
Возможности технологии Cisco IOS IP SLA.
Данная статья, дает представление о возможностях оценки качества, мониторинга сети, а также принятия решений оборудованием Cisco с помощью технологии Cisco IOS IP SLA.
Григорий Сандул
Возможности технологии Cisco IOS IP SLA.
Аннотация
О необходимости обеспечивать высокое качество, наряду с контролем, передачи данных по сети Интернет сказано много. Появление сервисов, таких как VoIP и IPTV диктуют свои условия. Данная статья, дает представление о возможностях оценки качества, мониторинга сети, а также принятия решений оборудованием Cisco с помощью технологии Cisco IOS IP SLA.
Введение.
На текущий день существует множество программных и аппаратных решений контроля качества передачи данных по сети Интернет. Я не буду проводить обзор существующих решений. Возможности Cisco IP SLA часто используется для оценки качественных характеристик сети различными программными продуктами, предназначенными для мониторинга состояния сети. Однако не все программные продукты мониторинга сети поддерживают эту технологию. Описываемые методы могут быть использованы как для построения своей системы мониторинга, так и для расширения существующей.
Аббревиатура SLA расшифровывается как Service Level Agreements, что можно перевести как соглашения об уровне обслуживания. Первоначально технология называлась RTR Round Trip Reporter – что можно перевести как агент, информирующий о задержках. В зависимости от версии IOS команды по конфигурированию устройства могут различаться. Подробно об этом можно почитать здесь. Я буду описывать все на примере IOS выше 12.4. Команды конфигурирования могут отличаться в различных версиях IOS-а.
Суть технологии.
В Cisco IOS встроены программные тесты состояния сети. На текущий момент существует более десятка тестов. Различные IOS поддерживают различные наборы тестов. Например мой Cisco 2821 поддерживает следующие тесты:
c2821(config)#ip sla monitor 19c2821(config-sla-monitor)#type ?
dhcp DHCP Operation
dlsw DLSW Operation
dns DNS Query Operation
echo Echo Operation
frame-relay Perform frame relay operation
ftp FTP Operation
http HTTP Operation
jitter Jitter Operation
pathEcho Path Discovered Echo Operation
pathJitter Path Discovered Jitter Operation
slm SLM Operation
tcpConnect TCP Connect Operation
udpEcho UDP Echo Operation
voip Voice Over IP measurement
Подробно о каждом тесте говорить смысла нет. Способы конфигурирования и что можно получить, используя тот либо иной тест, можно узнать на сайте Cisco. В общем же случае, Cisco умеет:
- выполнять тест
- можно вывести результаты теста с помощью командной строки
- результаты тестов сохраняются и доступ к ним можно получить по SNMP
- можно настроить отправку SNMP trap и syslog сообщений, информирующих о неудовлетворительных и удовлетворительных результатах тестов
- можно сконфигурировать Cisco, так чтобы он принимал решения о маршрутизации на основе результатов тестов.
- ….? Я не претендую на 100% полноту знаний в этом вопросе :).
Одним из самых ценных тестов, на мой взгляд, является jitter тест. На нем стоит остановиться подробно.
Jitter тест.
Jitter тест особенно ценен в тех случаях, когда вы контролируете систему предоставляющую кроме передачи данных еще и VoIP.Для понимания самого теста, что он дает, необходимо знать что такое jitter-ы и как они влияют на качество голоса.
Jitter с английского языка можно перевести как дребезжание, в сети Интернет это понятие я бы определил как межпакетную вариацию длин временных задержек при передаче пакетов (сумбурно, но по другому выразиться сложно).
Как известно, на качество передачи голоса в сети Интернет влияет 3 параметра, это используемый кодек, задержки и потери пакетов. От кодека зависит качество аналогово-цифровых преобразований. Задержки влияют на восприятие человеком качества тем, что при задержках более 300 Миллисекунд в одну сторону, хотя голос передается одновременно в обе стороны, человеку кажется, что его не слышат и надо говорить в режиме односторонней рации, то есть сказал фразу, услышал ответ, сказал следующую. Потери пакетов неизбежно ведут к ухудшению связи, так как не все звуки доходят до собеседника. Вы, наверное, заметили, что при определении качества, Jitter-ы не упоминаются, однако их величина может создавать ситуации аналогичные потерям пакетов.
Возьмем, к примеру, кодек g729, обычно этот кодек передает голос разбивая его на 50 пакетов в секунду. Интервал посылки пакетов 20 Миллисекунд. Рассмотрим идеальный случай без Jitter-ов, с задержкой 70 Миллисекунд.
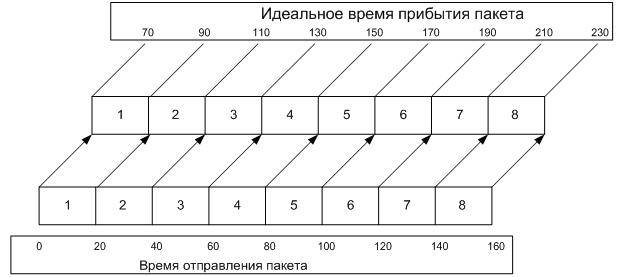
В реальном же мире мы часто имеем другую картину.

