
Использование Libwhisker
Как замечено в статье Проверка надежности Web-приложений использование веб приложений для ведения бизнеса возрастает. Часто компании имею сайты, созданные внутренними разработчиками, и найти все уязвимости сайта, используя автоматизированные утилиты, практически невозможно. Простой поиск различного ПО с установками по умолчанию может ничего не дать, но этот созданный на заказ сайт все же может быть уязвимым ко многим различным ошибкам программирования. Проведение тестирования сайта может быть наиболее важным этапом создания сайта, и намного более сложным, чем тестирование с использованием соответствующих утилит. Ручная проверка сайта необходима почти всегда, но когда специфическая уязвимость обнаружена, очень удобно иметь набор утилит для автоматизации дальнейших действий.
Как замечено в статье Проверка надежности Web-приложений использование веб приложений для ведения бизнеса возрастает. Часто компании имею сайты, созданные внутренними разработчиками, и найти все уязвимости сайта, используя автоматизированные утилиты, практически невозможно. Простой поиск различного ПО с установками по умолчанию может ничего не дать, но этот созданный на заказ сайт все же может быть уязвимым ко многим различным ошибкам программирования. Проведение тестирования сайта может быть наиболее важным этапом создания сайта, и намного более сложным, чем тестирование с использованием соответствующих утилит. Ручная проверка сайта необходима почти всегда, но когда специфическая уязвимость обнаружена, очень удобно иметь набор утилит для автоматизации дальнейших действий.
Почему Libwhisker?
С того момента, когда мы начинаем иметь дело с заказными приложениями, нам нужен набор специализированных утилит. Есть много различных утилит, для которых можно создавать скрипты, но мы сосредоточимся на Libwhisker. Libwhisker это не утилита или приложение, это Perl библиотека, которая позволяет создавать HTTP пакеты.С этого момента предполагается, что читатель имеет представление о протоколе HTTP и знаком с написанием Perl скриптов, использующих внешние модули.
Для начала давайте ответим на вопрос: Зачем нам нужно использовать другой Perl модуль, для того чтобы сделать то, что может быть реализовано с помощью существующих Perl модулей (т.е. LWP, HTTP, URI)? Libwhisker дает нам много преимуществ по сравнению с другими модулями:- Это 100% Perl код. Это означает, что он будет работать на любой системе, где установлен Perl.
- Он сочетает в себе функциональные возможности многих различных Perl модулей, обычно используемых для взаимодействия с веб приложениями.
- Не требует инсталляции. Нужно всего лишь иметь копию LW2.pm в каталоге со скриптом, использующем этот модуль.
- Он был создан по методу отсутствия правил. Это означает, что он позволяет пользователю создавать запросы, не соответствующие стандартам. Другие Perl модули могут проверять и изменять наши запросы для соответствия стандартам.
Использование Libwhisker
Главная структура данных в Libwhisker это хэш-массив 'whisker'. Хэш-массив это структура данных в Perl, похожая на ассоциативные массивы в других скриптовых языках и языках программирования.Хэш-массив 'whisker' может устанавливать различные параметры HTTP запроса и читать различные части HTTP ответа. Однако доступ к этой информации может вызвать затруднения.
Прежде чем использовать какие-либо функции Libwhisker, нужно определить два хэш-массива, один для HTTP запроса, другой для HTTP ответа. Некоторые элементы будут определены в хэш-массиве 'whisker', а некоторые непосредственно в хэш-массиве запроса, или будут читаться непосредственно из хэш-массива ответа. Чтобы определить какие части HTTP запроса/ответа являются частью хэш-массива 'whisker', а какие частю хэш-массивов запроса/ответа, давайте посмотрим на возможные элементы хэш-массива 'whisker', имеющие отношение к HTTP пакету.Обратите внимание, что два элемента хэш-массива 'whisker', 'hin' и 'hout' непосредственно указывают на хэш-массивы запроса и ответа соответственно. В этой статье мы будем использовать хэш-массивы Perl %request, %response и %jar для обращения к хэш-массиву HTTP запроса, хэш-массиву HTTP ответа и хэш-массиву HTTP cookies соответственно.
