину инструкции call).Поскольку в стеке теперь появился дополнительный адрес возврата, сначала нам нужно вытолкнуть этот адрес из стека, иначе стек будет поврежден (перехватывающая функция считает из стека некорректные аргументы, т. к. указатель стека будет неправильным). Мы вытолкнем этот адрес из стека путем добавления 4 к указателю стека (когда адрес кладется в стек, указатель стека сначала уменьшается на 4, затем данный адрес записывается туда, куда указывает обновленный указатель стека). После выталкивания адреса из стека мы переходим на перехватывающую функцию.
Данная техника работает как для прямого, так и для непрямого варианта инструкции call. Далее следует рисунок, иллюстрирующий рассмотренный метод.
Другие методы
Помимо обсуждавшихся до сих пор, существует несколько других методов со специфическими назначениями. Они могут пригодиться в некоторых ситуациях.Другие методы I: Hotpatching
Это метод, специфичный для программ, скомпилированных компилятором Microsoft Visual C++ Compiler с включенным флагом Hotpatching (это справедливо для множества dll вроде user32.dll).Если функция допускает так называемый Hotpatch, она уже определенным образом подготовлена для перехвата. Первой инструкцией функции в этом случае будет mov edi, edi (два байта длиной), а перед собственно функцией расположены 5 nop-инструкций. Это позволяет разместить инструкцию близкого перехода (ту, что имеет длину два байта и принимает 8-битное относительное смещение) по адресу собственно функции (перезаписав инструкцию mov edi, edi) и обычную инструкцию перехода с 32-битным относительным смещением на место nop-инструкций.
Вот и все, что касается данной техники. Отметим, что вместо хотпатчинга подобной функции возможно также выполнить перехват одним из ранее рассмотренных методов, поместив перехватчик по адресу function+2, где два означает размер инструкции, вставленной компилятором для хотпатчинга (В этом случае остается возможность применения Hotpatch, несмотря на установку перехвата одним из наших излюбленных методов).
Вот изображение, иллюстрирующее хотпатчинг. Перехватываемой функцией здесь является MessageBoxA, а перехватывающей – hook_MessageBoxA (т. е. MessageBoxA = функция A, hook_MessageBoxA = функция B).
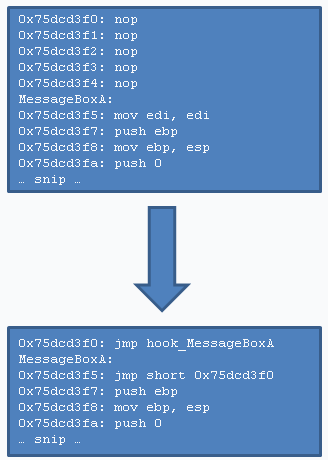
Другие методы II: Методы для классов C++
Эта техника относится к перехвату методов классов C++. Методы классов C++ используют так называемое соглашение вызова __thiscall [5] (по крайней мере в Windows).
Соглашение вызова __thiscall хранит указатель на информацию об объекте (к которому можно обратиться в методах класса через переменную this) в регистре ecx перед вызовом метода класса. Другими словами, если мы хотим перехватить метод класса, необходимо особое внимание.
В дальнейшем обсуждении мы будем использовать следующий фрагмент кода, определяющий функцию (function_A), которую мы хотим перехватить.
class A { public: void function_A(int value, int value2, int value3)
{ printf("value: %d %d %d\n", value, value2, value3); } };
Так как мы хотим перехватывать функции C++ обычными функциями C, нам нужно, чтобы первым параметром перехватывающей функции был указатель this. Пример перехватывающей функции и трамплин (который мы обсудим позднее) выглядят следующим образом. Отметим, что вместо this используется имя переменной self из-за того, что this – зарезервированное в C++ ключевое слово.
void (*function_A_trampoline)(void *self, int value, int value2, int value3);
void function_B(void *self, int value, int value2, int value3)
{ return function_A_trampoline(self, value + 1, value + 2, value + 3); }
Чтобы иметь возможность перехватывать методы классов C++ из обычных C-функций, нам придется изменить стек, поскольку нам нужно вставить в него указатель this. Следующий пример представляет разметку стека при вызове функции A (слева) и разметку, которую мы хотим иметь при вызове функции B (перехватывающей функции). Отметим, что ecx содержит значение указателя this, а вершина стека – это адрес, по которому расположен return_address.

К счастью для нас, мы можем вставить указатель this всего двумя инструкциями – довольно лаконично. Первый шаг – обмен значений указателя this (регистра ecx) и вершины стека (return_address). После данного обмена на вершине стека окажется указатель this, а в регистре ecx – return_address. Теперь мы можем просто положить значение регистра ecx на стек, и стек станет выглядеть в точности так, как мы хотели (см. изображение).
Вот ассемблерное представление перехвата метода класса C++.

Мы рассмотрели часть, касающуюся перехвата. Однако, нам также нужно адаптировать наш трамплин, поскольку трамплин принимает указатель this в качестве первого аргумента. Стек, который мы имеем и стек, к которому мы хотим прийти, выглядят следующим образом. (Очевидно, что значение this после всех манипуляций должно снова оказаться в регистре ecx).

Мы выполняем действия, в точности обратные тем, которые делали в ходе перехвата функции. Сначала мы выталкиваем из стека return_address, так что стек теперь указывает на this, а регистр ecx принимает значение return_address. Теперь мы обмениваем значение на вершине стека с регистром ecx, после чего стек принимает желаемый вид, а в регистр ecx загружается значение указателя this. Следующее изображение иллюстрирует трамплин, хотя инструкции из функции A на нем не показаны (т. е. данное изображение лишь показывает что особенного в трамплине к методу класса C++, а не то, что мы ранее обсуждали в разделе Трамплины).