В идеальных условиях, второй пакет должен был дойти на 90-стой миллисекунде, на самом деле он пришел на 130-той. Это пакет с позитивным jitter-ом, четвертый должен был прийти на 130-ой, а пришел на 115, пакет с негативным jitter-ом. Для сглаживания подобных ситуаций обычно VoIP устройства используют jitter буфер, величина буфера измеряется не в пакетах, но в миллисекундах. Обычно используется адаптивный jitter буфер, величина которого может меняется во время разговора в зависимости от условий сети. Например, на моём Cisco 2821 он по умолчанию установлен с такими параметрами:
c2821#sh voice portForeign Exchange Office 0/2/0 Slot is 0, Sub-unit is 2, Port is 0
Type of VoicePort is FXO
……..
Playout-delay Mode is set to adaptive
Playout-delay Nominal is set to 60 ms
Playout-delay Maximum is set to 250 ms
Playout-delay Minimum mode is set to default, value 40 ms
Буфер адаптивный, нормальная его величина 60 миллисекунд, может достигать 250 миллисекунд, и минимальная, при очень хорошей сети – 40 миллисекунд. В данном примере, очевидно, что даже наличие буфера не позволит избежать потери пакета под номером 5. Этот пакет будет просто отброшен, и для разговора потерян. Возможно, более понятное описание процесса потери пакетов в результате наличия jitter-ов можно найти здесь
Jitter тест позволяет получить представление об уровнях задержек, потерь пакетов и jitter-ов, при этом, так как трафик двунаправленный, то можно увидеть что происходит при передаче пакетов в каждую из сторон. Перейдем к конкретному примеру, который у меня настроен и работает.
Ситуация была следующей: у меня по Интернету гоняется голос между тремя филиалами, связь с одним филиалом никаких нареканий не вызывает, работает почти идеально, связь со вторым – не удовлетворительна. Согласно CDR (Call Detail Records) собираемым на Radius Server-е с помощью Cisco VSA (Vendor Specific Attributes) видно, что уровень ICPIF при связи с филиалом c идеальной связью на уровне 11, с другим – примерно 22. Как известно, чем ниже ICPIF, тем лучше связь. В моем случае, как и описано на сайте, связь с одним офисом, немного хуже очень хорошего (при учете ICPIF необходимо делать поправку на ожидания пользователей, так как филиалы географически удалены, а связь между ними практически бесплатна, то ее можно считать очень хорошей в данном случае), во втором, немного хуже адекватного. Необходимо было выяснить, что приводит к таким результатам и после устранения причины – контролировать появление подобных ситуаций. Для этого были сконфигурированы 2 jitter теста с каждым из филиалов вот таким образом
ip sla monitor 1type jitter dest-ipaddr XXX.XXX.XXX.XXX dest-port 20001 source-ipaddr ZZZ.ZZZ.ZZZ.ZZZ codec g729a codec-numpackets 1000 codec-size 20
frequency 300
ip sla monitor schedule 1 life forever start-time now
ip sla monitor 2
type jitter dest-ipaddr YYY.YYY.YYY.YYY dest-port 20001 source-ipaddr ZZZ.ZZZ.ZZZ.ZZZ codec g729a codec-numpackets 1000 codec-size 20
frequency 300
ip sla monitor schedule 2 life forever start-time now
Относительно вариантов конфигурирования рекомендую проконсультироваться на сайте Cisco. В данном конкретном случае запускается 2 jitter теста, первый между маршрутизаторами Cisco с IP ZZZ.ZZZ.ZZZ.ZZZ и XXX.XXX.XXX.XXX, второй - между ZZZ.ZZZ.ZZZ.ZZZ и YYY.YYY.YYY.YYY. Генерируется 1000 пакетов эмулирующих g729 кодек с полезной нагрузкой 20 байт на пакет, тест запускается 1 раз в 5 минут. Другими словами, раз в 5 минут каждый тест эмулирует 20-ти секундный разговор по g729-му кодеку.
Весьма важный момент: jitter тест возможен только между двумя устройствами Cisco поддерживающими IP SLA тесты. Вы не сможете запустить данный тест между маршрутизатором Cisco и, например, компьютером или маршрутизатором другого производителя. Кроме того, по умолчанию, данный тест с произвольным маршрутизатором Cisco не возможен, для того, чтобы все заработало необходимо включить на маршрутизаторах с IP XXX.XXX.XXX.XXX и YYY.YYY.YYY.YYY так называемый responder командой
ip sla monitor responder
В данном случае, маршрутизаторы с включенным responder-ом, выполняют функции ассистентов для тестов.
С помощь командной строки результаты последнего выполнения тестов можно посмотреть командой
sh ip sla monitor operational-state
Можно также посмотреть накопленные за некоторый промежуток времени (по умолчанию час) результаты командой
sh ip sla monitor collection-statistics
И то и другое ценно, однако для того чтобы реально оценить ситуацию в течение длительного промежутка времени не годится. Для адекватной комплексной оценки необходимо периодически опрашивать маршрутизатор, сохранять результаты в базу данных, строить графики. Для опроса маршрутизатора удобней всего использовать протокол SNMP. Можно, конечно использовать SNMP MIB OID-ы для collection-statictics, однако, на мой взгляд, проще использовать результаты последнего теста. Раз в 5 минут проходит тест, раз в 5 минут необходимо опрашивать устройство по результатам. С помощью Cisco SNMP Object Navigator-а можно за 5 минут найти интересующие вас OID-ы, в данном случае вот они
Обратите внимание, результатом каждого теста является 52 значения, которые можно посмотреть. По названию каждого и его описанию можно представить себе, что означает каждый из параметров. Возникает вопрос, какие из них важны, какие – нет. На самом деле, я думаю, важны почти все.