{'whisker'}->{'host'}= Удаленный хост, к которому мы хотим подключиться. Это значение будет также находится в поле 'Host' HTTP заголовка. Это может быть IP адрес, DNS или NetBIOS имя. Если вы хотите установить другое значение в поле 'Host' HTTP заголовка, вы должны будете сделать это вручную до вызова функции 'LW2::http_do_request'. Это поле должно быть во всех HTTP 1.1 пакетах, чтобы соответствовать RFC. По умолчание его значение - 'localhost'.{'whisker'}->{'port'}= Удаленный порт, с которым мы хотим соединиться. Допустимые значения это числа между 1 и 65535. Значение по умолчанию - 80.{'whisker'}->{'proxy_host'}= Хост прокси, который мы хотим использовать. По умолчанию не установлен.{'whisker'}->{'proxy_port'}= Порт прокси, который мы хотим использовать. Должно быть установлено, если установлена переменная 'proxy_host'.{'whisker'}->{'method'}= HTTP метод, который мы хотим использовать. По умолчанию это GET.{'whisker'}->{'uri'}= URI, который мы хотим использовать. По умолчанию это '/'.{'whisker'}->{'version'}= Версия протокола HTTP, которую мы хотим использовать. Мы можем указать 0.9, 1.0 или 1.1 . Если установлено 0.9, Libwhisker, по умолчанию, будет использовать только те возможности, которые поддерживаются версией 0.9. По умолчанию установлено значение 1.1.{'whisker'}->{'error'}= Используется только если определен хэш-массив 'hout'. Не имеет отношения к HTTP коду, возвращенному сервером, но реагирует на ошибки, возникающие при получении данных от сервера. По умолчанию пусто.{'whisker'}->{'data'}= Если используется в хэш-массиве запроса, в эту переменную помещаются любые POST или PUT данные. Если после определения {'whisker'}->{'data'}, происходит вызов функции 'http_fixup_request', будет установлено поле 'Content-Length' HTTP заголовка. Если эта переменная используется в хэш-массиве ответа, она указывает на HTML данные, полученные от сервера.{'whisker'}->{'code'}= Доступно только в хэш-массиве ответа. Это должен быть числовой HTTP код, возвращенный удаленным сервером.{'whisker'}->{'message'}= Текстовое сообщение, ассоциированное с {'whisker'}->{'code'}.{'whisker'}->{'header_order'}= Это хэш-массив, содержащий все HTTP заголовки, полученные от сервера, в порядке, в котором они были получены.{'whisker'}->{'http_space1'}= Это значение, которое отделяет HTTP метод от URI. По умолчание это '' (один пробел).{"whisker'}->{'uri_prefix'}= Значение, находящееся перед URI. По умолчанию пусто.{'whisker'}->{'uri_postfix'}= Значение, находящееся после URI. По умолчанию пусто.{'whisker'}->{'uri_param_sep'}= Символ, отделяющий параметры. По умолчанию это '?'.{'whisker'}->{'http_space2'}= Значение, отделяющее URI и версию HTTP. По умолчанию - пробел.{'whisker'}->{'http_eol'}= Значение, определяющее конец заголовка.{'whisker'}->{'cookies'}= Доступно только в хэш-массиве ответа. Обычно не используется, так как есть функции для чтения и записи cookies. Если для cookies определен хэш-массив, они могут быть сохранены в нем.
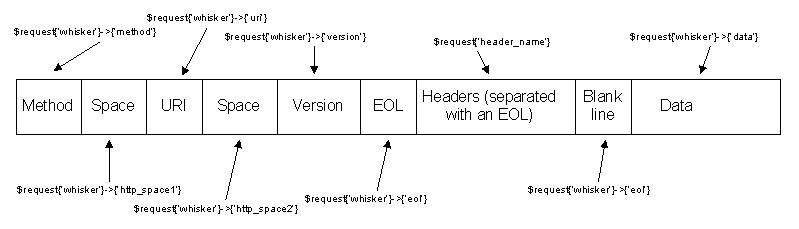
Рисунок 1: HTTP запрос и хэш-массив 'whisker'
Далее идет схема пакета HTTP ответа, на которой показано, как обратиться к хэш-массиву 'whisker'.