Построение трамплинов
В одном из предыдущих разделов, Трамплины, мы обсуждали, как должны строиться трамплины. В данном разделе мы обсудим некоторые граничные случаи, которые нужно принимать во внимание при построении трамплинов.Вот основы построения трамплинов. У нас есть функция (функция A), которую мы хотим перехватить и метод перехвата. Сейчас мы используем самый простой метод – прямой безусловный переход, который имеет размер 5 байтов. Поскольку мы будем перезаписывать первые пять байтов функции A, нам нужно взять, по меньшей мере, те инструкции, которые расположены в первых пяти байтах данной функции. Однако, последняя инструкция в этих пяти байтах может оказаться довольно длинной, например, растянуться от третьего до шестого байта, что имеет место в использованном ранее примере (далее еще раз приведено иллюстрирующее его изображение).
Как вы можете видеть, третья инструкция использует шестой байт, из-за этого мы не можем просто скопировать первые пять байт, нам придется скопировать инструкцию целиком. Чтобы сделать это мы используем так называемый LDE (Length Disassembler Engine). LDE способен вычислять длину инструкции (обычно путем махинаций с предопределенной таблицей, содержащей информацию о каждом опкоде).
Поскольку LDE может вычислить для нас длину инструкции, мы можем просто продолжать получать длины инструкций, пока не найдем достаточно инструкций для покрытия первых пяти байт. На вышеуказанном рисунке видно, что нам достаточно трех инструкций, чтобы набрать длину в 6 байт, достаточную для трамплина.
Это была простая часть, поскольку инструкции, которые мы нашли, не содержали ветвлений. Однако, любые инструкции перехода, вызова и возврата также требуют особого внимания. Для начала, инструкции вызова и перехода должны указывать в трамплине на тот же адрес, на который они указывали в исходной функции. Впрочем, этого несложно добиться с помощью двух формул (одной для получения адреса инструкции вызова или перехода и другой для вычисления относительного смещения для инструкции вызова или перехода, размещенной в трамплине). Отметим также, что любые переходы, которые имеют 8-битное относительное смещение, должны быть преобразованы в инструкции перехода с 32-битными относительными смещениями (вряд ли относительное смещение между трамплином и исходной функцией будет в пределах, задаваемых 8-битным смещением).
Наконец, иногда бывает, что для нашего метода перехвата попросту не хватает места. Это случается при наличии инструкции безусловного перехода или инструкции возврата. Такое происходит, когда мы попадаем в конец функции (т. е. нам требуется переписать байты, находящиеся уже после инструкции возврата). После инструкции возврата, например, может располагаться совершенно другая функция, содержимое которой переписывать мы не собирались и в общем случае не можем. То же справедливо и для ситуации, в которой нужно переписать инструкцию безусловного перехода: функция не будет продолжать выполняться после инструкции перехода, так что перезапись участка памяти после данной инструкции может привести к неопределенным последствиям.
Многослойные перехваты
Для одной функции вполне возможно установить несколько слоев перехватчиков. При установке одного перехватчика поверх другого нужно соблюдать лишь одно условие: требуемая длина для нового перехватчика должна быть равна или меньше длины существующего. Причина, по которой это необходимо, была раскрыта в предыдущем разделе, Построение трамплинов. В любом случае, обычный прямой переход с 32-битным относительным смещением должен подойти, поскольку это (в обычном случае) перехватчик с наименьшим размером.Предотвращение рекурсии перехвата
И, напоследок, несколько соображений на счет рекурсии перехвата. Иногда бывает, что в перехватывающей функции (функции B в нашем примере) используются функции вроде логирования в файл. Однако, что если такая функция перехвачена тем же или иным нашим перехватчиком? Это может привести к рекурсивному перехвату, т. е. перехватчик может начать циклически перехватывать себя, либо образуется цикл из нескольких перехватчиков. Это не то, что мы хотим, да еще и очень раздражает.В целом, чтобы предотвратить данную проблему, нам нужно поддерживать счетчик перехватов. Всякий раз при запуске перехватчик будет производить проверку счетчика (который, очевидно будет увеличиваться при входе в перехватчик). Таким образом, мы сможем контролировать две вещи. Первая – то, что перехватчик не будет создавать вложенные перехваты (например, если мы перехватили функцию fwrite(), и в перехватывающей функции мы также вызываем fwrite(), перехватчик не отработает повторно). Вторая – максимальная вложенность рекурсии, например, не более трех вложенных перехватов. Впрочем, подобная функциональность обычно не нужна.
Отметим также, что подобный счетчик перехватов должен быть специфичным для потока. Для решения этой задачи, код, приведенный в разделе «Демонстрация», хранит счетчик в сегменте, на который указывает регистр fs [6] (данный раздел обозначает Блок Информации Потока, т. е. специфичную для потока информацию).
Демонстрация
Для демонстрации практической применимости содержащейся в данном посте информации мы представляем читателю Cuckoo Sandbox, систему для автоматического анализа вредоносных программ. В относительно новом компоненте анализатора Cuckoo мы применили техники из данного поста. Например, хотя он использует прямой 32-битный переход, он обладает достаточно мощным движком для построения трамплинов и поддерживает предотвращение рекурсии перехвата.Текущий исходный код можно найти тут, достаточно скоро он будет здесь. Реализацию описанных в данном посте методов можно посмотреть в файле hooking.c.