Распространенными инструментами опроса устройств по SNMP с целью получения статистических графиков являются MRTG и Cacti (Кактус). Однако, в данном случае конфигурирование более 50-ти параметров для каждого теста очень накладно с точки зрения человеческих ресурсов. Поэтому, весьма оправдано использование простейших скриптов.
Скрипты и инструкции по установке представлены в приложении, работают под FreeBSD 5.3. Под другими NIX ОС, возможно, необходимо будет сделать модификацию. Под Windows – в принципе можно портировать. Используются RRDTool, perl с CGI, snmpwalk, cron daemon.
Работу скриптов можно описать в нескольких словах. Принцип такой же как и у MRTG и Кактуса. По cron-у запускается скрипт, который осуществляет snmpwalk по интересующим нас значениям и заполняет базы данных. В качестве базы данных используется Round Robin Database сформированная и обрабатываемая утилитами rrdtool. По запросу пользователя формируются графики на web сервере с помощью perl CGI. Графики можно построить за произвольный период последних 8-ми суток с уровнем детализации равным одному часу.
С помощью незначительных модификаций скриптов можно добавить на рисунки еще несколько SLA Jitter тестов или изменить период, за который необходимо получить графики. Для этого необходимо понимать, как работает rrdtool и иметь базовые знания perl.
Ниже – скриншоты работы скриптов
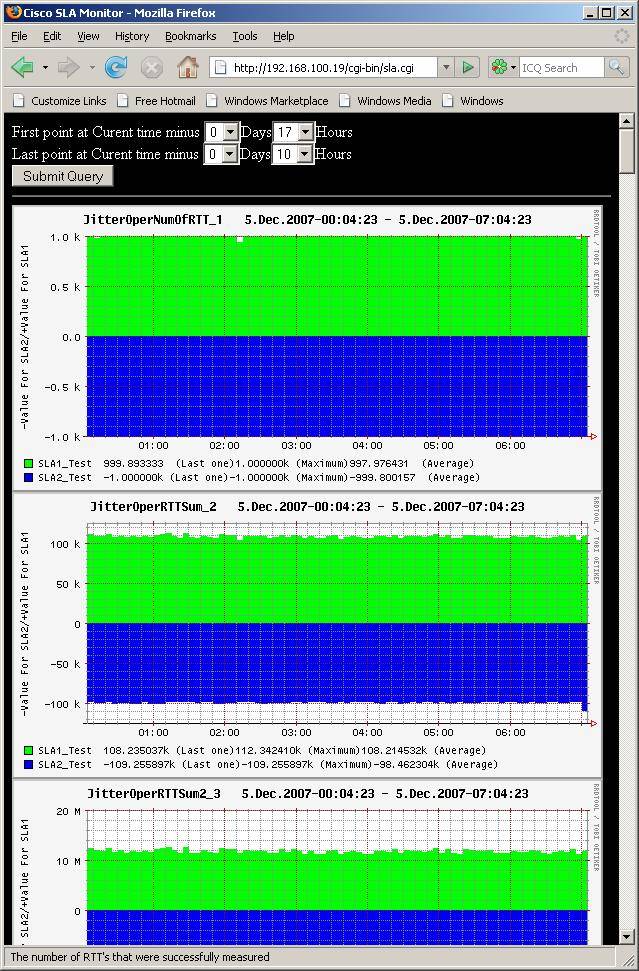
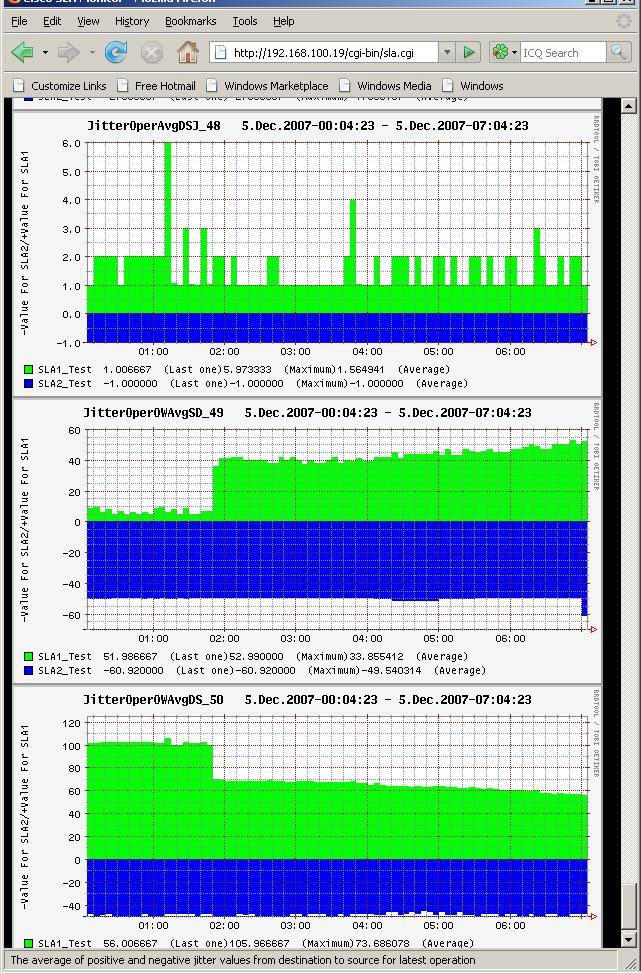
Относительно интерпретации графиков величин можно говорить долго, но я всего лишь потрачу свое и ваше время, так как не существенные для одной сети отклонения могут быть существенными в другой. Лучше самому настроить и посмотреть, что происходит на самом деле. Отмечу лишь один момент, Cisco, в jitter тесте вычисляет 2 основных параметра качества голоса это MOS и ICPIF, но вычисляет их не совсем корректно. При оценке этих параметров не учитывается потеря пакетов, которая возникает из-за jitter-ов, в моем случае для двух филиалов MOS и ICPIF были примерно одинаковы, на самом деле качество очень сильно отличалось именно из-за наличия огромных jitter-ов в одном из филиалов.