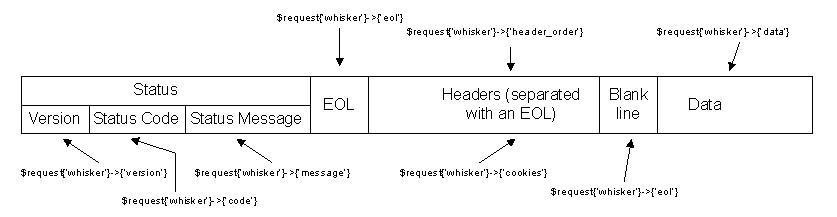
Рисунок 2: HTTP ответ и хэш-массив 'whisker'
Начнем
Для ознакомления с Libwhisker напишем консольную утилиту, осуществляющую первые пять шагов, описанных в статье "Penetration Testing of Web Applications". Это будет хороший пример, на котором могут основываться ваши скрипты. Обобщим, что должен делать скрипт:
- Анализировать ответы на запросы HEAD и OPTIONS
- Анализировать формат и структуру 404 и других страниц об ошибках
- Проверка на известные типы файлов/расширения/каталоги
- Анализ исходников доступных страниц
- Манипулирование вводом для выявления ошибок в скриптах
I.
use LW2;
%request = ();
%response = ();
LW2::http_init_request(\%request);
$request{'whisker'}->{'host'} = "www.victim.com";
II.
use LW2; $request = LW2::http_new_request(host=>'www.victim.com', uri =>'/'); $response = LW2::http_new_response();Для осуществления первого из наших пяти шагов нам нужно послать на сервер запрос HEAD или OPTION и посмотреть, что нам будет отправлено в ответ. Это означает, что нам нужно изменять значение переменной
{'whisker'}->{'method'} и печатать все заголовки, возвращенные сервером. Метод можно будет указать, используя опцию '-m' командной строки. Можно будет выбрать метод GET, HEAD или OPTIONS.
#Модули, которые мы будем использовать.
use strict;
use LW2;
use Getopt::Std;
#Хэш-массивы для опций командной строки, запросов и ответов
my (%opts, %request, %response, $headers_array, $header);
getopts('h:m:', \%opts);
#Инициализация всех переменных запроса. Некоторые из них будут перезаписаны.
LW2::http_init_request(\%request);
if (!(defined($opts{h}))) {
die "You must specify a host to scan.\n";
}
if (defined($opts{m})) {
if ($opts{m} =~ /OPTIONS|HEAD|GET/) {
$request{'whisker'}->{'method'} = $opts{m};
} else {
die "You can only use OPTIONS, HEAD or GET for the method.\n";
}
}
##начинаем создание запросов
#Установка хоста, который мы хотим сканировать
$request{'whisker'}->{'host'} = $opts{h};
#Обеспечиваем совместимость с RFC
LW2::http_fixup_request(\%request);
#Производим сканирование
if(LW2::http_do_request(\%request,\%response)){
##обработка ошибок
print 'ERROR: ', $response{'whisker'}->{'error'}, "\n";
print $response{'whisker'}->{'data'}, "\n";
} else {
##выводим результаты
#Получаем информацию из хэш-массива
#'$headers_array' это ссылка
$headers_array = $response{'whisker'}->{'header_order'};
print "HTTP " ,$response{'whisker'}->{'version'}, "\t";
print $response{'whisker'}->{'code'} , "\n";
foreach $header (@$headers_array) {
print "$header";
print "\t$response{$header}\n";
}
}
Второй, третий, четвертый и пятый шаг в нашем примере могут быть объединены, так как они все состоят в изменении URI и анализе HTML данных, возвращенных сервером. Чтобы поменять URI, нам нужно изменить значение переменной {'whisker'}->{'URI'}. Нам также нужно добавить опцию для вывода HTML данных. Так мы сможем увидеть, есть ли что-нибудь интересное в возвращенных данных, например ошибка 404 (шаг 2), файлы и директории (шаг 3), исходный код (шаг 4) и ошибки, полученные манипуляцией URI в GET запросах (шаг 5). Для задание URI мы будем использовать опцию '-u', а для вывода HTML кода опцию '-d'.