Что мне дал настроенный мониторинг. Оценив наглядно, почему плох один из каналов, я попросил провайдера поменять мне модем. После смены модема качество улучшилось, однако исходящий канал в филиале работал не очень хорошо, из-за того, что он оказался узким, периодически возникали огромные jitter-ы. Так как мой исходящий канал мне полностью подвластен, то я раскрасил трафик и настроил качество обслуживания в своей сети. После чего проблема была закрыта.
Вообще вариантов использования данного теста может быть много. Например, вы решили проверить, как влияет определенный параметр обеспечения QoS прописанный в пакете на качество передачи данных в вашей сети по сравнению с другим параметром для QoS. Для этого запускаете 2 теста между двумя устройствами, с различными сконфигурированными параметрами QoS (при настройке теста используется поле tos пакета) и смотрите в чем разница. Это я, например, использовал после того, как настроил качество в обслуживании для своей сети и проверял, насколько настроенный QoS улучшил параметры. Или, пытаетесь определить, как влияет последняя миля в удаленном филиале на качество связи с вами, для этого просите провайдера настроить у себя responder и сравниваете значения для тестов между своими Cisco и своим Cisco и Cisco провайдера.
После того, как вы добились для себя приемлемого качества канала можно отключить тесты, но можно и оставить их включенными для ведения статистики либо оперативного выявления неудовлетворительных результатов тестов. На графиках прекрасно видно как в нормальной ситуации ведет себя сеть, поэтому настроить оповещения о ненормальном ее поведении довольно просто. Как я уже упоминал, Cisco умеет сообщать о результатах тестов с помощью SNMP и отсылать syslog сообщения. Вам необходимо настроить агента, получающего сообщение от Cisco SLA мониторов на оперативное оповещение администратора приемлемым для вас способом (например, по электронной почте или popup-ами на рабочем столе администратора). Также необходимо сконфигурировать Cisco на отсылку сообщений по результатам тестов, о которых вас необходимо информировать. Подробно о последнем почитать здесь
Например, я хочу получать SNMP и syslog сообщения о событиях, когда средний jitter для пакетов идущих ко мне становится больше 10 Миллисекунд и возвращается к значениям меньше 10 Миллисекунд, таким образом, отслеживая ситуации, которые я считаю предельно допустимыми для моей сети. Сконфигурировав вот так:
ip sla monitor reaction-configuration 1 react jitterDSAvg threshold-value 10 10 threshold-type immediate action-type trapAndTrigger
В результате я получаю такие SNMP и syslog сообщения
12:00:02 syslog snmptrapd[479]: 192.168.100.1 [192.168.100.1]: Trap , DISMAN-EVENT-IB::sysUpTimeInstance = Timeticks: (1319928900) 152 days, 18:28:09. 00, SNMPv2-MIB::snmpTrapOID.0 = OID: SNMPv2-SMI::enterprises.9.9.41.2.0.1, SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.2.33222 = STRING: "RTT", SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.3.33222 = INTEGER: 4, SNMPv2-MI::enterprises.9.9.41.1.2.3.1.4.33222 = STRING: "IPSLATHRESHOLD", SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.5.33222 = STRING: "IP SLA Monitor(1): Threshold exceeded for jitterDSAvg", SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.6.33222 = Timeticks: (1319928899) 152 days, 18:28:08.99
12:00:02 192.168.100.1 922441: 12:00:03.023: %RTT-3-IPSLATHRESHOLD: IP SLA Monitor(1): Threshold exceeded for jitterDSAvg
12:05:02 syslog snmptrapd[479]: 192.168.100.1 [192.168.100.1]: Trap , DISMAN-EVENT-IB::sysUpTimeInstance = Timeticks: (1319958896) 152 days, 18:33:08.96, SNMPv2-MIB::snmpTrapOID.0 = OID: SNMPv2-SMI::enterprises.9.9.41.2.0.1, SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.2.33223 = STRING: "RTT", SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.3.33223 = INTEGER: 4, SNMPv2-MI::enterprises.9.9.41.1.2.3.1.4.33223 = STRING: "IPSLATHRESHOLD", SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.5.33223 = STRING: "IP SLA Monitor(1): Threshold below for jitterDSAvg", SNMPv2-SMI::enterprises.9.9.41.1.2.3.1.6.33223 = Timeticks: (1319958895) 152 days, 18:33:08.95
12:05:02 192.168.100.1 922442: 12:05:02.981: %RTT-3-IPSLATHRESHOLD: IP SLA Monitor(1): Threshold below for jitterDSAvg
По получению SNMP трапов и syslog сообщений можно автоматически запустить комплексную проверку состояния сети (например, проверить все значения IP SLA теста, проверить объем и тип трафика, который на текущий момент передается, объем занятой памяти и процент использования процессора на маршрутизаторе, либо другие параметры оборудования) и прислать отчет по почте администратору для последующего анализа. При грамотной настройке можно выявлять аномалии, обнаружить причину и устранить ее до того, как ситуация станет критической. Теперь мы подошли к вопросу пассивного мониторинга сети с помощью IP SLA.
IP SLA и пассивный мониторинг.
Если вы настраивали систему мониторинга, то наверняка знаете, что мониторинг может быть пассивным и активным. Активный мониторинг заключается в периодическом опросе тем либо иным методом состояния устройств. Пассивный мониторинг подразумевает ожидание сообщения о событиях от устройств, при этом устройства сами сообщают вам о тех либо иных ситуациях. Правильная система мониторинга должна использовать оба эти метода. События от устройств на станцию мониторинга поступают обычно по протоколам SNMP, с помощью trap-ов, и syslog в виде сообщений. Как настраивается отсылка таких сообщений по результатам IP SLA тестов я уже описывал выше. Для различных конфигурации сети можно использовать любой наиболее подходящий из набора тестов. В случае использования IP SLA тестов станция мониторинга пассивно выполняет свои функции, Cisco же, активно выполняет тесты, таким образом, пассивным этот мониторинг можно назвать только в сточки зрения станции мониторинга.
Возникает резонный вопрос, зачем это нужно, ведь проще опрашивать устройства со станции мониторинга, осуществляя активный мониторинг. Мониторинг с помощью IP SLA тестов следует применять в случаях, когда устройство по отношению к станции мониторинга расположено за Firewall-ом, NAT-ом или вообще не маршрутизируется до станции мониторинга.
Рассмотрим такой пример. У вас есть удаленный филиал, сеть которого логически представлена на рисунке.

В данном примере, маршрутизатор Cisco осуществляет функции NAT для внутренней сети, он расположен в серверной, ваш офис на другом этаже. Switch-и A и B вам не принадлежат, вам выделен отдельный VLAN, проключенный до вашего Switch-а C. Switch C имеет свой IP адрес, однако на нем не прописан default gateway, из соображений политики безопасности. Мониторить рабочие станции сотрудников бессмысленно, так как они могут быть произвольно выключены. Однако вам необходимо оперативно выявлять ситуации когда:
1) Пропадет связь с внешним интерфейсом вашего маршрутизатора
2) Пропадет связь между вашей внутренней сетью и маршрутизатором Cisco.
Для этого, на станции мониторинга настраивается активный мониторинг по ICMP состояния связи офиса с Интернетом. Также, настраивается простой IP SLA echo ICMP тест между Cisco и Switch-ем С. Теперь, пассивный мониторинг выявит ситуации сбоев связи во внутренней сети, активный – во внешней.
Преимущества такого мониторинга очевидны, вы не тратите внешний трафик на мониторинг внутренней сети (опрашивать Switch в связи с этим можно сколь угодно часто, следовательно, проблема будет обнаружена быстрее), и ваша внутренняя сеть более защищенная, чем, если бы вы открывали наружу ваше оборудование.
Итак, для данного случая необходимо сконфигурировать IP SLA примерно следующим образом
ip sla monitor 3
type echo protocol ipIcmpEcho 172.17.31.100 source-ipaddr 172.17.31.1
timeout 2000
threshold 10
frequency 10
ip sla monitor reaction-configuration 3 react timeout threshold-type immediate action-type trapAndTrigger
ip sla monitor schedule 3 life forever start-time now
Однако, в этом случае при timeout-е, мы получим только SNMP trap сообщение, syslog сообщение не генерируется. При этом сами Trap-ы не совсем читабельны. Например, при обнаружении timeout-а для одного из тестов я получаю вот такой trap
15:51:33 syslog snmptrapd[479]: 192.168.100.1 [192.168.100.1]: Trap , DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (1329958030) 153 days, 22:19:40.30, SNMPv2-MIB::snmpTrapOID.0 = OID: SNMPv2-SMI::enterprises.9.9.42.2.0.2, SNMPv2-SMI::enterprises.9.9.42.1.2.1.1.3.3 = "", SNMPv2-SMI::enterprises.9.9.42.1.4.1.1.5.3 = Hex-STRING: C0 A8 46 02 , SNMPv2-SMI::enterprises.9.9.42.1.2.9.1.6.3 = INTEGER: 1
Когда все приходит в норму – вот такой
16:04:43 syslog snmptrapd[479]: 192.168.100.1 [192.168.100.1]: Trap , DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (1330037041) 153 days, 22:32:50.41, SNMPv2-MIB::snmpTrapOID.0 = OID: SNMPv2-SMI::enterprises.9.9.42.2.0.2, SNMPv2-SMI::enterprises.9.9.42.1.2.1.1.3.3 = "", SNMPv2-SMI::enterprises.9.9.42.1.4.1.1.5.3 = Hex-STRING: C0 A8 46 02 , SNMPv2-SMI::enterprises.9.9.42.1.2.9.1.6.3 = INTEGER: 2
Проблема в том, что как написал в своем посте http://ioshints.blogspot.com/2007/01/log-ip-sla-failures.html Ivan Pepelnjak, технология IP SLA заточена под SNMP (is extremely SNMP-oriented). Однако в том же тесте описано как можно сгенерировать syslog сообщение. Для этого необходимо воспользоваться возможностями EEM (Embedded Event Manager – Встроенный [в IOS] Обработчик событий). EEM умеет периодически опрашивать SNMP переменные и, в зависимости от их состояния, выполнять различные действия, в частности, генерировать syslog сообщения.