Давайте посмотрим на новый код, основанный на предыдущем:
#Модули, которые мы будем использовать.
use strict;
use LW2;
use Getopt::Std;
#Хэш-массивы для опций командной строки, запросов и ответов
my (%opts, %request, %response, $headers_array, $header);
##обратите внимание на дополнение, опцию 'd' для данных
##и 'u' для URI
getopts('dh:m:u:', \%opts);
#Инициализация всех переменных запроса. Некоторые из них будут перезаписаны.
LW2::http_init_request(\%request);
if (!(defined($opts{h}))) {
die "You must specify a host to scan.\n";
}
if (defined($opts{m})) {
if ($opts{m} =~ /OPTIONS|HEAD|GET/) {
$request{'whisker'}->{'method'} = $opts{m};
} else {
die "You can only use OPTIONS, HEAD or GET for the method.\n";
}
}
##установка URI, если он передан в командной строке
if (defined($opts{u})) {
$request{'whisker'}->{'uri'} = $opts{u};
}
#Установка хоста, который мы хотим сканировать
$request{'whisker'}->{'host'} = $opts{h};
#Обеспечиваем совместимость с RFC
LW2::http_fixup_request(\%request);
#Производим сканирование
if(LW2::http_do_request(\%request,\%response)){
print 'ERROR: ', $response{'whisker'}->{'error'}, "\n";
print $response{'whisker'}->{'data'}, "\n";
} else {
#Получаем информацию из хэш-массива
#'$headers_array' это ссылка
$headers_array = $response{'whisker'}->{'header_order'};
print "\n\n";
print "HTTP " ,$response{'whisker'}->{'version'}, "\t";
print $response{'whisker'}->{'code'} , "\n";
foreach $header (@$headers_array) {
print "$header";
print "\t$response{$header}\n";
}
##если использована опция 'd' выводим некоторую информацию
if (defined($opts{d})) {
print "\n\n-----------------------------
-----------------------------\n\n";
print $response{'whisker'}->{'data'} , "\n";
}
}
Теперь добавим возможность изменения поля 'User-Agent' HTTP заголовка. Разработчики использует его, чтобы определиться использует ли клиент поддерживаемый ими браузер. По умолчанию 'User-Agent', используемый Libwhisker, установлен в 'Mozilla (libwhisker/2.0)'. Мы добавим поддержку трех различных браузеров, Netscape 7.1, Microsoft IE 6 и Mozilla Firefox 0.9.
Чтобы подделать 'User-Agent' мы добавим опцию '-U', которая будет использоваться в сочетании с N (Netscape), I (Internet Explorer) или F (Mozilla Firefox). Однако подделать браузер гораздо сложнее, чем просто изменить поле 'User-Agent' HTTP заголовка. В большинстве случаев наш способ сработает, но каждый браузер также имеет какие-то свои, специфичные поля заголовка. Если вы хотите полностью подделать браузер, нужно сначала определить, какие специфичные поля заголовка он использует и какие значение в них передаются, а затем соответственно установить эти поля в вашем скрипте.
Нам также нужно добавить поддержку метода POST. Некоторые приложения требуют, чтобы пользователь открыл сеанс перед отправкой данных методом POST, поэтому мы должны получить cookies из ответа сервера и установить их для осуществления POST запроса. Один минус этого состоит в том, что URI, который мы будем определять, используя опцию '-u', должен использоваться только в POST запросе. Вначале скрипт сделает простой GET запрос и получить cookie, затем, перед вызовом 'LW2::http_do_request', установит cookie в POST запросе. Ниже показан скрипт, позволяющий изменять поле 'User-Agent' HTTP заголовка, а также делать POST запросы. Опция '-D' будет использоваться для определения данных, которые должны находится в POST запросе.Ниже находится заключительный вариант нашего скрипта, который теперь может выполнить все пять ранее поставленных задач.