Например, если для описанного выше теста сконфигурировать так:
event manager applet Office1_down
event snmp oid 1.3.6.1.4.1.9.9.42.1.2.9.1.6.3 get-type exact entry-op eq entry-val 1 entry-type value exit-comb or exit-op eq exit-val 2 exit-type value exit-time 600 exit-event false poll-interval 5
action 1.0 syslog msg "Ping to 172.17.1.100 timeout"
event manager applet Office1_up
event snmp oid 1.3.6.1.4.1.9.9.42.1.2.9.1.6.3 get-type exact entry-op eq entry-val 2 entry-type value exit-comb or exit-op eq exit-val 1 exit-type value exit-event false poll-interval 5
action 1.0 syslog msg "Ping to 172.17.1.100 OK"
То мы будем получать такие syslog сообщения каждые 10 минут при отсутствии внутренней связи
15:07:01.034: %HA_EM-6-LOG: Office1_down: Ping to 172.17.1.100 timeout
15:17:01.038: %HA_EM-6-LOG: Office1_down: Ping to 172.17.1.100 timeout
15:27:01.043: %HA_EM-6-LOG: Office1_down: Ping to 172.17.1.100 timeout
И в случае, когда связь восстановится, получим одно сообщение:
15:34:19.033: %HA_EM-6-LOG: Office1_up: Ping to 172.17.1.100 OK
Вариантов использования IP SLA тестов в целях мониторинга может быть огромное количество. Однако только мониторингом возможности тестов не ограничиваются.
IP SLA и принятие решений маршрутизации.
На текущий день не редки ситуации, когда у конечного пользователя Интернет существует множество Интернет каналов предоставляемых одним или несколькими провайдерами. Главное преимущество наличия нескольких каналов связи это минимизирование рисков простоя в случае сбоев. В случае наличия нескольких каналов связи решение о том, через какой из них маршрутизировать трафик можно принимать на основе доступности канала. В классической ситуации, без IP SLA тестов, о доступности канала связи можно судить по состоянию интерфейса. Однако состояние интерфейса не всегда однозначно говорит о доступности канала передачи данных. Например, если у вас маршрутизатор подключен к DSL модему по Ethernet, то в случае сбоя связи в DSL вы не сможете его выявить стандартными способами. Наличие различных IP SLA тестов позволяет выявлять подобные ситуации. На текущий, день в IOS существует возможность принимать решения о маршрутизации на основе результатов IP SLA тестов. Описывать, как все настраивается, я не берусь, так как не использовал такие методы. Однако на сайте Cisco все, как всегда, понятно описано. Вот пример для Policy Based Routing with the Multiple Tracking Options Feature
и для IOS NAT Load-balancing for Two ISP Connections
Я считаю, что подобные фичи могут часто быть полезными. Однако их функционала не всегда хватает для решения задач.
IP SLA как расширение возможностей EEM.
EEM (Embedded Event Manager – Встроенный [в IOS] Обработчик Событий) позиционируется как средство самодиагностики и устранения проблем самим маршрутизатором. Обычно Обработчик Событий расположен не на маршрутизаторе, а на NMS (Network Management Station - Станция Управления Сетью), сами же события могут быть самыми разными от высокой загрузки CPU и памяти, отключения интерфейса до высокой температуры в корпусе маршрутизатора. В классической схеме маршрутизатор сообщает о событиях на NMS, которая может на их основе выполнить различные действия, начиная от оповещения различными способами администраторов до перезагрузки устройства. Необходимость встроенного обработчика событий обусловлена тем, что не всегда при критических событиях у маршрутизатора будет возможность сообщить о них на NMS. Простейший пример этого – отключился интерфейс маршрутизатора и связь у него со всем миром потеряна. Примеров использования EEM на сайте Cisco множество. Весьма интересная презентация возможностей EEM совместно с языком программирования Тиклем (TCL) здесь
Наличие IP SLA тестов расширяет возможности EEM, так как тесты могут дать маршрутизатору представление не только о том, что происходит непосредственно с ним, но и в сети. Как было неоднократно упомянуто выше результаты тестов записываются в SNMP переменные и могут генерироваться syslog сообщения, EEM же, в свою очередь спроектирован так, что может реагировать именно на такие события. Использование возможностей EEM совместно с IP SLA может дать весьма интересные, с точки зрения минимизирования времени простоя сети, результаты.
Рассмотрим пример представленный на рисунке
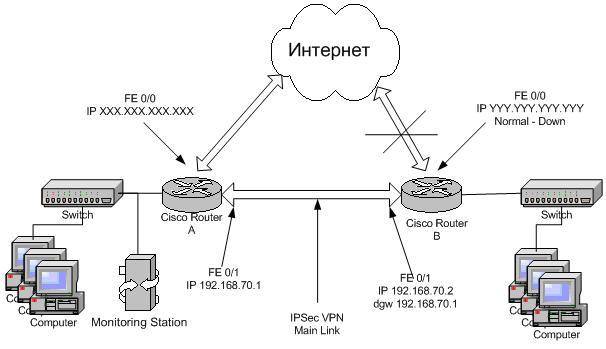
Здесь с левой стороны – центральный офис, ресурсами которого пользуются сотрудники удаленного офиса (с правой стороны). Между офисами провайдером поднята связь точка – точка, на входе каждого офиса – провайдер предоставил модемы, cо стороны офисов на демарке – Ethernet. Между офисами поднят IPSec туннель. Центральный офис имеет постоянный доступ в Интернет, доступ к ресурсам Интернет из удаленного офиса осуществляется через центральный офис. У удаленного офиса есть также связь с Интернет по резервному каналу. Использование резервного канала не приемлемо в обычной ситуации из-за его дороговизны и не очень хорошего качества, в нормальной ситуации интерфейс, через который работает резервный канал в состоянии down. В случае сбоя основного канала можно использовать резервный (он для этого и предназначен). Задача – осуществить автоматический переход на резервный канал, в случае сбоя основного, при этом поднять VPN между офисами.
Если вы поднимали IPSec туннель между офисами на Cisco, то знаете, что туннель привязывается к конкретному интерфейсу, кроме того, в этом случае жестко прописывается IP адрес пира, с которым туннель нужно поднять. В примере, в случае сбоя изменяются оба эти параметра. Переконфигурировать все не сложно, и детали изменения конфигурации не суть важны, главное, что этого нельзя сделать одной командой. Нормальный план изменения конфигурации устройств подразумевает наличие заготовленных конфигураций для того либо иного случая (чтобы не терять время). Конфигурации могут храниться на tftp сервере или во flash памяти маршрутизатора. В случае сбоя основного канала можно просто дать команду и скопировать нужную конфигурацию в running-config маршрутизатора.
Если бы изменения конфигурации делал человек, то все выглядело бы примерно следующим образом:
- система мониторинга показала сбой основного канала до удаленного офиса (не пингуется IP 192.168.70.2)
- администратор некоторое время проверяет ложность срабатывания системы мониторинга (запустил ping на 192.168.70.2)
- если это было не ложное срабатывание (192.168.70.2 не откликается), то в running-config маршрутизаторов A и B заливаются конфигурации для работы с резервными каналами.
- Как только ситуация нормализуется (система мониторинга показала доступность основного канала), администратор убеждается в том, что все в порядке (некоторое время пингует 192.168.70.2) и заливает нужные конфигурации
Рассмотрим теперь, как это можно сделать автоматически только средствами Cisco, не прибегая к помощи NMS или системного администратора. Переключение необходимо делать как на маршрутизаторе A, так и на маршрутизаторе B, для примера рассмотрим только маршрутизатор B.
Первым делом необходимо запустить IP SLA echo ICMP тест на маршрутизаторе, выявляющий недоступность маршрутизатора A таким образом
ip sla monitor 3
type echo protocol ipIcmpEcho 192.168.70.1 source-ipaddr 192.168.70.2
timeout 2000
threshold 10
frequency 5
ip sla monitor reaction-configuration 5 react timeout threshold-type immediate action-type trapAndTrigger
ip sla monitor schedule 5 life forever start-time now
Каждые 5 секунд проверяется доступность IP адреса 192.168.70.1. Теперь необходимо отслеживать состояние недоступности маршрутизатора 192.168.70.1 в течение, допустим минуты. Если это имеет место, то принимаем меры по изменению конфигурации. Если в течение минуты связь появилась, то считаем, что было ложное срабатывание (ведь, на самом деле потери отдельных пакетов в сети Интернет скорее норма, чем нечто неординарное). Для этого настраиваем 3 EEM обработчика событий.
Итак, обработчик первый, отслеживающий потерю одного пакета до 192.168.70.1.
event manager applet OnePacketLost
event snmp oid 1.3.6.1.4.1.9.9.42.1.2.9.1.6.3 get-type exact entry-op eq entry-val 1 entry-type value exit-comb or exit-op eq exit-val 2 exit-type value exit-time 3 exit-event false poll-interval 5
action 1.0 counter name lost_count op inc value 1
action 2.0 syslog msg "WARNING Ping to 192.168.70.1 timeout"
Этот обработчик делает 2 вещи, отсылает сообщения, каждые 5 секунд, когда связь с офисом потеряна и в то же время каждые 5 секунд инкрементирует счетчик lost_count.
Следующий обработчик событий
event manager applet LinkOK
event snmp oid 1.3.6.1.4.1.9.9.42.1.2.9.1.6.3 get-type exact entry-op eq entry-val 2 entry-type value exit-comb or exit-op eq exit-val 1 exit-type value exit-event false poll-interval 5
action 1.0 counter name lost_count op set value 0
action 2.0 syslog msg "WARNING LINK to 192.168.70.1 is OK NOW"
Также делает 2 вещи, отсылает одно сообщение, когда связь восстановилась и сбрасывает в ноль счетчик потерянных пакетов – lost_count.
Третий обработчик
event manager applet MainLinkLost
event counter name lost_count entry-val 12 entry-op eq exit-val 12 exit-op eq
action 1.0 syslog msg "ALARM Link To 192.168.70.1 Down Going to Backup Channel"
Проверяет счетчик потерянных пакетов lost_count и в случае, если его значение равно 12 отсылает сообщение о том, что собирается переключить конфигурацию на резервный канал далее он должен залить новую конфигурацию в runnig-config, об этом ниже.
Настроив, таким образом, EEM события мы, в случае если основной канал в состоянии down будет больше минуты, получим такие сообщения
12:50:10.927: %HA_EM-6-LOG: OnePacketLost: WARNING Ping to 192.168.70.1 timeout
12:50:15.927: %HA_EM-6-LOG: OnePacketLost: WARNING Ping to 192.168.70.1 timeout
..............
12:51:00.928: %HA_EM-6-LOG: OnePacketLost: WARNING Ping to 192.168.70.1 timeout
12:51:05.928: %HA_EM-6-LOG: OnePacketLost: WARNING Ping to 192.168.70.1 timeout
12:51:05.928: %HA_EM-6-LOG: MainLinkLost: ALARM Link To 192.168.70.1 Down Going to Backup Channel
Если же связь восстановится раньше чем через минуту, то примерно следующие:
12:52:35.928: %HA_EM-6-LOG: OnePacketLost: WARNING Ping to 192.168.70.1 timeout
12:52:40.928: %HA_EM-6-LOG: OnePacketLost: WARNING Ping to 192.168.70.1 timeout
12:52:45.928: %HA_EM-6-LOG: OnePacketLost: WARNING Ping to 192.168.70.1 timeout
12:52:51.612: %HA_EM-6-LOG: LinkOK: WARNING LINK to 192.168.70.1 is OK NOW
Осталось только научить Cisco заливать конфигурацию для резервного канала после отсылки сообщения “MainLinkLost: ALARM Link To 192.168.70.1 Down Going to Backup Channel”. Эту конфигурацию лучше всего хранить во flash памяти Cisco, в этом случае у нас будет полностью автономное решение, не зависящее от внешних ftp или tftp серверов.