#Модули, которые мы будем использовать.
use strict;
use LW2;
use Getopt::Std;
#Хэш-массивы для опций командной строки, запросов, ответов и cookies
my (%opts, %request, %response, , %jar, $headers_array, $header);
##обратите внимание, добавлены опции 'U' и 'D'
getopts('dh:m:u:U:D:', \%opts);
#Инициализация всех переменных запроса. Некоторые из них будут перезаписаны.
LW2::http_init_request(\%request);
if (!(defined($opts{h}))) {
die "You must specify a host to scan.\n";
}
if (defined($opts{m})) {
##по умолчание GET, если явно указано, то POST
if ($opts{m} =~ /OPTIONS|HEAD|GET/) {
$request{'whisker'}->{'method'} = $opts{m};
}
}
if (defined($opts{u})) {
##не устанавливать URI, если используем метод POST
$request{'whisker'}->{'uri'} = $opts{u} unless ($opts{m} eq "POST");
}
##установка 'User-Agent' по опции 'U'
##'F', 'I' или 'N' для Firefox/IE/Netscape
##как и указано в тексте
if (defined($opts{U})) {
if ($opts{U} eq "F") {
$request{'User-Agent'} =
"Mozilla/5.0 (Windows; U; Windows NT 5.1;
en-US; rv:1.7) Gecko/20040614 Firefox/0.9";
} elsif ($opts{U} eq "I") {
$request{'User-Agent'} =
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)";
} elsif ($opts{U} eq "N") {
$request{'User-Agent'} =
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.4)
Gecko/20030624 Netscape/7.1 (ax)";
} else {
die "You did not specify a supported \'User-Agent\'.\n";
}
}
#Установка хоста, который мы хотим сканировать
$request{'whisker'}->{'host'} = $opts{h};
#Обеспечиваем совместимость с RFC
LW2::http_fixup_request(\%request);
#Производим сканирование
H_REQUEST:
if(LW2::http_do_request(\%request,\%response)){
print 'ERROR: ', $response{'whisker'}->{'error'}, "\n";
print $response{'whisker'}->{'data'}, "\n";
} else {
##иначе сохраним cookie для следующего запроса
LW2::cookie_read(\%jar, \%response);
#Получаем информацию из хэш-массива
#'$headers_array' это ссылка
$headers_array = $response{'whisker'}->{'header_order'};
print "\n\n";
print "HTTP " ,$response{'whisker'}->{'version'}, "\t";
print $response{'whisker'}->{'code'} , "\n";
foreach $header (@$headers_array) {
print "$header";
print "\t$response{$header}\n";
}
if (defined($opts{d})) {
print "\n\n----------------------------------
------------------------\n\n";
print $response{'whisker'}->{'data'} , "\n";
}
if ($opts{m} eq "POST") {
LW2::cookie_write(\%jar, \%request);
$request{'whisker'}->{'method'} = "POST";
$request{'whisker'}->{'uri'} = $opts{u};
$request{'whisker'}->{'data'} = $opts{d };
LW2::http_fixup_request(\%request);
$opts{d} = undef;
$opts{m} = undef;
goto H_REQUEST;
}
}
Заключение
Наличие ваших собственных скриптов и утилит может быть очень удобно для тестирования веб приложений. Один из плюсов этого - вы знаете, как эти утилиты работают, и можете добавить новые функциональные возможности, в соответствии с вашими потребностями. Это также помогает в понимании принципов работы приложения.Многие утилиты, проведя простое тестирование, могут сказать пользователю, что приложение уязвимо, но иногда требуется большее. Libwhisker можно использовать для автоматизации процесса сбора информации, как это было показано здесь. Так же как и многие утилиты для проверки защиты, использующие libnet и libpcap, для создания и приема специфичных пакетов, Libwhisker предоставляет нам тот же уровень функциональных возможностей для создания и анализа HTTP пакетов и может быть очень полезен испытателю на проникновение.