EEM умеет выполнять с качестве действия (action) команды, как если бы вы давали их в командной строке. Однако есть ограничения в том, что после подачи команды Cisco ждет промпта после ее выполнения и, в случае если интерфейс команды подразумевает дополнительный ввода данных команда не выполняется. Например, если дать команду
c2821#copy flash:testsla running-config
То мы получим следующий вопрос, подразумевающий нажатие клавиши Enter в качестве подтверждения
Destination filename [running-config]?
Если давать команду с помощью EEM, то мы получим через некоторое время такое syslog сообщение:
14:45:26.037: FH-TTY::No more VTY line
Сама же команда выполнена не будет. Однако, как всегда можно использовать различные трюки. Все тот же Ivan Pepelnjak предлагает следующий рабочий трюк
Суть в том, что мы в качестве команды выполняем Тикль скрипт, который исполняет нужную нам команду и на промпт отвечает нужным нам образом с помощью функции typeahead
Тикль скрипт для нашего примера будет выглядеть так:
typeahead "\n"
exec "copy flash:configs/tobackup.cfg running-config"
Сама же команда для выполнения этого скрипта будет выглядеть следующим образом
action 2.0 cli command "tclsh flash:tcl/BackupLink.tcl "
Итак, делаем 2 директории на flash маршрутизатора
c2821#mkdir configs
c2821#mkdir tcl
Создаем на tftp сервере файл BackupLink.tcl содержащий 2 строки
typeahead "\n"
exec "copy flash:configs/tobackup.cfg running-config"
Создаем на tftp сервере файл MainLink.tcl
typeahead "\n"
exec "copy flash:configs/tomain.cfg running-config"
Создаем файл tobackup.cfg на tftp сервере, в котором прописана логика переключения на резервный канал, примерно так:
interface FastEthernet0/1
no shut
exit
no ip route 0.0.0.0 0.0.0.0 192.168.70.1
.......
interface FastEthernet0/1
crypto map ToCentralOf
exit
В конце конфигурационного файла удаляем ненужные при работе на резервном канале аплеты EEM командами
no event manager applet OnePacketLost
no event manager applet LinkOK
no event manager applet MainLinkLost
И создаем новые, для переключения на основной канал в случае его восстановления через 30 секунд если не потерялось ни одного пакета в 6-и последовательных с интервалом 5 секунд тестах, примерно такие:
event manager applet MainLinkUP
event counter name up_count entry-val 6 entry-op eq exit-val 6 exit-op eq
action 1.0 syslog msg "ALARM Link To 192.168.70.1 IS UP Going to Main channel"
action 2.0 cli command "tclsh flash:tcl/ MainLink.tcl "
event manager applet LinkOKCheck
event snmp oid 1.3.6.1.4.1.9.9.42.1.2.9.1.6.3 get-type exact entry-op eq entry-val 2 entry-type value exit-comb or exit-op eq exit-val 1 exit-type value exit-time 3 exit-event false poll-interval 5
action 1.0 counter name up_count op inc value 1
action 2.0 syslog msg "WARNING LINK to 192.168.70.1 is OK NOW"
event manager applet PacketLostNotGood
event snmp oid 1.3.6.1.4.1.9.9.42.1.2.9.1.6.3 get-type exact entry-op eq entry-val 1 entry-type value exit-comb or exit-op eq exit-val 2 exit-type value exit-event false poll-interval 5
action 1.0 counter name up_count op set value 0
action 2.0 syslog msg "WARNING Ping to 192.168.70.1 timeout Reset up_count"
Подобным же образом создаем файл tomain.cfg для переключения на основной канал. Затем заливаем по tftp файлы tcl и cfg в директорию tcl и configs соответственно на flash маршрутизатора.
Процедура переключения готова, осталось сделать примерно то же самое для маршрутизатора A и проверить правильность срабатывания скриптов, зашутдаунив нужный порт switch-а или, на худой конец, выдернув кабель из модема провайдера :).
Возможно такие методы выглядят несколько заумно и криво, но они работают и сама настройка не вызывает особых сложностей.
Заключение.
На мой взгляд, в целом, технология достойная изучения и применения. При изучении основная сложность в большом объеме информации, который необходимо переварить для того, чтобы добиться нужных результатов, однако это просто следствие высокой степени конфигурируемости тестов. Некоторые неудобства при конфигурировании доставляет то, что для различных версий IOS – ов надо давать различные команды. Это, в свою очередь не позволяет написать качественный tutorial для копипастеров (все мы периодически бываем копипастерами), однако на сайте Cisco, есть огромное количество примеров и вся необходимая информация. Следствием вышесказанного явилось появление этой статьи и именно в таком виде.
Литература.
http://www.cisco.com/ - Пожалуй, лучший ресурс по конфигурированию Cisco :)
http://ioshints.blogspot.com/ - Весьма познавательный и полезный блог, который ведет Ivan Pepelnjak.